1 Introducing Kubernetes
Kubernetes has matured into the default platform for running containerized applications, prized for abstracting infrastructure and automating everyday operations. At its heart, it is an API with controllers that reconcile a desired state: you describe how your application should run, and Kubernetes schedules it, restarts it when needed, and keeps it reachable. This declarative model standardizes deployment across laptops, data centers, and clouds, aligning well with microservices and DevOps practices while reducing cloud lock-in through a consistent API. Although smaller, simpler systems may not need it, managed services make adopting Kubernetes feasible even for lean teams. The material introduces Kubernetes hands-on, guiding readers through core concepts like pods, deployments, services, volumes, and configuration to build confidence without requiring prior container or Linux experience.
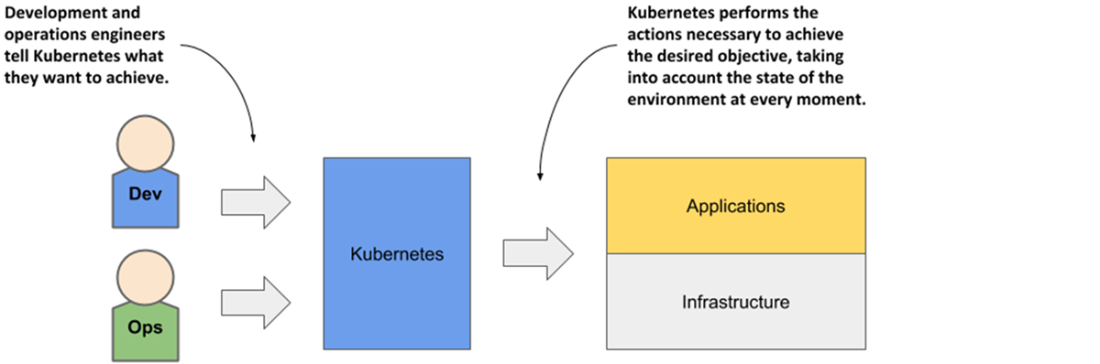
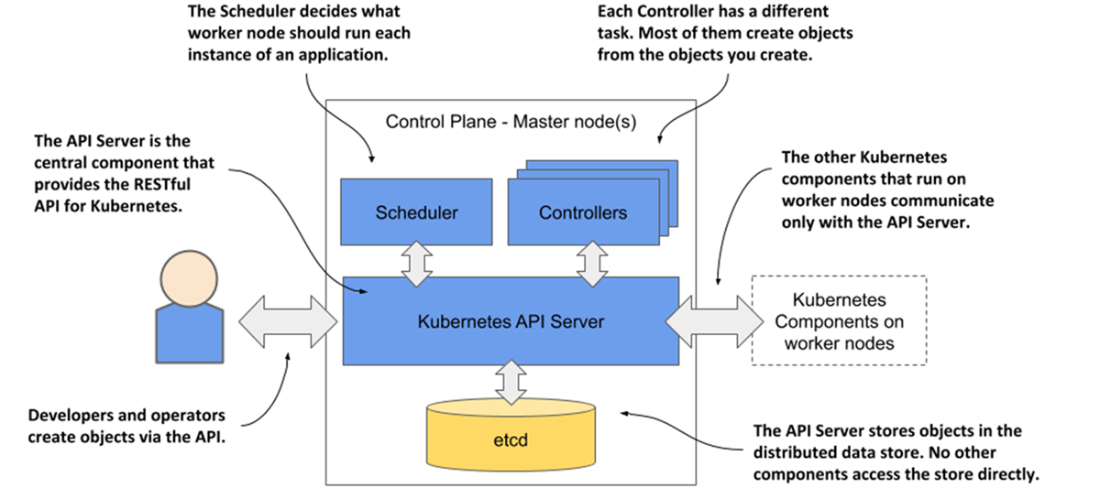
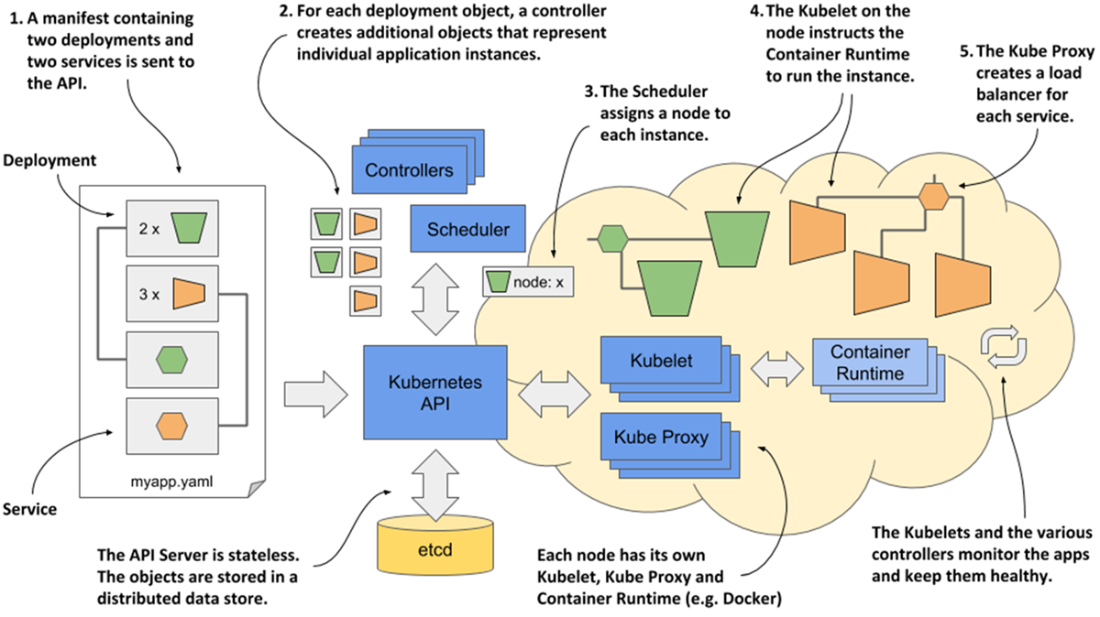
Conceptually, Kubernetes behaves like an operating system for clusters: the control plane (API server, etcd, scheduler, and controllers) maintains cluster state, while worker nodes run workloads via the kubelet and a container runtime, with kube-proxy handling traffic distribution. Once installed, the cluster appears as a single deployment surface; you submit YAML/JSON manifests, the API persists objects, controllers create the required instances, the scheduler places them, kubelets start containers, and networking exposes them behind stable endpoints. Built-in capabilities—service discovery, horizontal scaling, load balancing, leader election, and self-healing—let developers focus on business logic rather than infrastructure, while Kubernetes continually reconciles changes to keep applications healthy and aligned with their specifications.
For adoption, organizations can run Kubernetes on-premises, in the cloud, or in hybrid setups, taking advantage of elastic capacity and autoscaling where available. A central decision is whether to operate clusters in-house or rely on managed offerings such as GKE, AKS, or EKS; using Kubernetes is far easier than managing it, and enterprise distributions can add hardened defaults and tooling. Teams should weigh the learning curve, interim costs, and the actual need for automation: monoliths or very few services may not justify the complexity, whereas larger microservice estates benefit from improved utilization, resilience, and portability. By the end, readers should understand how Kubernetes works, how to package and deploy applications locally and in the cloud, and how to navigate the platform without feeling overwhelmed.
Infrastructure abstraction using Kubernetes
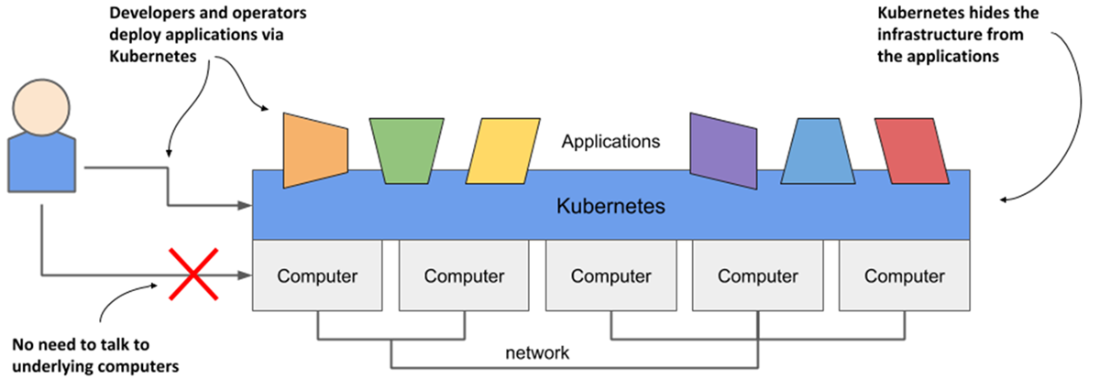
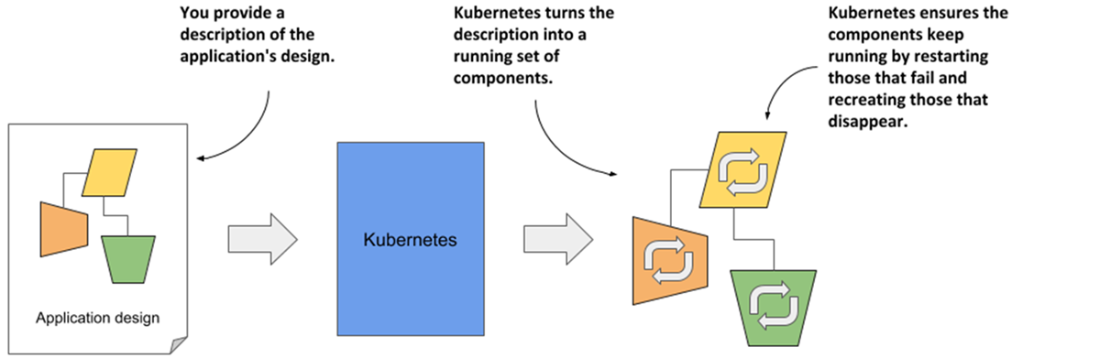
The declarative model of application deployment
Changes in the description are reflected in the running application
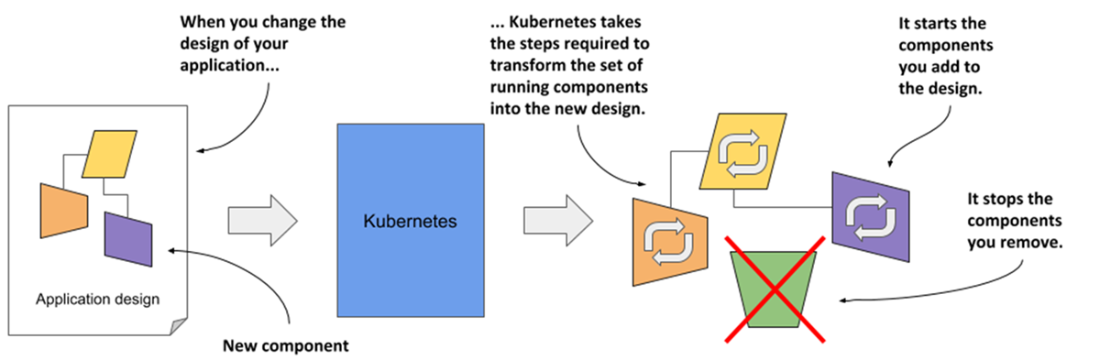
Kubernetes takes over the management of applications
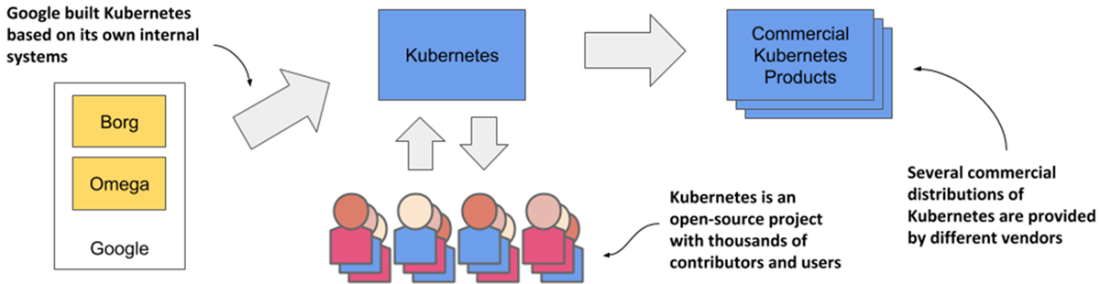
The origins and state of the Kubernetes open source project
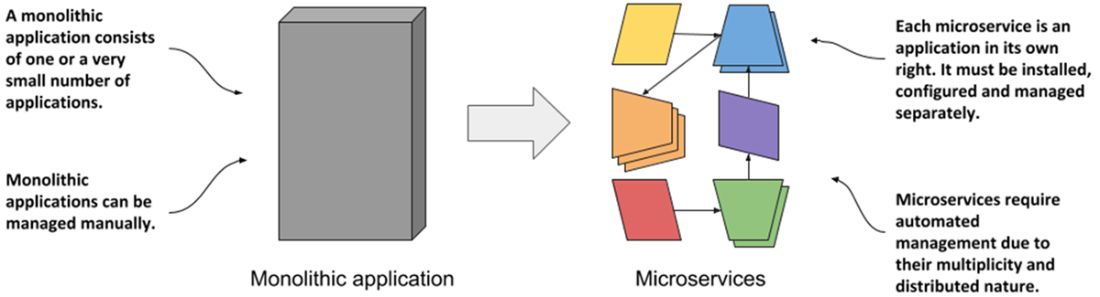
Comparing monolithic applications with microservices
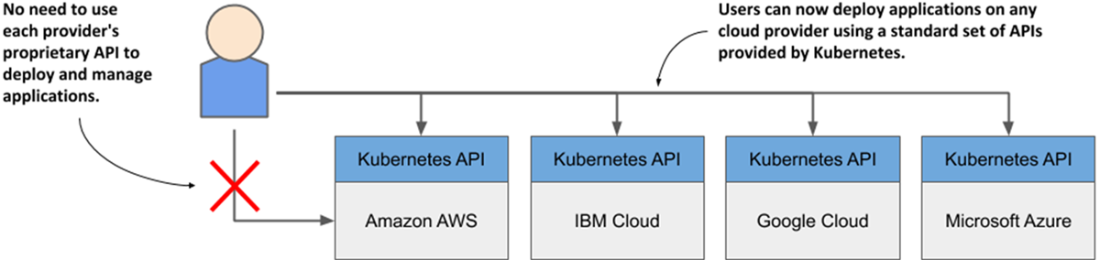
Kubernetes has standardized how you deploy applications on cloud providers
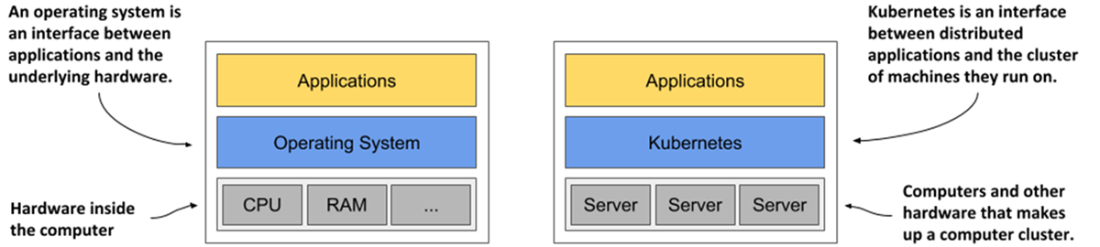
Kubernetes is to a computer cluster what an operating system is to a computer.
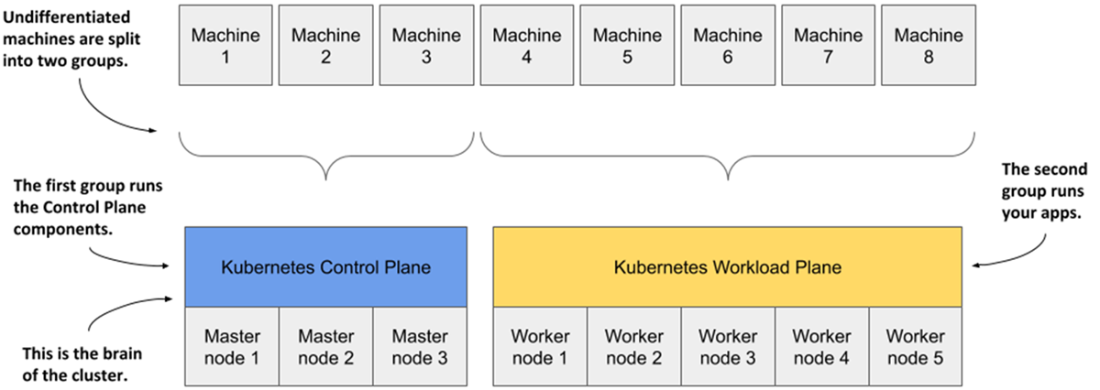
Computers in a Kubernetes cluster are divided into the control and the workload plane.
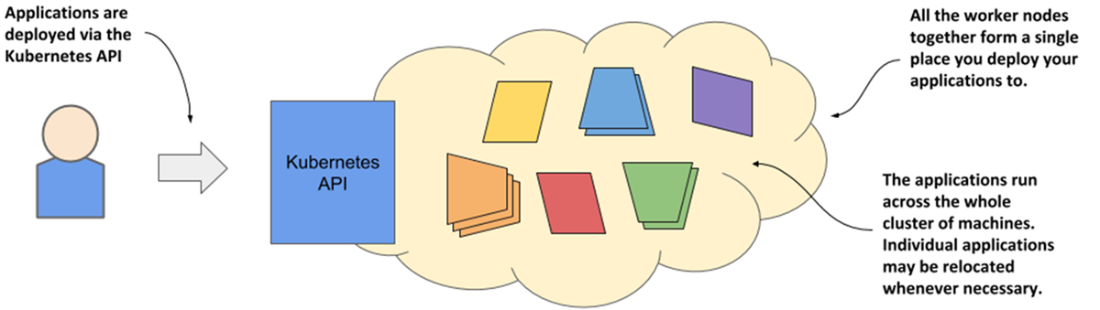
Kubernetes exposes the cluster as a uniform deployment area
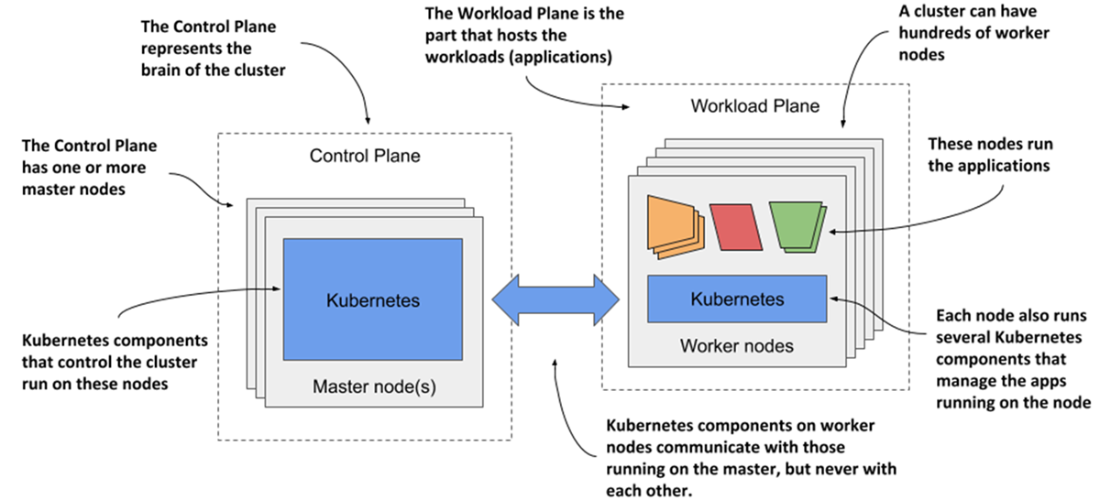
The two planes that make a Kubernetes cluster
The components of the Kubernetes control plane
The Kubernetes components that run on each node
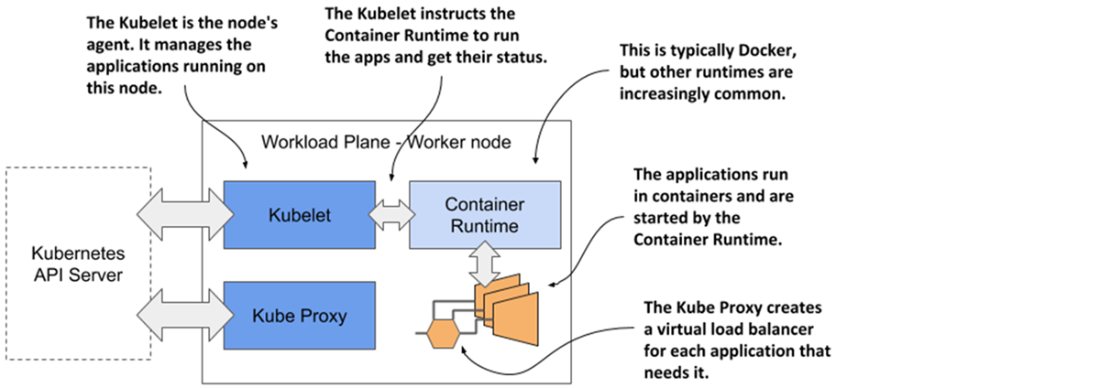
Deploying an application to Kubernetes
Summary
- Kubernetes is the Greek word for “helmsman.” Just like a ship’s captain oversees the ship while the helmsman steers it, you oversee your computer cluster, while Kubernetes performs the everyday management tasks.
- Kubernetes is pronounced koo-ber-netties. Kubectl, the Kubernetes command-line tool, is pronounced kube-control.
- Kubernetes is an open source project built on Google’s vast experience in running applications on a global scale. Thousands of individuals contribute to it today.
- Kubernetes uses a declarative model to describe application deployments. After you provide a description of your application to Kubernetes, it brings it to life.
- Kubernetes is like an operating system for the cluster. It abstracts the infrastructure and presents all computers in a data center as one large, contiguous deployment area.
- Microservice-based applications are more difficult to manage than monolithic applications. The more microservices you have, the more you need to automate their management with a system like Kubernetes.
- Kubernetes helps both development and operations teams do what they do best. It frees them from mundane tasks and introduces a standard way of deploying applications both on-premises and in any cloud.
- Using Kubernetes allows developers to deploy applications without the help of system administrators. It reduces operational costs through better utilization of existing hardware, automatically adjusts your system to load fluctuations, and heals itself and the applications running on it.
- A Kubernetes cluster consists of one or more control plane nodes and multiple worker nodes. The Kubernetes components running on the control plane nodes control the cluster, while the worker nodes run the deployed applications or workloads.
- Using Kubernetes is not too difficult, but managing it is hard. An inexperienced team should use a Kubernetes-as-a-Service offering instead of deploying Kubernetes by itself.
 Kubernetes in Action, Second Edition ebook for free
Kubernetes in Action, Second Edition ebook for free