Searching is often like asking a busy librarian for help: intent is ambiguous, context differs, languages vary, and relevant information may be scattered or missing. The chapter reframes this struggle by proposing deep learning as a helpful “advisor” that augments search engines with learned context and semantics—an approach the book calls neural search. After a brief primer on machine learning (supervised and unsupervised training leading to models that make predictions) and deep learning (neural networks that learn hierarchical representations), the chapter motivates why these techniques can make search more effective across text, images, and languages, ultimately aiming to deliver faster, more precise answers.
The chapter then grounds readers in classic information retrieval fundamentals: analyzing text into tokens and terms, filtering (e.g., stopwords, stemming), and storing them in inverted indexes to enable fast matching. It explains how queries are parsed and analyzed at search time to align with the index, and how retrieval models rank results by relevance—highlighting vector space models with TF‑IDF and probabilistic approaches like BM25. It also introduces how to measure effectiveness through precision and recall. Despite these mature techniques, unresolved issues remain: relevance is subjective and context-dependent, small wording changes can yield very different results, and the ranking behavior of search engines often feels like a black box, requiring users to iterate and reformulate queries.
Deep learning addresses these gaps by learning rich representations that capture semantics and context: word and document embeddings bring synonyms and related concepts closer; neural models can translate, generate text, and represent images by their objects rather than pixels. Applied to search, this enables better ranking, query reformulation, cross‑lingual retrieval, image search, and recommendations. The chapter also outlines practical integration concerns—training cost and data needs, online learning for evolving content, and model storage strategies (e.g., attaching embeddings to terms in the index)—and emphasizes continual evaluation. The book’s goal is to teach these principles and patterns, using open‑source tools (e.g., Lucene and Deeplearning4j) to build neural search systems that are data‑driven, performant, and measurably more relevant.
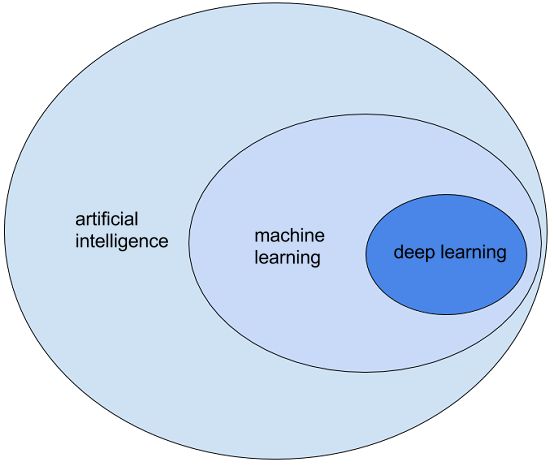
Figure 1.1. Artificial intelligence, machine learning, deep learning
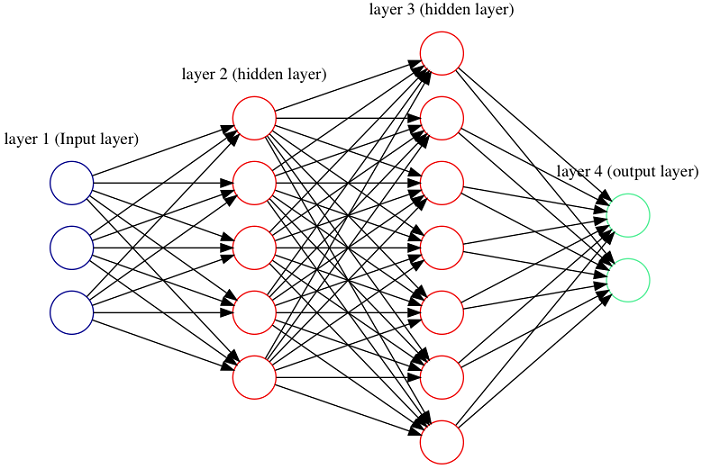
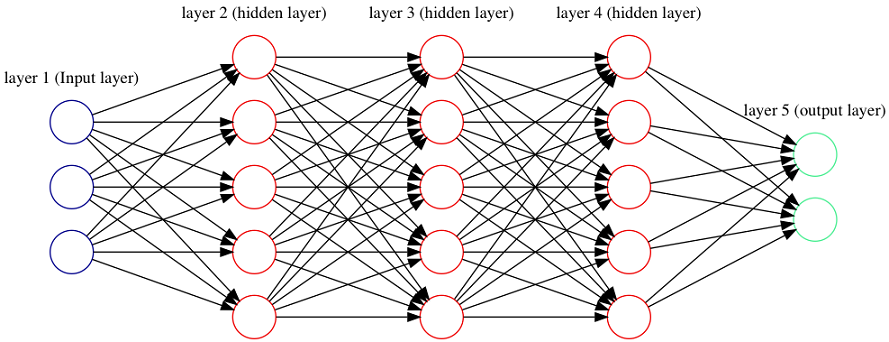
Figure 1.2. A deep feed forward neural network with 2 hidden layers
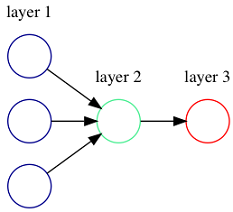
Figure 1.3. An artificial neuron (green) with 3 inputs and 1 output
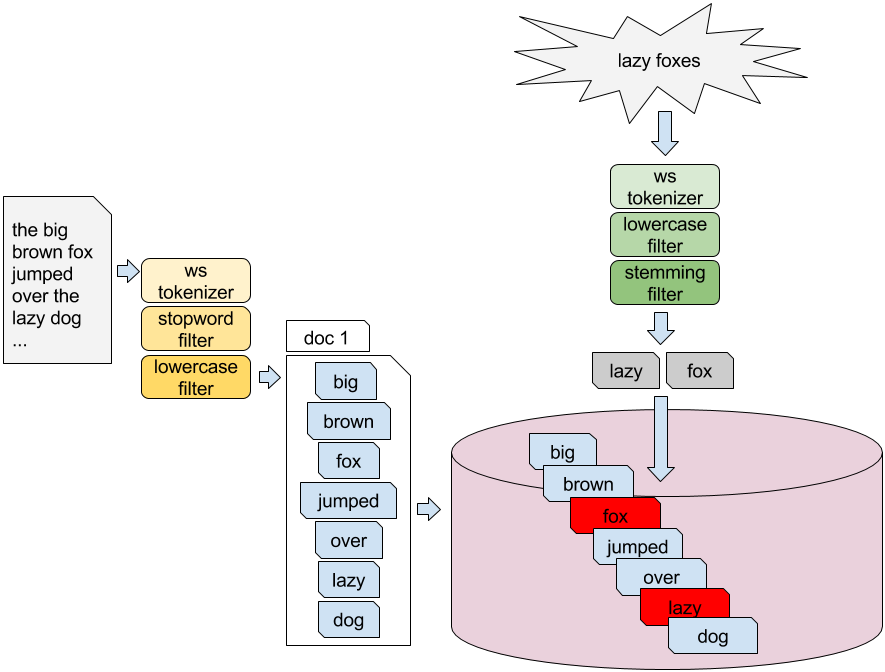
Figure 1.4. Getting the words of "I like search engines" using a simple text analysis pipeline
Figure 1.5. The traversed token graph
Figure 1.6. Index, search time analysis and term matching
Figure 1.8. A deep feed forward neural network with 3 hidden layers
Figure 1.9. Word vectors derived from papers on word2vec
Figure 1.10. A neural search application: using word representations generated by a deep neural network to provide more relevant results
Summary
Search is a hard problem: common approaches to information retrieval come with some limitations and disadvantages, and both users and search engineers can have a hard time making things work as expected.
Text analysis is an important task in search, for both indexing and search phases, because it prepares the data to be stored in the inverted indexes and has a high influence on the effectiveness of a search engine.
Relevance is the fundamental measure of how well the search engine responds to users' information needs. Some information retrieval models can give a standardized measure of the importance of results with respect to queries, but there is no silver bullet. Context and opinions can float significantly among users, and therefore measuring relevance needs to be a continuous focus for a search engineer
Deep learning is a field in machine learning that makes use of deep neural networks to learn (deep) representations of content (text like words, sentences, paragraphs, but also images) that can capture semantically relevant similarity measures.
Neural search stands as a bridge between search and deep neural networks with the goal of using deep learning to help improve different tasks related to search.
FAQ
What is “neural search” in this book?Neural search is the application of deep learning—especially deep neural networks—to information retrieval to improve how search engines understand, retrieve, and rank content. Think of deep learning as an “advisor” (like the book’s Robbie analogy) that gives the search engine context and better representations to return more precise results. The term stems from “neural information retrieval,” first highlighted at a SIGIR 2016 workshop.Why do we need neural search if web search already works?Users still struggle with mediocre relevance, time-consuming exploration, language barriers, and difficulty finding specific images or nuanced answers. Deep neural networks help by: learning semantic representations of text and images; enabling multilingual search via neural machine translation; generating summaries/answers; and reducing zero-result queries—ultimately delivering more relevant, faster results.How does deep learning help a search engine understand text and images?Deep learning learns layered (deep) representations—embeddings—of words, sentences, documents, and images. These capture semantics (e.g., “artificial intelligence” ≈ “AI”) and compositional structure (words → phrases → documents; pixels → edges → objects), enabling efficient similarity search (nearest neighbors), better ranking, cross-lingual matching, and image search without manually authored metadata.What are tokens, terms, and analyzers—and why do they matter?Text analysis pipelines split and normalize text before indexing/searching. Tokenizers break text into tokens; token filters transform or remove them (e.g., lowercasing, stopword removal, stemming). The final units, called terms, are what the index stores and matches. Choices at index time and search time control what matches, affecting both recall and relevance (e.g., removing “the,” stemming “foxes” → “fox”).How does an inverted index work?An inverted index maps each term to a posting list of document IDs that contain it. This makes term lookups very fast: the engine finds the term’s posting list and retrieves candidate documents. You can maintain separate fields or indexes (e.g., title vs. body) with different analyzers to balance exact matching and recall.How are queries interpreted and matched?A query parser turns user text into clauses (terms, phrases, boolean operators like AND/OR/NOT, required/optional flags). The search-time analyzer processes the query text (e.g., lowercasing, stemming) so its terms can match the index-time terms. Documents are retrieved when query terms match indexed terms referenced by a document’s posting lists.What is “relevance” and how are results ranked?Relevance measures how well a document satisfies an information need. Common retrieval models include the Vector Space Model with TF-IDF weighting (rank by similarity to the query vector) and probabilistic models like Okapi BM25 (rank by estimated relevance probability). In practice, you still tune analyzers, models, and parameters for your data.How do we measure search quality?Precision is the fraction of retrieved documents that are relevant; recall is the fraction of relevant documents that are retrieved. Measuring both typically requires human judgments or curated benchmarks. Public datasets like TREC provide judged queries to evaluate and compare systems.Which traditional search problems can deep learning help solve?It mitigates issues such as: mismatched user/librarian context (by learning contextual representations and user-aware models), language mismatches (via neural machine translation), iterative query refinement (via better semantic matching and even text generation), and opaque behavior (by making matching less brittle to synonyms and phrasing).How are neural networks integrated with a search engine in practice?Training needs lots of data and time; models must be kept in sync with evolving indexes. Options include online learning or periodically retraining and discounting stale model outputs. Models can be stored alongside the index—for example, saving word embeddings with their terms—to enable fast lookup without extra infrastructure. The book’s examples use Apache Lucene for IR and Deeplearning4j for deep learning (principles generalize to other frameworks like TensorFlow).
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!





 Deep Learning for Search ebook for free
Deep Learning for Search ebook for free