1 Generative AI in Computer Vision
This chapter introduces Generative AI in the context of Computer Vision and situates it within the broader field of Artificial Intelligence. It clarifies how generative models learn data distributions to synthesize new visual content, in contrast to discriminative models that classify or detect. At the intersection of AI, Computer Vision, and Generative AI, systems now interpret, manipulate, and create images with increasing control—from random generation to conditional and text-guided synthesis—powering capabilities such as image-to-image translation, super-resolution, style transfer, and text-to-image generation. The chapter sets a roadmap for the field, highlighting rapid progress, cross-industry impact, and the shifting boundaries of creativity and authorship.
Concrete applications demonstrate this impact at scale. In film and television, digital face re-aging has moved from labor-intensive visual effects to generative pipelines that deliver temporal consistency, identity preservation, fine-grained artistic control, and major efficiency gains. For autonomous vehicles, photorealistic, diverse simulation environments enable safe, repeatable training and validation across rare and hazardous scenarios, accelerating development. In healthcare, synthetic medical imagery augments scarce datasets, preserves privacy, balances classes, and can ease annotation burdens—improving robustness and performance of diagnostic models.
Historically, the field evolved from early computer graphics experiments and foundational neural network research to deep learning breakthroughs, including VAEs and the GAN family (e.g., DCGAN, StyleGAN, BigGAN), followed by the rise of diffusion models and Transformer-based approaches that connect vision and language (e.g., ViT and CLIP) and enable powerful text-to-image systems and latent diffusion. The chapter proposes a taxonomy spanning levels of control (random, conditional, text-driven) and core architectures (autoencoders, adversarial networks, diffusion models, transformers), outlining their respective strengths, trade-offs, and selection criteria. It concludes with a forward-looking view that pairs technical momentum with ethical responsibility around copyright, misuse, and the role of human creators.
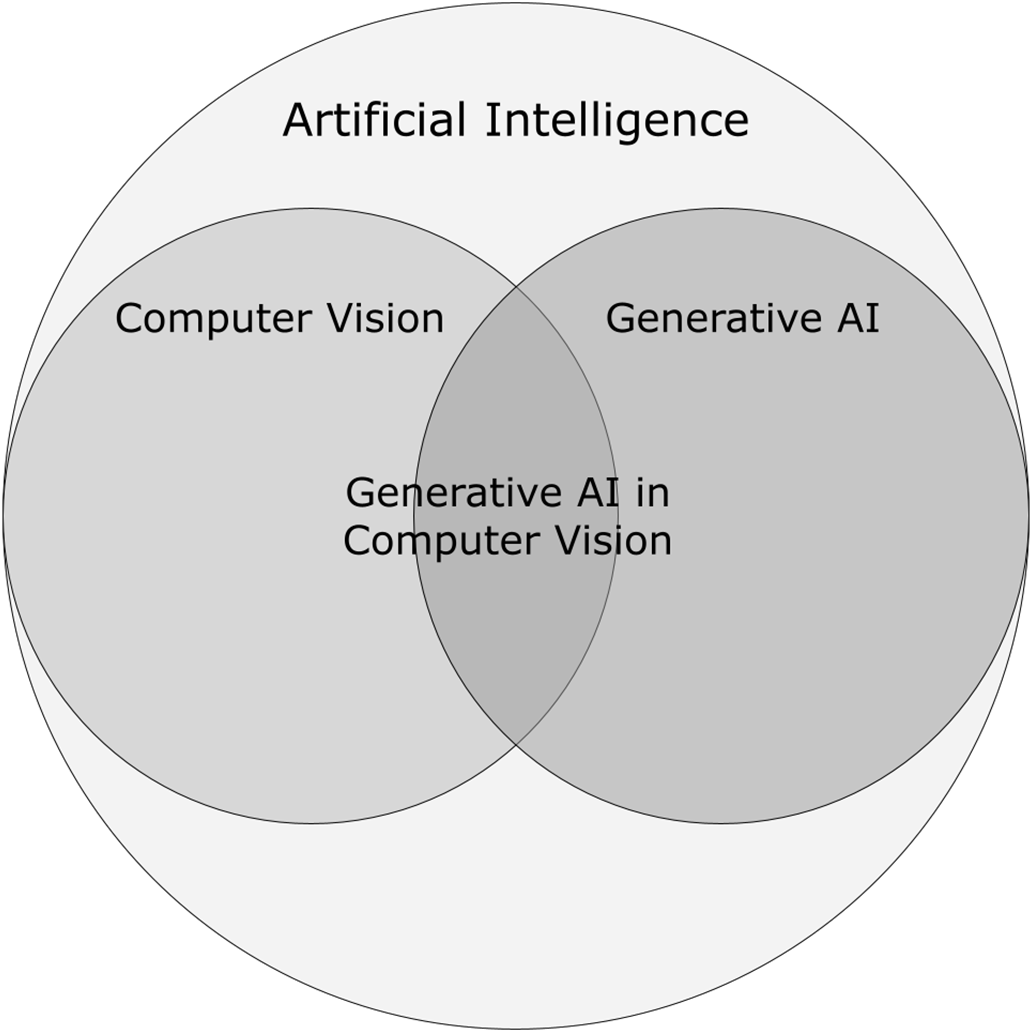
A Venn diagram illustrating the relationship between Artificial Intelligence, Computer Vision, and Generative AI
The rapid improvement in synthetic image quality illustrated using AI-generated human faces. In less than 5 years, Generative AI progressed from blurry, low-resolution images to photorealistic, high-resolution faces.

Illustration of random image generation process
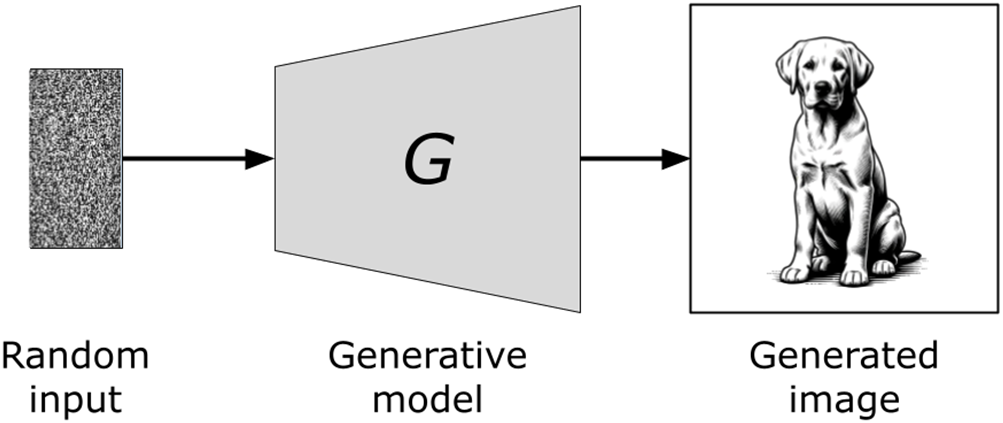
Illustration of conditional image generation process
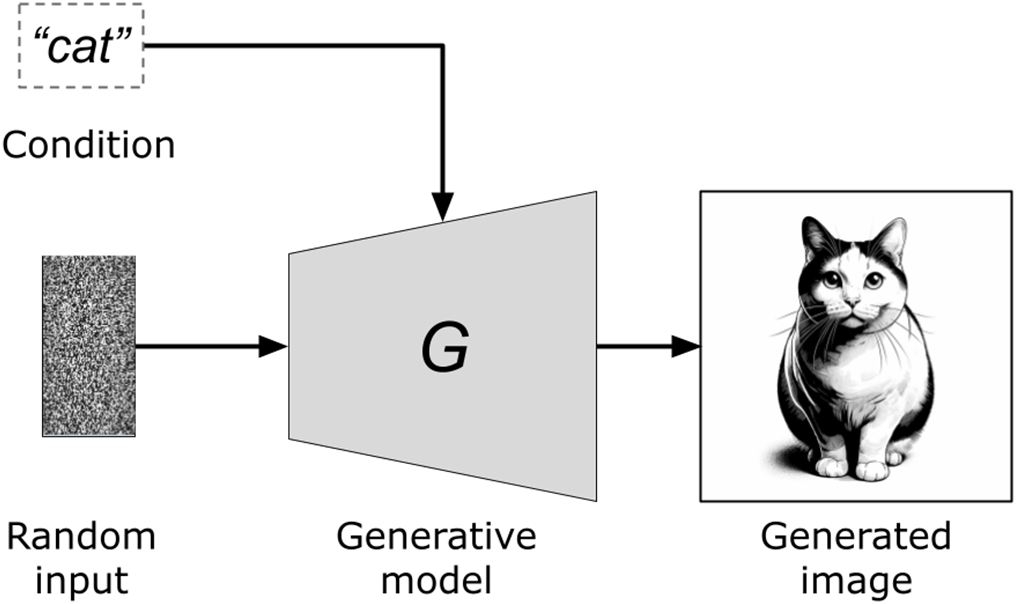
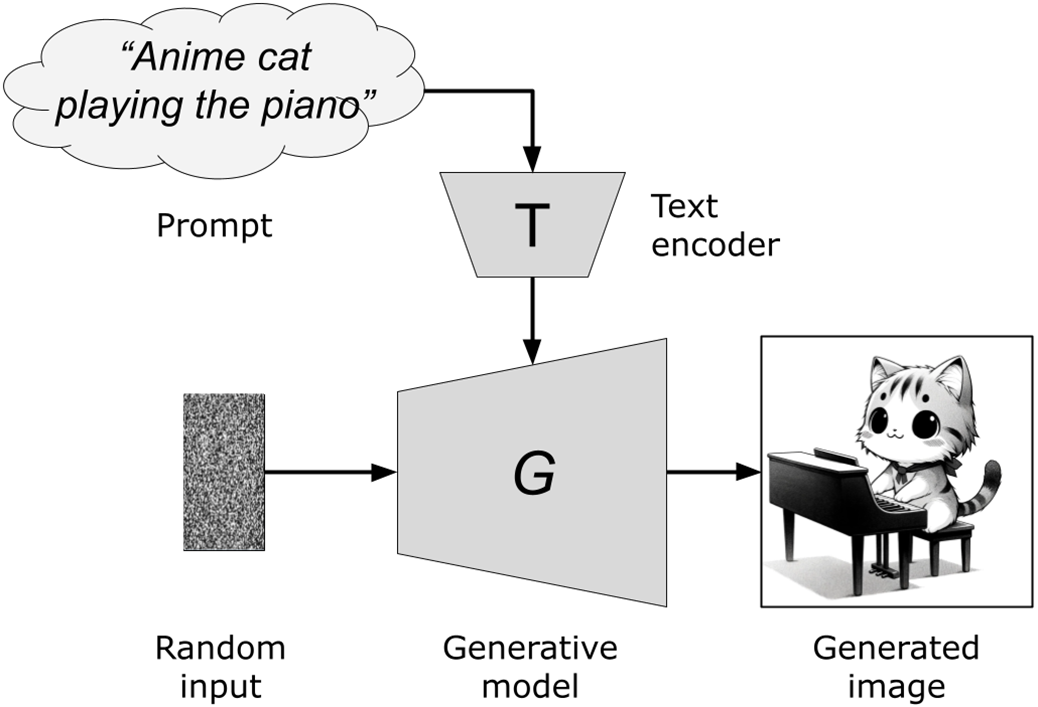
Illustration of text-to-image generation process
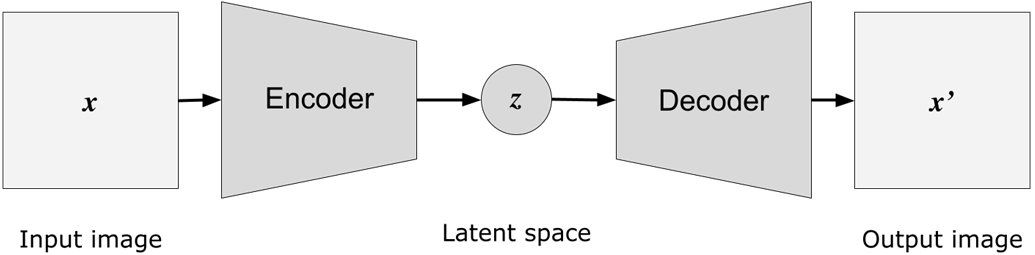
High-level autoencoder model architecture
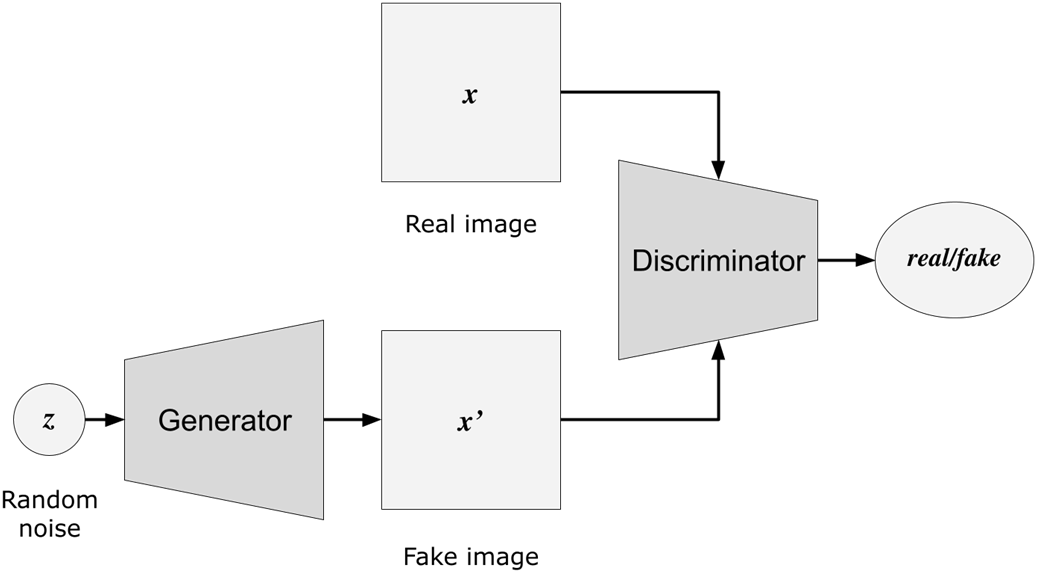
High-level Generative Adversarial Network (GAN) architecture
High-level architecture of a diffusion model

High-lecure
Summary
- Artificial Intelligence (AI): Systems designed to perform tasks requiring human-like cognition.
- Computer Vision: A subset of AI focused on enabling machines to interpret and understand visual data.
- Generative AI: AI models that create new content based on learned patterns. Its intersection with Computer Vision enables the creation and manipulation of visual content.
- Model Architectures
- Autoencoders: Learn compressed data representations through encoding and decoding processes.
- GANs (Generative Adversarial Networks): Use a two-network structure (generator and discriminator) in a competitive process to create realistic images.
- Diffusion Models: Transform random noise into coherent images through iterative noise addition and removal.
- Transformers: Use self-attention mechanisms to efficiently capture global dependencies in data.
- Vision Transformers: Apply transformer principles to image patches for sophisticated visual processing.
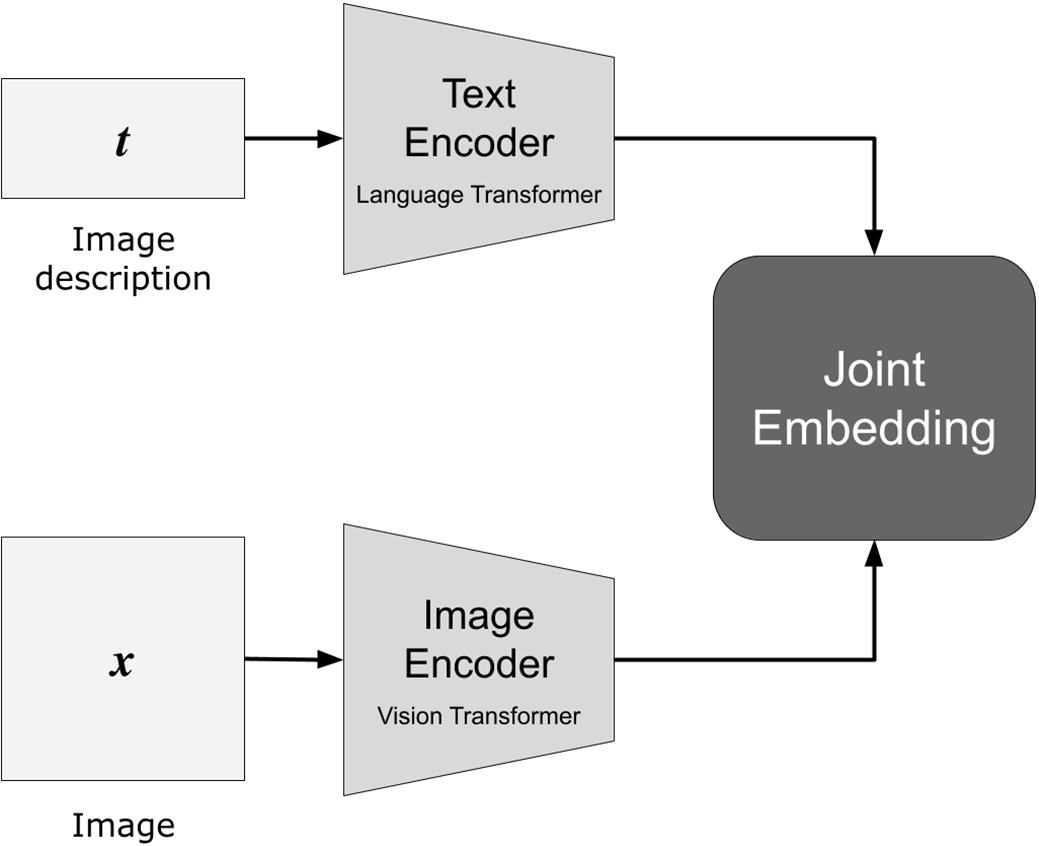
- CLIP (Contrastive Language–Image Pretraining): Combines text and image understanding for text-aligned image creation.
 Image Generation Models ebook for free
Image Generation Models ebook for free