4 Creating Consumer Applications
This chapter focuses on the consumer side of Kafka: how applications read at scale, coordinate safely, and stay correct. It clarifies subscribing to topics versus explicitly positioning within a stream, shows how batching and timeouts shape throughput and latency, makes consumer groups and rebalances concrete, and surfaces typical pitfalls such as lag, duplicates, and ordering. It also touches on using a REST proxy as a lightweight integration option so teams can access Kafka over HTTP. The outcome is a set of practices for building consumer logic that’s reliable, efficient, and easy to operate.
- Receiving messages from Kafka: Explains how consumers read records, subscribe to topics or explicitly control their position in the stream (offsets), and how batching and timeouts influence throughput and latency.
- Principles of parallel message reception: Describes partition-based parallelism via consumer groups, assignment of partitions to consumers, and how rebalances occur as members join or leave.
- Common challenges in Kafka consumer handling: Highlights the most frequent issues—consumer lag, handling duplicates, and maintaining ordering—and frames how design choices affect each.
- Accessing Kafka via HTTP: Introduces Kafka REST Proxy as a lightweight way for applications to consume data without native clients.
- Utilizing data compression in Kafka: Summarizes why and when to use compression to reduce data size and improve efficiency, noting the impact on performance characteristics.
4.1 Field notes: Consumer patterns and trade-offs
The team shifts focus to building the consumer application that aggregates data from two Kafka topics—customer profiles (keyed by customer ID) and transactions (keyed by transaction ID)—with aggregation centered on customer ID. What initially seemed simple reveals multiple operational and architectural trade-offs.
- Consumer design challenges: determining the right number of service instances, controlling how much data is fetched per request to avoid memory pressure, and ensuring timely failure detection in the cluster.
- Configuration burden: like producers, consumers require careful tuning to work reliably and efficiently.
- Fallback integration path: REST Proxy offers a familiar HTTP interface for producing and consuming, useful as a pragmatic backup or for diverse environments.
- Trade-offs: REST is approachable but adds HTTP overhead; native Kafka libraries provide full features with better throughput and lower latency.
- Aggregation approach: feasible directly in the application using Java stream programming, slated for the next phase.
Outcome: the team commits to exploring consumer configurations and scaling strategies, keeps REST Proxy as a contingency, and plans to implement in-app Java-based aggregation next.
4.2 Organizing consumer applications
This section explains how Kafka consumers read data using a pull model and how to scale consumption with consumer groups. Consumers connect to the cluster, subscribe to topics, and repeatedly poll for new records. Processing is decoupled from offset updates: committing offsets marks records as seen, not necessarily fully processed. Parallelism is achieved via consumer groups, where partitions are exclusively assigned to one consumer instance within a group, while multiple groups can consume the same topic independently.
- Subscribe to one or more topics and poll regularly for new records.
- Receive batches when data is available or a timeout elapses.
- Deserialize records.
- Process records according to application logic.
- Update offsets in Kafka to acknowledge receipt (not guaranteed processing).
Consumer message reception involves periodic polling, receiving available batches, deserializing, processing, and acknowledging via offsets.

Consumers coordinate in consumer groups to split work across partitions for parallel processing. Within a group, each partition is handled by only one consumer instance at a time, ensuring ordered processing per partition. Different services can run as separate consumer groups and consume the same topic independently without affecting each other.
Each service can consume the same topic independently as its own consumer group.
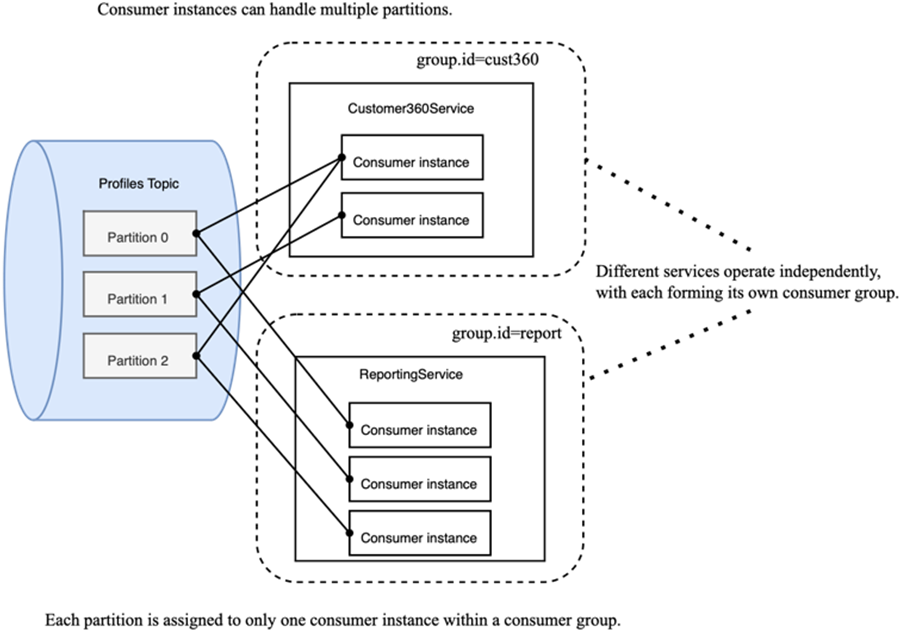
Overall, the section frames the consumer loop, clarifies offset semantics, and introduces consumer groups as the foundation for scalable, partition-aligned parallel consumption.
4.3 Receiving a message
This section explains how Kafka consumers fetch, process, and track progress, and how to scale, coordinate, and tune them for reliability and throughput.
- Consumer read cycle: A consumer joins a group, receives partition assignments, polls for new records, deserializes and processes them, then advances its position by committing offsets. A commit records where to resume; it doesn’t acknowledge records individually.
- Parallelism with consumer groups: Partitions enable parallel reads. Within a consumer group, each partition is owned by a single consumer instance, ensuring each record is processed once by the group. Multiple services needing the same data use distinct groups. Consumers can subscribe to multiple topics; assignment strategy is configurable.
- Customer360 initial setup: Consumers connect via bootstrap servers, use string deserializers for JSON, share
group.id=cust360, and apply topic-specificclient.idprefixes. The team documents operations and IDs with AsyncAPI. - Coordination roles: A broker-side group coordinator manages group membership and distributes assignments. A client-side group leader computes assignments using the configured
partition.assignment.strategyand reports to the coordinator. Consumers only talk to the coordinator and fetch from partition leaders. - Offset management: Offsets are tracked per group in
__consumer_offsets.enable.auto.commitcontrols periodic auto-commits; many systems prefer manual commits for stronger delivery guarantees. If no offset exists,auto.offset.resetgoverns where to start (e.g., earliest or latest). - Customer360 offset policy: Manual commits (
enable.auto.commit=false) to avoid loss; start from earliest if no offsets, requiring idempotent processing. - Batch sizing and flow control: Tune throughput vs latency and memory via:
fetch.min.bytesandfetch.max.wait.ms(wait to build bigger batches),fetch.max.bytesandmax.partition.fetch.bytes(caps per fetch/partition),max.poll.records(limit by record count).
- Rebalances and timeouts: Group membership changes (join/leave/fail) trigger partition redistribution. Two styles:
- Eager: revoke all, then reassign (pause all consumers).
- Cooperative: move only what’s needed (minimize pauses).
heartbeat.interval.ms,session.timeout.ms(broker-driven removal if missed), andmax.poll.interval.ms(consumer self-removal if processing takes too long). - Static group membership: Set a stable
group.instance.idto preserve assignments across brief restarts (within session timeout) and avoid unnecessary rebalances. - Assignment strategies:
- RangeAssignor (default): sequential per consumer; aligns same-index partitions across topics (useful for co-partitioned joins).
- RoundRobinAssignor: evenly distributes partitions; can cause larger movement on rebalance.
- StickyAssignor: balances while preserving existing placements where possible.
- CooperativeStickyAssignor: incremental changes to minimize disruption during rebalance.
- Next-gen rebalance protocol: Moves assignment logic to brokers for consistency and simpler operations. A combined
ConsumerHeartBeatAPI handles heartbeats and assignment with server-side assignors (even distribution, stickiness, rack awareness). Broker configs includegroup.consumer.assignorsand heartbeat/session limits. No group leader; available only in KRaft clusters. - Explicit positioning: Beyond subscriptions from last commit, consumers can programmatically set positions by exact offsets or by timestamp-derived offsets. With direct assignment,
group.idis unused and positioning is fully controlled in code. - Compacted topics: Client API is unchanged. Expect at least the latest record per key; older records may appear until compaction catches up. Choose keys carefully to match compaction needs.
- Customer360 implementation notes: Two consumer sets read profiles and transactions with distinct
client.idprefixes within the same group. Manual commits with earliest reset. To avoid lost updates when multiple consumers update the same aggregate, use optimistic locking (version/timestamp checks and retries). An alternative is a single stream-processing service to centralize updates, trading simplicity in concurrency for potential scaling complexity.
4.4 Common consumer issues
This section summarizes frequent challenges in building Kafka consumer applications and the configuration and design choices that mitigate them.
Consumer scalability challenges
- Consumer-side scalability is bounded by the number of partitions; each partition in a group can be processed by only one consumer instance. Choose partition counts carefully (tuned via experimentation).
- Scale by running multiple instances in the same consumer group; monitor whether they keep up using consumer lag.
- Consumer lag reflects how many produced records haven’t been processed by the group yet; it can be read from JMX or approximated as latest produced offset minus latest committed offset (gaps can exist due to compaction and other factors).
Figure Calculating consumer lag.

- Another scaling model is dispatching polled records to a bounded worker pool sharded by key (preserves per-key ordering). Offset commits must advance only to the highest contiguous completed offset (a watermark) because workers finish out of order.
Optimizing batch size configuration
- Tune batch size for your workload and memory limits; max.poll.records caps the number of records per fetch but actual bytes vary by message size.
- Trade-off: larger batches increase throughput but can raise latency; monitor and adapt over time.
Timeout management strategies
- For long-running processing, tune max.poll.interval.ms and max.poll.records to avoid unnecessary rebalances.
- Health-related timeouts—heartbeat.interval.ms and session.timeout.ms—must balance fast failure detection with stability (avoiding churn).
Error-proof deserialization processes
- Brokers don’t validate payloads; consumers must handle deserialization errors robustly to prevent a single bad message from halting progress.
- Use client-side error handlers; a Schema Registry (see Chapter 6) enforces contracts and compatibility across producers and consumers.
Offset initialization strategies for new consumers
- Decide whether to read historical data or only new messages. The default auto.offset.reset is latest; many use cases need earliest.
Figure Different configurations of auto.offset.reset property.

- Offsets have retention (offset.retention.minutes, default 7 days). If they expire while a group is inactive, auto.offset.reset dictates the restart position. Set retention to cover expected downtime to avoid loss or replay.
Accurate offset commitment practices
- With enable.auto.commit=true, offsets may be committed before processing completes, risking loss on failure.
- For critical paths, manage commits manually and only after successful processing to ensure at-least-once semantics.
Coordinating transactions across external systems
- Kafka doesn’t provide distributed transactions. If you write to a database and commit Kafka offsets, ordering matters:
- Commit offsets first: risk of data loss if DB write fails.
- Write DB first: risk of duplicates if offset commit fails.
- Chapter 6 discusses strategies to manage these trade-offs.
4.5 Data compression
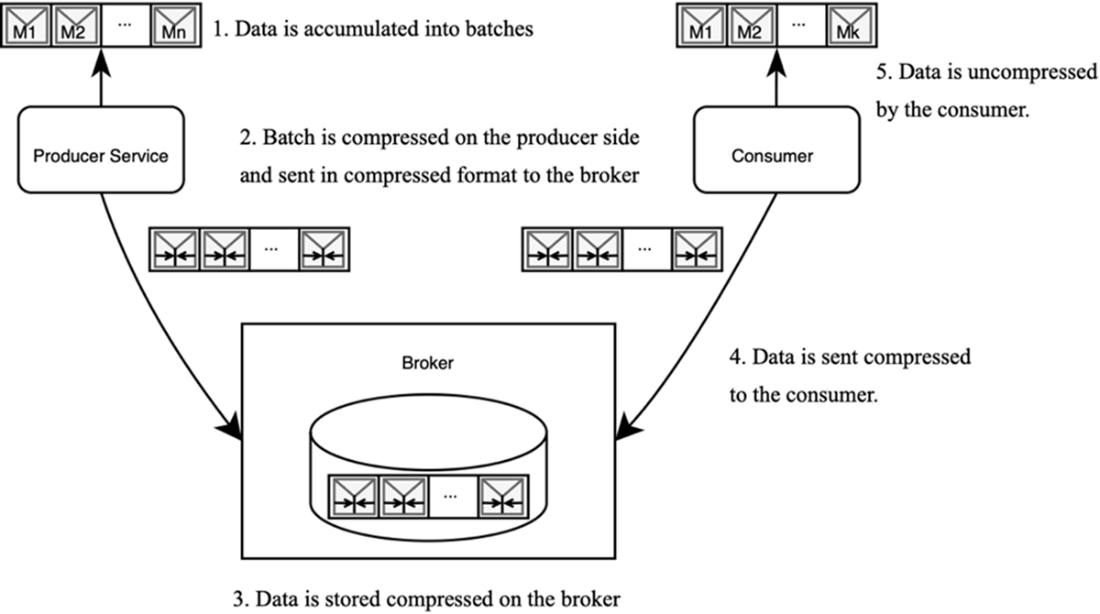
Kafka supports message compression to improve throughput and reduce storage by compressing batches of records. The recommended approach is producer-side compression: the producer compresses each batch, the broker stores and transmits it as-is, and consumers automatically decompress without extra configuration.
-
Producer level:
- Configure via compression.type in the producer: gzip, snappy, lz4, zstd, or none.
- Compression happens per batch, yielding better ratios due to data similarity.
- Data remains compressed end-to-end until the consumer reads it.
-
Broker level:
- Configure via compression.type in the broker (can be per topic): uncompressed, producer (default), or a specific codec (zstd, lz4, snappy, gzip).
- producer retains the producer’s codec (preferred). If the broker enforces a different codec, it must decompress and recompress, adding overhead.
- Compression is more effective on text formats (e.g., JSON) and less on compact binary formats (e.g., Avro). Encrypted data does not compress meaningfully.
- There is a small CPU cost; it’s typically a good trade-off for aggregated workloads (like logs) where throughput matters more than latency.
Figure Compressing the data on producer side.
4.6 Accessing Kafka through REST Proxy
The REST Proxy enables applications to interact with Kafka over HTTP/HTTPS instead of Kafka’s native protocol, acting as an intermediary that translates REST calls into Kafka operations and returns results via HTTP responses. This approach is useful when native Kafka client libraries are unavailable for a chosen language, for rapid prototyping, and for administrative tasks where ultra-low latency is not essential.
- How it works: clients call REST endpoints; the proxy forwards requests to Kafka and returns responses over HTTP.
- Implementations:
- Confluent REST Proxy: HTTP interface for producing/consuming messages and administering topics, brokers, and configurations.
- Kafka Bridge (Strimzi): similar capabilities, optimized for cloud-native and Kubernetes environments.
- Cloud integration: can be fronted by cloud API gateways (e.g., Amazon API Gateway) to simplify authentication/authorization via cloud identity services and to publish APIs for broader access within the ecosystem.
- Best fit: heterogeneous language environments, quick experiments, and operational tooling; not ideal for latency-critical workloads.
Communicating to Kafka through REST.

4.7 Online resources
This section curates authoritative references to deepen understanding and improve practice when building Kafka consumer applications.
- Kafka Consumer Configuration Reference: Comprehensive catalog of consumer properties, defaults, and trade-offs affecting reliability and performance, including polling, heartbeats, commit modes, fetch tuning, isolation levels, deserialization, and security.
- Understanding Kafka Partition Assignment Strategies: Explains how assignments are computed and maintained; contrasts range, round-robin, sticky, and cooperative-sticky strategies; and offers guidance for designing custom assignors.
- Consumer Group Protocol: Walkthrough of group membership and rebalance flows (join, sync, heartbeat), failure handling, and the mechanics behind cooperative rebalancing.
- Kafka Consumer Groups and Offsets: Practical guidance on managing groups and offsets, understanding delivery guarantees, choosing synchronous vs. asynchronous commits, and inspecting lag and offsets in operations.
- Apache Kafka Message Compression: Details codec choices and their end-to-end impact on throughput, latency, and CPU; when to enable compression and where (producer vs. broker) for optimal results.
- Confluent REST Proxy for Apache Kafka: Describes producing and consuming over HTTP, schema handling, and operational considerations for non-JVM integrations and polyglot environments.
- Strimzi Kafka Bridge Documentation: Presents a Kubernetes-friendly bridge for producing and consuming over REST/AMQP, including capabilities and limitations in cloud-native setups.
- What Are Apache Kafka Consumer Group IDs?: Clarifies dynamic vs. static membership, stable group identity, and techniques to reduce disruptive rebalances during deployments and scaling.
- KIP-848: The Next Generation of the Consumer Rebalance Protocol: Outlines protocol improvements for faster, safer, and more incremental rebalances to enhance scalability and availability.
Together, these resources support configuring consumers for correctness and efficiency, selecting assignment and commit strategies, integrating via REST bridges, and preparing for upcoming changes in the consumer protocol.
 Kafka for Architects ebook for free
Kafka for Architects ebook for free