Voice-first computing moved from decades of niche promise to mainstream reality with products like Amazon Echo, turning natural conversation into a primary way to use technology. These platforms are defined by voice as the main input and by openness to third-party extensions that bring the web’s breadth to voice through skills and actions. The ecosystem is led by Amazon, Google, and Microsoft, is expanding quickly into homes, and increasingly supports multimodal experiences that pair speech with displays while keeping voice at the center.
Designing for voice requires applying the rules of good conversation: a helpful tone and personality appropriate to context, concise responses, smart follow-up questions, and graceful recovery when users stumble. Unlike rigid, menu-driven IVR systems, voice-first aims for flexible, goal-oriented dialogs that reduce user effort. This shifts responsibility from users to designers and developers—discoverability must be built in, inputs handled naturally despite variation, and outputs pruned to the most relevant answer—forcing those from visual-first backgrounds to rethink interaction models around conversation.
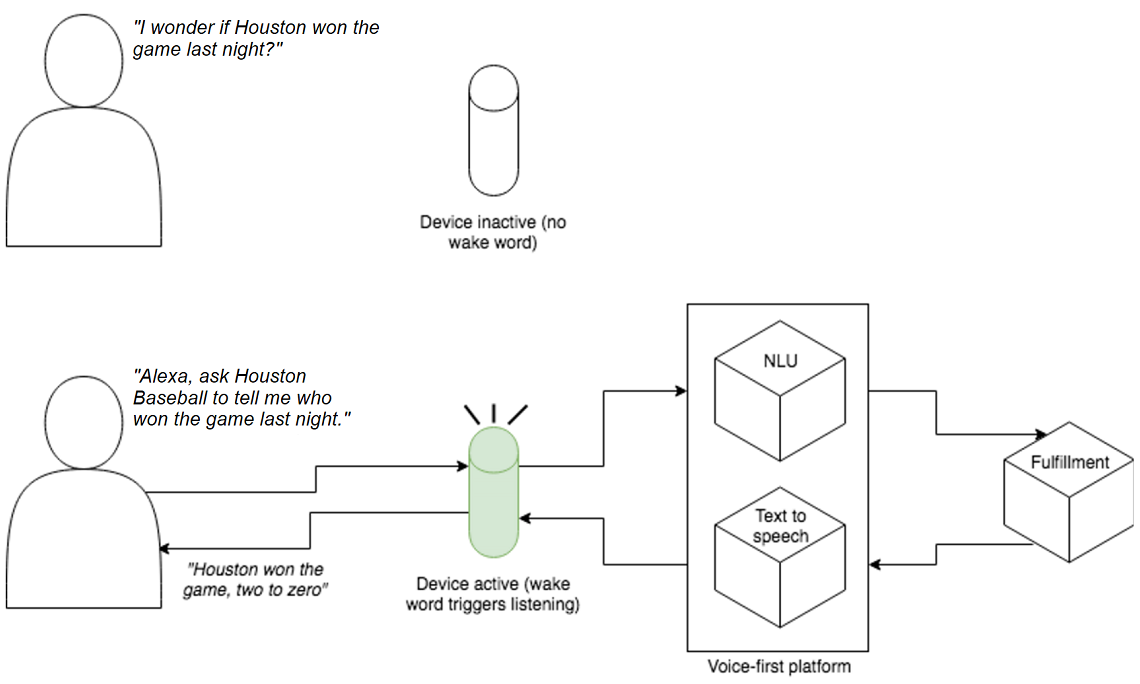
Under the hood, voice experiences follow a clear pipeline: a wake word triggers local listening, speech is streamed to the cloud, converted to text, and interpreted by NLU to match developer-defined intents and extract variable details via slots, guided by sample utterances. Fulfillment code—often running on serverless platforms—executes business logic, calls APIs, and returns a response that the assistant renders using text-to-speech, enhanced with SSML for pacing, emphasis, and other prosody controls. Put together, intents, slots, utterances, handlers, and SSML form the toolkit for building natural, reliable, and scalable voice applications.
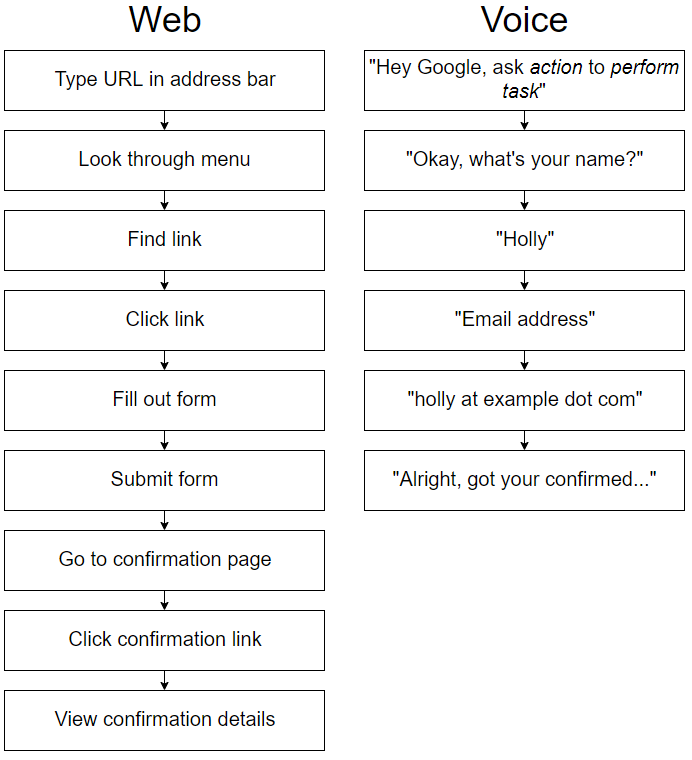
Figure 1.1. Web flow compared to voice flow
Figure 1.2. Alexa relies on natural language understanding to answer the user’s question.
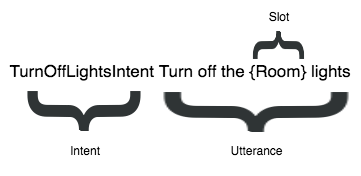
Figure 1.3. The overall user goal (the intent), the intent-specific variable information (the slot), and how it’s invoked (the utterance)
Summary
Focus on taking the burden of completing an action from the user in voice-first applications.
Data in a conversation flows back and forth between partners to complete an action.
Building a voice application involves reliably directing this data between systems.
Begin to think of requests in terms of intents, slots, and utterances.
FAQ
What does “voice first” mean?Voice-first platforms are interacted with primarily through voice and are open to extension by third-party developers. They bring the web to voice by allowing built-in functions plus developer-created apps (skills/actions).How are voice-first platforms different from old IVR phone trees?Classical IVR systems are rigid decision trees with a tiny set of choices. Voice-first platforms support natural, open-ended conversations and can invoke web-backed skills/actions, making the options practically limitless and more conversational.Who are the main voice-first platforms, and why isn’t Apple listed?The primary platforms discussed are Amazon, Google, and Microsoft because they’re open to third-party developers. Although Siri and HomePod are popular, Apple has not opened them to third-party development.Is “voice first” the same as “voice only”?No. Voice first prioritizes voice but can be multimodal. Devices like Echo Show and Google Home with Chromecast combine voice with displays, expanding interaction options while keeping voice as the main modality.What makes designing for voice different from web or mobile UI?Voice design relies on natural conversation. You must give the right amount of information, ask clarifying follow-ups, handle unexpected input gracefully, and set an appropriate personality—all without visual scaffolding. Responsibility shifts from users to developers to make options discoverable, inputs natural, and results concise.What are intents, sample utterances, and slots?Intents represent what the user wants to do (like functions). Sample utterances are example phrases that train the NLU to map speech to an intent. Slots are variable pieces of information (like arguments) extracted from the utterance (for example, a Room slot in “turn off the lights in the kitchen”).How does a voice command flow from speech to response?The device wakes on a local wake word, streams audio to the platform, converts speech to text, uses NLU to infer intent and slots, forwards the request to fulfillment (your code), receives a textual response, converts it to speech, and plays it back to the user.What is a wake word and how is it handled?A wake word/phrase (for example, “Alexa,” “Hey Google”) is recognized locally. Devices keep a short audio buffer and continuously listen for the wake word so they can quickly start streaming speech once invoked, helping responsiveness and privacy.Why is converting speech to text difficult?Speech varies by accent, voice, and context; background noise and similar-sounding phrases add ambiguity. Systems break audio into phonemes, compare to known patterns, and rely on statistical models and large training sets to infer the most likely words.What is fulfillment, and how does the device decide what to say back?Fulfillment is your code that handles requests (often on serverless platforms like AWS Lambda or Google Cloud Functions). A handler mapped to an intent processes slots, performs logic, and returns a response. Speech is typically returned using SSML, which lets you control prosody (rate, volume, pronunciation) before it’s synthesized and spoken to the user.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Voice Applications for Alexa and Google Assistant ebook for free
Voice Applications for Alexa and Google Assistant ebook for free