This chapter introduces the central challenge of modern data science: automated systems are increasingly easy to build and deploy, but increasingly difficult to understand. Models can generate predictions, rankings, classifications, and decisions with impressive speed, yet their apparent success can hide fragile assumptions, data drift, bias, poor calibration, or unstable relationships. The chapter argues that accuracy and performance metrics are not the same as reliability or understanding; when conditions change or systems fail, practitioners need more than tool familiarity—they need the judgment to diagnose what happened and decide whether a model can be trusted.
The chapter frames the book as an exploration of the foundational ideas behind modern machine learning and artificial intelligence rather than a guide to coding, libraries, or implementation. It emphasizes that many ideas powering today’s systems were developed long before modern AI: Bayes on updating beliefs, Fisher on estimation, Shannon on information and uncertainty, Vapnik on generalization, Breiman on algorithmic modeling and ensembles, and later work on deep learning, transformers, and scaling. These ideas are presented as practical frameworks for interpreting how models learn from data, represent uncertainty, generalize beyond training examples, and produce outputs that must be understood in context.
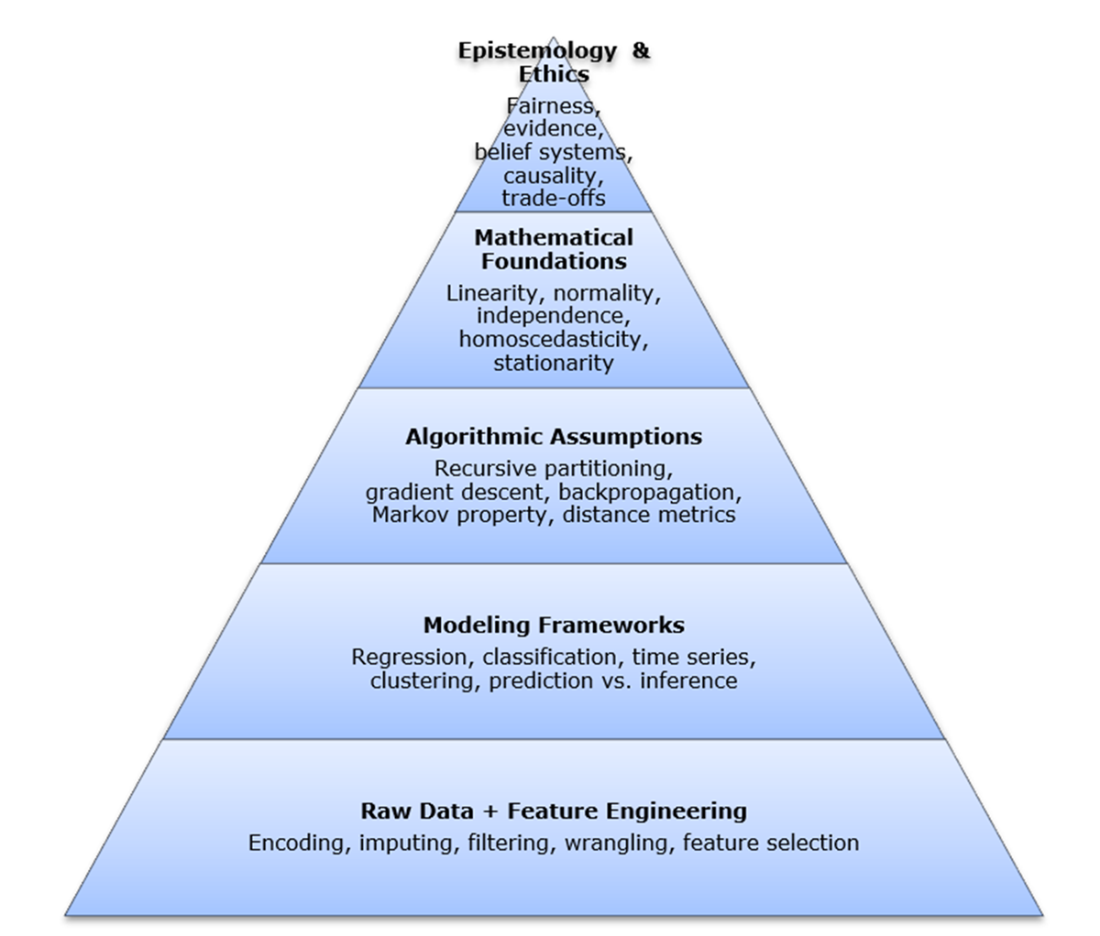
A key organizing concept is a layered view of model behavior: data and features shape what can be observed; modeling frameworks define the task; algorithmic procedures determine how learning occurs; mathematical foundations establish when results are meaningful; and interpretation, judgment, and ethics determine how outputs should be used. By making these layers visible, the chapter shows how a single model output is really the result of many interacting assumptions and decisions. The overall message is that foundational understanding helps practitioners choose models more wisely, diagnose failures, interpret results responsibly, and make better decisions when automated systems stop behaving as expected.
The hidden stack of modern intelligence. This figure presents a layered view of the ideas and assumptions that give structure to data-driven reasoning. From bottom to top, the stack moves from raw data and feature engineering to modeling frameworks, algorithmic assumptions, mathematical foundations, and finally epistemology and ethics. Each layer shapes what can be observed, how problems are framed, how relationships are learned, what conditions must hold for results to be reliable, and how outputs should ultimately be interpreted and used. The foundational works explored in this book do not correspond one-to-one with these layers; instead, each contributes to one or more layers of the stack, thereby helping explain how modern systems reason from data and why their outputs take the forms they do.
Summary
Modern data science has lowered the barrier to building systems, but not to understanding them. Tools can generate results quickly, yet those results depend on assumptions that are often hidden. The central challenge is no longer execution, but interpretation—understanding how results are produced, why they behave as they do, and when they can be trusted.
The foundational ideas explored in this book—spanning probability, estimation, information, generalization, and decision-making—form the intellectual basis of modern data-driven reasoning. Developed across different contexts, many of these ideas now operate together within the same systems, shaping how data is structured, how relationships are defined, and how results are interpreted.
The hidden stack of modern intelligence provides a framework for making this structure visible. By organizing ideas into layers—from data and representation through mathematical structure to epistemology and ethics—it becomes possible to see where assumptions enter, how results are formed, and how different components interact.
Each foundational contribution examined in this book addresses a subset of layers within this stack. These ideas do not function as complete systems on their own; rather, they contribute to specific aspects of a larger structure. Understanding where they operate—and how they connect—bridges the gap between theory and practice.
These ideas are powerful, but not universally applicable. They rely on conditions such as stable patterns, representative data, and well-defined objectives. When those conditions fail, results can degrade—sometimes immediately, and sometimes gradually over time. Using these ideas effectively requires not just applying them, but recognizing when their assumptions hold and when they do not.
FAQ
What is the main problem described in chapter 1, “Seeing inside the black box”?The chapter argues that modern data science has created a gap between execution and understanding. Today, tools can generate code, select algorithms, and produce results quickly, but practitioners may not understand why a model behaves as it does, when it can be trusted, or how to diagnose failures when conditions change.Why does the chapter compare modern data science to flying a plane on autopilot?The autopilot metaphor illustrates the risk of relying on automated systems without understanding them. As long as everything works, the system appears trustworthy. But when sensors fail, assumptions break, or the model stops performing reliably, someone must be able to take control. In data science, that means understanding the model well enough to diagnose problems and make corrective decisions.Why is model performance not the same as model understanding?A model can achieve high accuracy while relying on unstable, biased, spurious, or context-dependent patterns. Performance metrics describe how a model behaved on a particular data set, but they do not guarantee that the model will remain reliable in production or under new conditions. Accuracy shows that a model worked in one setting; understanding explains why it worked and whether it is likely to keep working.What is data drift, and why does it matter?Data drift occurs when the conditions surrounding a model change after deployment. Customer behavior, economic environments, measurement practices, or data collection methods may shift, weakening relationships the model learned from historical data. Because drift often happens gradually and quietly, a model may continue producing confident outputs even as its reliability declines.What does the chapter mean by the difference between knowledge and wisdom?Knowledge means knowing what tool to use, which function to call, which model to run, or which metric to report. Wisdom means being able to interpret results, question assumptions, recognize failure modes, and decide when a model should or should not be trusted. The chapter argues that modern practitioners need wisdom, not just technical execution.What is this book about, and what is it not about?The book is about the foundational ideas behind modern data science and AI, such as Bayesian reasoning, likelihood, information theory, generalization, ensemble learning, dynamic programming, deep learning, and transformers. It is not a programming guide, a software tutorial, or a collection of historical essays. Its goal is to make model behavior intelligible, not to teach step-by-step implementation.Who is the intended audience for the book?The book is written for practitioners who work with models or rely on their outputs, including data scientists, analysts, machine learning engineers, and decision-makers. It assumes familiarity with basic concepts but does not require advanced mathematical training. Mathematics is used as a tool for understanding rather than as an end in itself.What is the “hidden stack of modern intelligence”?The hidden stack is a conceptual framework for understanding what happens beneath the surface of modern learning systems. It organizes data-driven systems into layers: raw data and feature engineering, modeling frameworks, algorithmic assumptions, mathematical foundations, and epistemology and ethics. Each layer introduces assumptions that shape what the system can learn, how results are produced, and how outputs should be interpreted.What are the layers of the hidden stack?The stack begins with raw data and feature engineering, where inputs are collected, cleaned, encoded, and selected. Above that are modeling frameworks, which define the task, such as classification or regression. Algorithmic assumptions determine how procedures process data and produce results. Mathematical foundations define when results are stable, meaningful, and trustworthy. At the top, epistemology and ethics determine how outputs are interpreted, how uncertainty is understood, and how decisions should be made.Why do foundational ideas still matter for modern AI systems?Modern systems may appear new, but they are built on older ideas about probability, estimation, uncertainty, information, generalization, and decision-making. Bayes, Fisher, Shannon, Vapnik, Breiman, and others developed principles that still shape models ranging from logistic regression and random forests to neural networks and large language models. Understanding these foundations helps practitioners select models more carefully, diagnose failures, interpret outputs correctly, and make better decisions.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Timeless Algorithms: The Seminal Papers ebook for free
Timeless Algorithms: The Seminal Papers ebook for free