2 Advantages & Disadvantages of Using a Coding Companion
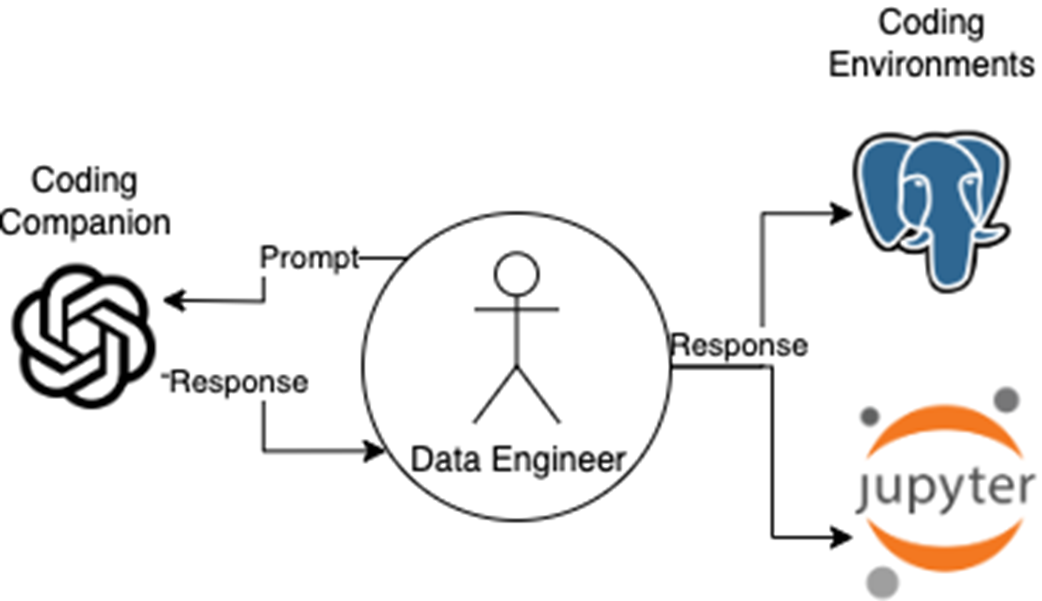
Large language models have evolved from conversational tools into capable coding companions that can accelerate many parts of a data engineering workflow. This chapter presents a balanced view of how these assistants fit into real projects: they can boost productivity, compress iteration cycles, and reduce manual effort, yet they must be guided by clear prompts and paired with careful human oversight. A key mental model is to keep the companion and the execution environment distinct, so you can observe how prompts are interpreted, evaluate generated code safely, and learn the model’s reasoning patterns before moving toward tighter integrations.
On the benefits side, LLMs shine when complexity rises—rapidly producing draft code for tasks like multi-step transformations, API integrations, and nested JSON normalization. Their conversational interface supports iterative refinement, enabling you to steer solutions toward correctness and maintainability without starting from scratch. While modern IDEs increasingly blend AI into the editing experience, the chapter emphasizes starting with a separated workflow to build foundational skills: crafting effective prompts, validating results, and understanding what the model does and does not infer.
The drawbacks are equally important. LLMs can hallucinate—confidently inventing functions, columns, or logic that don’t exist—and they lack awareness of your specific schemas, business rules, and system constraints. Their finite context windows can cause truncated reasoning or forgotten details in long prompts. To mitigate these risks, the chapter stresses treating AI output as a first draft, validating against real schemas and requirements, and using focused, incremental prompts. It grounds practice in a well-known sample database to share context with the model, illustrates how seemingly correct SQL can miss intent without precise criteria, and closes with hands-on exercises that reinforce prompt iteration, code execution, and rigorous human review as non-negotiable parts of AI-assisted development.
The AI coding companion mental model: You, the data engineer, interact with a coding companion via prompts and responses, then test and execute code within a separate coding environment. This separation reinforces how AI generates code and supports learning prompt engineering
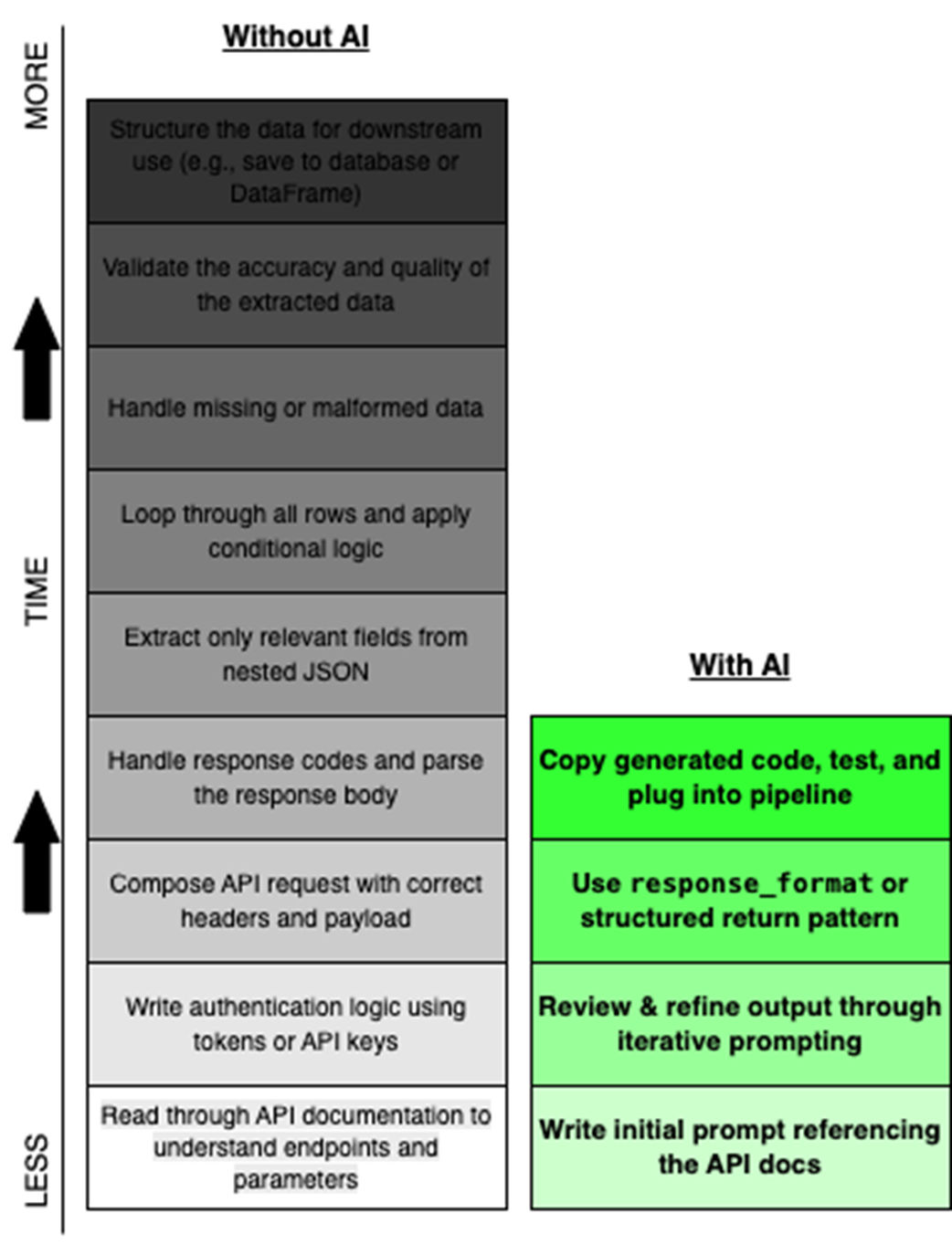
Reading from bottom to top, this timeline compares the traditional manual steps (left) versus an AI-assisted workflow (right) for API data extraction. The "Without AI" column illustrates the cumulative time and effort required to manually code each part of the task. In contrast, the "With AI" column shows how a well-structured prompt and a few refinements can significantly compress the workflow.
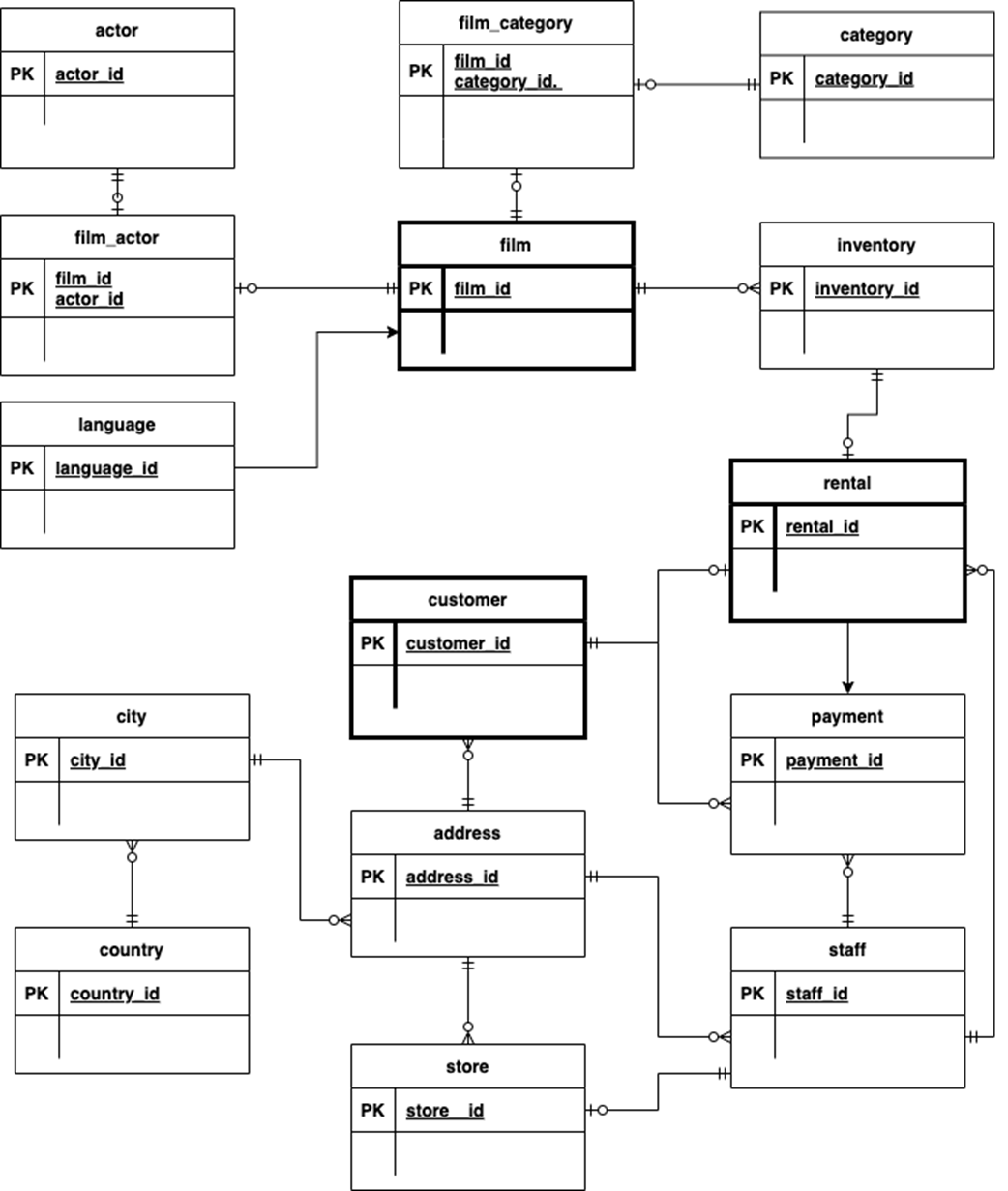
The Pagila Entity Relationship Diagram illustrating relationships between the different objects in the Paglia DVD Store data set
Lab Answers
Note: Due to the probabilistic nature of language models, your AI-generated answers might differ slightly from the code shown here. As long as the results are correct and the logic aligns with the prompt, your solution is valid.
1.
2.
3.
4.
5.
6.
FAQ
What is an AI/LLM coding companion and how does it fit into a data engineering workflow?An AI coding companion (e.g., ChatGPT) is a conversational tool that generates code and suggestions from your prompts. You craft prompts and review responses in the companion, then paste and run the code in your separate coding environment (e.g., Jupyter, VS Code, pgAdmin). This separation helps you observe how prompts are interpreted and validate outputs against real systems.What are the main advantages of using an AI coding companion for data engineering?They accelerate code generation, reduce boilerplate, automate repetitive tasks, and support rapid, iterative prototyping. By refining prompts based on output, you can converge on accurate, elegant solutions faster, especially as complexity increases.Which kinds of tasks benefit most from LLM assistance?Complex, multi-step tasks such as nested JSON normalization, API integrations, conditional data transformations, and non-trivial SQL/ETL logic benefit greatly. For example, extracting structured columns from product descriptions and applying status-based tax rules can be generated quickly and refined conversationally.What is a hallucination in this context, and what might it look like?Hallucinations are confident but incorrect outputs. Examples include suggesting non-existent library methods, referencing columns that aren’t in your dataset, or producing SQL that looks valid but fails due to incorrect joins or misunderstood relationships.How can I handle or prevent hallucinations in AI-generated code?Always validate code against your actual schema and business rules, treat AI output as a first draft (not production-ready), and use feedback loops to correct and refine results. Human review is essential for accuracy and safety.Why keep the AI companion separate from the IDE, at least initially?Separation makes the generation process transparent, helping you learn how prompts influence reasoning, spot misunderstandings, and build prompt-engineering skills. IDE-integrated tools are powerful but can hide the steps you need to understand early on.What are token limits and context windows, and why do they matter?LLMs process only a finite amount of text at once. Long schemas, prompts, or conversations can exceed this window, causing the model to forget earlier details or fabricate missing pieces, which leads to incomplete or incorrect reasoning.How can I work around token/context window constraints?Provide concise, relevant schema snippets (DDL, ERDs), break requests into smaller steps, restate key relationships in your prompt, validate outputs against known definitions, and explore a schema iteratively with targeted questions.Why does the chapter use the Pagila dataset?Pagila is a well-known, well-documented sample schema that fits within a typical context window and is likely familiar to LLMs. It minimizes missing context so you can focus on prompt strategy, validation, and iterative refinement rather than lengthy schema ingestion.Why can a “simple” SQL question still go wrong, and how do I improve results?Ambiguity in terms like “most popular” can cause misalignment (e.g., missing date ranges, store filters, or handling of edge cases). Make prompts explicit about metrics, filters, and business rules, then iterate based on results and validation against your data.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Learn AI Data Engineering in a Month of Lunches ebook for free
Learn AI Data Engineering in a Month of Lunches ebook for free