1 How AI works
This chapter offers a clear, opinionated tour of how modern AI works, demystifying concepts now common in everyday conversation—tokens, embeddings, temperature, attention—and distinguishing “AI” from “machine learning.” It begins with large language models (LLMs) and how they convert prompts into fluent text, then broadens to the methods that power them and adjacent systems, including the transformer architecture, data and training practices, and practical product-layer “wrappers” that make models feel conversational and current. It closes by extending the lens beyond language to vision, audio, and multi-modal AI, tying together common patterns, real-world constraints, and the field’s present limitations.
At their core, LLMs are next-token predictors that generate text one token at a time. In practice, an application layer (the “wrapper”) strings tokens into full responses, inserts special markers for chat turns, adds a system prompt for context (e.g., date, role, constraints), and can call external tools or retrieve documents (RAG) to supplement the static model. The chapter explains tokens and vocabularies, why usage is billed per token, and why non‑English and non‑Latin scripts often tokenize inefficiently. It introduces embeddings as high-dimensional representations of meaning, shows how transformers use attention to contextualize tokens across a fixed context window, and describes sampling controls like temperature and top‑p as levers for creativity versus reliability, along with caveats around reproducibility.
Training-wise, the chapter frames ML as designing an architecture with learnable parameters and then fitting it to data via supervised or self‑supervised learning (for LLMs, predicting masked/next tokens at Internet scale), followed by fine‑tuning and reinforcement learning with human feedback to “tame” outputs and align behavior. It outlines loss (cross‑entropy), optimization with stochastic gradient descent over many epochs, and the distinction between expensive training and faster inference. Beyond text, it surveys convolutional neural networks for images, audio, and video, U‑Nets for image-to-image tasks, and diffusion models that synthesize images (and video) from text by iterative denoising, as well as multi‑modal systems that bridge CNN and LLM embeddings. The chapter ends with pragmatic notes on privacy, costs, and the No Free Lunch lesson: progress comes from task‑tailored architectures, not a single universal model.
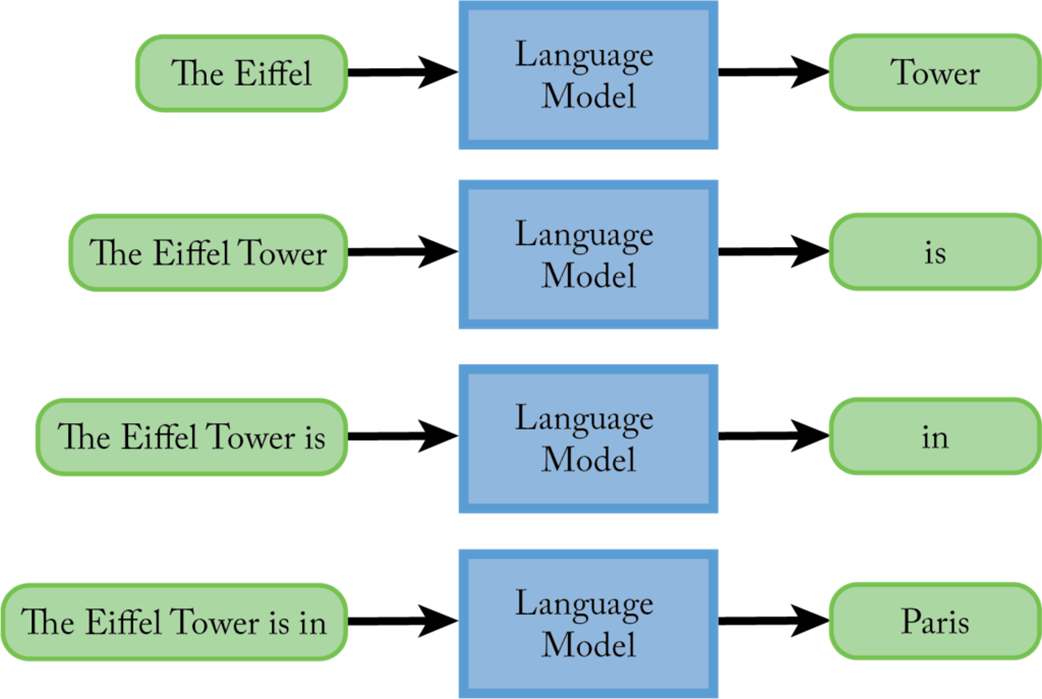
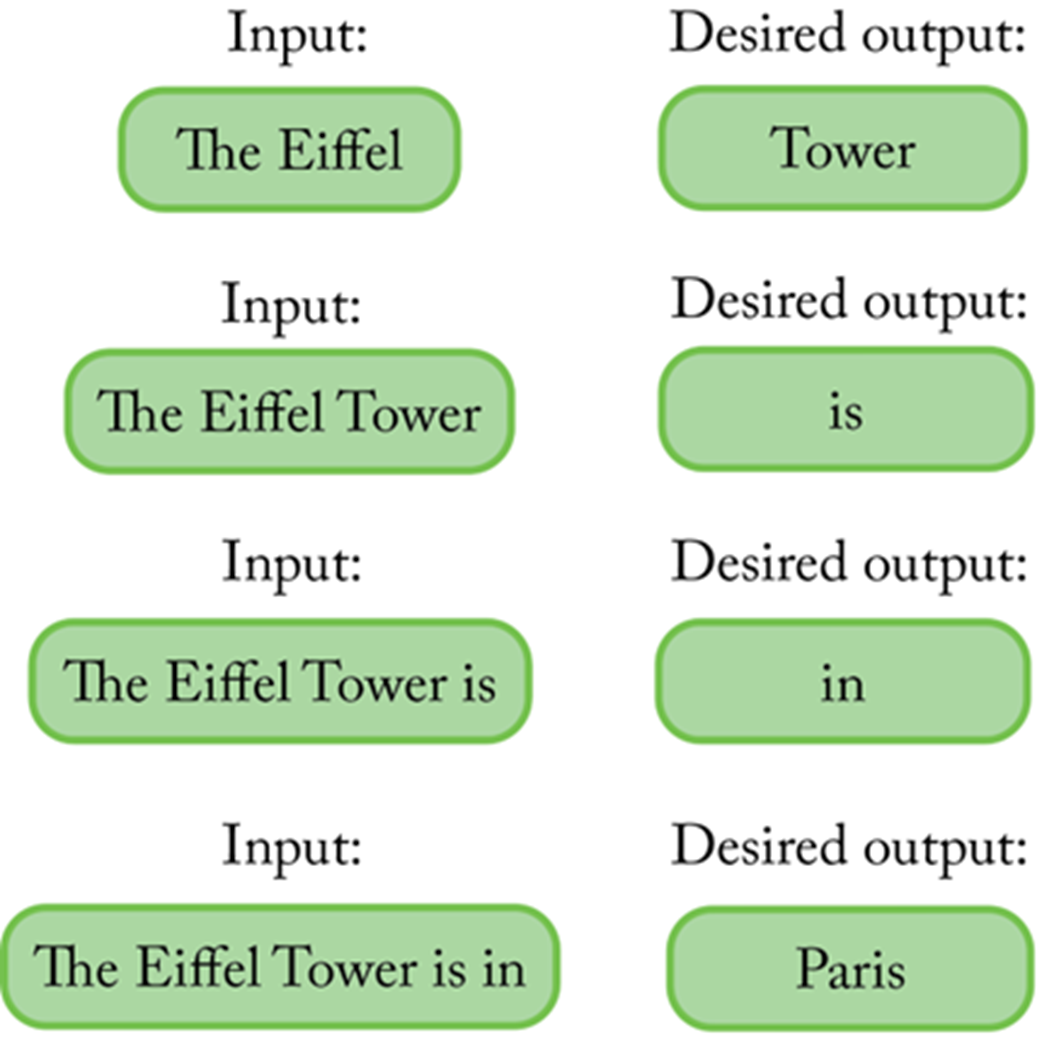
In order to generate full sentences, the LLM wrapper used the LLM to generate one word, then attaches that word to the initial prompt, then it uses the LLM again to generate one more word, and so on.
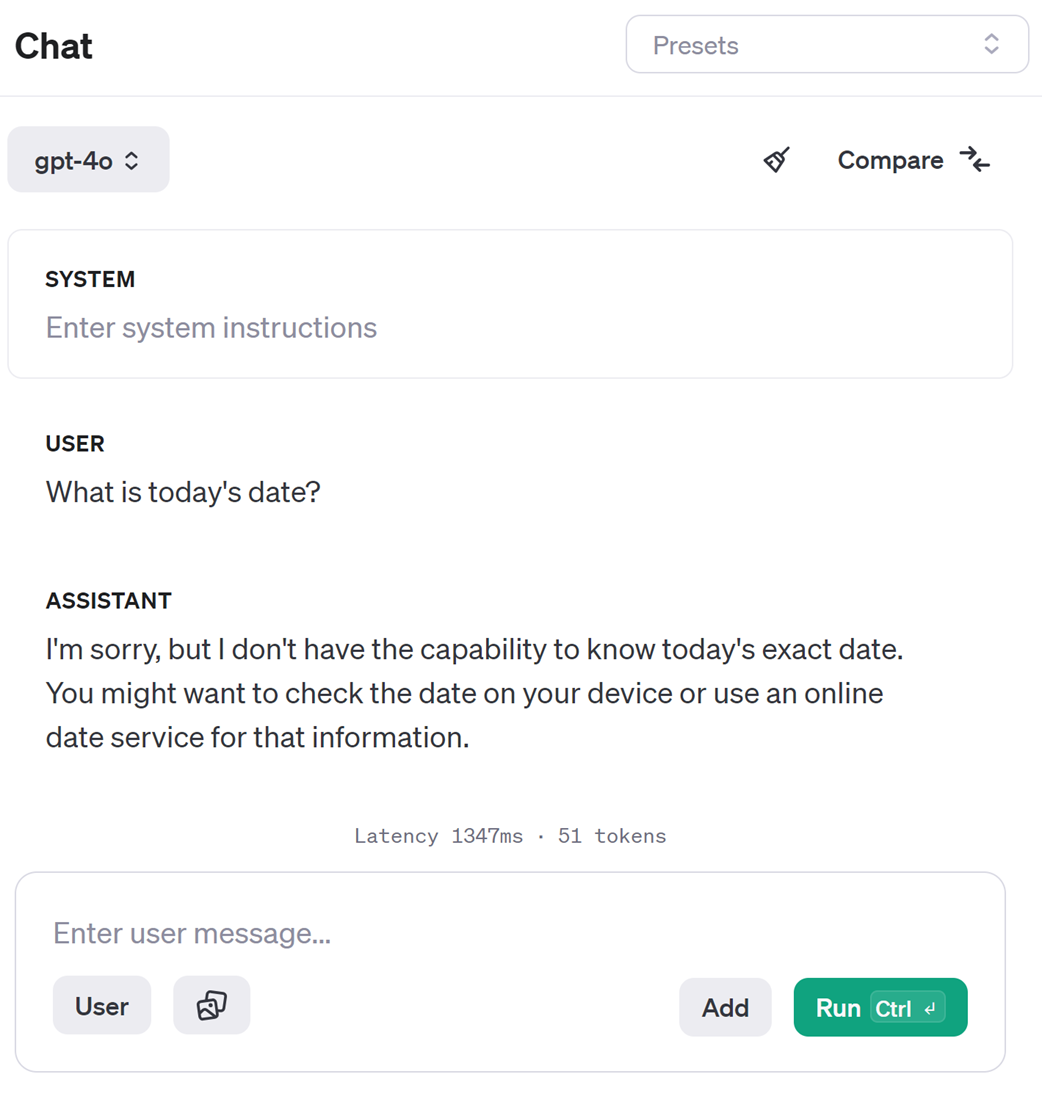
OpenAI’s API lets users define a system prompt, which is a piece of text inserted into the beginning of the user’s prompt.
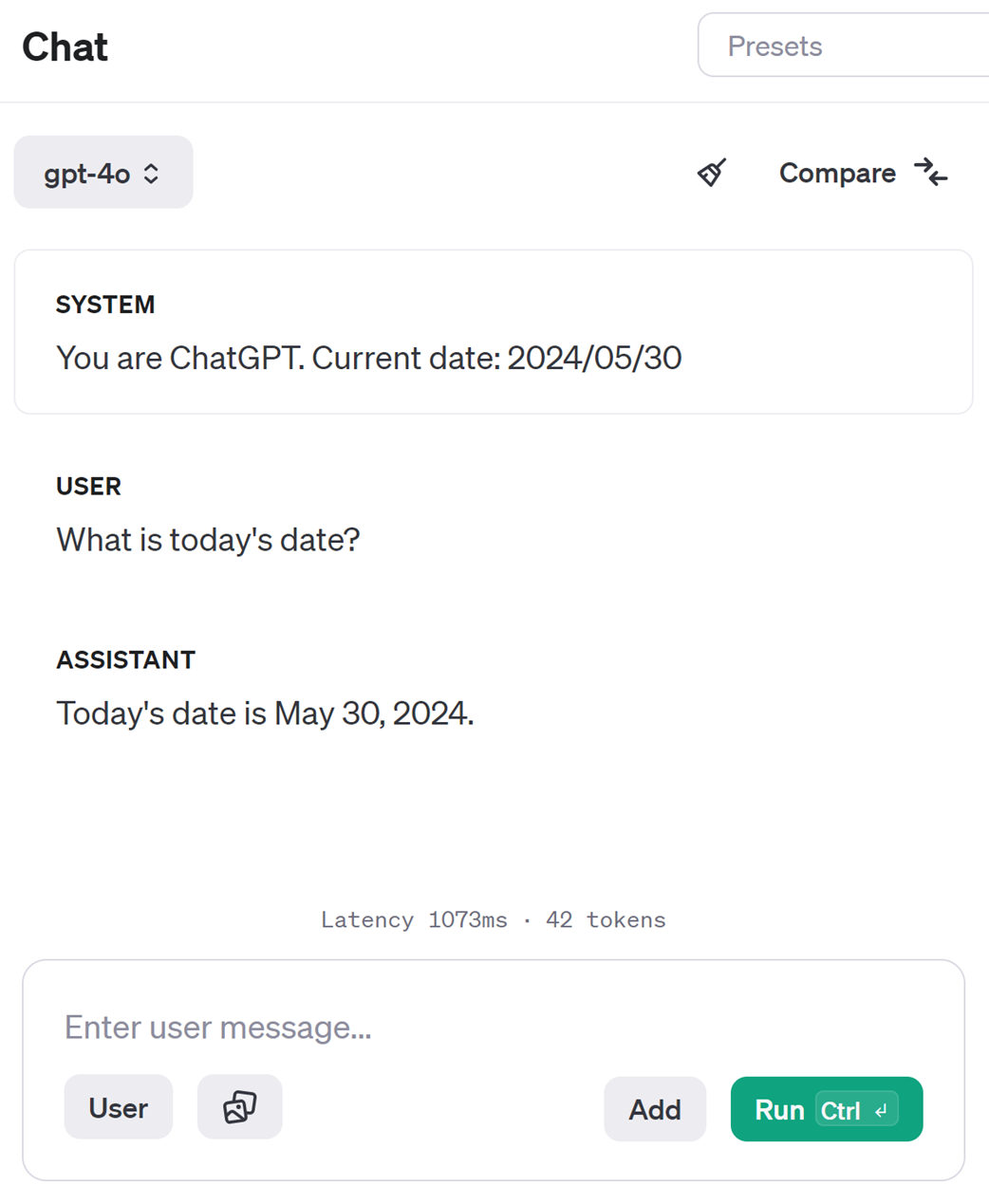
When the current date is supplied as part of the system prompt, the LLM can answer questions about the current date.
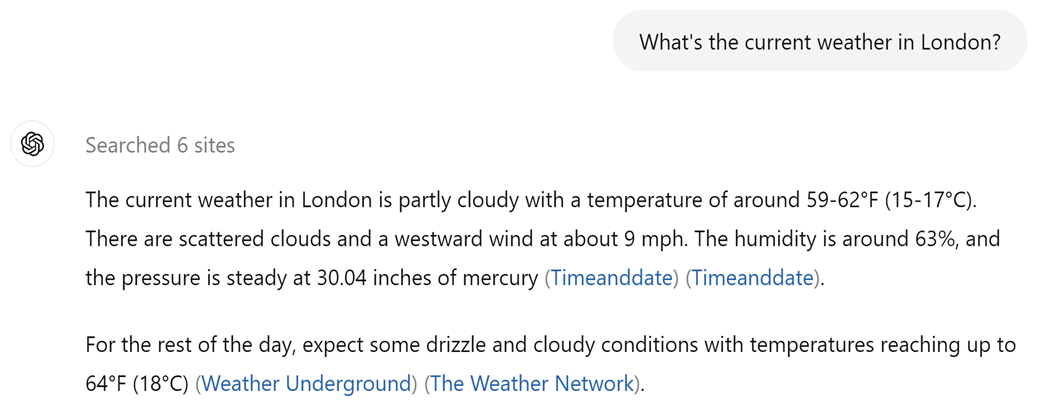
ChatGPT called a function to search the web behind the scenes and inserted the results into the user’s prompt. This creates the illusion that the LLM browses the web.
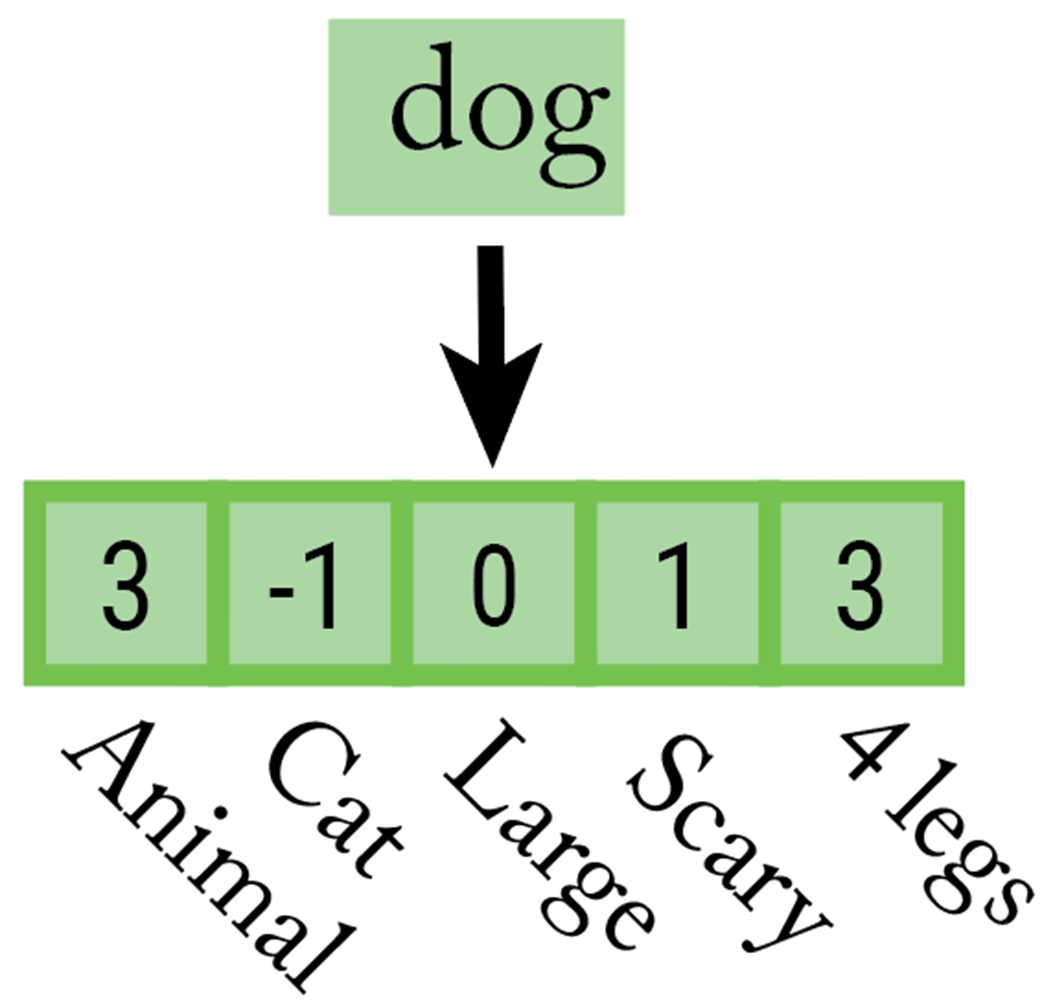
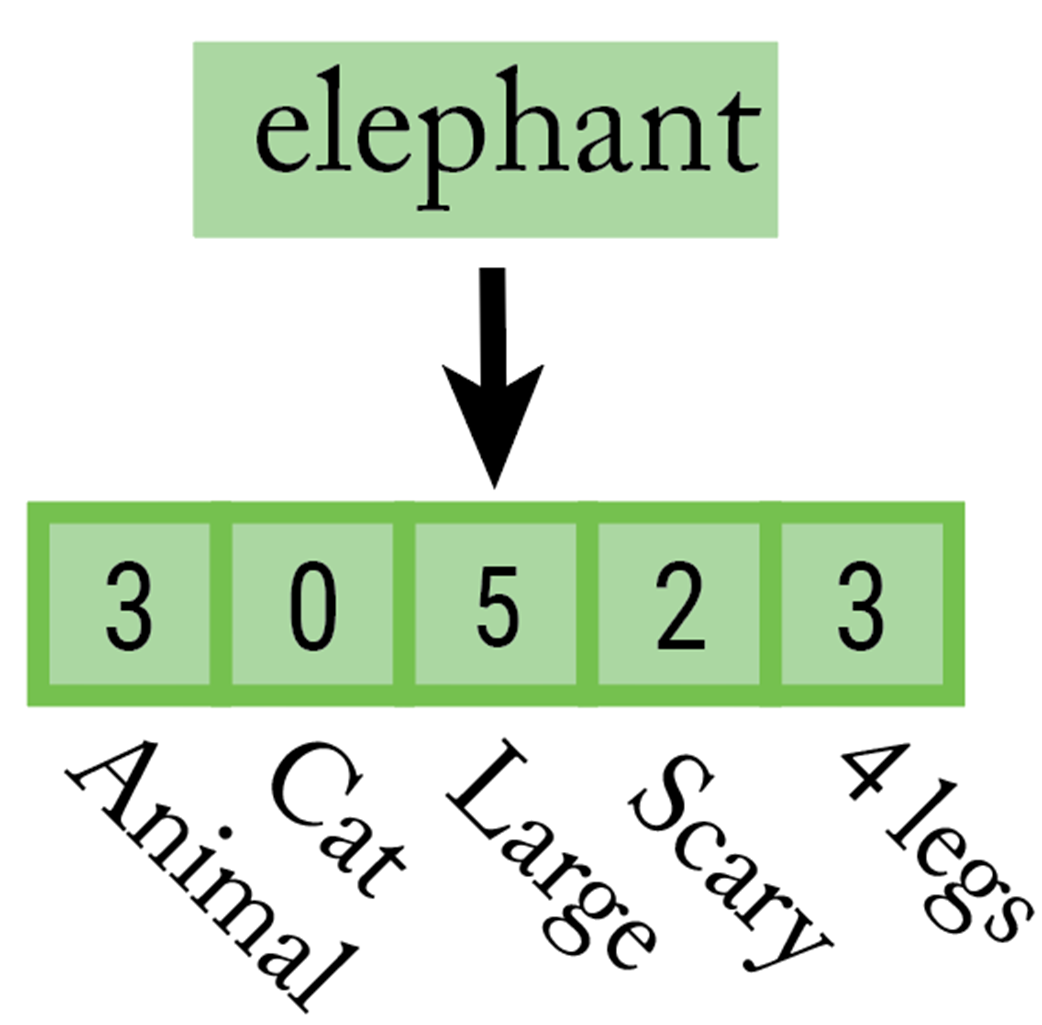
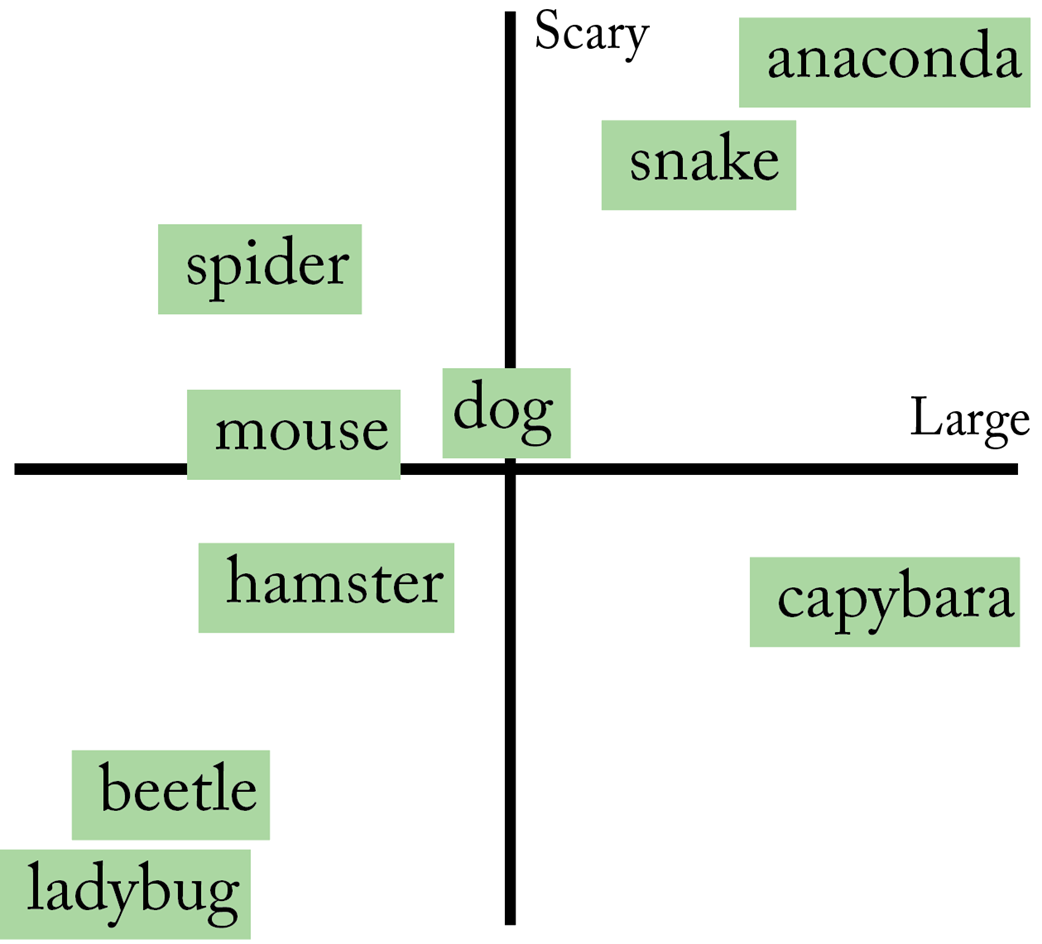
We can think the numbers in an embedding vector as coordinates that place the token in a multi-dimensional “meaning space.”
LLMs often struggle to analyze individual letters in words.

LLM overview. In Step 1, the tokens are mapped to embeddings one by one. In Step 2, each embedding is improved by contextualizing it using the previous tokens in the prompt. In Step 3, the much-improved embeddings are used to make predictions about the next token.
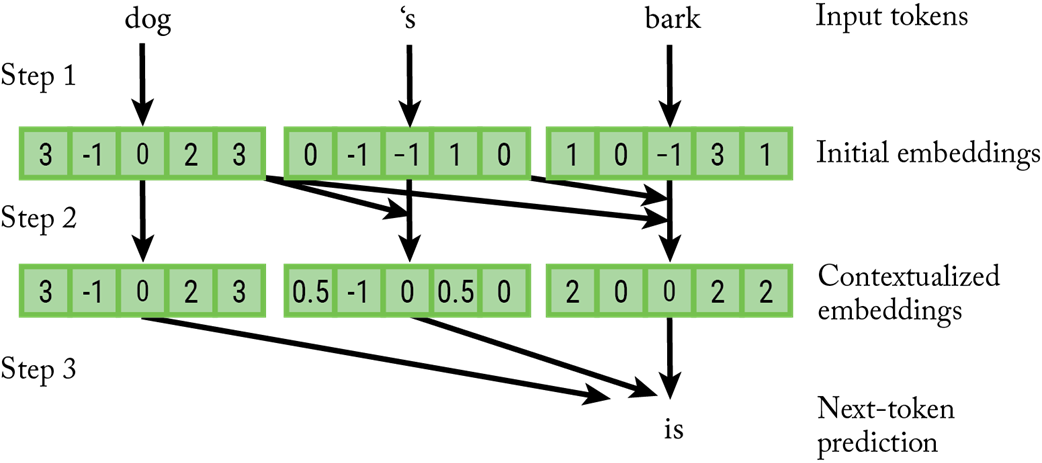
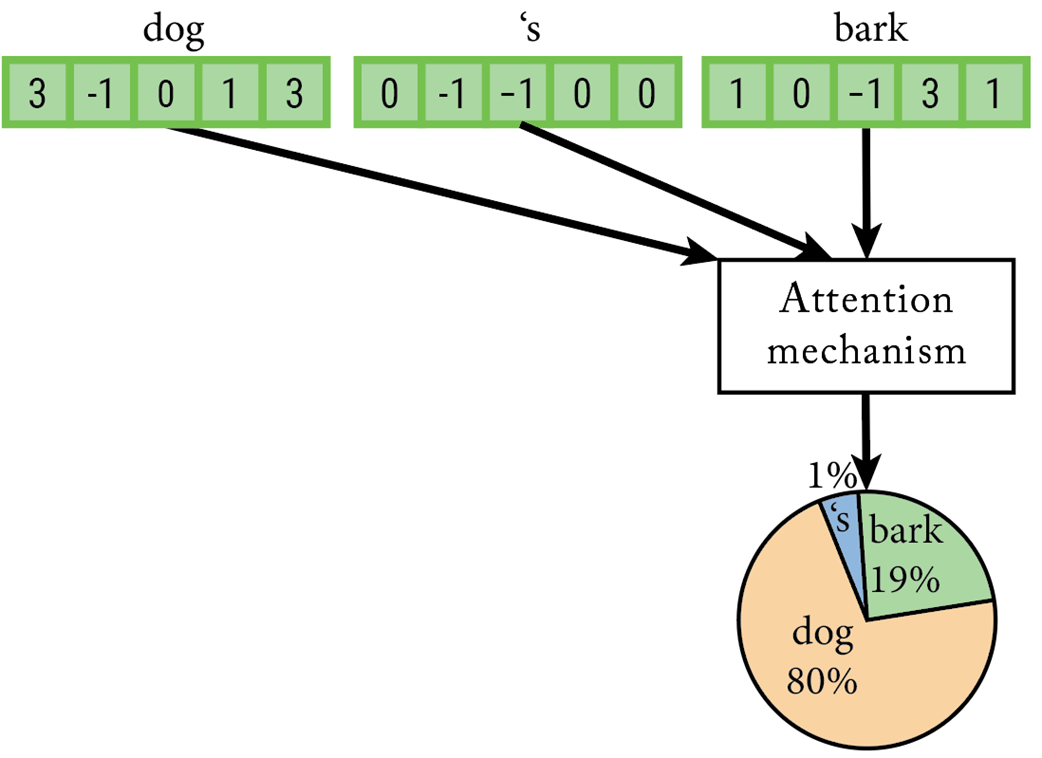
The attention mechanism calculates the relative relevance of all tokens in the context window in order to contextualize or disambiguate the last token.
A diffusion model is trained to improve a corrupted image paired with its caption.
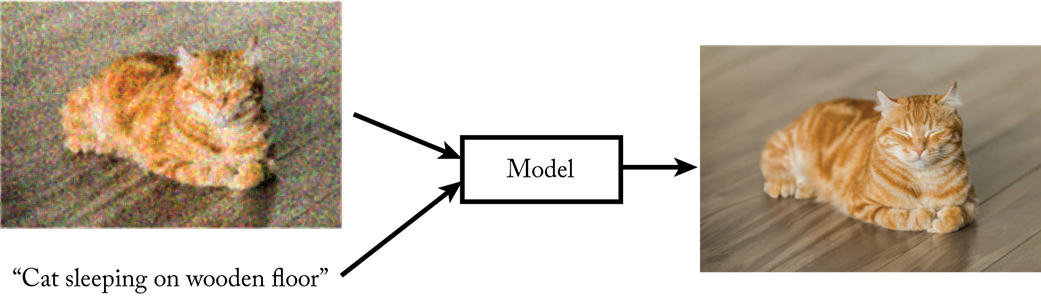
A diffusion model is used repeatedly to have a desired image emerge from Gaussian noise.

Summary
- LLMs are designed to guess the “best next” word that completes an input prompt;
- LLMs subdivide inputs into valid “tokens” (common words or pieces of words) from an internal vocabulary;
- LLMs calculate the probability that each possible token is the one that comes next after the input;
- A wrapper around the LLM enhances its capabilities. For examples, it makes the LLM “eat its own output” repeatedly to generate full outputs, one token at a time;
- Current LLMs represent information using embedding vector, which are lists of numbers;
- Current LLMs follow the transformer architecture, which is a method to progressively contextualize input tokens;
- LLMs are created using machine learning, meaning that data is used to define missing parameters inside the model;
- There are different types of machine learning, including supervised, self-supervised, and unsupervised learning.
- In supervised learning, the computer learns by example—it is fed with examples of how to perform the task. In the case of self-supervised learning, these examples are generated automatically by scanning data.
- Popular LLMs were first trained in a self-supervised way using publicly available data, and then they were refined using manually generated data in order to “align” them to the users’ objectives.
- CNNs are a popular architecture to process other types of data, such as images;
- CNNs are combined with transformers to create multi-modal AI.
 The AI Pocket Book ebook for free
The AI Pocket Book ebook for free