11 Large Language Models (LLMs)
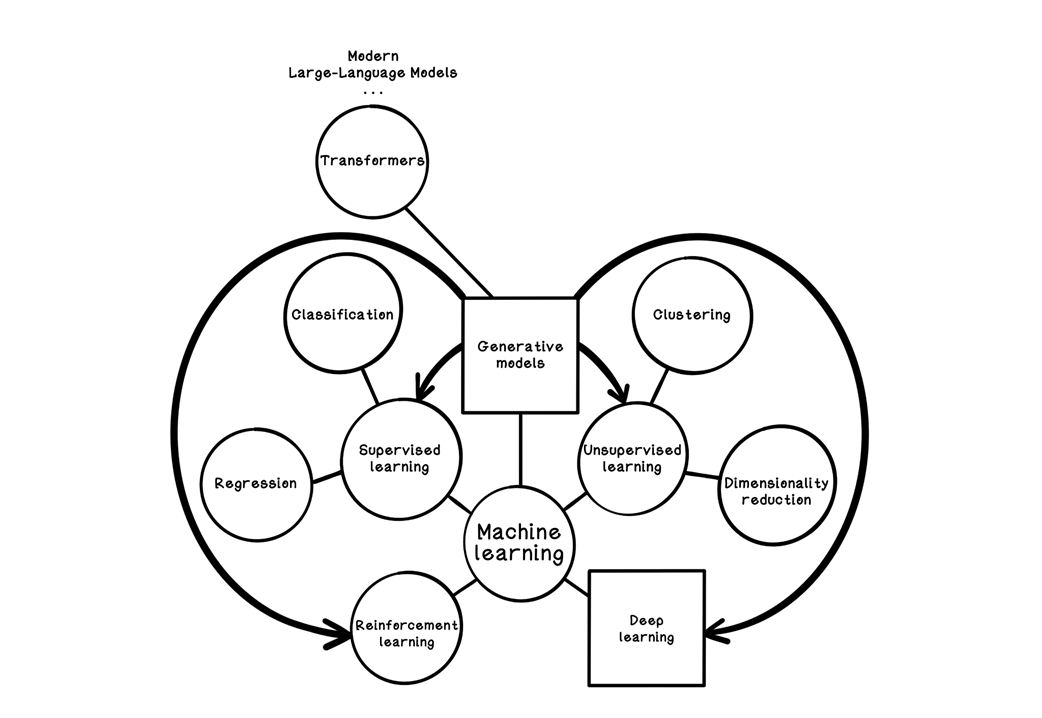
Large language models are presented as next-word predictors that have been scaled up in capacity, data, and architectural sophistication to acquire broad language competence. Built on Transformers and their self-attention mechanism, modern LLMs learn long-range dependencies and contextual relationships across vast corpora spanning books, web pages, code, and domain texts. With billions of parameters and carefully curated training sets, they generalize beyond single-token prediction to tasks like drafting prose, answering questions, translating, and writing code, while drawing on ideas from supervised, unsupervised, reinforcement, and deep learning.
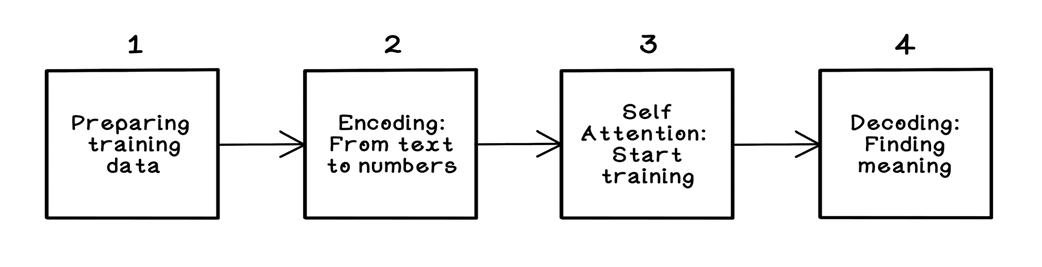
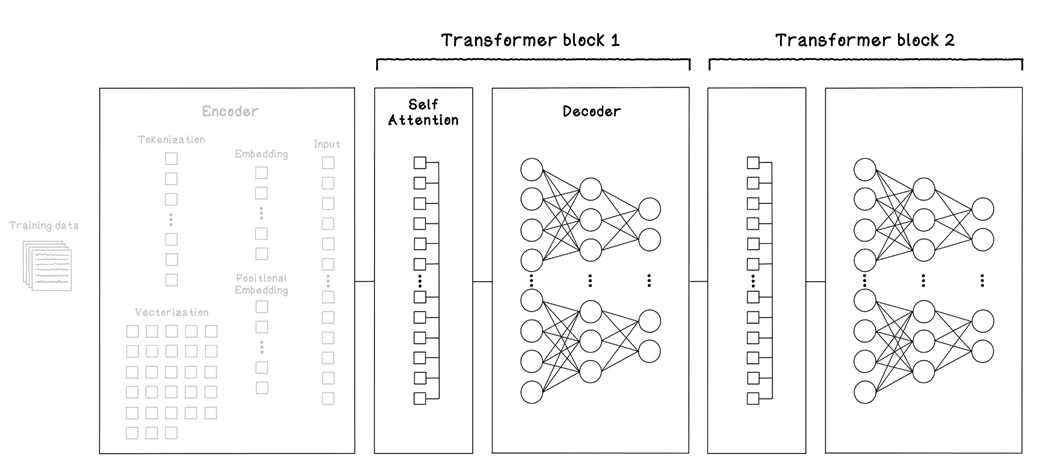
The chapter walks through a practical training workflow end to end: selecting and licensing data; cleaning and normalizing it (removing boilerplate, duplicates, unsafe content; standardizing casing, quotes, whitespace, and characters); and turning text into numbers via tokenization, using byte-pair encoding to build a compact vocabulary. After vectorizing text into token streams and batching within a fixed context window, the model maps tokens to trainable embeddings and injects order via positional encodings. Self-attention then forms Queries, Keys, and Values, computes scaled dot products and softmax weights, and blends Value vectors into context-rich representations. Residual connections and layer normalization stabilize training; a small feed-forward network projects features up and down; and stacking many such blocks, governed by hyperparameters like width, depth, heads, and context length, yields an efficient pipeline that runs best on GPU hardware.
Prediction converts the final hidden states to logits over the vocabulary and probabilities via softmax. Training minimizes cross-entropy loss against the known next token in the sequence, and backpropagation nudges all weights—embeddings, attention projections, and feed-forward layers—over many batches, epochs, and checkpoints, with early stopping and hyperparameter tuning (manual, grid, random, or Bayesian) guiding progress. Beyond base pretraining, the chapter highlights practical control and refinement methods: prompt-based zero- and few-shot learning, reinforcement learning from human feedback to align behavior, Mixture-of-Experts for scalable capacity without proportional compute, and Retrieval-Augmented Generation to ground outputs in external knowledge. It closes with high-impact applications—content generation, information synthesis, coding assistance, and product features—that turn these mechanisms into tangible value.
Example of autocomplete as a language model

How generative models and Transformers fit into machine learning
How we subconsciously identify patterns in language

Formula for probability of a word occurring after another word

Example of the probability of words occurring

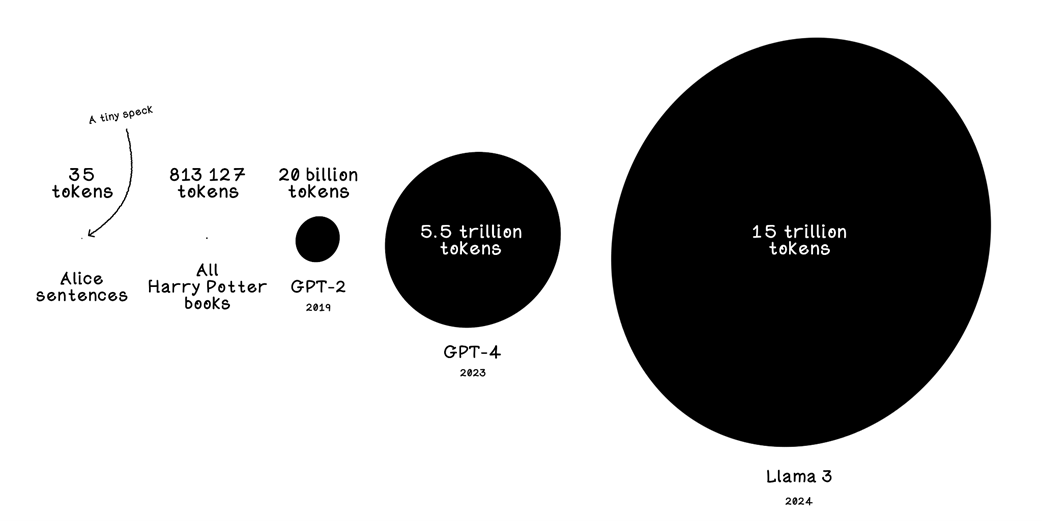
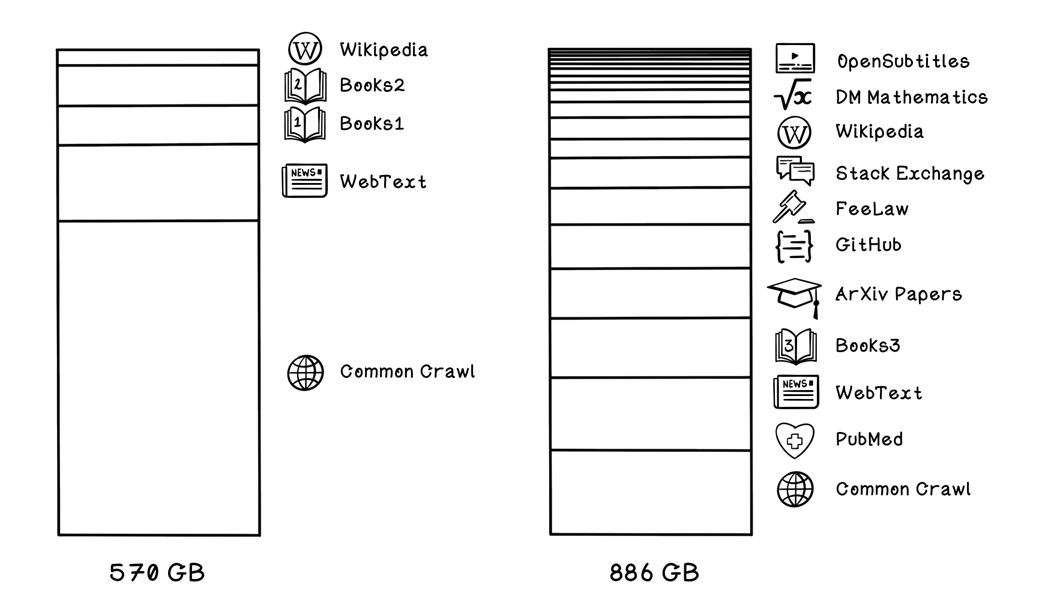
Comparison of size of training sets in popular language models
An overview of the LLM training workflow
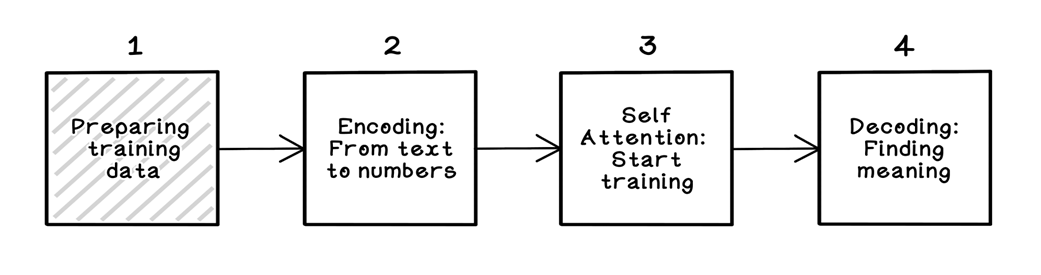
Preparing training data step in the LLM training workflow
Sample training datasets and their domain composition
Excerpt of training data from Alice’s Adventures in Wonderland

Training data with boiler-plate stipped

Training data normalized

Encoding step in the LLM training workflow
Training data split into characters with end-of-word markers

Training data after one iteration of merging with BPE

Training data after two iterations of merging with BPE

Training data after three iterations of merging with BPE


Original training data

Tokenized training data as a token stream

Tokenized training data as training batches


Designing the architecture step in the LLM training workflow
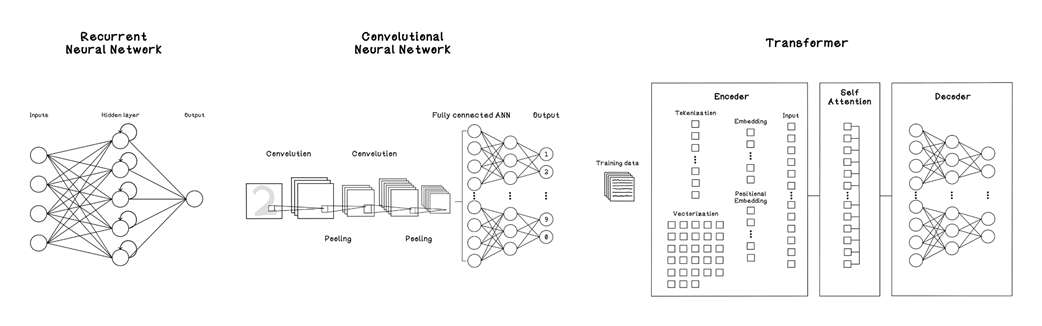
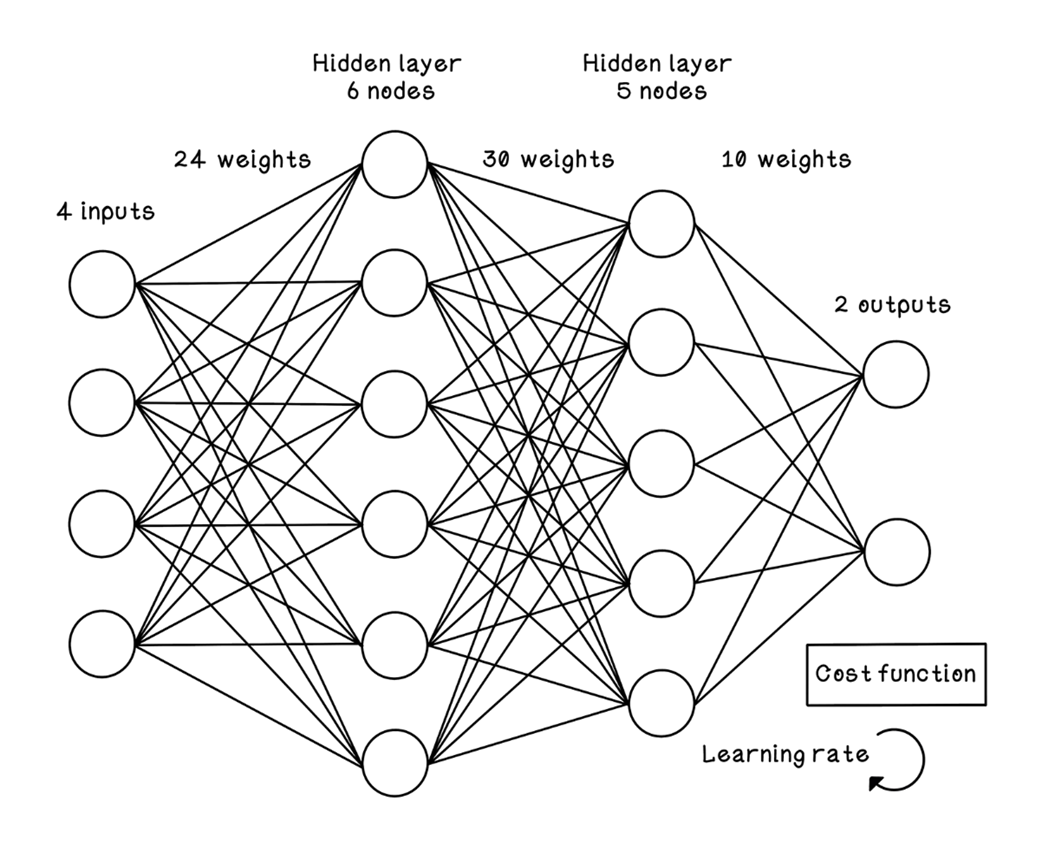
Comparison of different ANN architectures aimed at training LLMs
The fundamental composition of an artificial neural network
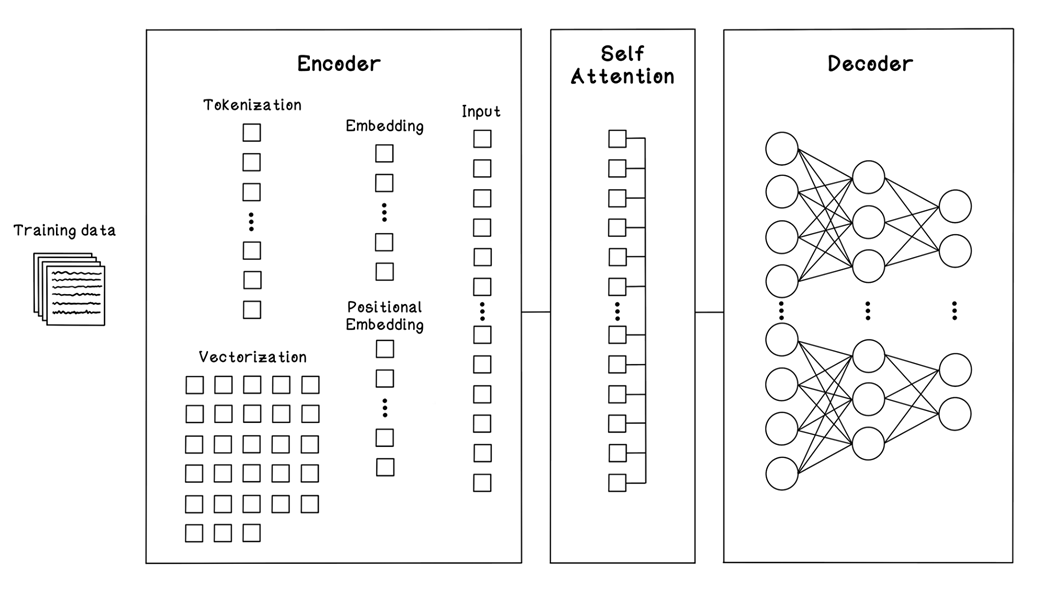
A simplistic overview of the Transformer framework
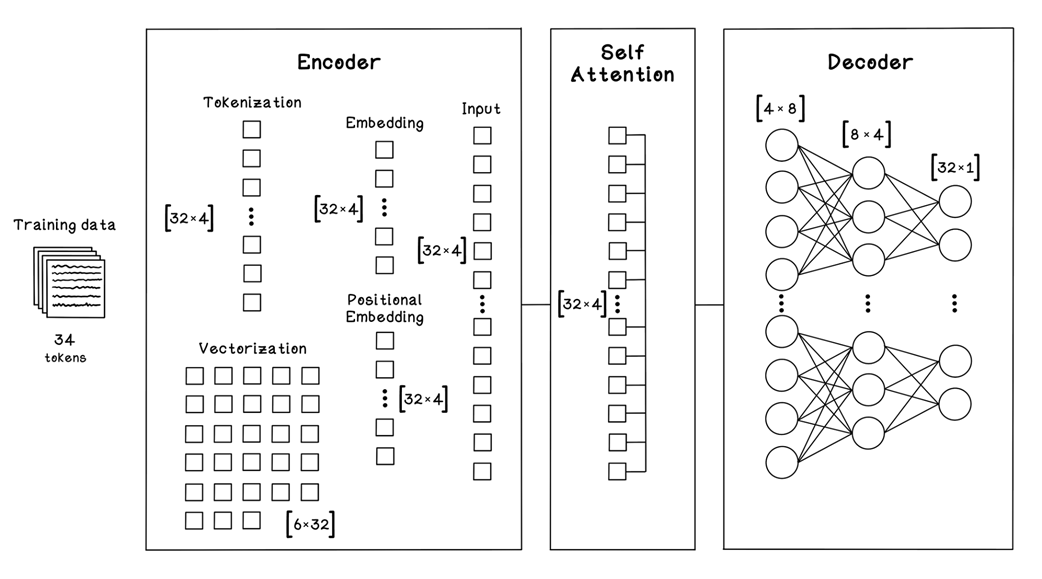
The data shapes for the different components in our Transformer framework
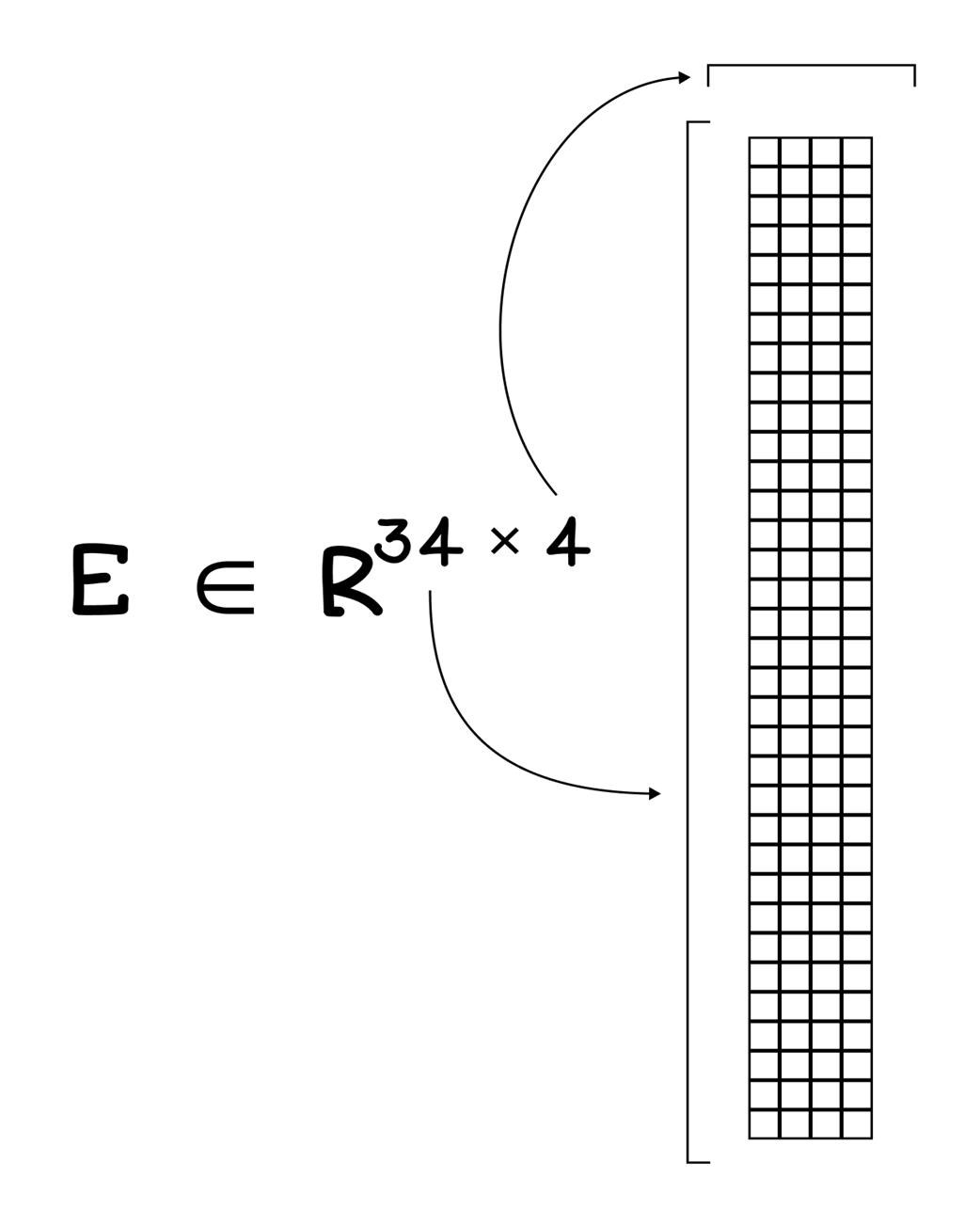
Continuation of the encoding step in the LLM training workflow
Sampling the first batch of tokens from the training data

A view of how the vocabulary size and width dimensions shape the embedding
An odometer analogy for how sinusoidal positional encoding works
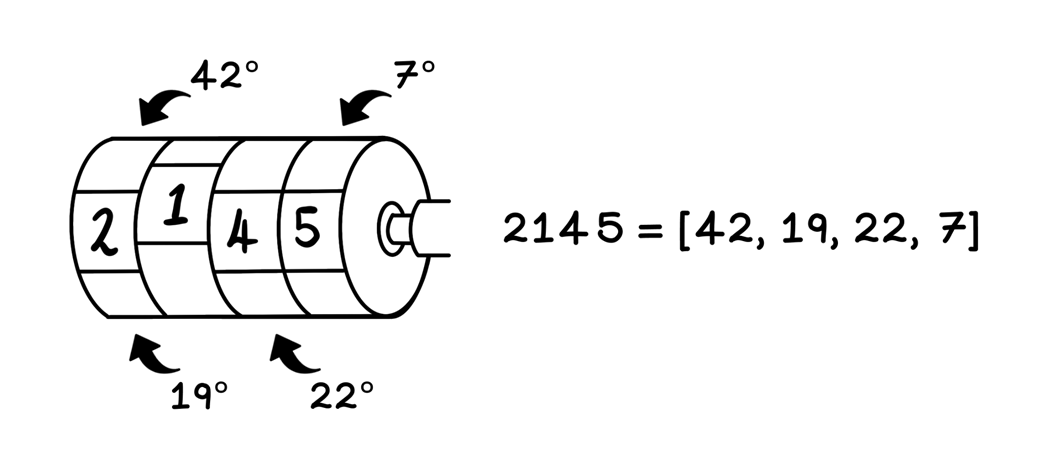
A breakdown of the calculations involved in sinusoidal encoding

A view of the embedding combination step in the encoding stage
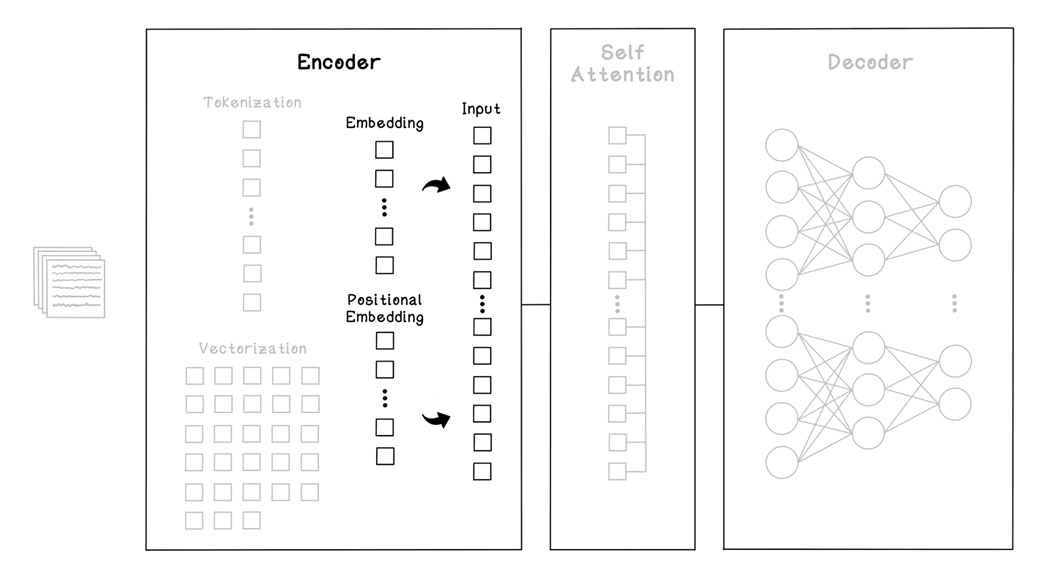

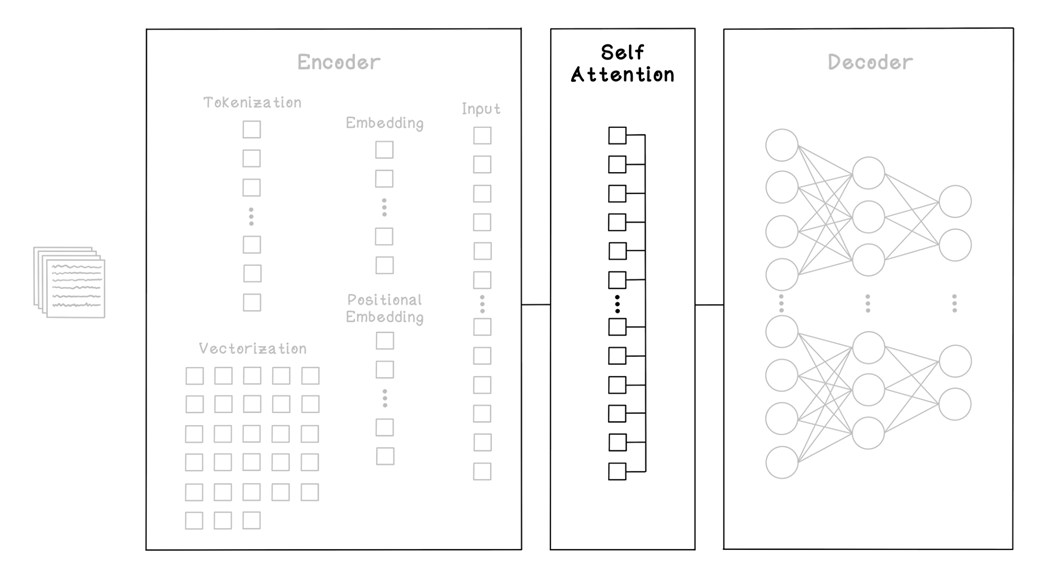
The self-attention step in the LLM training workflow
Where self-attention fits into the Transformer framework
An analogy of the purposes of Query, Key, and Value
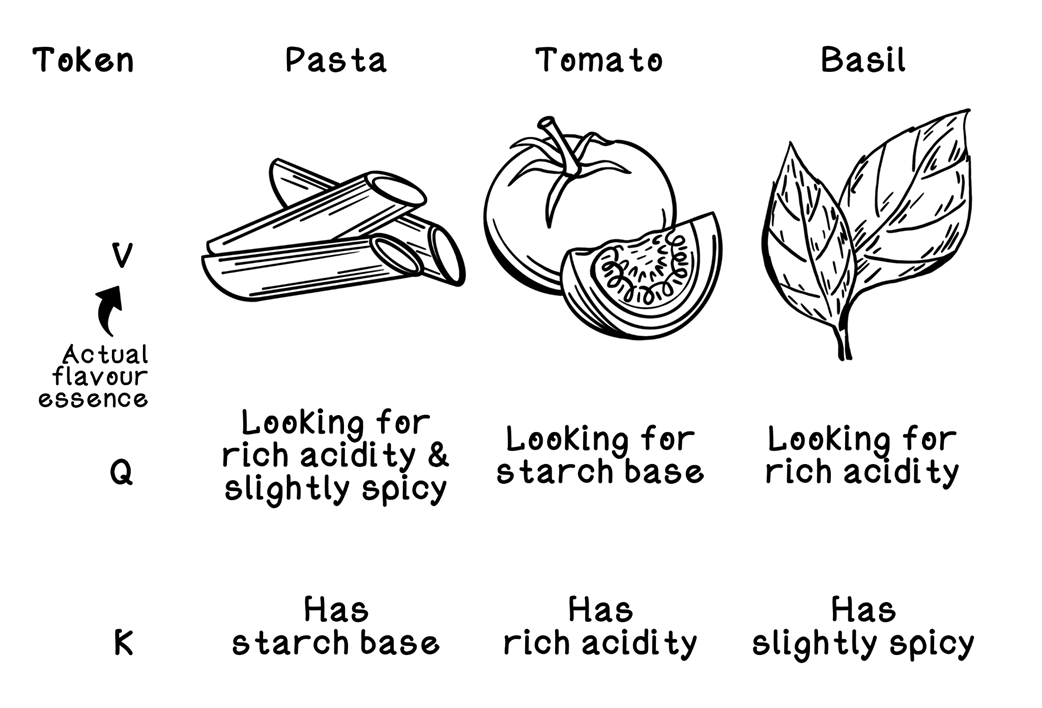
Initialization of the values for Queries, Keys, and Values

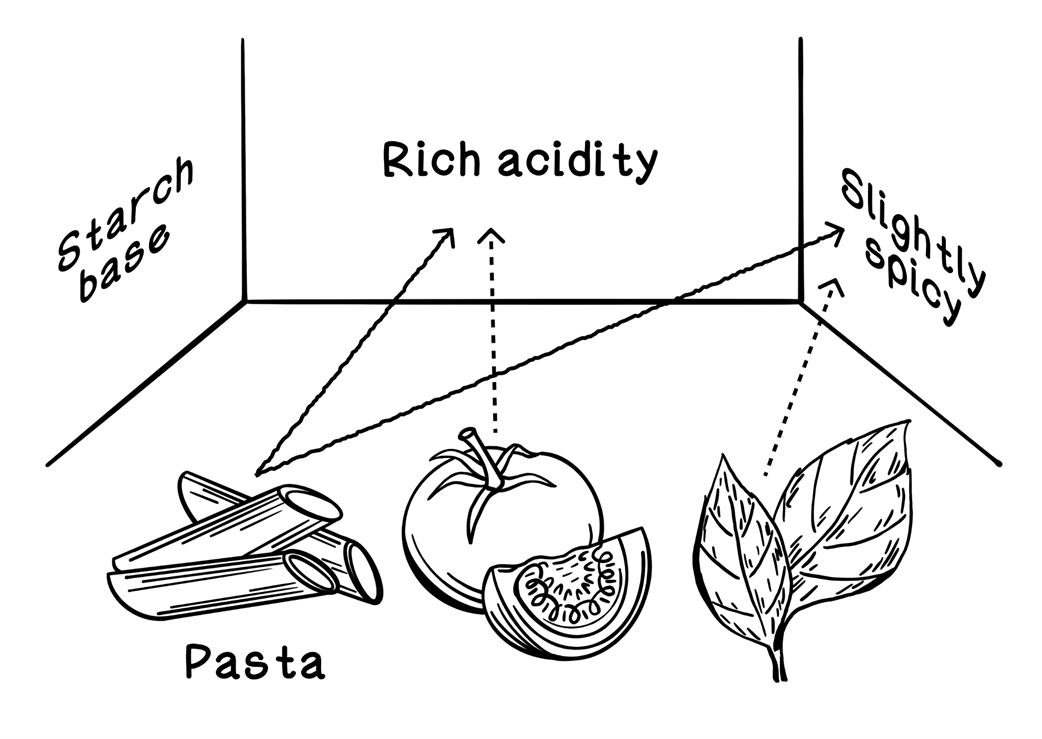
An analogy of how self-attention works
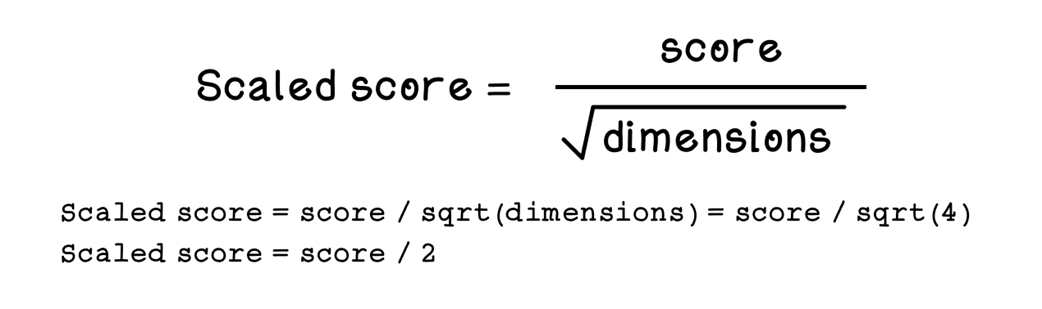
The formula for scaling scores given the score and dimensions
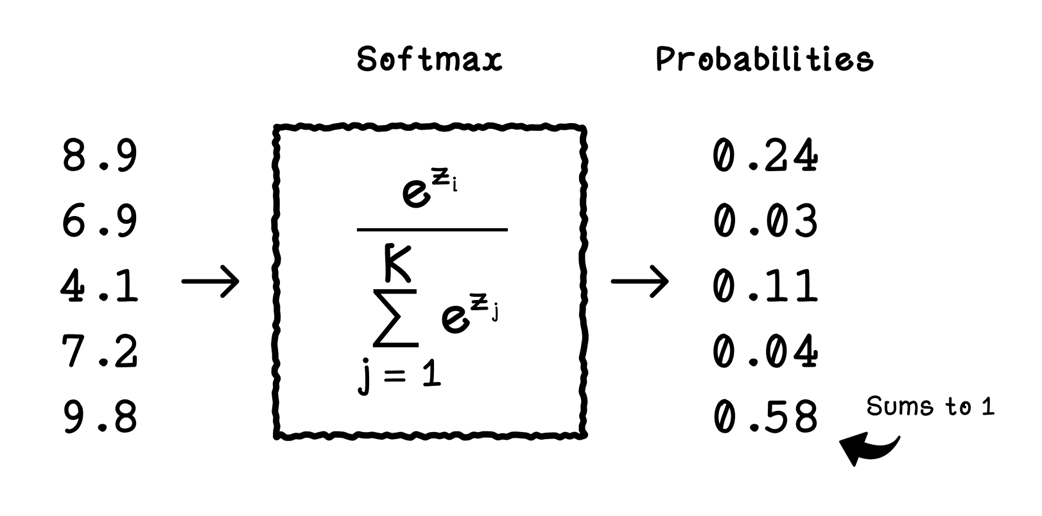
How softmax scales scores to probabilities
A subset of the context vector calculations


An analogy of the usefulness of multiple attention heads

Calculations for the residual connection

The formula for layer normalization
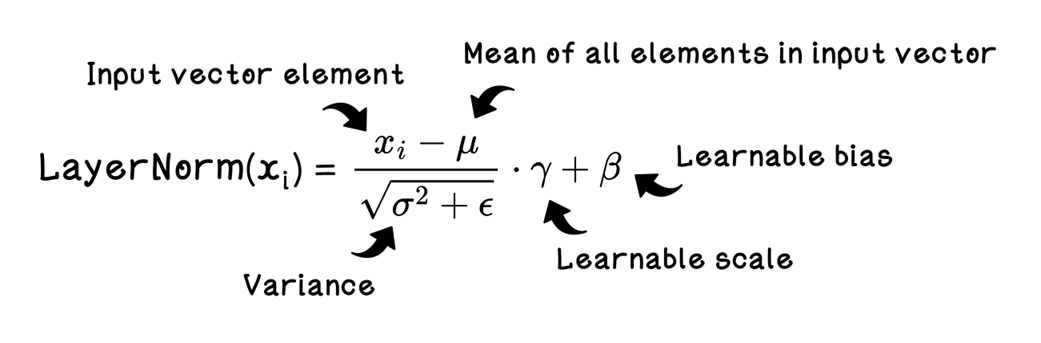

The decoding step in the LLM training workflow
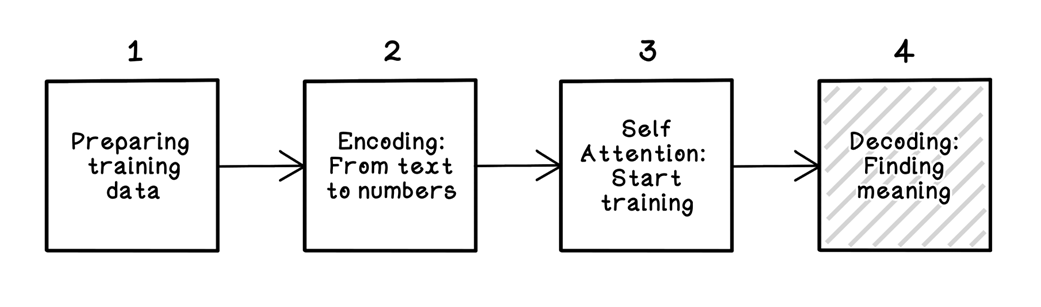
The architecture of the feed-forward network to output token probabilities
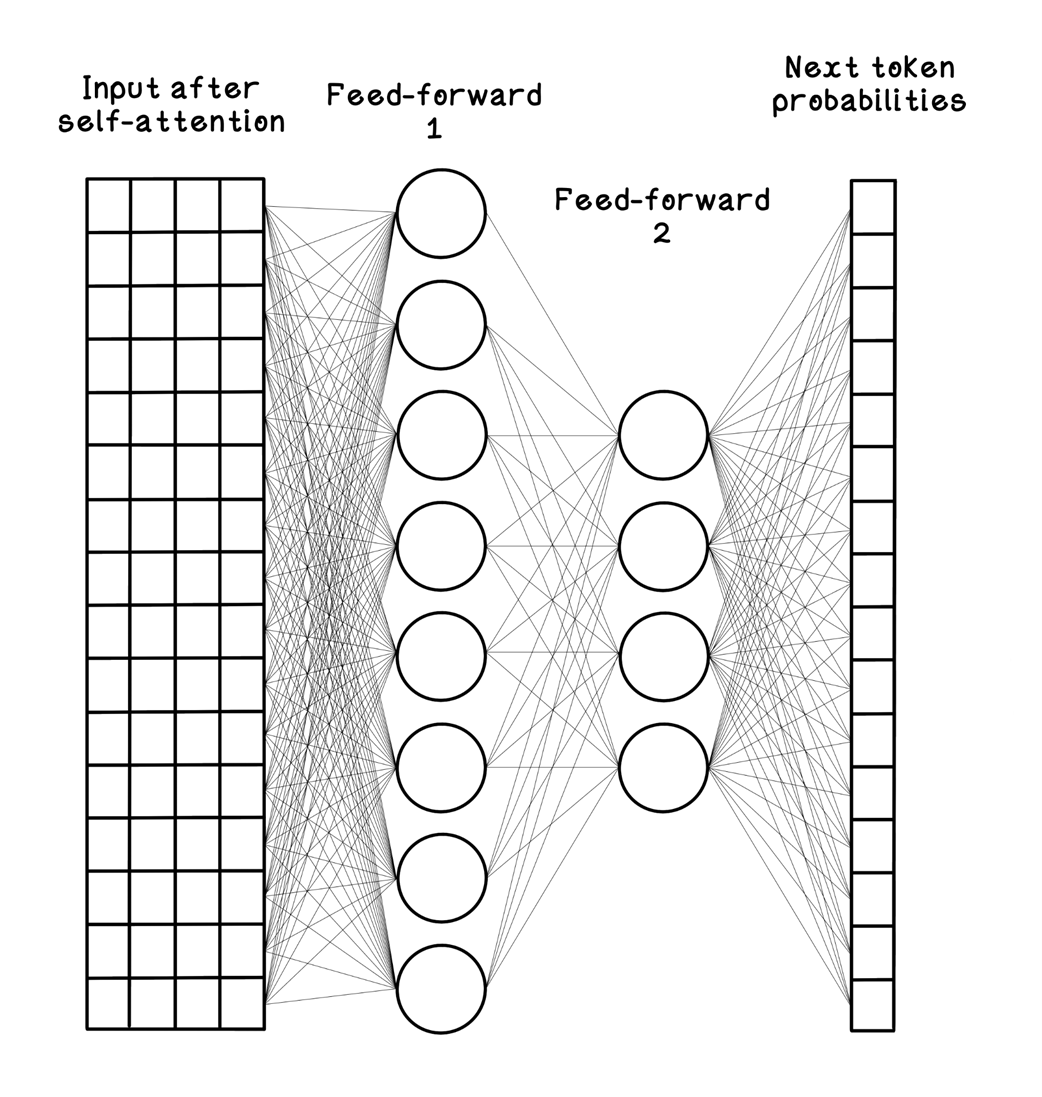
Calculations for feed-forward outputs

Calculations for adding bias to the output

Calculations for applying the ReLU activation function


Calculations for the project-down layer output

Calculations for adding bias to the output of the project-down layer

Calculations for adding the residual

How multiple transformer blocks are stacked
Calculations for logits for tokens
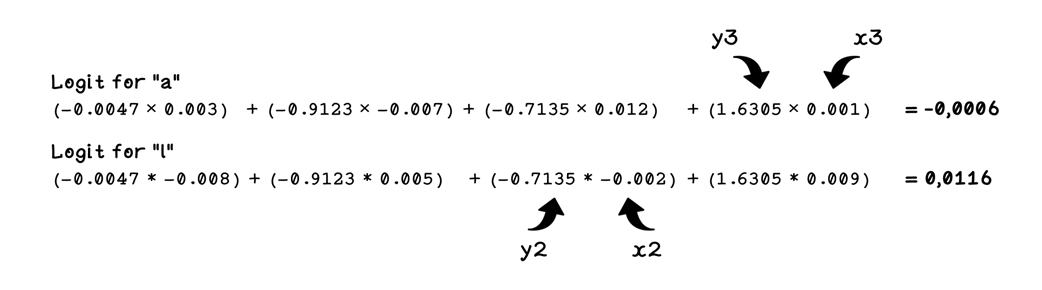
Final prediction for the next token after “a”

Revisiting the first training batch of tokens


Calculations for new weights given the learning rate and gradient
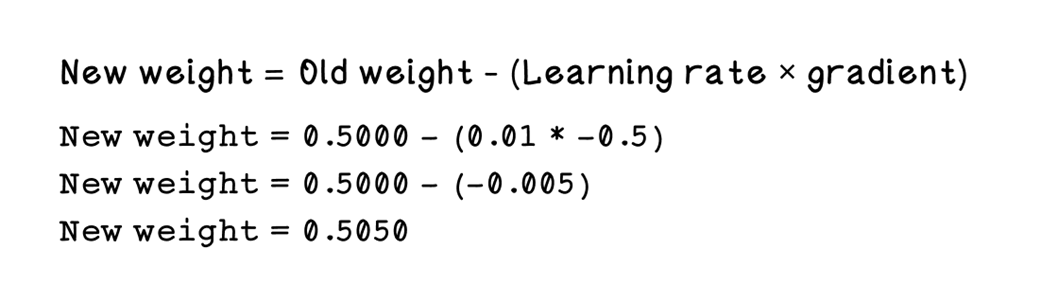

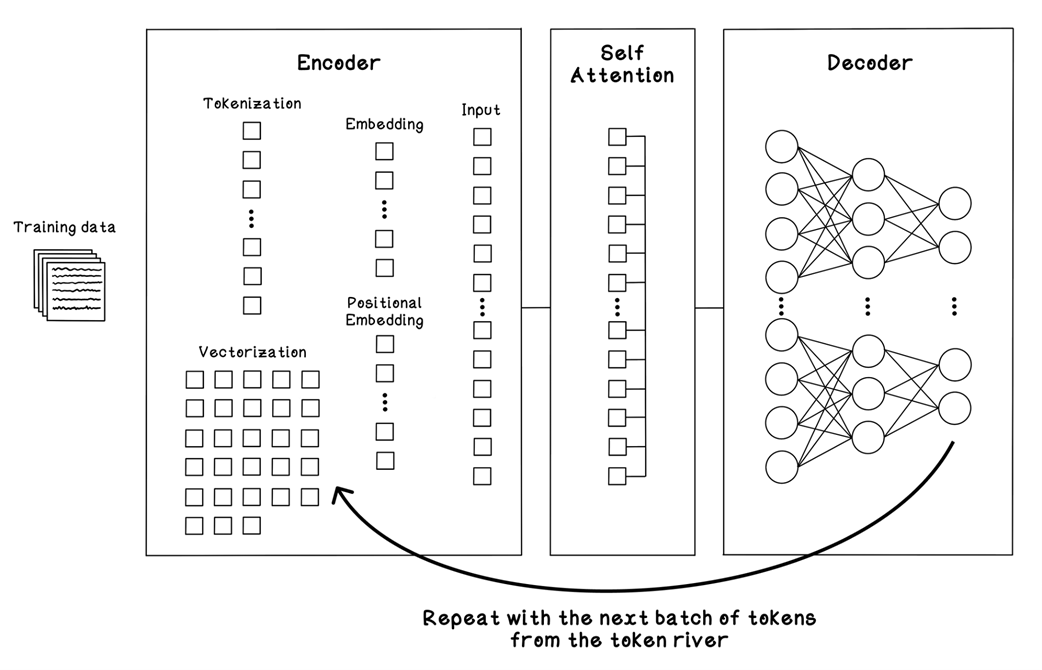
How epochs repeat in the Transformer framework
Example of use cases for few-shot learning

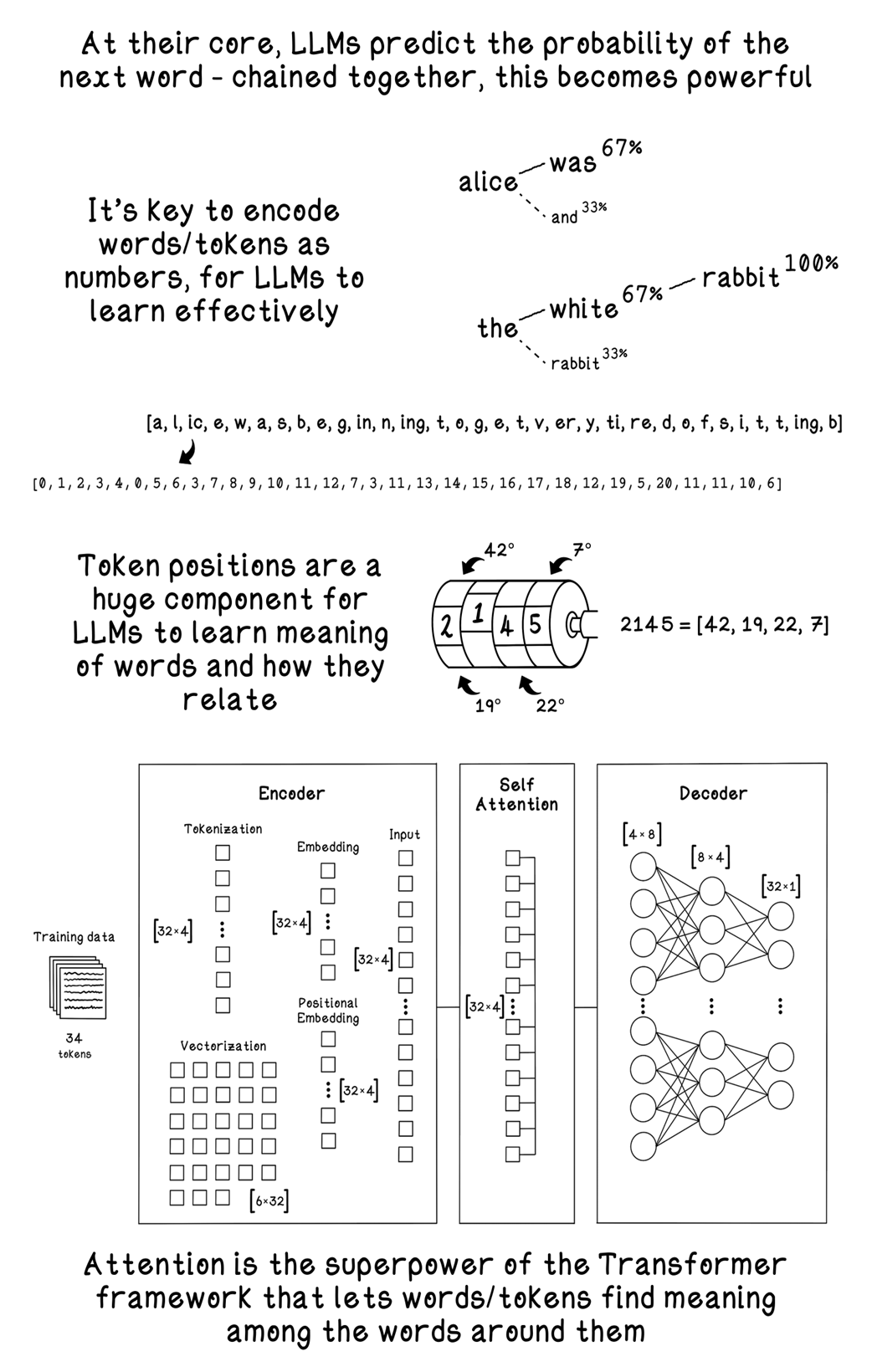
Summary of Large Language Models
FAQ
What is a Large Language Model (LLM) and how does it differ from a simple language model?
An LLM predicts the next token in a sequence like a simple language model, but it scales that idea with:
- Far more capacity: billions of trainable parameters instead of small count tables.
- Vast training data: web pages, books, papers, code, forums—often trillions of tokens.
- Transformer architecture: self-attention learns long-range relationships and context.
- Richer abilities: coherent generation, QA, translation, coding, reasoning-like behavior.
What are tokens and parameters, and why do their sizes matter?
- Tokens: the basic units the model sees (often subwords via BPE). More tokens in training = broader coverage of language and edge cases.
- Parameters: the learned weights in the Transformer. More parameters = more representational capacity.
- Scale matters: bigger token corpora plus more parameters typically yield better generalization—up to the limits of data quality, compute, and optimization.
How do I prepare training data for an LLM?
- Select sources: public-domain books, web crawls, forums, news, domain corpora, code.
- Mind licensing: use public-domain, permissive licenses, or explicitly licensed data.
- Clean and normalize: strip boilerplate, remove near-duplicates, filter toxicity/PII, fix encoding/casing/whitespace, handle diacritics.
- Audit quality: check duplicate rate, toxicity/profanity, markup density, language purity, PII, readability, domain balance.
How does Byte Pair Encoding (BPE) tokenization work?
- Start with characters (plus end-of-word markers).
- Count adjacent pairs (bigrams) and merge the most frequent pair into a new token.
- Repeat count-and-merge until a target vocabulary size or frequency threshold is reached.
- Result: subword tokens that capture common roots/affixes (e.g., “un”, “believ”, “able”) and handle rare words robustly.
Why are embeddings and positional encodings needed?
- Embeddings: map discrete token IDs to dense vectors the network can learn from.
- Positional encodings: add position information (e.g., sinusoidal) so attention can distinguish word order.
- Combined vector = token meaning (“what”) + position (“where”), enabling the model to learn grammar and context.
What does self-attention do in a Transformer?
- Projects inputs to Query, Key, Value spaces (learned matrices).
- Computes relevance scores via scaled dot-product between Queries and Keys.
- Converts scores to attention weights (softmax), then blends Values accordingly.
- Multi-head attention: multiple “perspectives” capture different patterns (syntax, coreference, etc.).
How does the end-to-end training workflow produce predictions?
- Encode: tokenize to IDs, create embeddings, add positional encodings, batch into context windows.
- Transform: self-attention + feed-forward layers (with residuals and layer norm), possibly stacked many times.
- Decode: project final vectors to vocabulary logits, softmax to probabilities.
- Predict: choose next token (greedy, sampling, temperature, etc.).
How does the model learn—loss, backpropagation, epochs, and stopping?
- Loss: cross-entropy between predicted distribution and the actual next token.
- Backpropagation: compute gradients through all layers and update weights (via a learning rate).
- Epochs and batches: iterate over many batches, often multiple passes (epochs). Some massive runs can learn well in < 1 epoch due to huge corpora.
- Checkpoints and early stopping: save progress regularly; stop when validation loss stops improving (patience).
Which hyperparameters matter most, and how are they tuned?
- Key knobs: vocabulary size, context window, embedding width, number of layers, attention heads, feed-forward size, learning rate, batch size.
- Tuning strategies: manual tuning, grid search, random search, Bayesian optimization.
- Prompting modes: zero-shot and few-shot can steer pre-trained LLMs without retraining.
What advanced techniques extend or refine LLMs (RLHF, MoE, RAG)?
- RLHF: align behavior with human preferences—collect ranked responses, train a reward model, and fine-tune with reinforcement learning.
- Mixture of Experts (MoE): many specialized feed-forward “experts”; a router activates only a few per token—huge capacity at lower compute per token.
- Retrieval-Augmented Generation (RAG): fetch relevant external documents at inference time to ground answers, reduce hallucinations, and keep knowledge current.
 Grokking AI Algorithms, Second Edition ebook for free
Grokking AI Algorithms, Second Edition ebook for free