1 Starting a fabulous adventure
This chapter introduces the book’s playful approach to algorithms and data structures by explaining why some ideas feel “fabulous”: they solve real problems in unexpected ways, produce surprising results, work across many domains, highlight meaning over low-level mechanics, and even feel a bit magical. It also emphasizes that programming is not just about efficiency, but about discovery, creativity, and learning to think differently about problems.
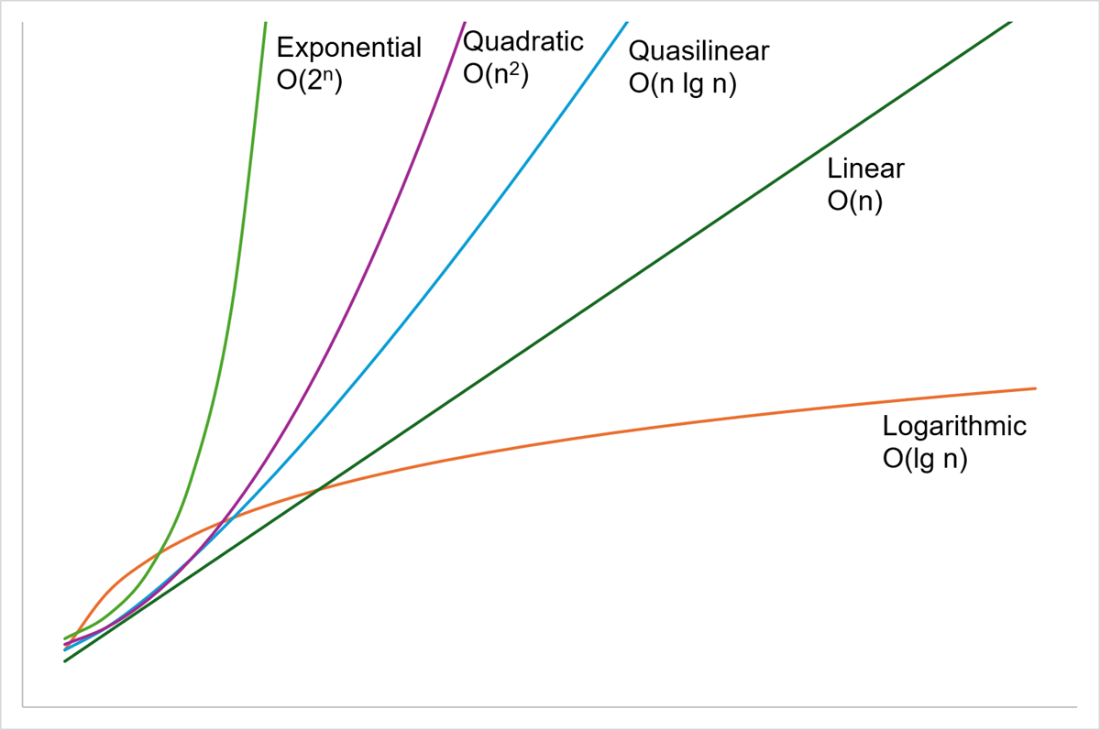
It then defines the basic terms used throughout the book. A data structure is an organized way to store information, an algorithm is a finite set of steps for solving a problem, and complexity describes how the cost of solving that problem grows with its size. The discussion introduces big O notation and contrasts common growth rates, from constant and logarithmic to linear, quasilinear, quadratic, exponential, and factorial, while warning that the “best” asymptotic complexity is not always the best choice for real workloads.
To make these ideas concrete, the chapter builds an immutable linked list in C# and examines its performance, showing that even simple code can hide costs such as recursive equality checks and accidentally quadratic string concatenation. It then demonstrates reversing an immutable list by constructing a new list in reverse order, giving an O(n) solution in time and memory. The chapter closes by previewing the journey ahead: revisiting familiar structures with new twists, exploring advanced techniques like persistence and memoization, and moving toward algorithms for developer tools, probability, randomness, statistical inference, and deeper theoretical connections.
A graph comparing the growth curves for logarithmic, linear, quasilinear, quadratic and exponential growth. Logarithmic is the shallowest curve, growing very slowly, and exponential is the fastest.
Summary
- There are lots of books about standard data structures such as lists, trees and hash tables, and the algorithms for sorting and searching them. And there are lots of implementations of them already in class libraries. In this book we’ll look at the less well-known, more off-the-beaten-path data structures and algorithms that I had to learn about during my career. I’ve chosen the topics I found the most fabulous: the ones that are counterintuitive, or seemingly magical, or that push boundaries of languages.
- I had to learn about almost all the topics in this book when I needed a new tool in my toolbox to solve a job-related problem. I hope this book saves you from having to read all the abstruse papers that I had to digest if you too have such a problem to solve.
- But more important to me is that all these fabulous adventures gave me a deeper appreciation for what computer programmers are capable of. They changed how I think about the craft of programming. And I had a lot of fun along the way! I hope you do too.
- Asymptotic complexity gives a measurement of how a solution scales to the size of the problem you’re throwing at it. We generally want algorithms to be better than quadratic if we want them to scale to large problems.
- Complexity analysis can be subtle. It’s important to remember that time is not the only resource users care about, and that they might also have opinions on whether avoiding a bad worst-case scenario is more or less important than achieving an excellent average performance.
- If problems are always small, then asymptotic complexity matters less.
- Reversing a linked list is straightforward if you have an immutable list! We’ll look at other kinds of immutable lists next.
FAQ
What makes an algorithm or data structure “fabulous” in this chapter?
They are described as fabulous when they solve real problems in interesting ways, achieve counterintuitive results, apply across many domains, emphasize meaning over mechanism, look like a magic trick, take advantage of language features, challenge the usual frame, connect with theory, or are simply fun to use and build.
What is the difference between a data structure and an algorithm?
A data structure is a way to store information in an organized, structured manner. An algorithm is a finite sequence of steps that, when executed, solves a problem.
What does algorithm complexity measure?
Algorithm complexity describes the relationship between the size of a problem and the cost of solving it, usually measured in time, memory, or another resource.
What are the common big O complexity classes mentioned in the chapter?
The chapter discusses O(1), O(log n), O(n), O(n log n), O(n2), O(2n), and O(n!) as common ways to describe how algorithm cost grows as problem size increases.
Why is O(n2) often considered a warning sign?
Quadratic algorithms grow much faster than linear or quasilinear ones. If the input size increases tenfold, the cost can increase a hundredfold, so quadratic or worse algorithms are often avoided for large-scale problems.
Why can the best asymptotic algorithm still be the wrong choice?
Because performance depends on real usage. An algorithm with a worse worst case may still be fastest on the small, typical inputs that users actually have, so asymptotic complexity is only one factor in choosing a solution.
How is the immutable linked list represented in this chapter?
It is defined recursively: a linked list is either empty or a value followed by a tail linked list. The example implementation uses a C# record with Value and Tail fields, plus Push, IsEmpty, and ToString.
What are the performance characteristics of creating and reversing the immutable linked list?
Creating a new node with new or Push is O(1) time and extra memory. Reversing the list by repeatedly pushing items onto a new list is O(n) in both time and extra memory.
What hidden performance problems can appear in the linked list example?
The chapter points out that the default record equality can be more expensive than expected, may recurse deeply enough to overflow the call stack, and that the naive ToString implementation is accidentally quadratic because repeated string concatenation copies previous content each time.
What topics will the book explore after this introductory chapter?
The book will move through stacks, queues, trees, persistence, memoization, list reordering, unusual constant-time linked list reversal, backtracking and graph coloring, code formatting and tree unification, and later probability, randomness, statistical inference, and category theory connections.
 Fabulous Adventures in Data Structures and Algorithms ebook for free
Fabulous Adventures in Data Structures and Algorithms ebook for free