1 Thinking in distributed systems: Models, mindsets, and mechanics
Modern software is inherently distributed to varying degrees, and we build distributed systems because no single component can handle unbounded load or survive inevitable failures. This chapter frames a distributed system as concurrent components that communicate by exchanging messages, where both behavior and complexity emerge from interactions. It argues that success requires moving from “knowing” terms to truly “understanding” through accurate, concise mental models—tools that cut through industry ambiguity and enable confident reasoning about functionality, scalability, and reliability.
The chapter defines mental models as internal representations used for comprehension and communication, and characterizes good models as both correct (no falsehoods) and complete (no relevant omissions). It shows that multiple, equally valid models may describe the same system—sometimes equivalently, sometimes emphasizing different aspects. Behavior is helpfully viewed as a state machine advancing in discrete steps taken by components or the network, and correctness is rigorously expressed via safety (nothing bad happens) and liveness (something good eventually happens). Scalability and reliability are reframed as responsiveness under load and failure, grounded in SLIs, SLOs, error rates, and error budgets; importantly, such guarantees are application-specific and emergent from component interactions.
Two big ideas shape the mindset: systems-of-systems (holons/holarchies) that let us zoom in and out of abstraction boundaries, and the contrast between global and local views—an omniscient observer versus components with only local knowledge. The core challenge is to think globally yet act locally, e.g., avoiding split-brain while each participant follows only a local algorithm. To make mechanics tangible, the “Distributed Systems Inc.” office metaphor maps components, network, and external interfaces to rooms, pneumatic tubes, and mailboxes, illustrating failure and delivery semantics while reminding us to use analogies critically. Finally, the chapter urges thinking above code by adopting minimal process models to reason about concurrency, race conditions, and serializability—showing how precise mental models yield clarity and confidence in designing functional, scalable, and reliable systems.
Mental model and system

Different models describing the same aspects of a system (the set of facts of each model totally overlaps)

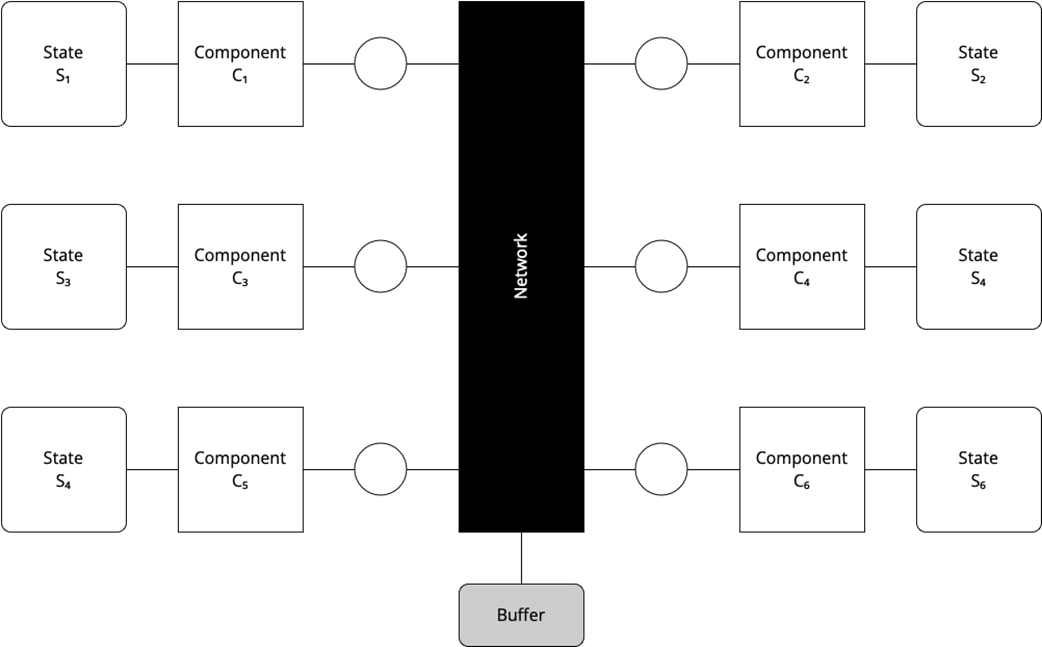
The network as the buffer of inflight messages
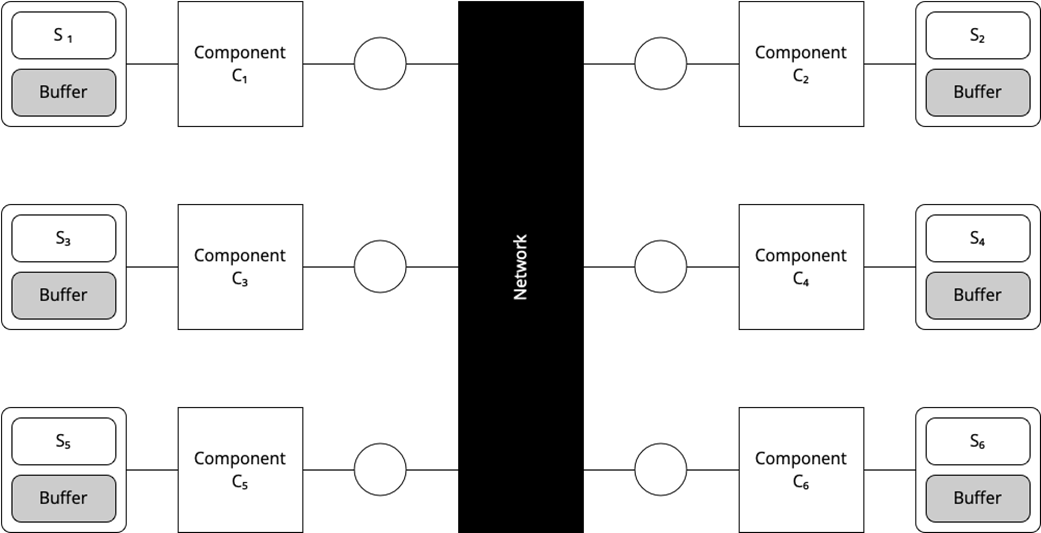
The components as the buffer for inflight messages
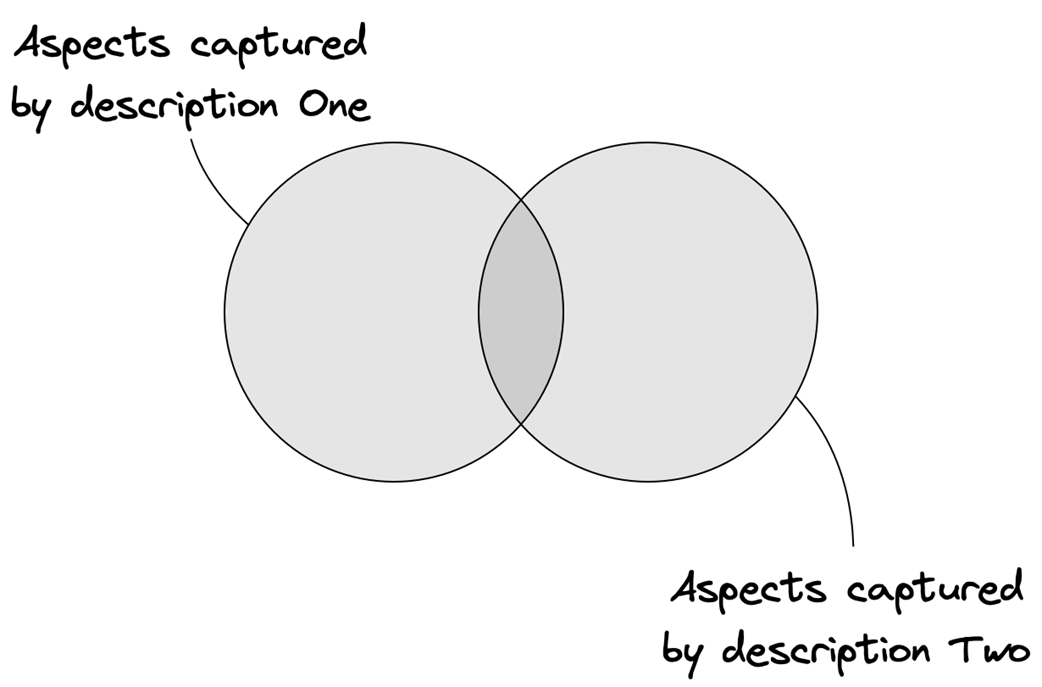
Different models describing different aspects of a system (the set of facts of each model partially overlaps)
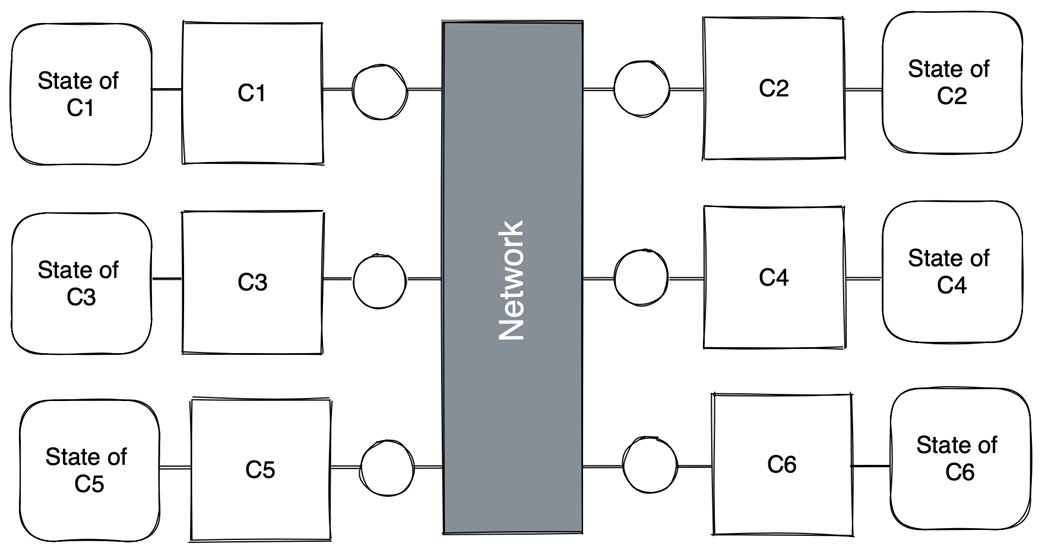
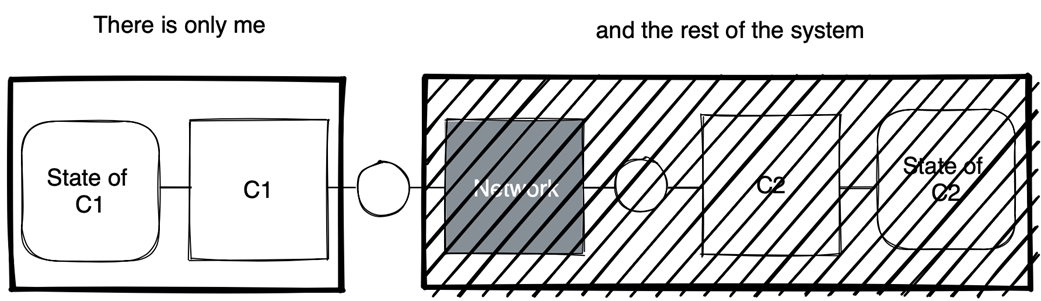
A distributed system as a set of concurrent, communicating components (local state of network not shown)
Behavior of a system as a sequence of states

Safety and liveness
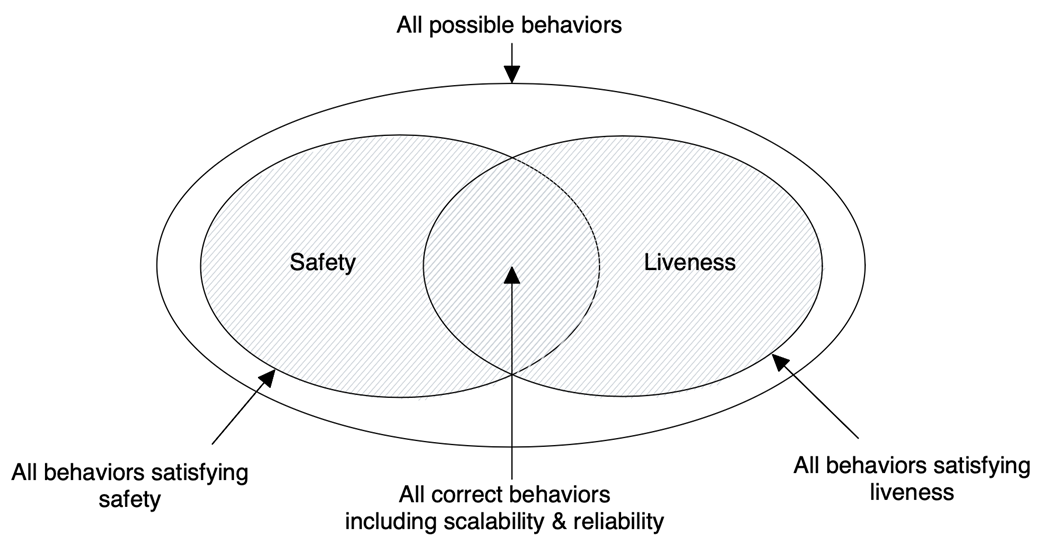
Behavior space of a distributed transaction with two participants
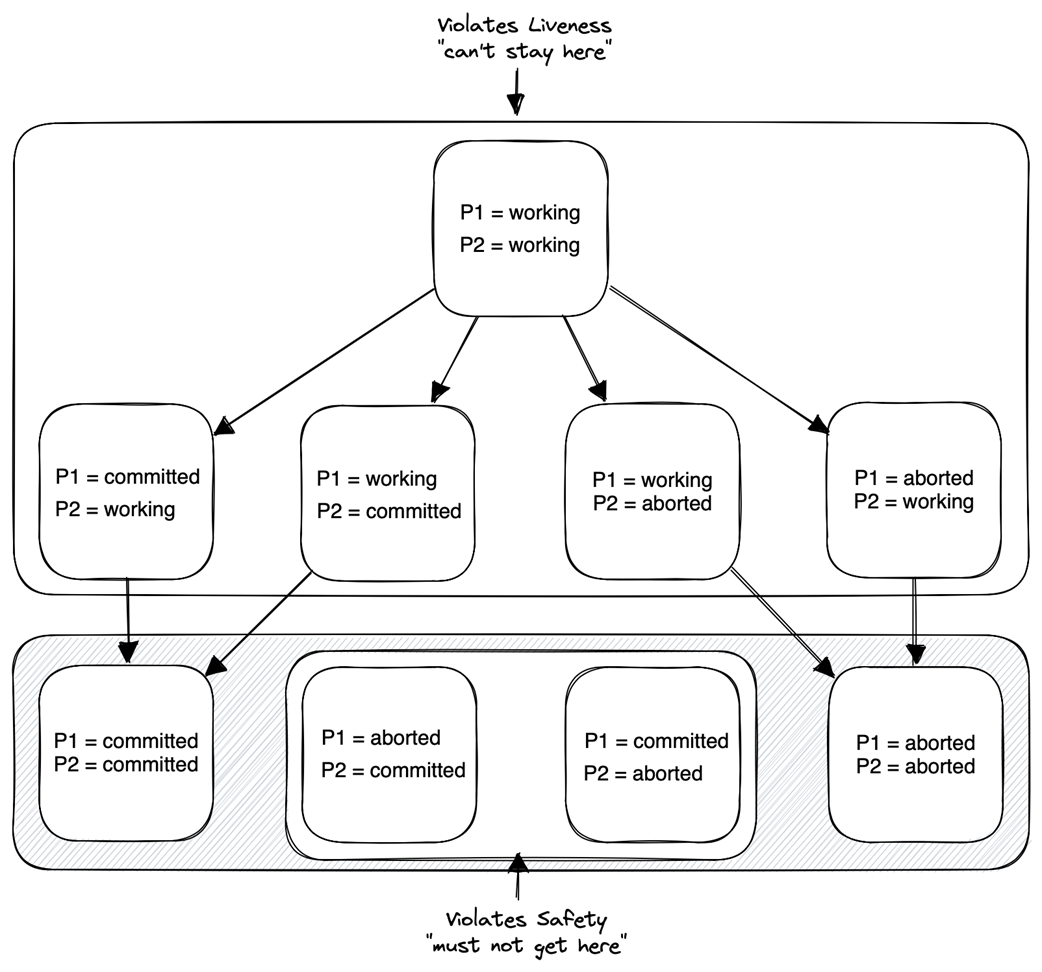
A distributed system as a set of concurrent, communicating subsystems
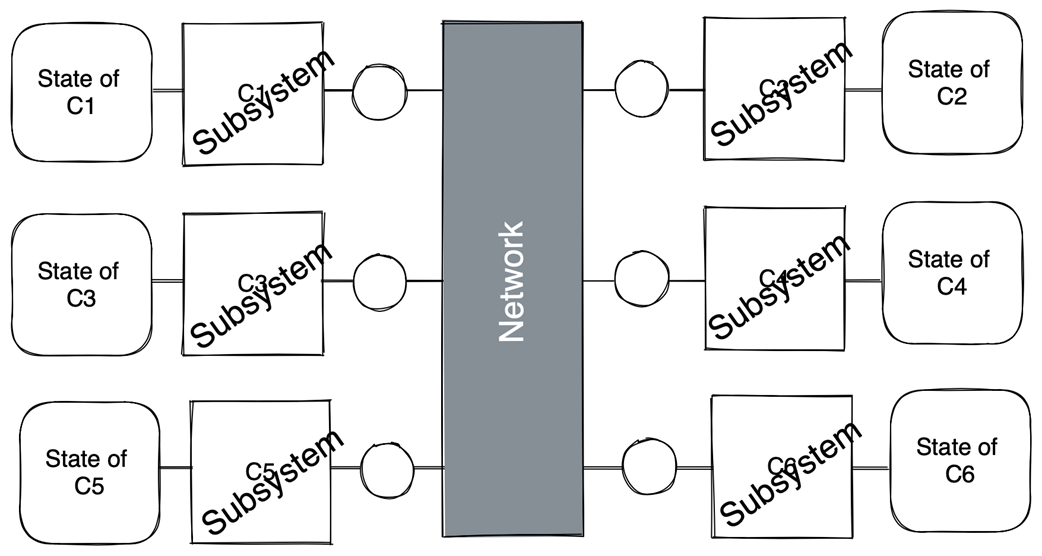
Holons and holarchies
Two different holarchies, representing the same system
Global point of view

C1’s point of view
Distributed Systems Incorporated
Black box versus white box, a global point of view
Local point of view

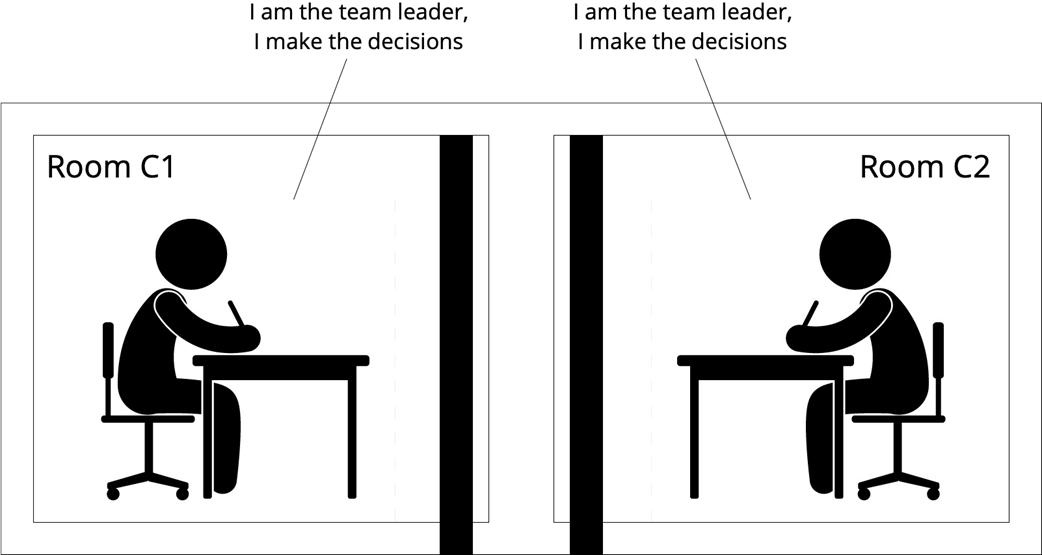
Splitbrain
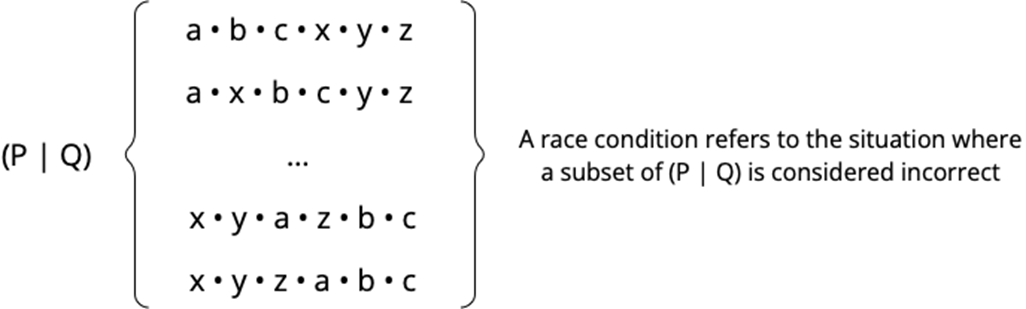
Reasoning about race conditions
Reasoning about serializability

Summary
- A mental model is the internal representation of the target system and is the basis of comprehension and communication.
- Striving for a deep understanding of distributed systems is better than merely knowing about their concepts.
- A distributed system is a set of concurrent components that communicate by sending and receiving messages over a network.
- The core challenge in designing distributed systems is creating a coherent system that functions as a whole despite each component having only local knowledge.
- Ultimately, we are interested in the guarantees a system provides. We reason about these guarantees in terms of correctness—that is, in terms of safety and liveness guarantees as well as scalability and reliability guarantees.
- Distributed systems can be visualized as a corporation, where rooms represent concurrent components, pneumatic tubes represent the network, and a mailbox represents the external interface.
FAQ
Why do we build distributed systems even though they are hard?
Because real systems must remain functional as load grows and failures occur. A single component may be correct in isolation, but it cannot absorb unbounded load or survive inevitable failures. To achieve correctness under scale and failure—namely, to be functional, scalable, and reliable—we need multiple components working together: a distributed system.
What is a distributed system according to this chapter?
A distributed system is a set of collaborating, concurrent components that communicate by exchanging messages over a network. Each component has exclusive access to its local state; the network maintains its own local state (for example, messages in flight). The system’s behavior—and its complexity—emerge from the components and their interactions.
What are mental models, and what makes a good one?
A mental model is your internal representation of a system—the basis for understanding and communication. A good mental model is:
- Correct: it contains no falsehoods (every fact in the model is a fact of the system).
- Complete: it omits no relevant facts (what’s “relevant” depends on your goal and context).
Can different descriptions of a distributed system all be “right”?
Yes. Multiple models can be valid:
- Equivalent models describe the same aspects in different ways (e.g., “network holds in-flight messages” versus “each component holds its own inbox”), yet both can express loss, duplication, and reordering.
- Complementary models emphasize different aspects (e.g., an abstract commit model that ignores messaging versus a concrete two-phase commit that models messages). Understanding why an author chose a model helps you see the intended focus.
How does this book model system behavior?
As a state machine: a sequence of states connected by discrete steps. At any moment, exactly one entity—either a component or the network—takes exactly one step. Steps can be external (send/receive) or internal (local computation/state access). You may see components called actors/agents/processes/nodes and steps called actions/events.
What do safety and liveness mean, and how do they define correctness?
Safety guarantees that nothing bad ever happens; liveness guarantees that something good eventually happens. A system is correct if every possible behavior satisfies its safety and liveness properties. Example: in a distributed transaction with two participants, safety forbids one committing while the other aborts; liveness ensures both eventually decide. Together, they imply both eventually reach the same decision.
How does the chapter define scalability and reliability?
In terms of responsiveness—the system’s ability to meet its Service Level Objectives (SLOs). Key terms:
- Service Level Indicator (SLI): a measured signal (e.g., latency).
- Service Level Objective (SLO): a predicate on the SLI (e.g., p95 latency ≤ X ms).
- Error rate: fraction of observations violating the SLO in a time window.
- Error budget: the maximum allowed error rate.
Scalability is responsiveness under load; reliability is responsiveness under failure. These guarantees are application specific and emerge from the system as a whole.
What are “systems of systems,” holons, and holarchies—and why do they matter?
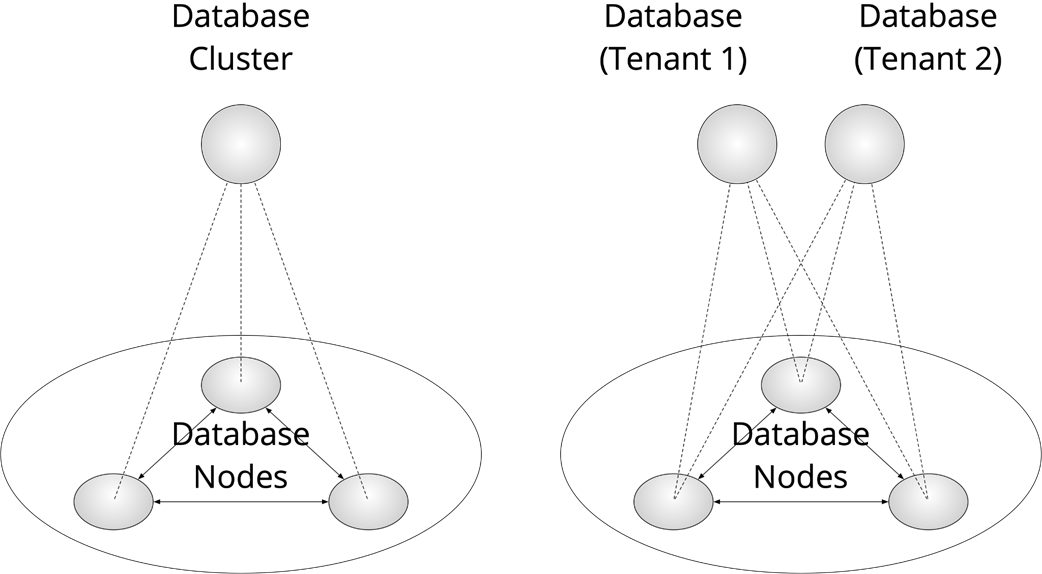
Components are often subsystems. A holon is both a whole and a part; holarchies are nested arrangements of holons. This view lets you “zoom” levels of abstraction. For example, a replicated database can be seen as one cluster, as several collaborating nodes, or as multiple tenant databases—whichever view best serves your current question.
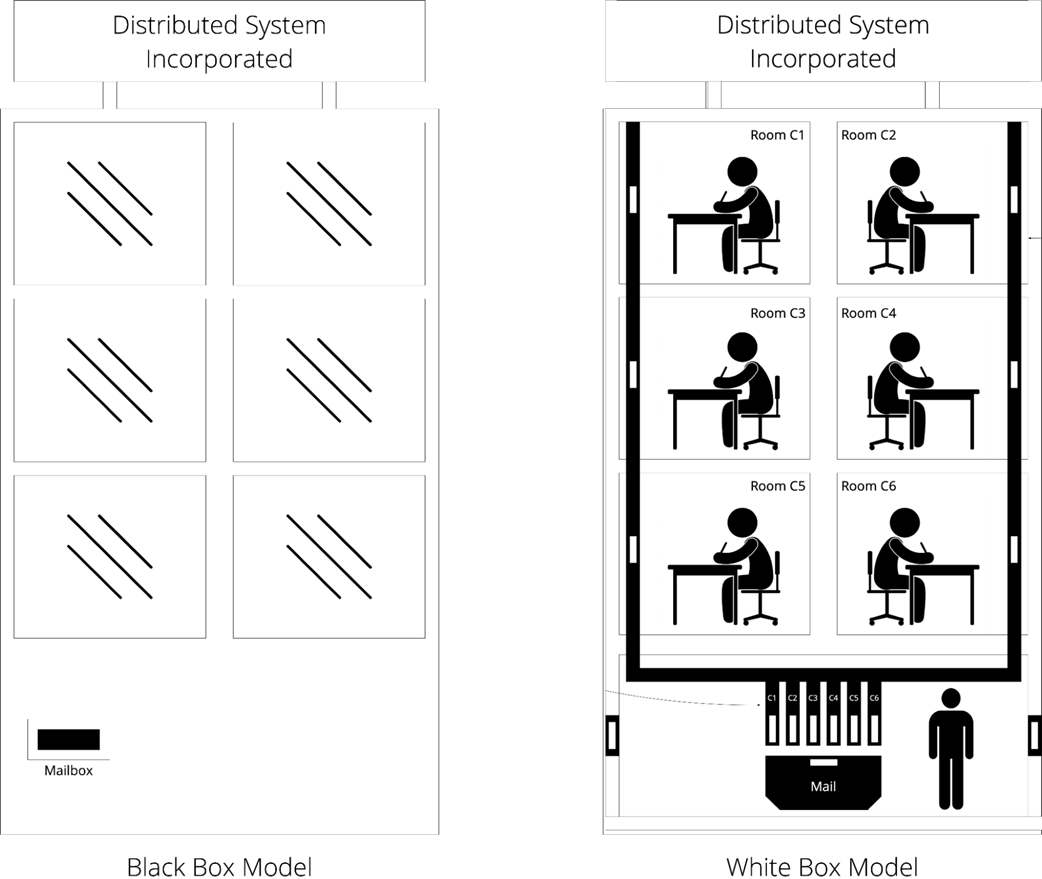
What’s the difference between a global and a local view, and why is “think globally, act locally” hard?
A global view (all-knowing observer) can see the entire system state; a local view (a single component) sees only its own state and its channel to the network. Achieving global guarantees (e.g., “exactly one leader,” avoiding split-brain) using only local knowledge and message exchange is the core challenge: design a global algorithm implemented via local algorithms.
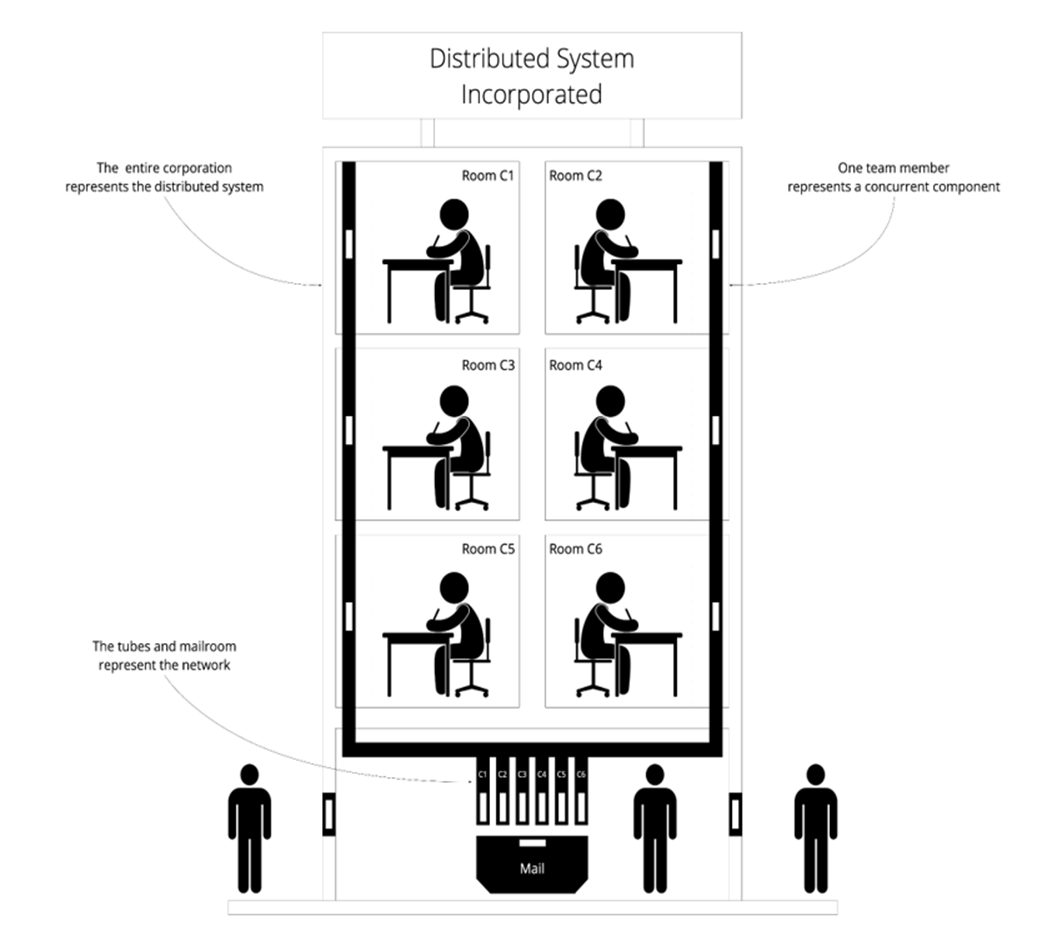
How does the “Distributed Systems Incorporated” analogy help me reason about failures and messaging?
Think of an office building: rooms are components, pneumatic tubes are the network, and the mailbox is the external interface. It maps common concerns:
- Crash semantics: short absences (transient), vacations (intermittent), departures (permanent).
- Message delivery semantics: loss, duplication, and reordering.
This concrete framing makes it easier to explore consequences and mitigations (e.g., retries, idempotence, deduplication) for real distributed behaviors.
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free