1 Large language models: The foundation of generative AI
The chapter opens with the public debut of ChatGPT as a watershed moment that brought large language models (LLMs) into everyday awareness, highlighting both their seemingly magical fluency and their real shortcomings. It argues that a practical understanding of how LLMs work is essential for anyone who will use or build with them, setting expectations for a balanced, pragmatic tour of their strengths, limitations, and societal implications. The authors frame LLMs as a general-purpose capability poised to transform work and communication across domains, while emphasizing the need to navigate hype, manage risks, and cultivate responsible use.
Tracing the evolution of natural language processing, the chapter moves from brittle rule-based systems to statistical methods and then to neural networks and deep learning, culminating in the transformer architecture and attention mechanisms that enabled today’s LLMs. It explains pretraining on vast unlabeled text (self-supervised prediction) and fine-tuning for specific tasks, which together unlocked broad competence without expensive labeled data. With this foundation, the chapter surveys major applications—language modeling and generation, question answering and reading comprehension, coding assistance, content creation, translation, summarization, and emerging logical and scientific reasoning—alongside the rise of multimodal systems that integrate text, vision, and audio.
The authors then examine the field’s core challenges: bias and toxicity inherited from web-scale training data; difficulties controlling outputs, including confident factual errors (hallucinations); and the environmental, economic, and competitive pressures of training and deploying very large models. They profile the key ecosystem players and strategies—from proprietary leaders to open-source efforts and efficiency-focused startups—illustrating how safety techniques, guardrails, deployment choices, and business models shape progress. The chapter closes by urging readers to pair enthusiasm for LLM capabilities with rigor about reliability, fairness, privacy, and sustainability, laying the groundwork for responsible innovation throughout the book.
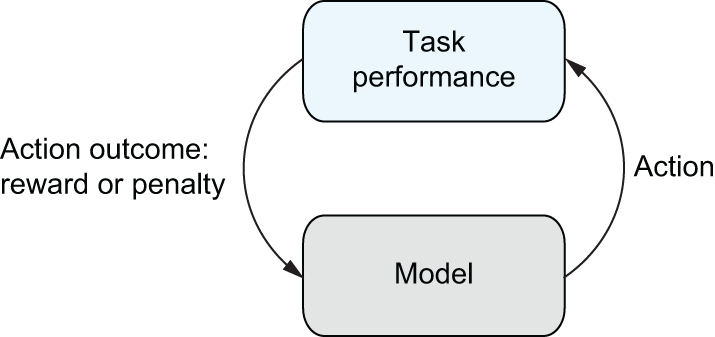
The reinforcement learning cycle
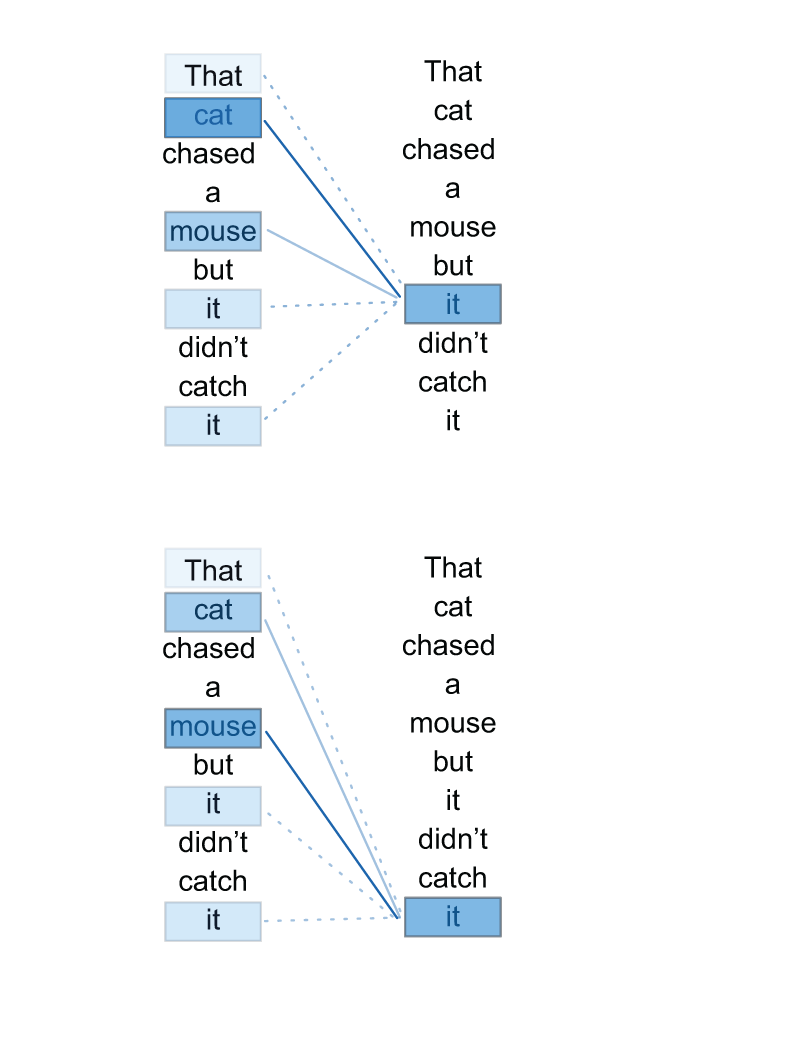
The distribution of attention for the word “it” in different contexts.
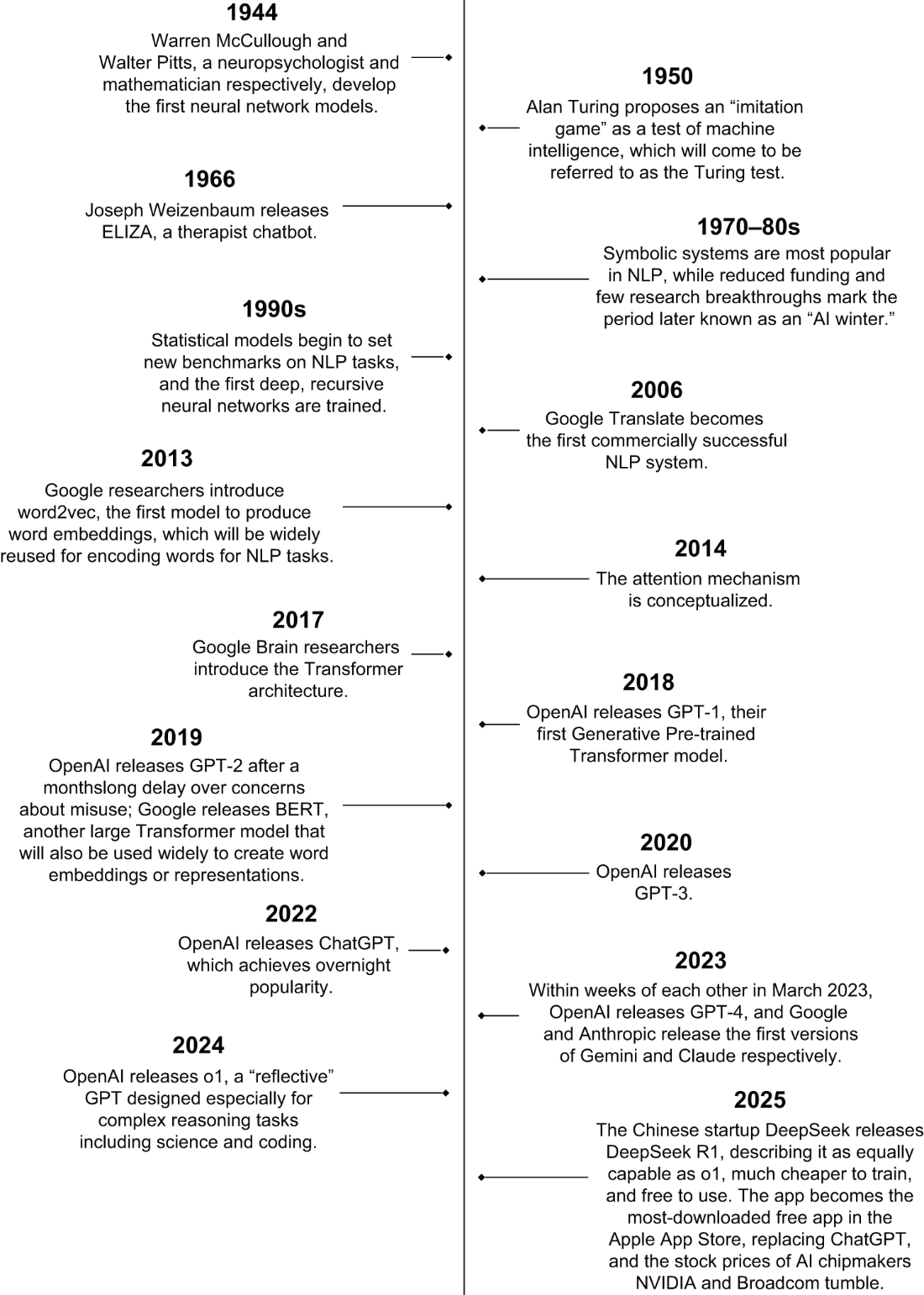
A timeline of breakthrough events in NLP.
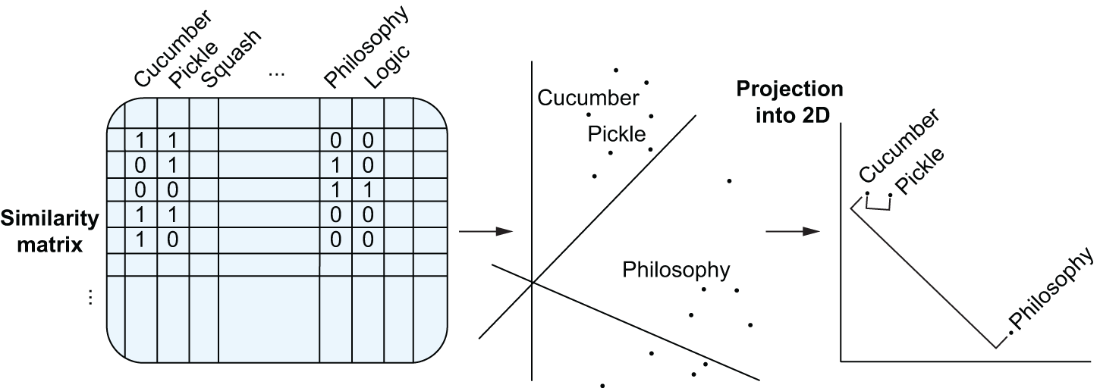
Representation of word embeddings in the vector space
Summary
The history of NLP is as old as computers themselves. The first application that sparked interest in NLP was machine translation in the 1950s, which was also the first commercial application released by Google in 2006.
Transformer models and the debut of the attention mechanism were the biggest NLP breakthroughs of the decade. The attention mechanism attempts to mimic attention in the human brain by placing “importance” on the most relevant information.
The boom in NLP from the late 2010s to early 2020s is due to the increasing availability of text data from around the internet and the development of powerful computational resources. This marked the beginning of the LLM.
Today’s LLMs are trained primarily with self-supervised learning on large volumes of text from the web and are then fine-tuned with reinforcement learning.
GPT, released by OpenAI, was one of the first general-purpose LLMs designed for use with any natural language task. These models can be fine-tuned for specific tasks and are especially well-suited for text-generation applications, such as chatbots.
LLMs are versatile and can be applied to various applications and use cases, including text generation, answering questions, coding, logical reasoning, content generation, and more. Of course, there are also inherent risks, such as encoding bias, hallucinations, and emission of sizable carbon footprints.
In January 2023, OpenAI’s ChatGPT set a record for the fastest-growing user base in history and set off an AI arms race in the tech industry to develop and release LLM-based conversational dialogue agents. As of 2025, the most significant LLMs have come from OpenAI, Google, Meta, Microsoft, and Anthropic.
FAQ
What is a large language model (LLM)?An LLM is a transformer-based neural network trained on massive text corpora to predict the next token in context. This self-supervised training yields general-purpose language capabilities—generation, comprehension, and reasoning—that can be adapted to many tasks and refined with additional data or constraints.How did NLP evolve into today’s LLMs?NLP progressed from brittle rule-based systems (e.g., ELIZA) to data-driven statistical approaches in the 1990s, then to neural networks as data and compute grew. The introduction of attention and transformer architectures enabled parallel processing and long-range context handling, unlocking today’s large-scale, general-purpose LLMs.What is “attention,” and why did transformers change NLP?Attention lets a model weight the most relevant parts of an input sequence when generating each token. Transformers apply self-attention across entire sequences and compute in parallel, capturing long-range dependencies more efficiently. This made training on far larger datasets feasible and set new performance records.How are LLMs trained, and what does fine-tuning mean?LLMs are pre-trained with self-supervised objectives (e.g., next-token or masked-token prediction) on vast unlabeled text. They can then be fine-tuned—further trained on targeted data—to specialize for tasks like classification, translation, or dialogue. Some systems also use reinforcement signals to refine behavior.What kinds of tasks and applications can LLMs handle?Common uses include conversation, language modeling and text generation, question answering, translation, summarization (extractive and abstractive), content creation, coding assistance, and various reasoning tasks (math, science, commonsense). They also support grammar correction, terminology learning, and other linguistic utilities.How are LLMs used for coding, and what are their current limits?Code-focused LLMs generate snippets from natural language, autocomplete, propose alternatives, and translate comments into code (e.g., tools like GitHub Copilot built on Codex). They boost productivity but still struggle with complex, open-ended engineering and fully autonomous software development. Newer reasoning-focused models have improved on benchmarks, yet human oversight remains essential.What are hallucinations, and why do LLMs produce them?Hallucinations are fluent but incorrect outputs. They arise because LLMs predict plausible text rather than verify facts, can reflect errors in training data, and may be steered by adversarial prompts. The result can be confident, misleading statements—highlighting the need for grounding, verification, and guardrails.How do training data and bias affect LLM behavior?LLMs mirror patterns in their data. Because internet-scale corpora contain stereotypes and uneven coverage, models can produce disparate outputs across identity attributes (bias). Prior work on word embeddings showed gendered occupational associations; similar effects can surface in LLMs, and eliminating them fully is challenging.What are the costs and sustainability concerns of LLMs?Training state-of-the-art models requires thousands of specialized chips over weeks, costing millions of dollars and significant energy. Studies estimate substantial carbon emissions for training, and inference at scale can consume even more. High compute needs can concentrate power among a few firms, though open-source, efficiency, and model compression efforts aim to widen access.Who are the major players in generative AI, and how do their approaches differ?- OpenAI: ChatGPT, GPT-4/4o, Sora, and o1; rapid releases, multimodal and reasoning focus; deep partnership with Microsoft.
- Google: From LaMDA to Gemini and Project Astra; strong research base and cautious, principles-led rollout across products.
- Meta: Llama 2/3 and an open-access strategy enabling on-device and researcher use.
- Microsoft: Ecosystem integration via Copilot and Bing; productization at enterprise scale.
- Anthropic: Claude models and “Constitutional AI,” emphasizing safety and alignment.
- Others: DeepSeek (efficient MoE models), Mistral (compact open models), Perplexity (AI search with citations), xAI’s Grok, plus image/video leaders like Midjourney, Stability AI, and Runway.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Introduction to Generative AI, Second Edition ebook for free
Introduction to Generative AI, Second Edition ebook for free