3 Failure tolerance
This chapter develops a clear way to think about failure in distributed systems, with the goal of achieving failure tolerance—keeping behavior well-defined even when things go wrong. A failure is framed as an unwanted but possible transition that moves the system from a legal (good) state to an illegal (bad) state, distinct from intolerable states where recovery isn’t feasible. Correctness is expressed through safety (nothing bad happens) and liveness (something good eventually happens). In failure-free conditions both hold, but under failure we may have to trade them off while guiding recovery from illegal back to legal states.
Using safety and liveness, the text classifies failure tolerance into four modes: masking (both safety and liveness preserved), non-masking (liveness preserved, safety may be violated), fail-safe (safety preserved, liveness may halt), and not tolerant (neither preserved). Masking offers failure transparency but can be impossible or too costly; for example, partitions may force choosing between consistency and availability. The chapter also links detection and mitigation to these properties: detecting failures underpins safety by preventing dangerous actions, while mitigating failures underpins liveness by restoring progress—an interplay visible in quorum-based protocols that pause when out of quorum and resume once healthy.
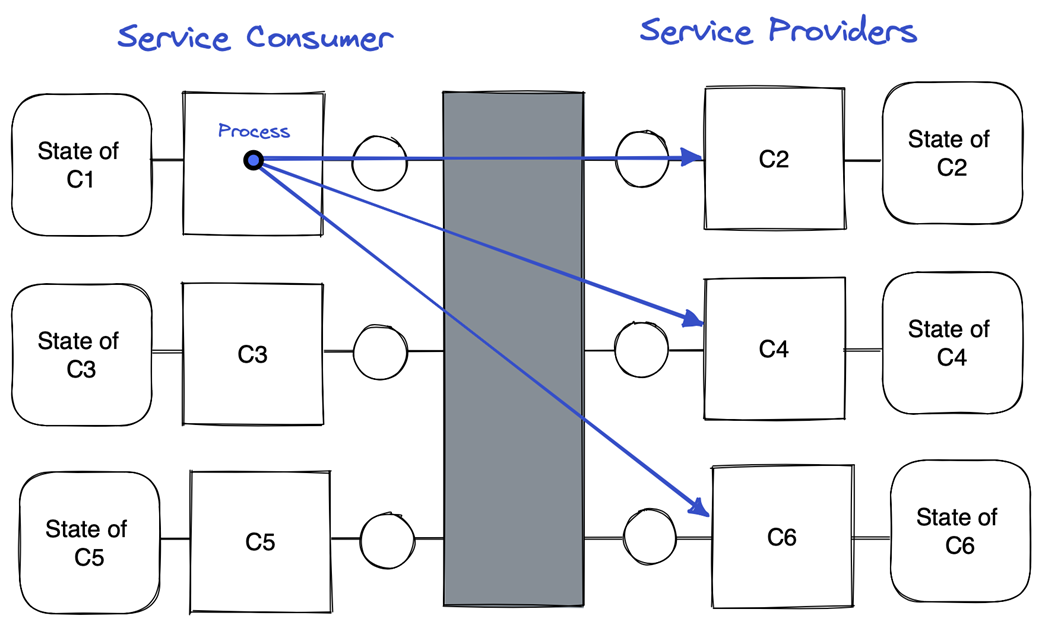
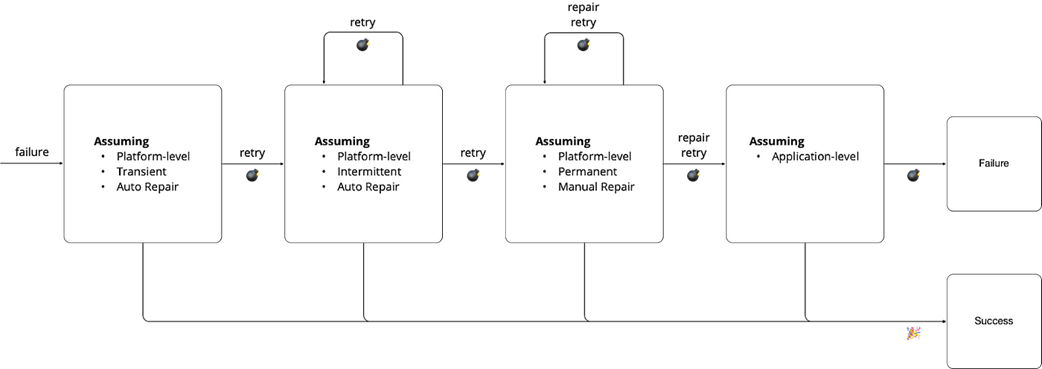
On the practical side, the chapter adopts a service-orchestration view (a consumer coordinating provider calls) and applies the end-to-end argument to place handling at the lowest layer that can correctly and completely do so. Spatially, failures are application-level (e.g., business errors like insufficient funds) or platform-level (e.g., connectivity), and temporally they are transient, intermittent, or permanent, with differing probabilities of recurrence and repair paths. Detection ranges from inspecting return codes to heartbeat/timeout mechanisms, which in unreliable, asynchronous settings cannot be both complete and accurate. Mitigation combines forward recovery (platform-led retries: immediate, backoff, or suspend-and-resume after manual fix) and backward recovery (application-led compensation) to ensure processes are either completed correctly or cleanly undone; if mitigation fails, escalate to the application and, ultimately, to human operators.
System states and state transitions
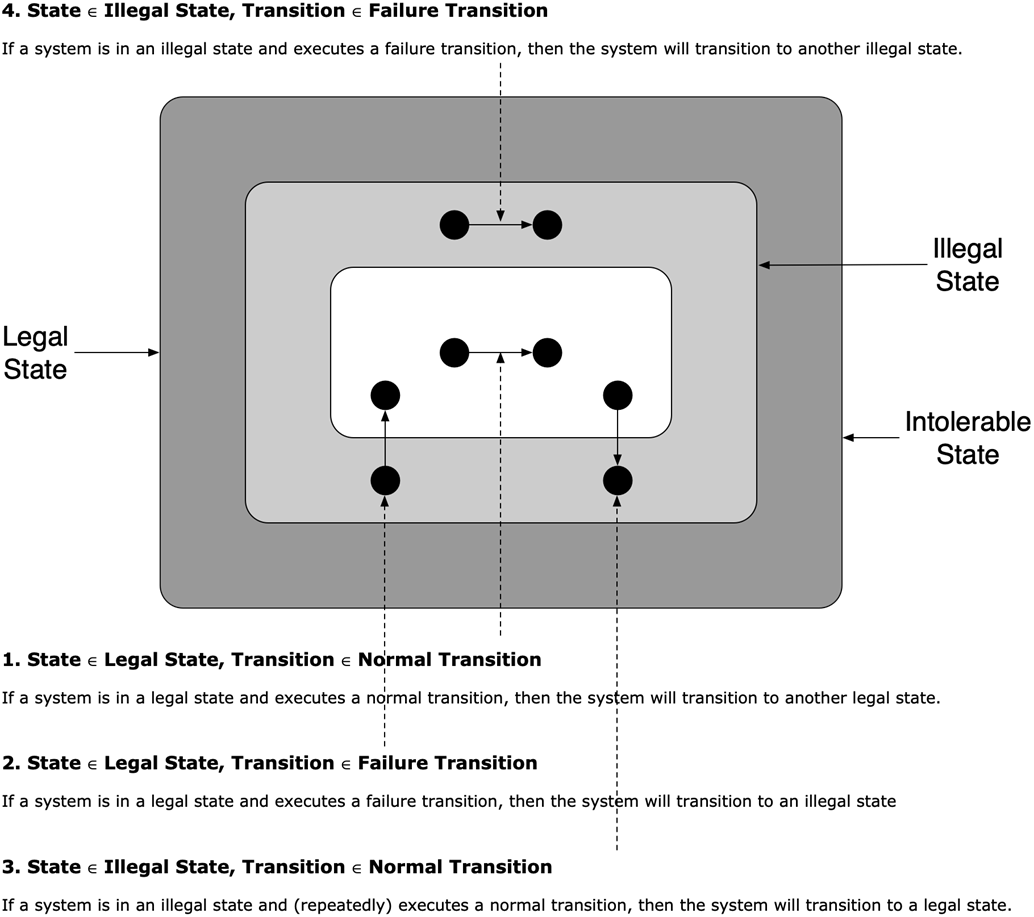
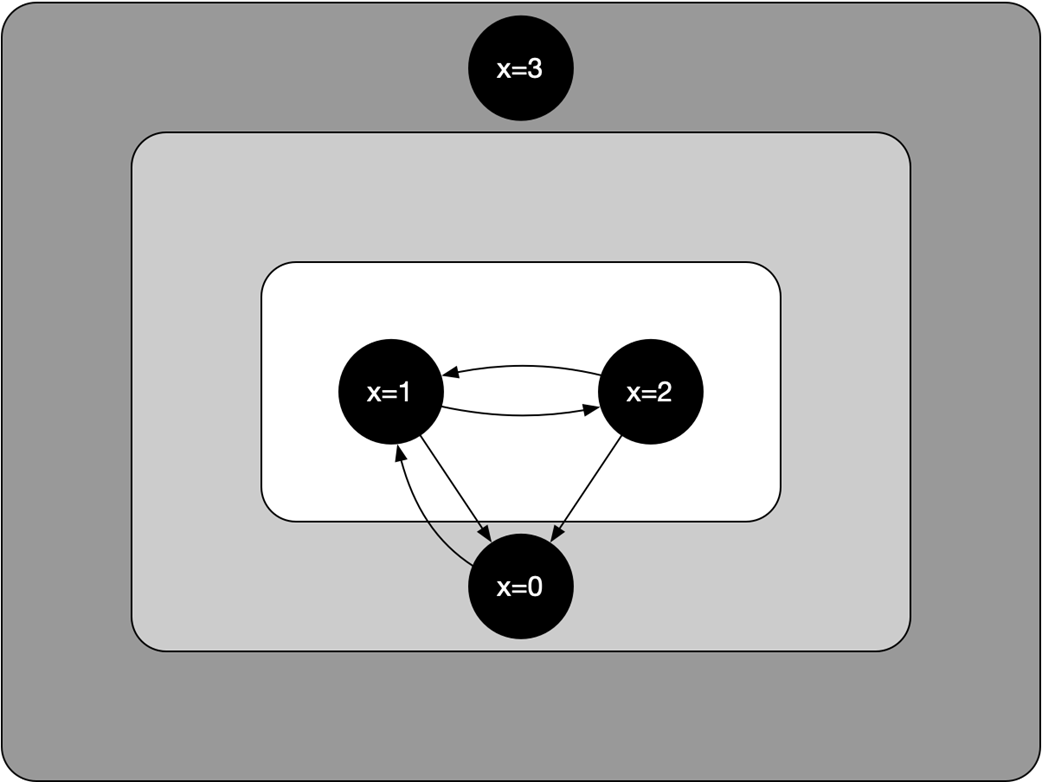
An illustration of the states and state transitions defined in Listing 3.1
Service orchestration
A process as a sequence of steps

E-commerce process

Failure handling
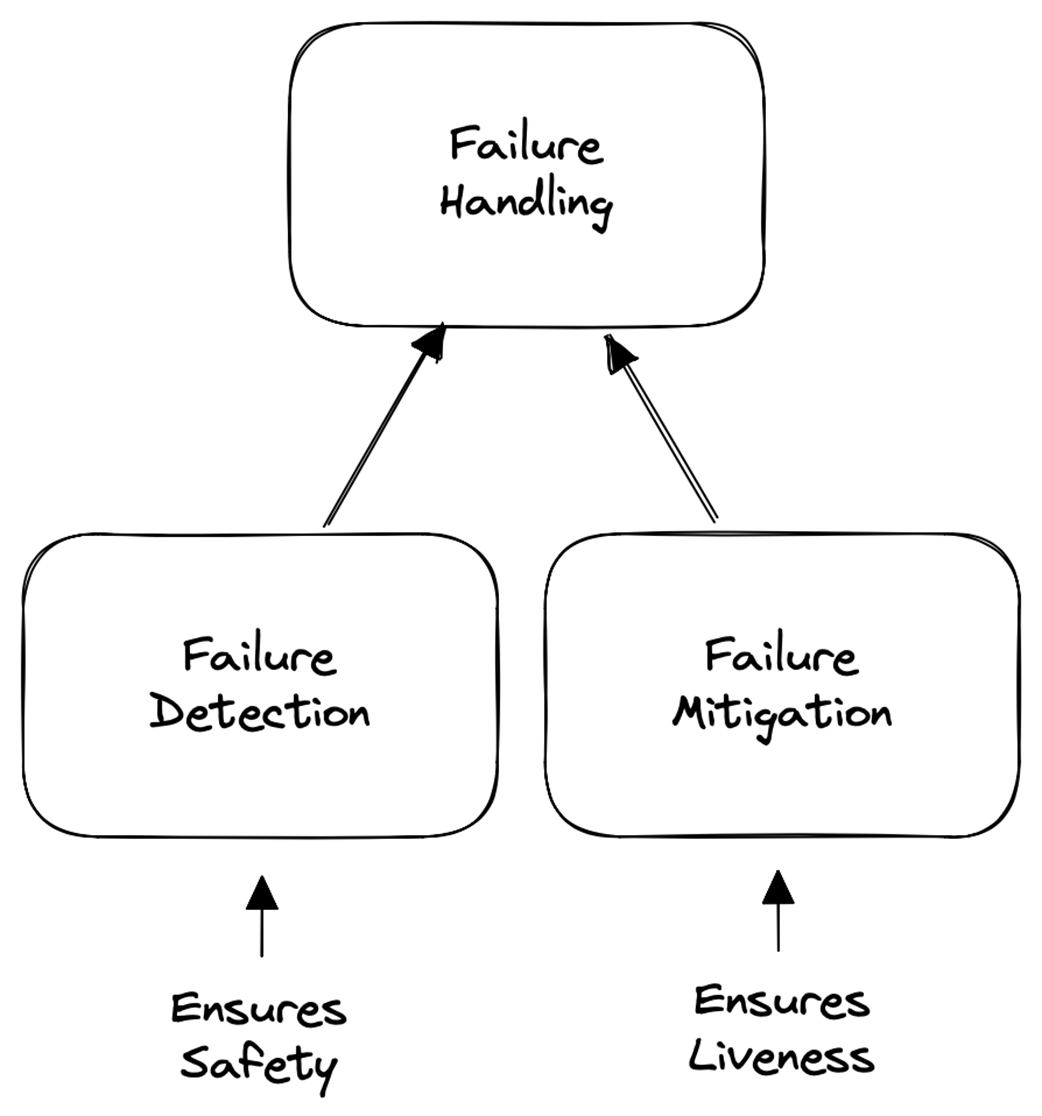
Failure classification
Thinking in layers
Spatial classification
Application-level versus platform-level failure
Temporal dimension
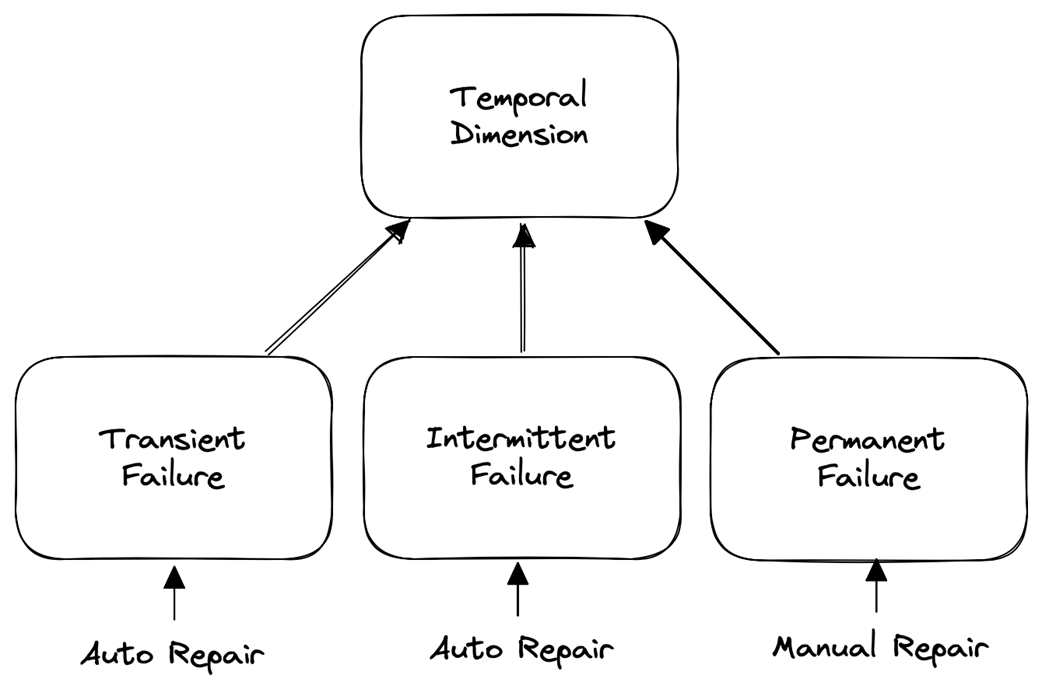
Transient failure
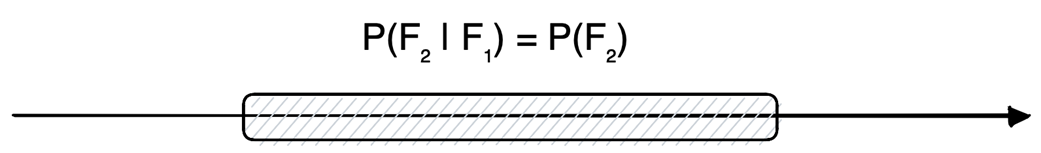
Intermittent failure

Permanent failure
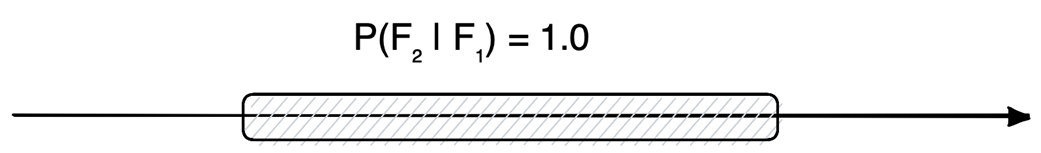
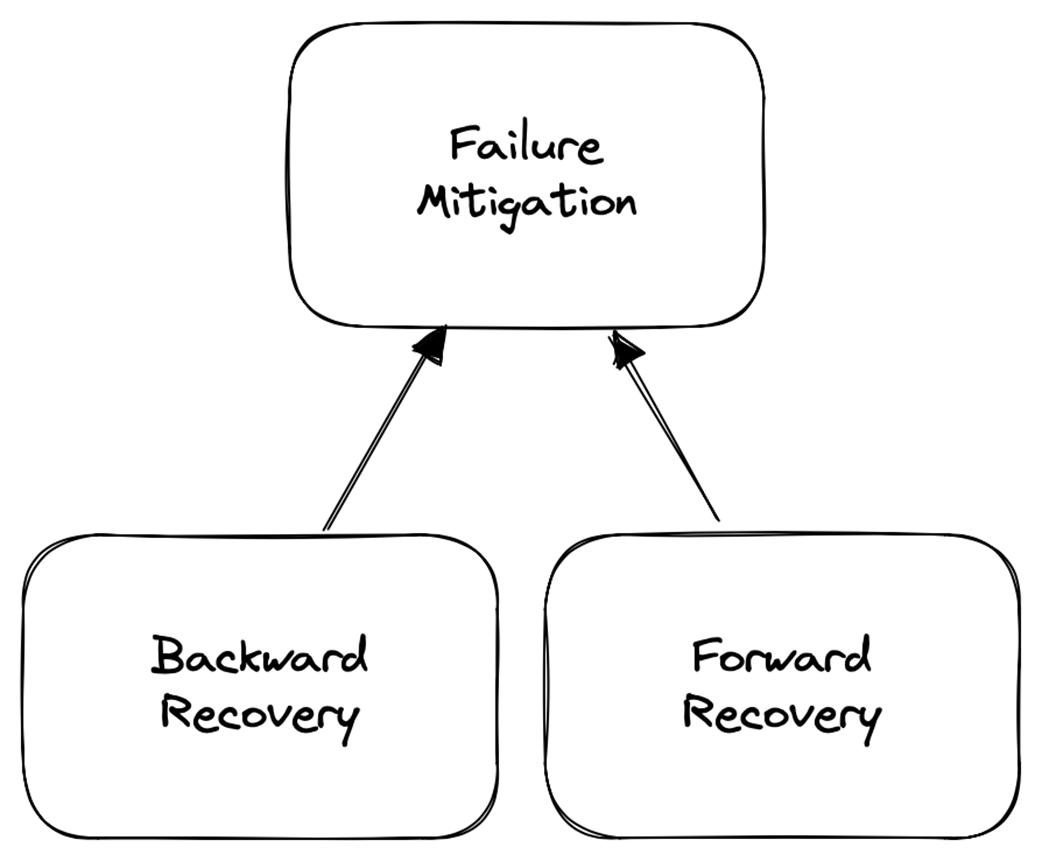
Failure mitigation
Outline of failure-handling strategy in an orchestration scenario
Summary
- Failure tolerance is the goal of failure handling.
- Failure handling involves two key steps: failure detection and failure mitigation.
- Failures can be classified across two dimensions: spatial and temporal.
- Spatially, failures are classified as application-level or platform-level.
- Temporally, failures are classified as transient, intermittent, or permanent.
- Different failure tolerance strategies, such as masking, non-masking, and fail-safe, address the safety and liveness of the system.
- Failure detection and mitigation strategies vary based on the classification of the failure and the desired class of failure tolerance.
FAQ
What do “failure” and “failure tolerance” mean in this chapter?
A failure is an unwanted but possible state change that moves a system from a good (legal) state to a bad (illegal) state. Failure tolerance is the ability of the system to keep behaving in a well-defined way even while it’s in a bad state, and to recover back to a good state.How are system states and transitions modeled?
- States: legal (good), illegal (bad), and intolerable (beyond recovery).- Transitions: normal transitions (intended evolution) and failure transitions (unintended moves into illegal states).
- Recovery: the sequence that returns the system from an illegal state to a legal one. Intolerable states are out of scope because they cannot be tolerated.
How do safety and liveness shape types of failure tolerance?
- Safety: nothing bad happens (e.g., no corruption, no rule violation).- Liveness: something good eventually happens (e.g., progress completes).
Combinations under failure yield four cases: safe+live (masking), live+not safe (non-masking), safe+not live (fail-safe), and neither (not failure tolerant). Detection typically protects safety (stop risky actions), while mitigation restores liveness (resume progress).
What’s the difference between masking, non-masking, and fail-safe tolerance?
- Masking: preserves both safety and liveness despite failures (failure is hidden); often costly or impossible in some settings.- Non-masking: preserves liveness but may violate safety during failure. Example: a FIFO queue keeps delivering but may reorder while the failure lasts.
- Fail-safe: preserves safety but may halt progress. Example: the same queue stops delivering to avoid reordering until the failure clears.
Why is “completeness” of a process so important in practice?
In orchestration, a process is a series of steps (requests to providers). Partial execution is undesirable: either all intended effects should occur (forward to the goal) or none should be observable (rollback to the start). This mirrors database atomicity: incomplete means incorrect for the overall outcome.Where should failure handling live: application layer or platform layer?
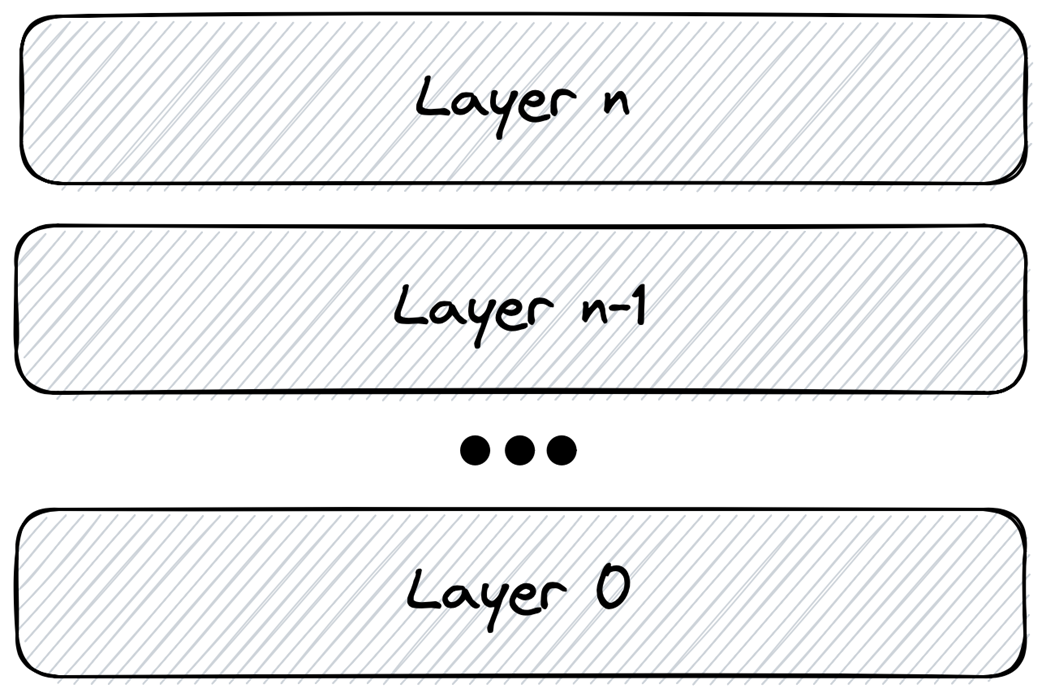
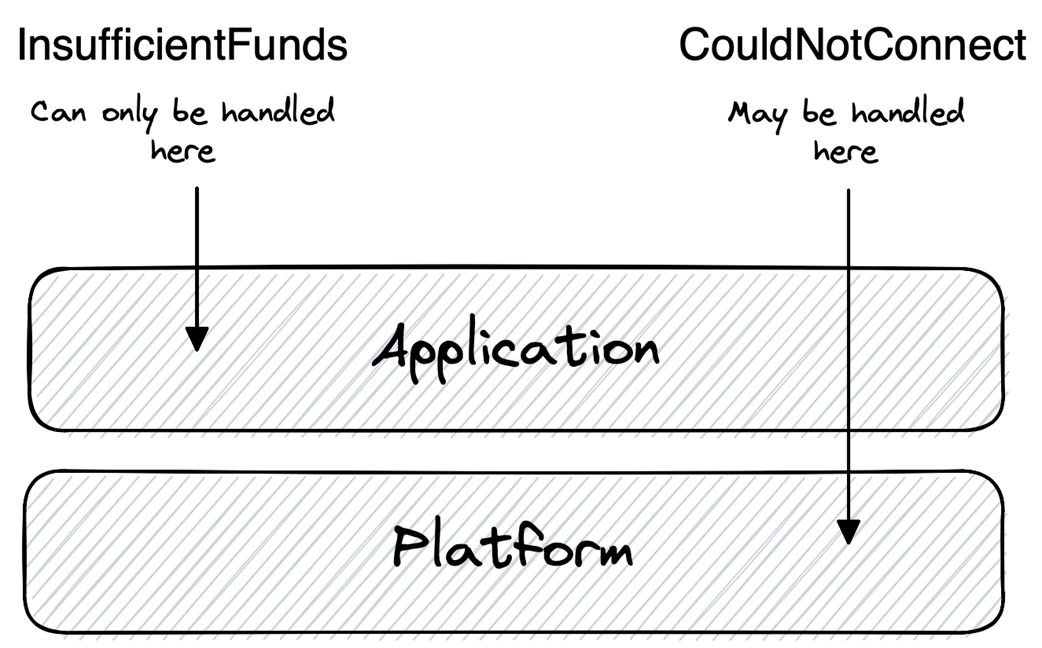
The end-to-end view says: place handling in the lowest layer that can fully and correctly detect and mitigate the failure.- Application-level failure: requires domain meaning to fix (e.g., InsufficientFunds).
- Platform-level failure: best handled by the platform (e.g., CouldNotConnect via retry/connectivity logic). If a failure can’t be unambiguously tagged as application-level, treat it as platform-level first.
What are transient, intermittent, and permanent failures, and how do they resolve?
- Transient: brief, self-healing; a second failure is no more likely than usual. Example: router restarts, then connections succeed again.- Intermittent: lingers and recurs; a second failure is more likely until the condition clears on its own (e.g., delayed routing updates).
- Permanent: persists until manual repair; a second failure is effectively certain (e.g., expired certificate until replaced).
How do failure detectors work, and why can’t they be perfect in asynchronous systems?
Detectors exchange messages between observer and observed:- Pull: observer pings and expects a reply in time.
- Push: observed sends periodic heartbeats.
Timeouts act as the predicate for suspicion. In unreliable or asynchronous networks, delayed or lost messages are indistinguishable from crashes, so you can’t have both complete (no misses) and accurate (no false suspicions) detection simultaneously.
What’s the difference between backward and forward recovery?
- Backward recovery: move back to a state equivalent to “not applied” (e.g., compensating actions like refunding a charge). Often doesn’t require fixing the underlying cause.- Forward recovery: push through to a state equivalent to “fully applied” (e.g., retries, failover). Typically requires addressing the root cause (e.g., reestablishing connectivity).
What is the chapter’s recommended failure-handling playbook for orchestration?
- If not clearly application-level, assume platform-level first:1) Treat as transient → immediate retry.
2) If it persists, treat as intermittent → multiple retries with backoff.
3) If it still persists, treat as permanent → pause, repair manually, then resume and retry.
- If platform mitigation ultimately fails, surface to the application for compensation (backward recovery). If compensation itself fails, escalate to operators (human intervention).
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free