1 Getting to know Kafka as an architect
This chapter introduces the architect’s view of Apache Kafka and event-driven architecture, explaining why adopting Kafka is as much an architectural decision as a tooling choice. It frames Kafka as the backbone for real-time, event-centric systems that decouple producers and consumers, enabling low-latency fan-out, scalability, and resilience across domains like fraud detection, personalization, and predictive maintenance. Alongside the benefits, it highlights the tradeoffs architects must weigh—latency budgets, eventual consistency, ordering, idempotency, and fault tolerance—emphasizing design over code and focusing on patterns, anti-patterns, and long-term sustainability.
The core of Kafka’s model is publish–subscribe over a durable, replicated log: producers publish once, consumers pull and process independently, and messages persist for replay. The chapter surveys the ecosystem’s key pieces—brokers for storage and replication, clients for producing and consuming, and KRaft controllers that manage cluster metadata and availability. It distills foundational principles: reliable delivery with acknowledgments and retries, fault tolerance through replication, immutable commit logs with retention, and the ability to handle high-throughput, low-latency streams that support autonomous services and offline tolerance while accepting the realities of eventual consistency.
Designing data flows requires explicit data contracts and operational discipline. The chapter outlines Schema Registry for governing message structure and compatibility, Kafka Connect for configuration-driven data integration with external systems, and streaming frameworks (such as Kafka Streams or Flink) for real-time transformation, routing, joins, and stateful processing with strong delivery semantics. It closes with operational considerations—capacity planning, security, monitoring, testing, disaster recovery, and choosing between on-premises, managed, or hybrid deployments—then positions Kafka’s strengths in enterprise use: durable event delivery, event sourcing, and real-time enrichment, while noting that Kafka complements rather than replaces databases and should be selected based on fit and long-term architectural goals.
Request-response design pattern

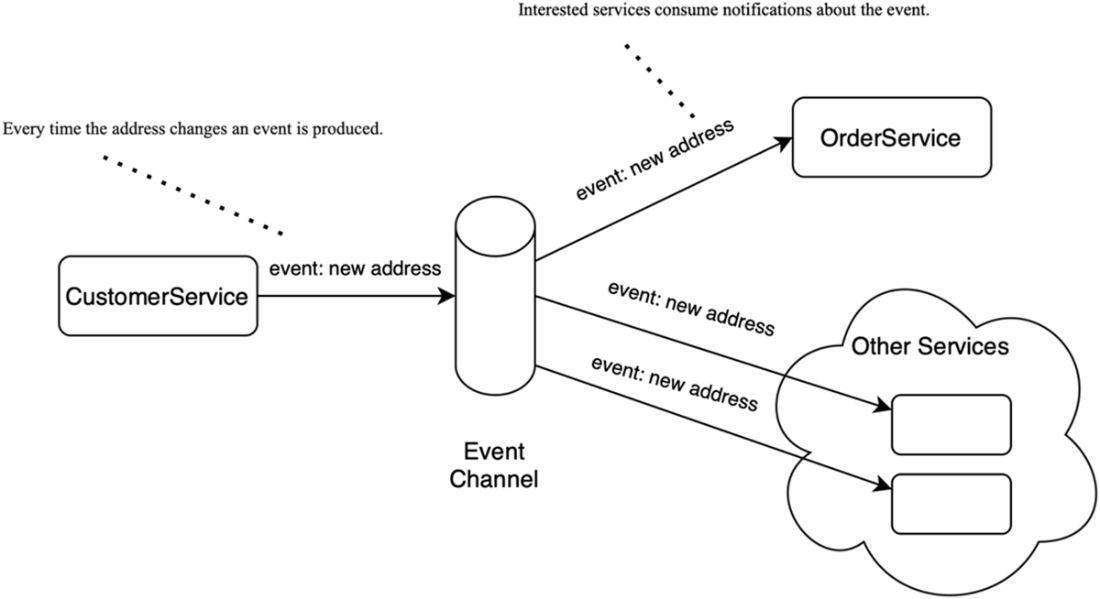
The EDA style of communication: systems communicate by publishing events that describe changes, allowing others to react asynchronously.
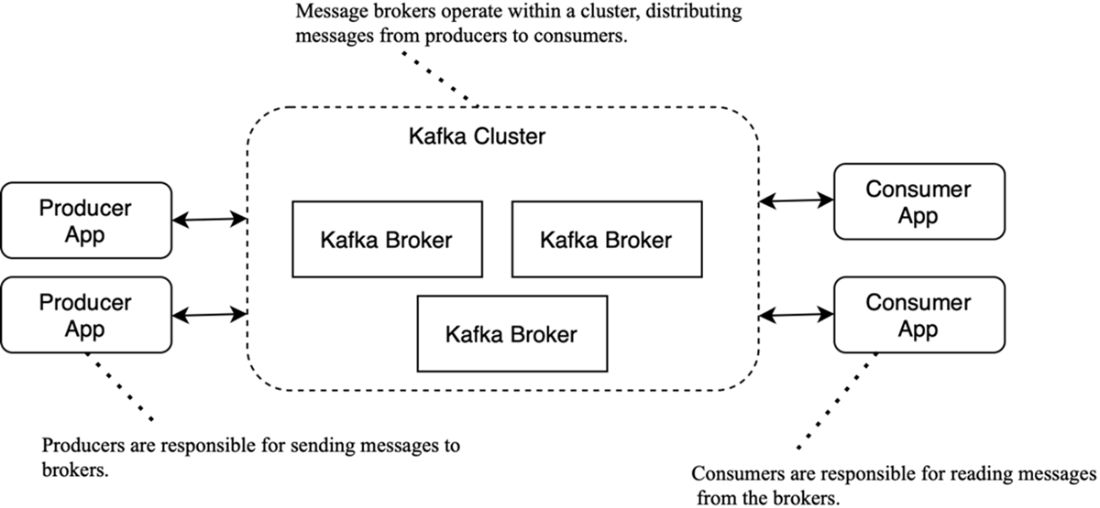
The key components in the Kafka ecosystem are producers, brokers, and consumers.
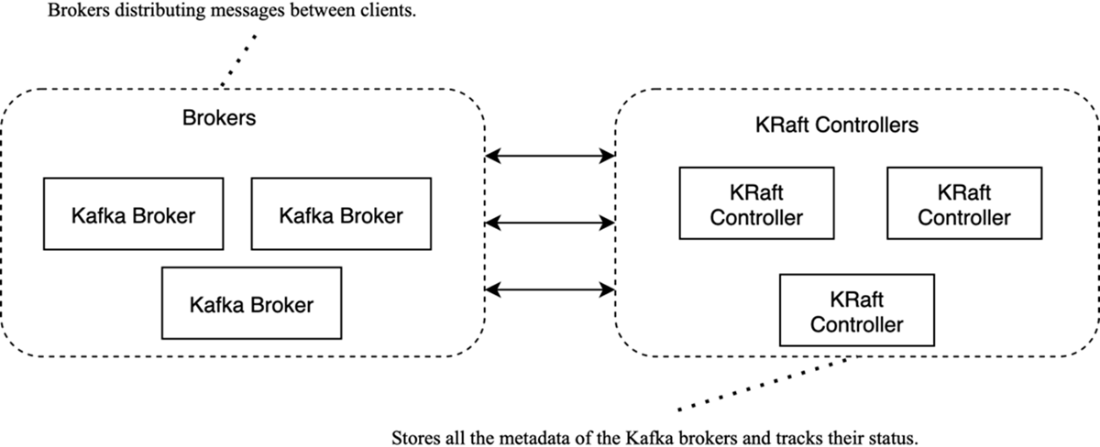
Structure of a Kafka cluster: brokers handle client traffic; KRaft controllers manage metadata and coordination
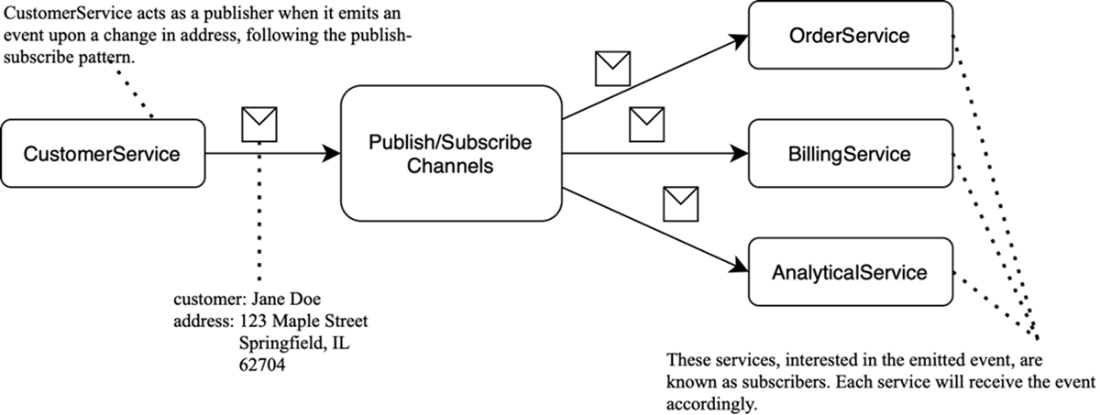
Publish-subscribe example: CustomerService publishes a “customer updated” event to a channel; all subscribers receive it independently.
Acknowledgments: Once the cluster accepts a message, it sends an acknowledgement to the service. If no acknowledgment arrives within the timeout, the service treats the send as failed and retries.
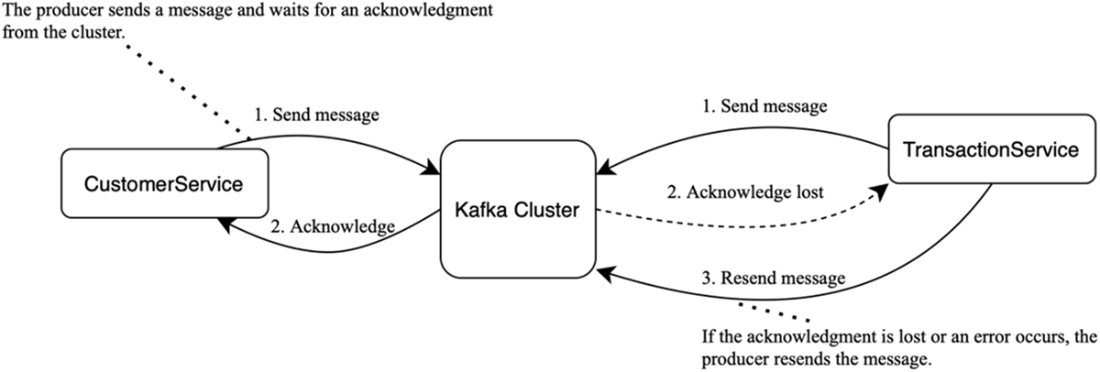
Working with Schema Registry: Schemas are managed by a separate Schema Registry cluster; messages carry only a schema ID, which clients use to fetch (and cache) the writer schema.
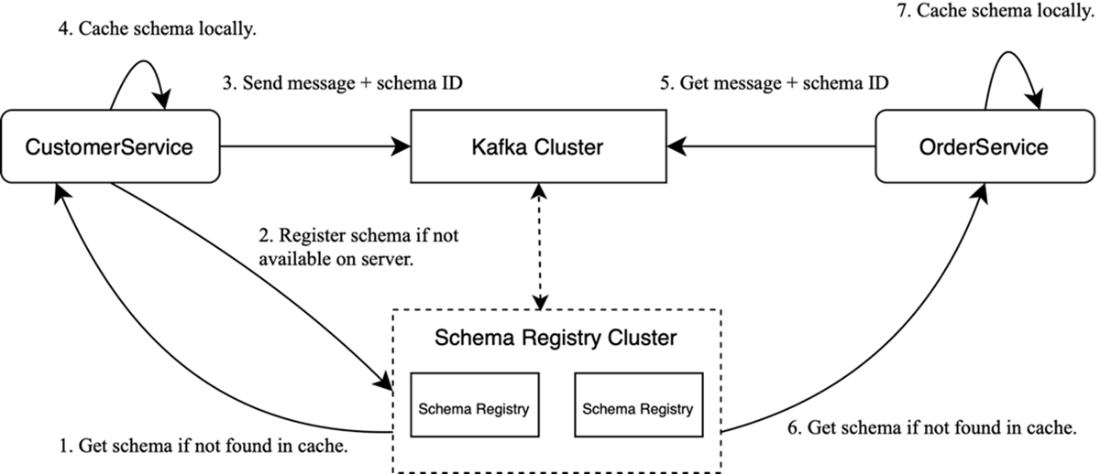
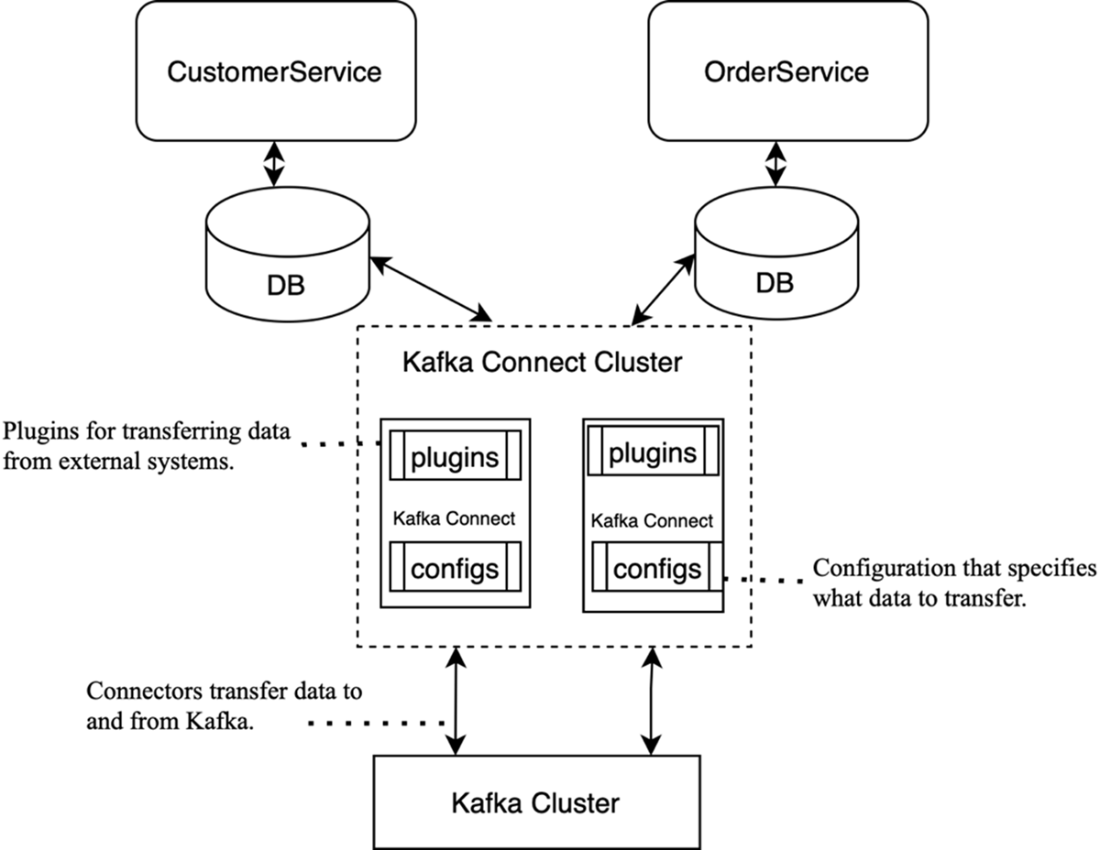
The Kafka Connect architecture: connectors integrate Kafka with external systems, moving data in and out.
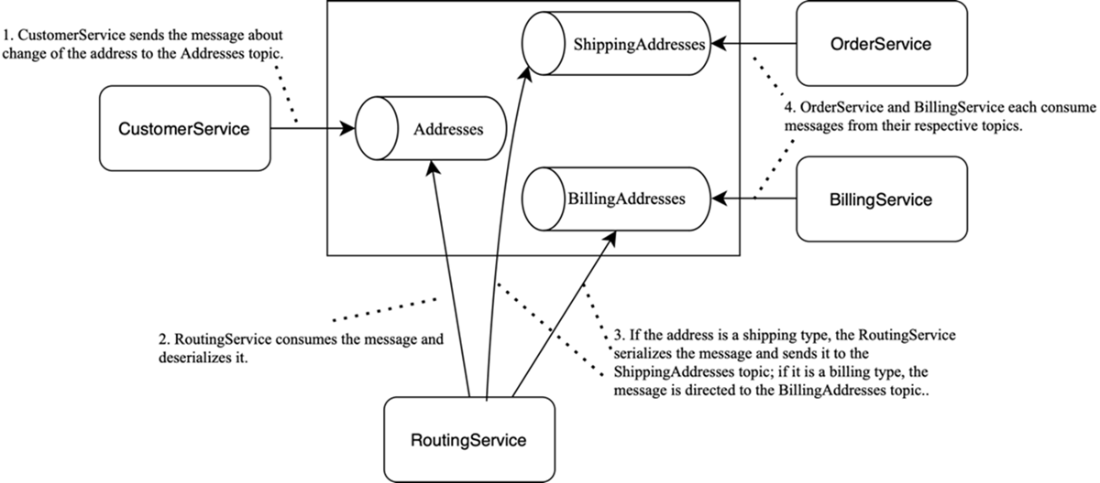
An example of a streaming application. RoutingService implements content-based routing, consuming messages from Addresses and, based on their contents (e.g., address type), publishing them to ShippingAddresses or BillingAddresses.
Summary
- There are two primary communication patterns between services: request-response and event-driven architecture.
- In the event-driven approach, services communicate by triggering events.
- The key components of the Kafka ecosystem include brokers, producers, consumers, Schema Registry, Kafka Connect, and streaming applications.
- Cluster metadata management is handled by KRaft controllers.
- Kafka is versatile and well-suited for various industries and use cases, including real-time data processing, log aggregation, and microservices communication.
- Kafka components can be deployed both on-premises and in the cloud.
- The platform supports two main use cases: message delivery and state storage.
FAQ
What is event-driven architecture (EDA), and how does Kafka enable it?
EDA centers on producing, detecting, consuming, and reacting to events. Instead of synchronous calls between services, producers publish events to a channel and consumers process them independently. Kafka enables this with durable, low-latency event streams, letting many services react to the same event without brittle point-to-point integrations. For example, rather than OrderService calling CustomerService for an address, it subscribes to address-change events and keeps a local copy.
When should architects prefer Kafka and events over synchronous REST?
Choose Kafka when workflows suffer from chained dependencies, fragility, and cascading failures, or when you need low-latency fan-out at scale. Typical cases include high-volume, asynchronous data from many sources (user behavior tracking, logs), and time-critical analytics like fraud detection or predictive maintenance, where near-real-time reactions are required.
How does Kafka’s publish-subscribe model decouple services?
Producers publish messages to topics without knowing who will consume them. Any number of subscribers can independently read the same message and act on it. This enables:
- Fan-out: one event, many consumers
- Autonomy: producers/consumers evolve independently
- Resilience: consumers can be offline and catch up later
Producers typically emit events driven by business needs and aim to make them reusable across known consumer domains.
What reliability guarantees does Kafka provide for message delivery?
Kafka provides end-to-end durability and fault tolerance:
- Producer acks and retries: the cluster acknowledges accepted messages; producers retry on timeouts.
- Persistent storage and replication: messages are written to disk and replicated across brokers.
- Consumer progress tracking and replay: consumers resume from where they left off and can re-read retained data to reprocess.
What is Kafka’s commit log, and why does it matter?
Kafka appends each message to an ordered, immutable log. This preserves arrival order and supports replay, state reconstruction, and auditability. Messages aren’t edited or deleted individually; corrections are sent as new events. Retention controls how long messages remain available (which can be set to “forever” for some use cases).
Who are the key components in Kafka and how do they interact?
The core components are:
- Producers: send messages to brokers.
- Brokers: persist, replicate, and serve messages in a fault-tolerant cluster.
- Consumers: pull messages from topics they subscribe to.
Messages are always persisted to local durable storage; tiered storage can offload older data to cheaper media while keeping recent data on faster disks.
What are KRaft controllers and how do they keep a cluster healthy?
KRaft controllers form Kafka’s control plane. One active controller (with hot standbys) manages cluster metadata and coordination by:
- Storing and replicating the metadata log (topic/partition assignments, broker registrations).
- Monitoring broker heartbeats and handling failures and leadership changes.
Servers can play broker and/or controller roles depending on configuration.
How do Schema Registry, Kafka Connect, and streaming frameworks fit into an architecture?
They address data contracts, movement, and transformation:
- Schema Registry: centralizes message schemas, versioning, and compatibility; messages carry a schema ID for consumers to deserialize correctly.
- Kafka Connect: configuration-driven data pipelines to and from external systems (databases, warehouses, cloud storage) via plugins—no custom code.
- Streaming frameworks (e.g., Kafka Streams, Apache Flink): perform real-time processing (filtering, joins, aggregations, routing) and can implement exactly-once semantics.
Should we use Kafka for messaging, storage, or both?
Both patterns are common:
- Messaging: persist events long enough for subscribers to process or replay after failures.
- Event-sourcing/log storage: retain events indefinitely as the source of truth; consumers rebuild state by replaying logs.
Kafka isn’t a general-purpose query engine; for rich query workloads (e.g., geospatial lookups), databases remain necessary.
What operational and deployment choices matter for enterprises (on-prem vs managed)?
On-premises: maximum control and tuning but responsibility for hardware, security, monitoring, and troubleshooting.
Managed service: easier provisioning and administration with provider SLAs, but potential limits on Kafka version choice, ecosystem availability (e.g., some registries), low-level tuning, and tooling flexibility. Architects must also plan for security, monitoring, sizing (topics, partitions, replication), and cost estimation.
 Kafka for Architects ebook for free
Kafka for Architects ebook for free