This chapter pivots from treating AI as an external coding helper to embedding it directly inside data pipelines. Instead of manually passing prompts to a chat interface, the model becomes a programmable step that sits alongside familiar libraries like Requests and pandas. Sentiment analysis serves as the anchor use case: it’s simple to visualize, broadly useful, and a clear example of AI as a drop-in enrichment stage that feeds downstream tools such as scikit-learn, databases, and BI dashboards. The emphasis is on integration and operational hygiene—securely loading API keys via environment variables and designing prompts and parameters that behave predictably in production.
The walkthrough builds a small but realistic pipeline: fetch recent news with a flexible articles endpoint, preprocess titles and body text into clean content blocks, then call the OpenAI Chat Completions API to classify sentiment. It adopts a crawl-walk-run approach—starting with plain prompts, inspecting raw JSON responses, and then iterating for reliability. Practical concerns are front and center: control costs with token discipline, cap outputs, and monitor usage; extract only the fields you need from responses; and expect variability in LLM judgments (especially with sarcasm or mixed tone). To make results pipeline-ready, the chapter normalizes outputs to compact labels (Positive, Neutral, Negative) or numeric scores, and adds logging and consolidation steps that enrich a DataFrame with consistent sentiment signals.
By the end, the pipeline loops through articles, applies sentiment, logs progress, and returns a clean, enriched dataset ready for modeling, storage, or visualization. The lab reinforces these skills: swapping the query topic, returning numeric scores from −1 to 1, and scaling to larger batches with simple aggregations. The key takeaway is that AI is no longer just a conversational assistant—it’s a composable building block for extraction, enrichment, and delivery. This foundation sets up future chapters where natural language can steer data transformations, making AI a first-class element of modern data engineering workflows.
In earlier chapters, the data engineer acted as a go-between—manually passing instructions between an AI coding companion and the coding environment. Now, the AI component is embedded directly within the workflow, alongside libraries like Requests and Pandas, enabling natural language tasks (like sentiment analysis) to execute as native steps within the Jupyter notebook
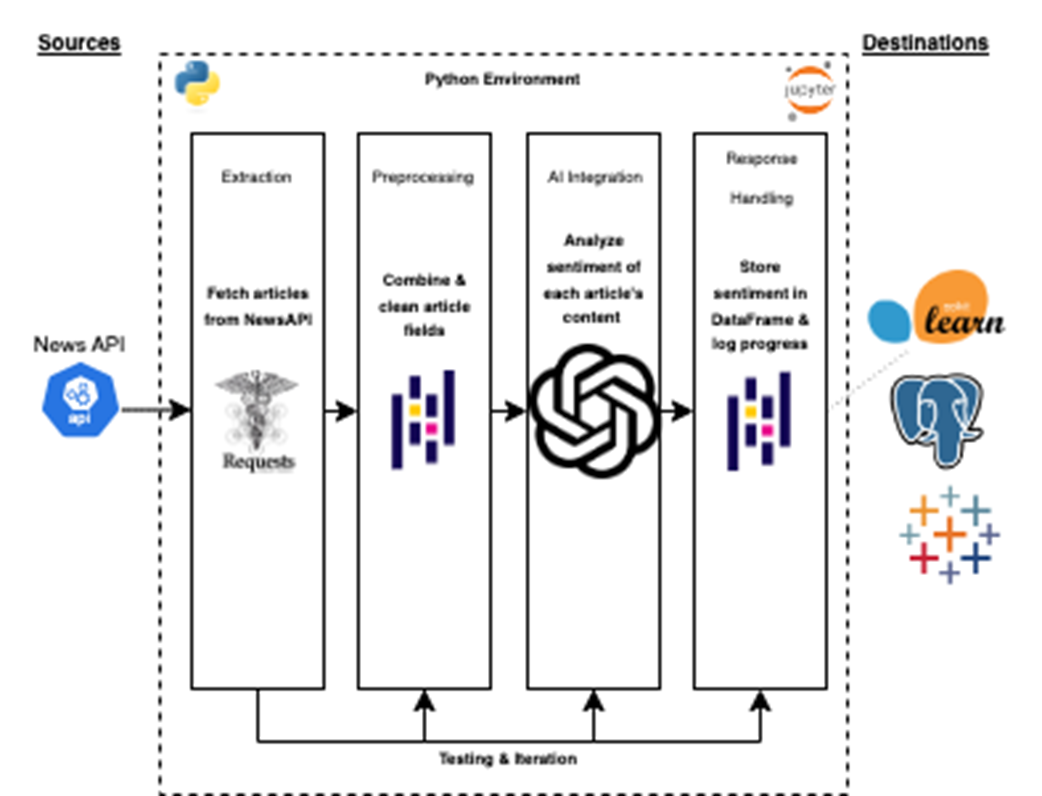
This diagram illustrates the full mental model for the use case. Articles are fetched from the NewsAPI using the requests library, then preprocessed into clean content blocks. The OpenAI API is embedded within the Python environment to analyze sentiment, returning structured labels. Finally, results are stored in a pandas DataFrame and logged—ready for downstream use in tools like scikit-learn, PostgreSQL, or Tableau.
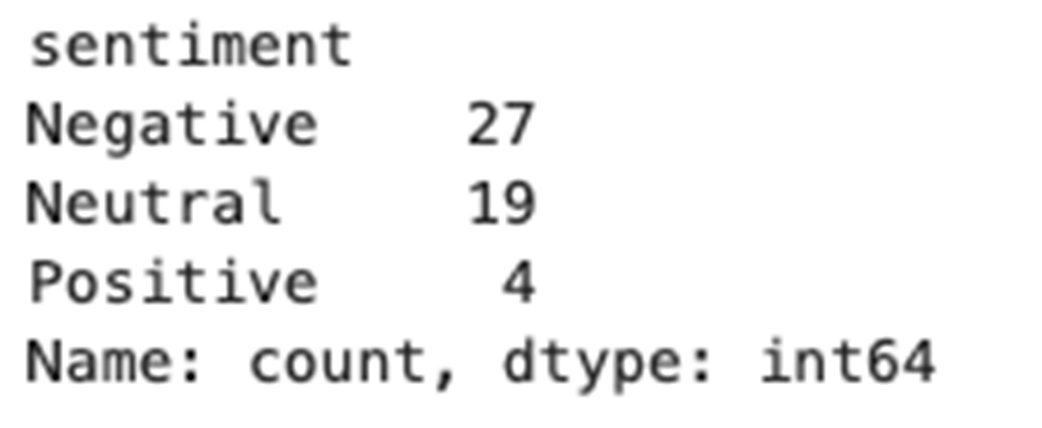
This figure shows the results of the full AI-powered sentiment pipeline. The top portion displays logging output for each step, including API requests and processed sentiment labels. The bottom shows the final pandas DataFrame, where each article title is paired with a normalized sentiment category. Results will vary over time, as the input depends on live Tesla news retrieved from NewsAPI.
Example of what output by sentiment score should look like.
Example of what aggregation results may look like.
FAQ
What does it mean to embed the OpenAI API inside a data workflow instead of using it as a separate coding companion?It means the model becomes a native step in your pipeline—right alongside libraries like Requests and pandas—so tasks like sentiment analysis run programmatically inside your notebook or scripts. Outputs flow directly into DataFrames, ML workflows, databases, or dashboards, making AI an integrated enrichment component rather than a separate assistant.Why use sentiment analysis as the first AI task, and where can the results go downstream?Sentiment analysis is clear, widely applicable, and easy to visualize. It demonstrates how AI can act as a drop-in enrichment step. Results can feed into pandas for analysis, scikit-learn models, PostgreSQL tables, or BI tools like Tableau—just another column you can aggregate, join, or visualize.How should I manage API keys for NewsAPI and OpenAI securely?Store keys in environment variables and load them via dotenv. Example: import os; from dotenv import load_dotenv; load_dotenv(); OPENAI_API_KEY = os.getenv("OPENAI_API_KEY"); NEWS_API_KEY = os.getenv("NEWS_API_KEY"). Avoid hardcoding keys in code or notebooks. See env_setup.md in the repo for a walkthrough.Which NewsAPI endpoint and parameters are used in this chapter?Use /v2/everything with parameters like q (keywords), from and to (date range), language (e.g., en), and sortBy (e.g., publishedAt). Free tier access covers the last 30 days, so use recent dates. The example fetches articles about “Tesla” from yesterday through today using dynamic date calculation.How do I extract and preprocess articles before sending them to the model?Extraction: call the NewsAPI URL with requests, handle status codes, and log results; collect articles from response.json()["articles"]. Preprocessing: combine title, description, and content into a single clean text field (replace newlines, strip whitespace) and load into a pandas DataFrame. Limit to a few records (e.g., 5) while testing.How do I call the OpenAI Chat Completions API for sentiment analysis in Python?Install openai (v1+), load OPENAI_API_KEY from the environment, then call openai.chat.completions.create with model="gpt-4o", messages=[system, user], and parameters like max_tokens and temperature. Extract the result with response.choices[0].message.content.strip().How do I parse the raw API response and get structured, pipeline-ready outputs?From the raw JSON, use choices[0].message.content to get the text. Normalize via prompting: ask the model to return only "Positive", "Neutral", or "Negative". Alternatively, ask for a numerical score between -1 and 1 and return only the number. For stricter structure, you can later use response_format with JSON schemas.What does this cost and how can I control it?Costs are token-based (input + output). As of writing, gpt-4o is around $0.005 per 1,000 input tokens and $0.015 per 1,000 output tokens. Control costs by sampling small batches first, setting max_tokens, keeping prompts concise, and monitoring usage in the OpenAI dashboard. Always check the current pricing page before scaling.What can go wrong with LLM sentiment analysis, and how do I improve reliability?Models can misread sarcasm, overreact to charged words, and vary across runs. Improve reliability by normalizing outputs (fixed labels or numeric scores), using explicit prompts (“Return only Positive/Neutral/Negative”), optionally specifying the method (e.g., VADER or hybrid), and treating AI sentiment as one signal among many—validate before acting.How do I apply sentiment analysis across the DataFrame and prepare results for downstream use?Iterate over df["content"], call your perform_sentiment_analysis function, log progress, and add a new df["sentiment"] column. For categorical labels, use value_counts() to summarize. For numeric scores, convert with pd.to_numeric(..., errors="coerce") and compute aggregates like mean. Store or serve the enriched DataFrame to ML pipelines, databases, or dashboards.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!


 Learn AI Data Engineering in a Month of Lunches ebook for free
Learn AI Data Engineering in a Month of Lunches ebook for free