Postgres is introduced as a fast-growing relational and general-purpose database that natively speaks SQL and excels at OLTP workloads while ensuring consistency and integrity. Over decades, it has expanded far beyond traditional transactions through a rich ecosystem of extensions, enabling full-text search, time series, geospatial, analytics, and generative AI use cases. Its rising popularity among developers is attributed to three factors: it is open source and community-governed, it is enterprise-ready with steady, incremental releases and broad commercial support, and it is designed for extensibility—an original goal that underpins today’s vibrant extension ecosystem for JSON, vector search, time series, and more.
“Just use Postgres!” is presented as practical guidance rather than dogma: if you already use Postgres and a new requirement arises, first check whether Postgres can meet it before introducing another database. When Postgres fits, you reduce operational complexity by avoiding multiple systems; when it doesn’t, choose a more suitable tool. The chapter sets the tone for the book’s goal—to reveal what Postgres can do so you can make informed, case-by-case decisions.
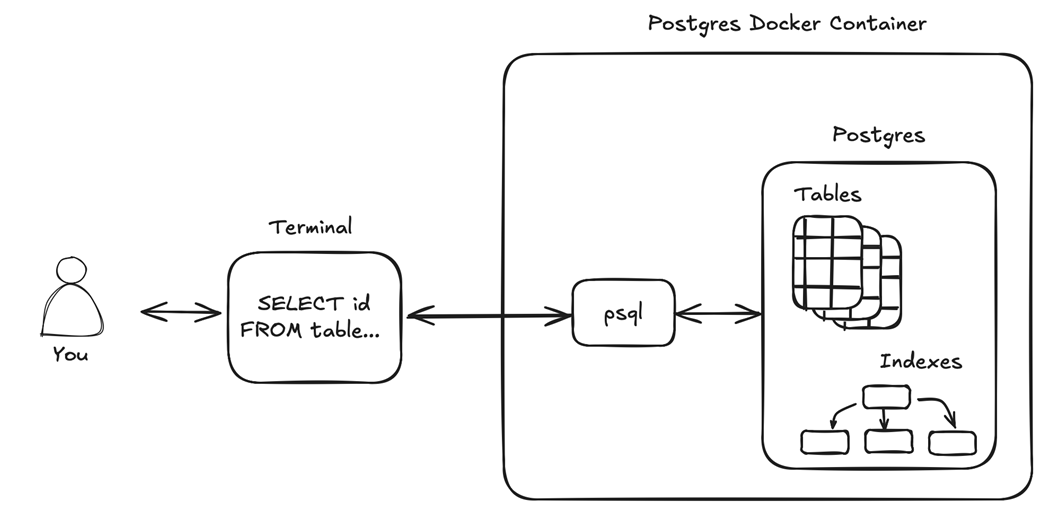
The chapter then moves into hands-on basics: running Postgres in a Docker container and connecting with the built-in psql tool from inside that container. After a quick tour of handy meta-commands, it demonstrates generating mock data entirely in SQL—creating a trades table and using generate_series, random values, arrays, rounding, and timestamps to insert 1,000 realistic rows. It closes with foundational queries you’ll reuse often: counting with filters, grouping and ordering to find most-traded stocks, and aggregating spend to identify top buyers—showcasing how quickly you can get productive with Postgres and preparing you for deeper exploration.
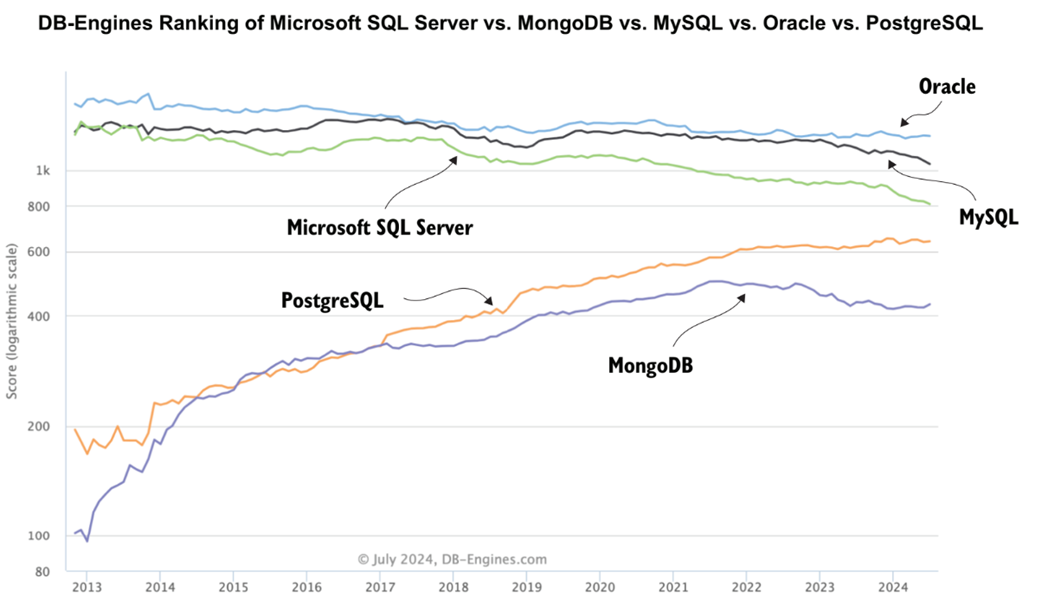
DB-Engines ranking showing Postgres trending up in popularity
How Postgres is deployed and used throughout the book
Summary
Postgres is one of the most popular and fastest-growing databases.
Postgres’s open source nature, enterprise readiness, and extendibility are key factors contributing to its popularity and growth.
The phrase “Just use Postgres” implies that Postgres offers a wide range of capabilities, allowing it to handle use cases far beyond traditional transactional workloads.
Postgres is written in C and can be installed on Windows and a wide range of Unix-based operating systems.
The database can be started as a container in under a minute on any operating system that supports Docker.
Postgres comes with the generate_series function, which can be used to generate mock data of varying complexity.
Postgres “speaks” SQL natively, allowing you to solve various business tasks by crafting simple and elegant SQL queries.
FAQ
What does “Just use Postgres!” actually mean?It’s a community motto that suggests you should first check whether PostgreSQL (often with extensions) can handle your new use case—geospatial, time series, full‑text, vector/AI, analytics—before adding another database. It’s not a claim that Postgres is always the only or best choice; it’s practical guidance to reduce stack complexity when Postgres is already in your toolkit.Why is PostgreSQL so popular among developers?Three main reasons: (1) it’s open source and community‑governed, (2) it’s enterprise‑ready with a long track record of stability and incremental annual releases plus broad commercial support, and (3) it’s extensible by design, with a rich ecosystem that adds capabilities like JSON, time series, full‑text, geospatial, and vector similarity search.Does Postgres fit every workload?No. Treat the motto as guidance, not dogma. Evaluate Postgres first; if it meets your needs, you avoid running multiple databases. If it doesn’t, pick a more suitable system. The goal is informed, pragmatic choices.Why use Docker to run Postgres for this setup?Docker provides a quick, cross‑platform way to spin up a Postgres instance without OS‑specific installers. You can start/stop/remove the container easily, and the official image includes psql, so you don’t need extra tools on your host.How do I start a Postgres container and keep data persistent?Create a Docker volume and run the official image mapping port 5432 and setting POSTGRES_USER/PASSWORD. Mount the volume to the container’s data directory so your data persists across restarts and recreations of the container.How can I verify the container is healthy?List the container (filter by name) to see its status and port mapping, and inspect logs to confirm the “database system is ready to accept connections” message. If startup fails, search for the specific Docker error; solutions are widely documented.How do I connect with psql and which meta‑commands are useful?Exec into the container and run psql with the postgres user. Inside psql: use \? to list meta‑commands, \conninfo to see connection details, and \d to list tables/views/sequences. Type \q to exit.Why wasn’t I prompted for a password when using psql in the container?Because psql connects over a local Unix socket from inside the container, and the image trusts such local connections, no password prompt is required in that context.How can I quickly generate mock data without external tools?Create a table and use generate_series to produce rows, random to vary values, and arrays to pick random symbols (for example, stock tickers). In Postgres 17+, use random(min,max). On earlier versions, compute a range with floor(random()*(max-min+1)+min). Insert the SELECT output directly into your table.What basic SQL queries should I try first?- Count with a filter (count(*) with WHERE) to measure volume; count(*) is optimized to count rows without fetching columns. - GROUP BY with ORDER BY to find most‑traded items. - SUM with GROUP BY and LIMIT to get top buyers or top‑N aggregates. Avoid SELECT * in application code unless you truly need all columns.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Just Use Postgres! ebook for free
Just Use Postgres! ebook for free