1 Seeing inside the black box
This opening chapter frames the modern condition of data science: powerful, convenient models make high‑stakes decisions while hiding their inner logic, and the gap between usability and understanding keeps widening. Through the metaphor of an autopilot that suddenly disengages, it warns that polished dashboards and plausible outputs can mask fragile assumptions, data drift, and encoded bias. The central claim is that interpretability and accountability are not luxuries—when models affect health, credit, jobs, or justice, we must be able to explain why a decision was made, not retreat behind “the algorithm said so.”
The chapter dismantles the illusion of understanding created by tools, libraries, and AI assistants that generate “working” solutions without testing fit-for-purpose assumptions. It contrasts modeling approaches (e.g., forests vs. neural networks; logistic regression vs. ensembles), showing how different inductive biases yield different answers, and emphasizes wisdom over rote precision: knowing when a method’s premises break, how thresholds reflect real costs, and why fat‑tailed risks can upend tidy averages. Foundational literacy turns diagnostics and preprocessing into judgment, not ritual—checking assumptions, calibrating probabilities, guarding against leakage and drift—and expands into ethics and epistemology, surfacing how choices about loss functions, features, priors, or inference paradigms encode values with real social consequences.
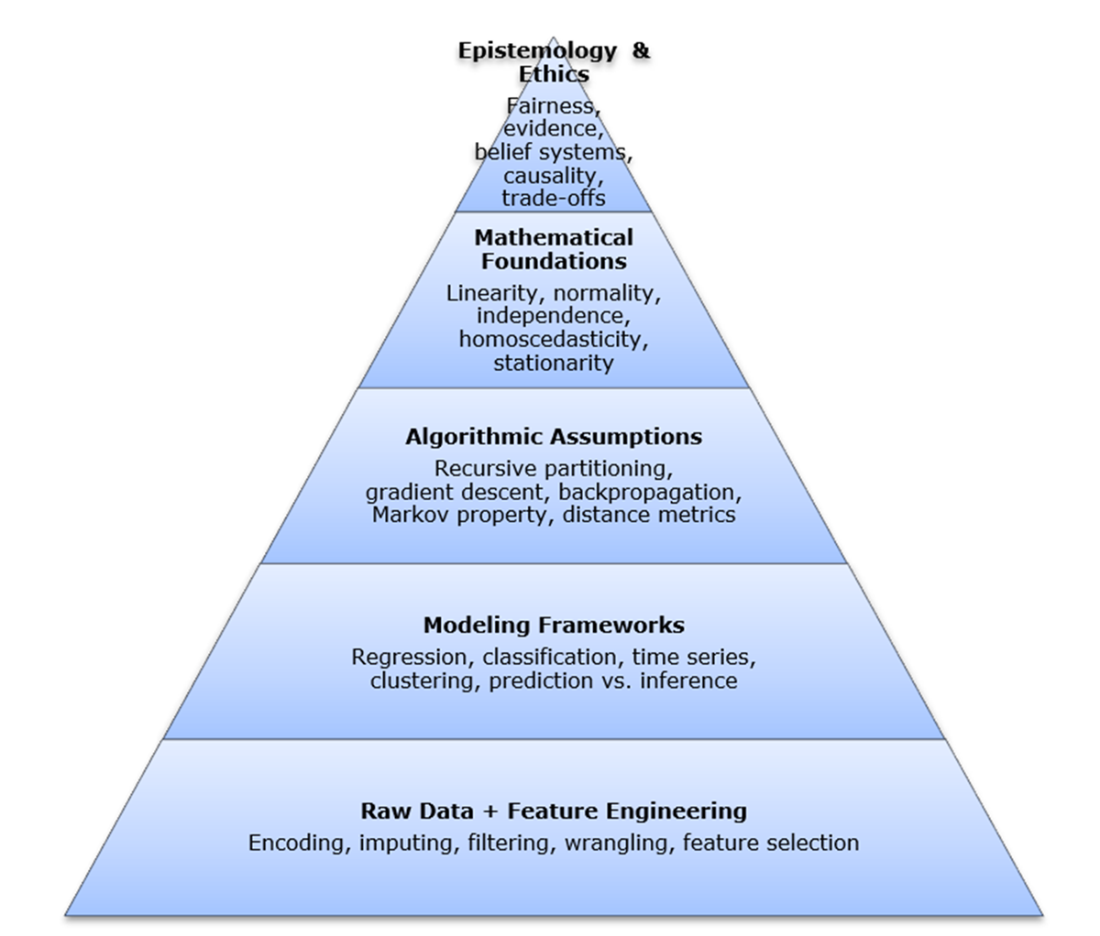
To reclaim understanding, the chapter introduces a “hidden stack” of modern intelligence—a conceptual layering from data and features through algorithms and mathematical principles to philosophical commitments—that shapes every prediction. It positions the rest of the book as a guided tour of seminal works—Bayes, Fisher, Neyman–Pearson, Shannon, Bellman, Breiman, and others—showing how timeless ideas still power today’s systems and help diagnose, adapt, and defend them. While automation (LLMs, AutoML) accelerates workflows, it can also obscure objectives and trade‑offs; the remedy is historical and conceptual fluency. Readers are invited to bring basic statistical and mathematical comfort, and in return gain clear, tool‑agnostic mental models for building trustworthy systems—and, ultimately, the ability to see inside the black box.
The hidden stack of modern intelligence. This conceptual diagram illustrates the layered structure beneath modern intelligence systems, from raw data to philosophical commitments. Each layer represents a critical aspect of data-driven reasoning: how we collect and shape inputs, structure problems, select and apply algorithms, validate results through mathematical principles, and interpret outputs through broader assumptions about knowledge and inference. While the remaining chapters in this book don’t map one-to-one with each layer, each foundational work illuminates important elements within or across them—revealing how core ideas continue to shape analytics, often invisibly.
Summary
- Interpretability is non-negotiable in high-stakes systems. When algorithms shape access to care, credit, freedom, or opportunity, technical accuracy alone is not enough. Practitioners must be able to justify model behavior, diagnose failure, and defend outcomes—especially when real lives are on the line.
- Automation without understanding is a recipe for blind trust. Tools like GPT and AutoML can generate usable models in seconds—but often without surfacing the logic beneath them. When assumptions go unchecked or objectives misalign with context, automation amplifies risk, not insight.
- Foundational works are more than history—they're toolkits for thought. The contributions of Bayes, Fisher, Shannon, Breiman, and others remain vital because they teach us how to think: how to reason under uncertainty, estimate responsibly, measure information, and question what algorithms really know.
- Assumptions are everywhere—and rarely visible. Every modeling decision, from threshold setting to variable selection, encodes a belief about the world. Foundational literacy helps practitioners uncover, test, and recalibrate those assumptions before they turn into liabilities.
- Modern models rest on layered conceptual scaffolding. This book introduces the “hidden stack” of modern intelligence, from raw data to philosophical stance—as a way to frame what lies beneath the surface. While each of the following chapters centers on a single foundational work, together they illuminate how deep principles continue to shape every layer of today’s analytical pipeline.
- Historical literacy is your best defense against brittle systems. In a field evolving faster than ever, foundational knowledge offers durability. It helps practitioners see beyond the hype, question defaults, and build systems that are not only powerful—but principled.
- The talent gap is real—and dangerous. As demand for data-driven systems has surged, the supply of deeply grounded practitioners has lagged behind. Too often, models are built by those trained to execute workflows but not to interrogate their assumptions, limitations, or risks. This mismatch leads to brittle systems, ethical blind spots, and costly surprises. This book is a direct response to that gap: it equips readers not just with technical fluency, but with the judgment, historical awareness, and conceptual depth that today’s data science demands.
 Timeless Algorithms: The Seminal Papers ebook for free
Timeless Algorithms: The Seminal Papers ebook for free