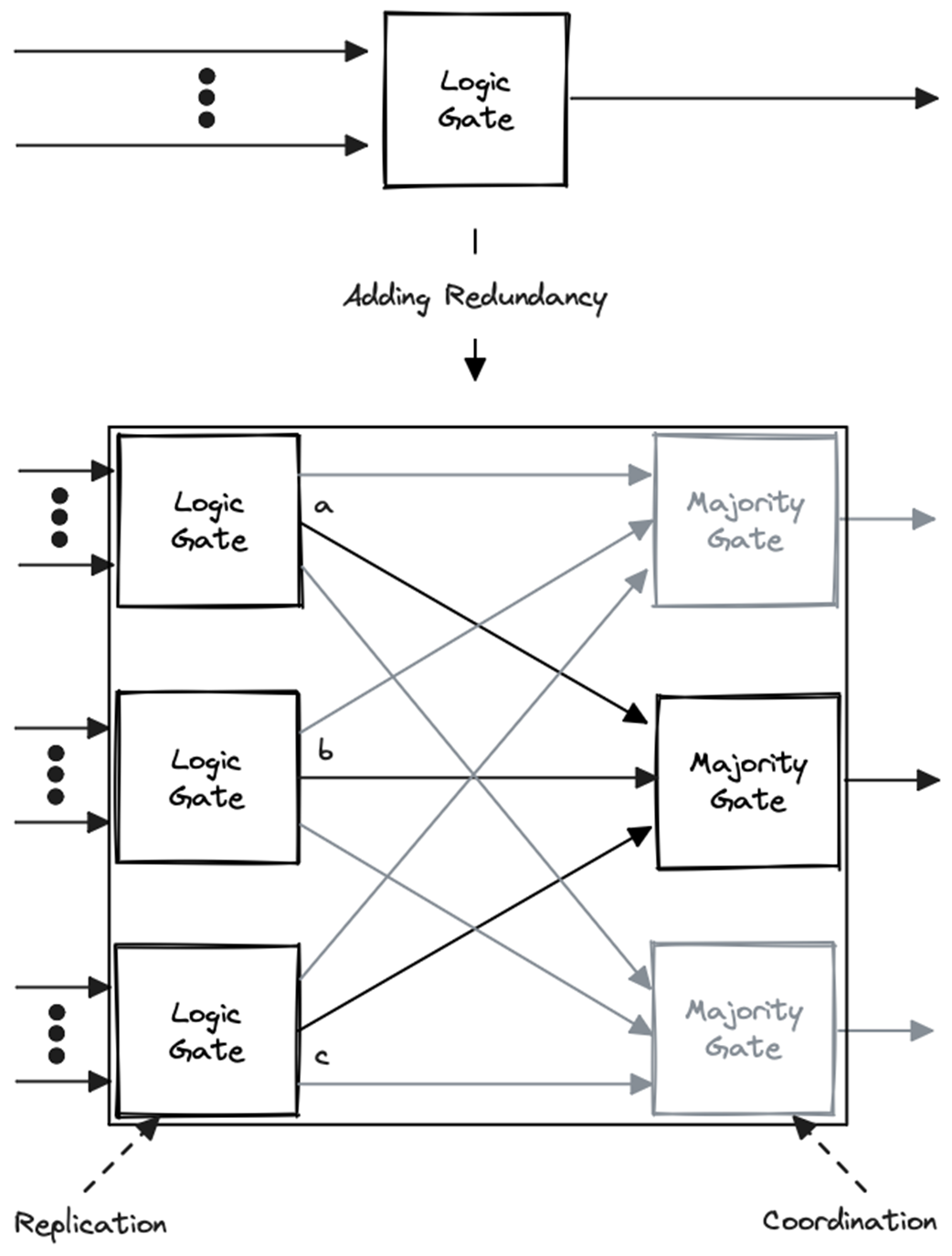
Distributed systems rely on redundancy to uphold durability and avoid “backtracking” on committed outcomes when components fail. The chapter frames redundancy as both duplication and coordination: simply adding more components is insufficient unless their behavior is orchestrated—ranging from simple load balancing to majority voting or full consensus. It distinguishes static (unchanging structure, common in hardware) from dynamic redundancy (evolving structure, common in software), illustrates fault masking via triple modular redundancy, and motivates replication as the most common software embodiment of duplication-plus-coordination aimed at reliability (with nuanced effects on scalability).
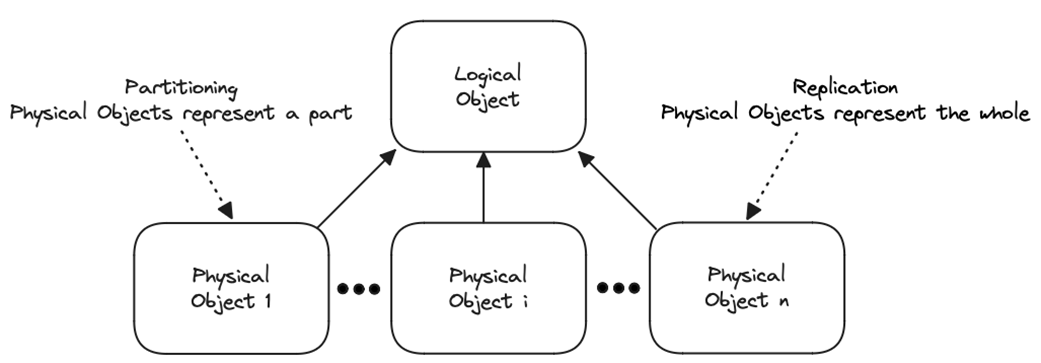
Replication represents one logical object with multiple identical physical replicas while striving for replication transparency—the illusion of a single object—despite real trade-offs among consistency, availability, and latency. The chapter spotlights the subtle question of “one thing” (identity and equivalence): multiple copies or editions may or may not be considered the “same,” mirroring the central challenge of consistency—do replicas faithfully represent the logical item? This perspective prepares engineers to reason about what guarantees users actually perceive when interacting with replicated data and services.
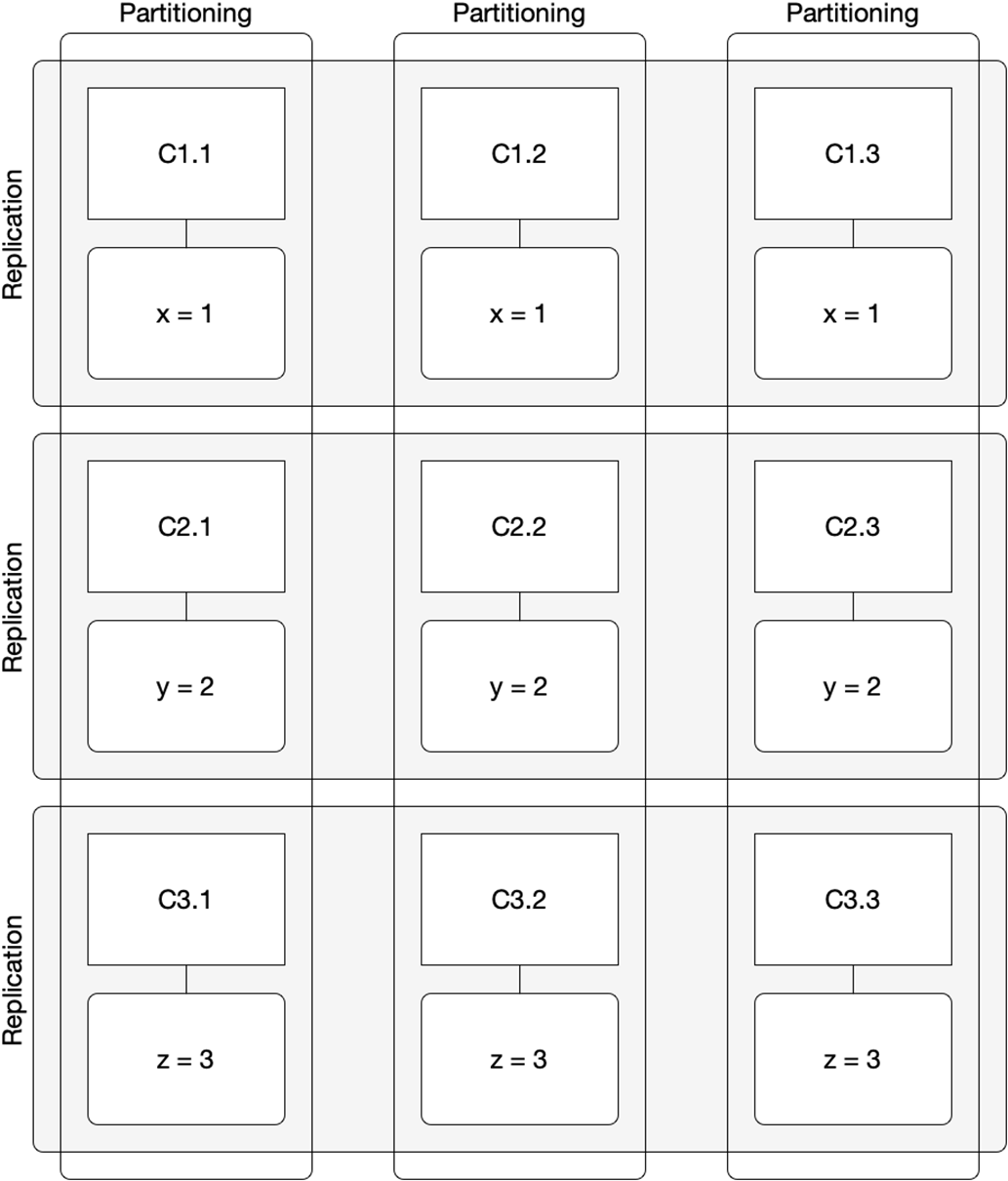
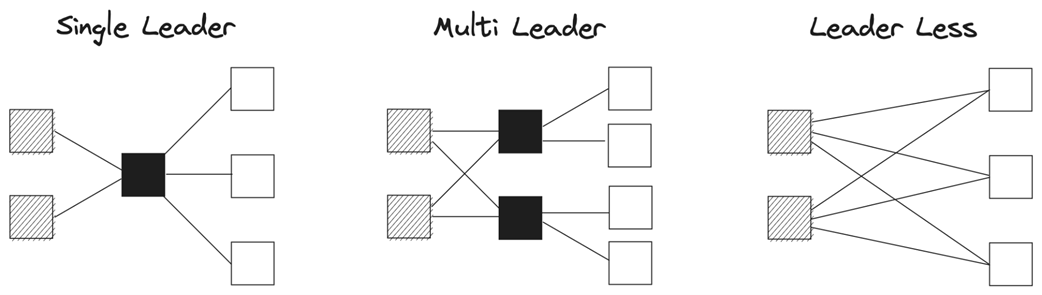
The mechanics focus on stateful replication, where change propagation drives complexity. The system model assumes partial synchrony, crash and omission failures, and point-to-point links that can partition. Replication lag is inherent (sequential propagation is unavoidable) and can be further imposed by failures; its visibility erodes transparency. Systems choose between synchronous, asynchronous, or quorum-based hybrids; replicate either state or operation logs (with deterministic state machines, log-based approaches prevailing in practice); and organize leadership as single-leader, multi-leader, or leader-less, each necessitating conflict resolution (for example, last-write-wins vs. CRDTs) with nontrivial trade-offs. A key operational caveat is that followers serving reads can return stale data under lag, so “leaders for writes, followers for reads” must be weighed against freshness requirements.
Redundancy as duplication and coordination
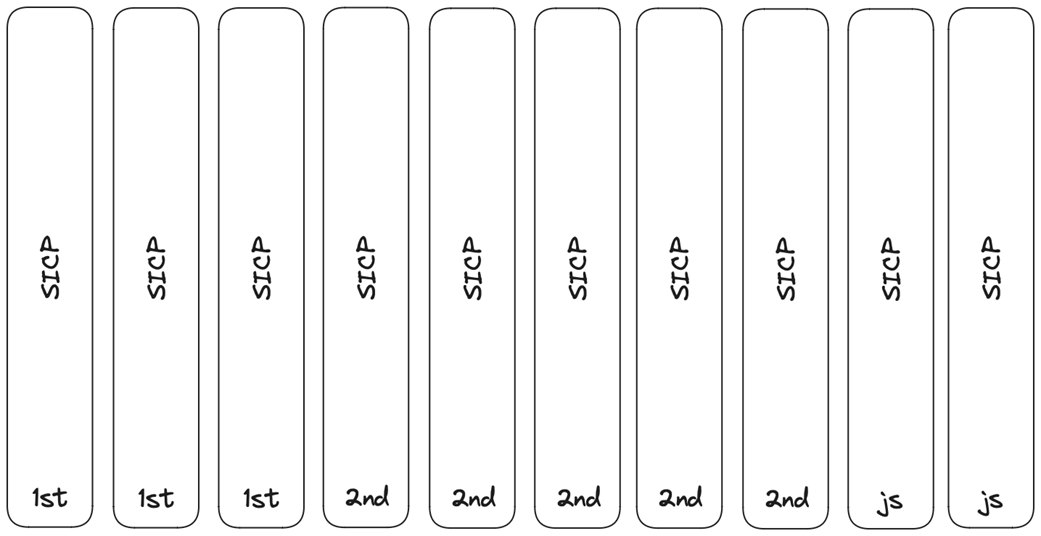
Library inventory of Structure and Interpretation of Computer Programs
Replication represents a single logical object by multiple, identical physical objects.
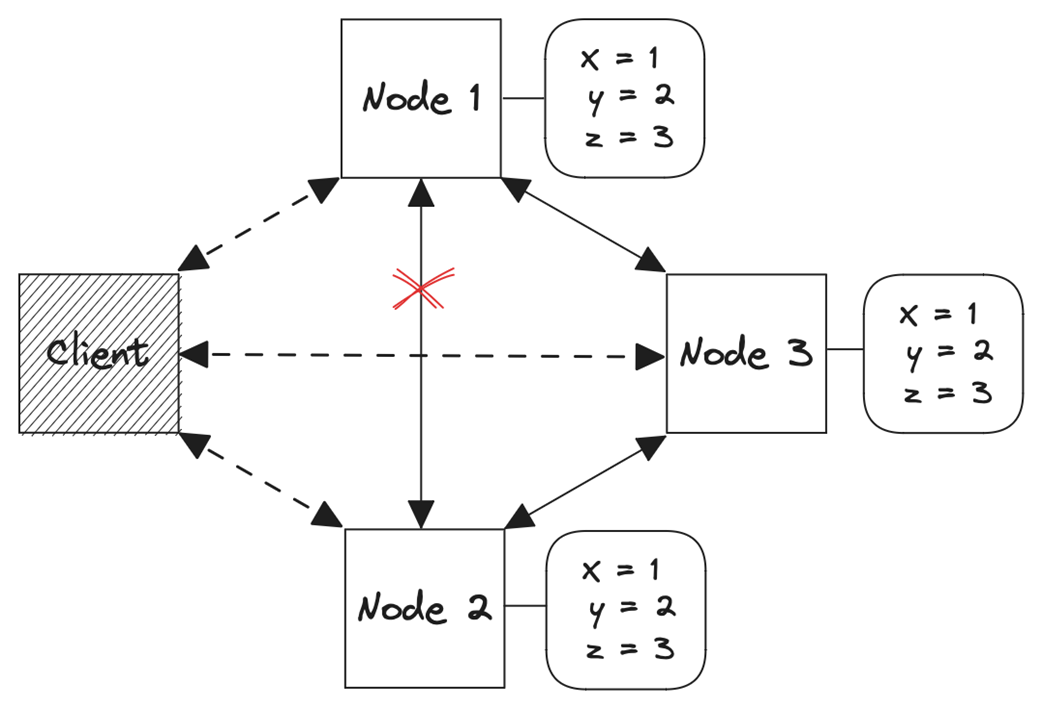
A replicated key-value store
The network as point-to-point communication links between components
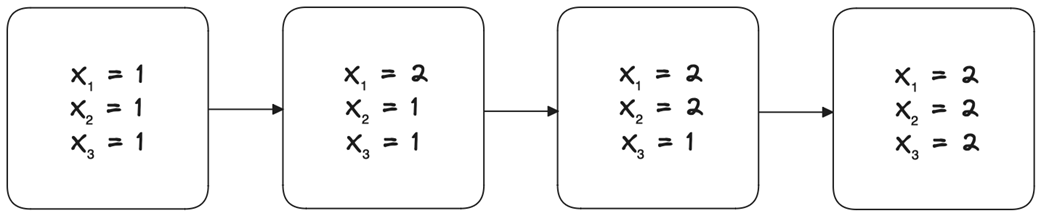
Replication lag: Instantaneous propagation of changes is impossible, resulting in an inherent lag.
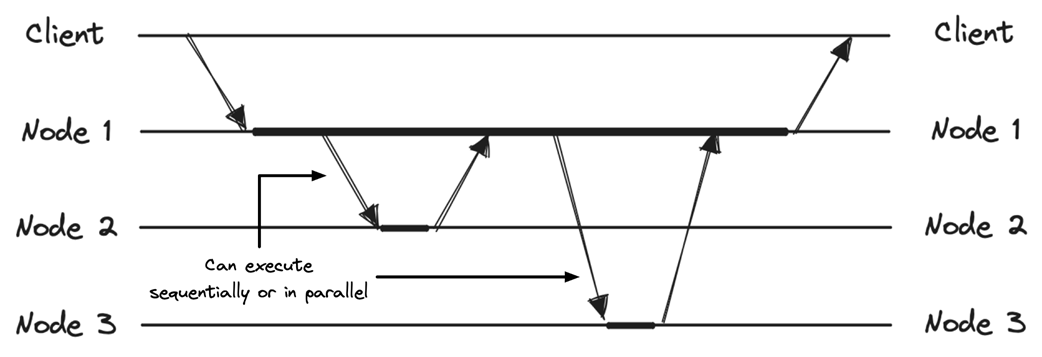
Synchronous replication
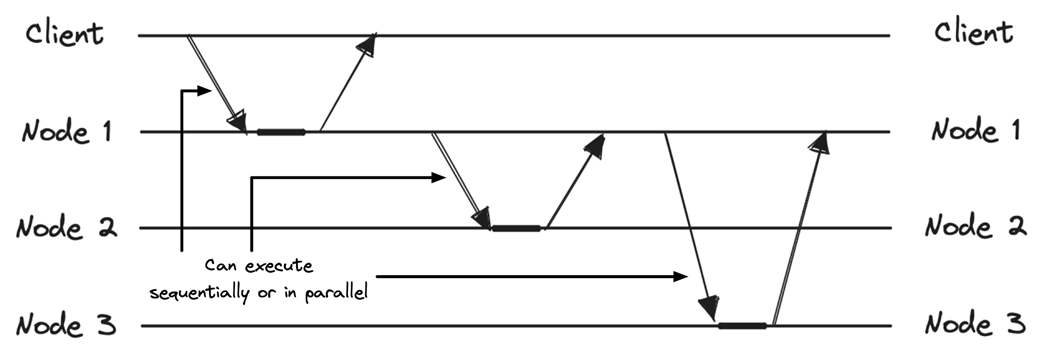
Asynchronous replication
Single-leader, multi-leader, and leader-less.
Summary
Redundancy aims to improve the reliability of a system, growing beyond the reliability limits of a single resource.
Redundancy refers to the duplication and coordination of subsystems, so that an increase in the duplication factor results in increased reliability.
Static redundancy refers to redundancy where the set of components and their interactions do not change, while dynamic redundancy refers to redundancy where they do change.
Replication, the employment of multiple instances of “the same thing,” is the most common implementation of duplication.
Replication improves the reliability of distributed systems by distributing data across multiple resources, overcoming the limitations of a single resource.
Replication lag is an inherent aspect of distributed systems and complicates replication transparency and consistency.
Synchronous replication ensures consistency but may impact latency and availability, while asynchronous replication improves latency and availability but may impact consistency.
State-based replication propagates the current state of the system, while log-based replication propagates the sequence of operations leading to the state.
FAQ
What does “durability” mean in ACID, and why does backtracking matter in distributed systems?Durability guarantees that once a transaction commits, its effects are permanent. Backtracking—going back on a committed promise—breaks business expectations (for example, shipping goods after a payment “commit” that later disappears). Because components can fail in real systems, we add redundancy to avoid single points of failure and preserve durability.How do redundancy and scalability relate?Redundancy primarily improves reliability by duplicating and coordinating subsystems. It can also aid scalability by distributing data and allowing load partitioning across replicas. However, redundancy can sometimes decrease scalability, so the relationship is not straightforward.What is the difference between static and dynamic redundancy?Static redundancy keeps both the set of components and their interactions fixed over the system’s lifetime (common in hardware). Dynamic redundancy allows components and interactions to change at runtime (common in software), requiring ongoing coordination.Why is coordination as important as duplication in redundancy?Duplicating components alone does not make a system. The duplicates must be coordinated so they behave like a coherent whole—ranging from simple round-robin load balancing to complex consensus. Coordination is what turns a collection of parts into a reliable system.How does the logic-gate majority example illustrate redundancy?Replacing one logic gate with three replicas and a majority gate lets the system tolerate one replica’s failure: the majority output reflects the correct value if at least two replicas agree. To avoid a new single point of failure, even the majority gate is replicated. This shows duplication plus coordination improving reliability.What is meant by “one logical object” and why is identity/equivalence tricky?Replication represents a single logical object with multiple physical copies. Deciding what counts as “the same thing” can be nuanced (like book editions differing by language or content). Replication and consistency hinge on whether replicas faithfully represent the same logical item, which depends on your chosen notion of identity and equivalence.What is replication transparency and when does it break down?Replication transparency hides the existence of multiple replicas, making the system appear as one object. It becomes harder to maintain under replication lag and network partitions, forcing trade-offs among consistency, availability, and latency, and sometimes revealing the replication details to clients.What is replication lag, and what are “inherent” vs “imposed” lag?Replication lag is the unavoidable delay in propagating changes across replicas because updates occur sequentially, not instantaneously. Inherent lag comes from the nature of distributed systems; imposed lag comes from partitions or component failures. Both can surface stale reads and reduce transparency.How do synchronous and asynchronous replication differ, and what is a quorum?Synchronous replication waits for all required acknowledgments before completing an operation, yielding immediate consistency but potentially higher latency and lower availability. Asynchronous replication returns as soon as the leader applies the change, reducing latency but risking staleness. Many systems use quorums: they wait for a majority to ack in the foreground, then propagate to remaining replicas in the background.What’s the difference between state-based and log-based replication, and why must the state machine be deterministic?State-based replication sends (diffs of) the current state; log-based replication sends the sequence of operations. Determinism is required so replicas that start from the same state and apply the same operations in the same order reach the same state. In practice, log-based replication is widely favored.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free