This chapter establishes why deliberate database design is essential to reliable software. Poorly designed data storage leads to redundancy, slow queries, bugs, and a degraded user experience, while a well-structured schema enables efficient querying, integrity, and scalability. Aimed at beginners, the chapter sets the foundation by introducing core relational concepts and the basics of SQL so readers can reason about structure, integrity, and performance as they progress through the book.
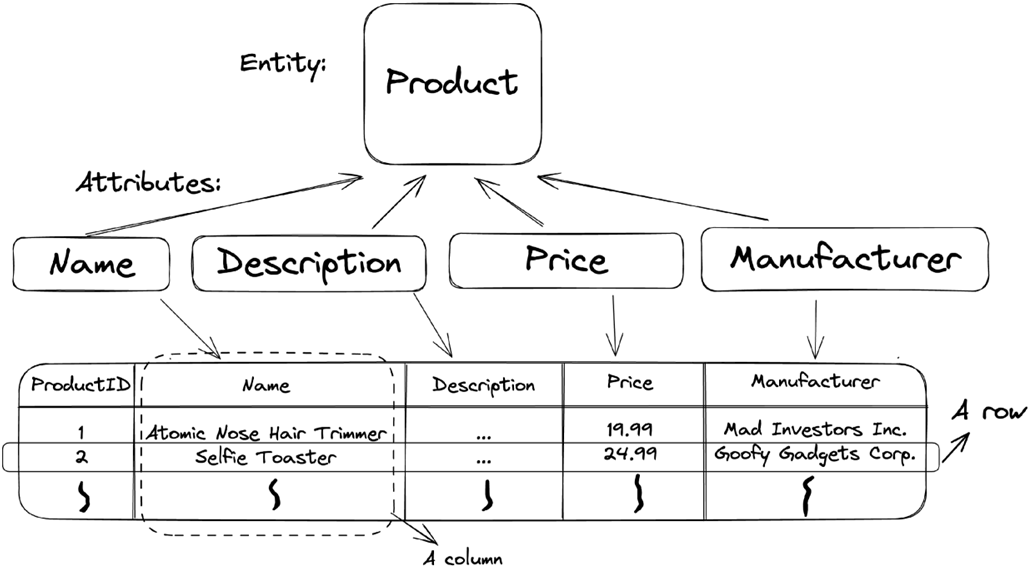
It contrasts ad hoc spreadsheet use with relational databases, noting that as data volume and complexity grow—and as needs like access control, consistency, and integrity emerge—relational databases become the right tool. The chapter defines tables, rows, and columns as representations of entities and attributes, and explains primary keys as unique identifiers for rows. It also shows how cramming multiple entities into one table creates redundancy and anomalies (such as insert and delete anomalies), underscoring how thoughtful modeling prevents these pitfalls. The role of relational database management systems is introduced as the software layer that stores, secures, and serves data.
On SQL, the chapter highlights its declarative nature and cross-RDBMS consistency. It introduces the SELECT, FROM, and WHERE clauses for filtering numeric and text data, logical operators for combining conditions, common data types, and core aggregate functions (COUNT, SUM, AVG, MAX, MIN). GROUP BY is presented with best practices: include grouped columns in SELECT and avoid non-aggregated columns that aren’t grouped. Finally, it covers essential data definition tasks—creating tables with appropriate types, NOT NULL constraints, and primary keys; inserting single or multiple rows; altering table structures; and cautiously dropping tables—providing the practical toolkit needed to design and manage relational schemas.
Summary
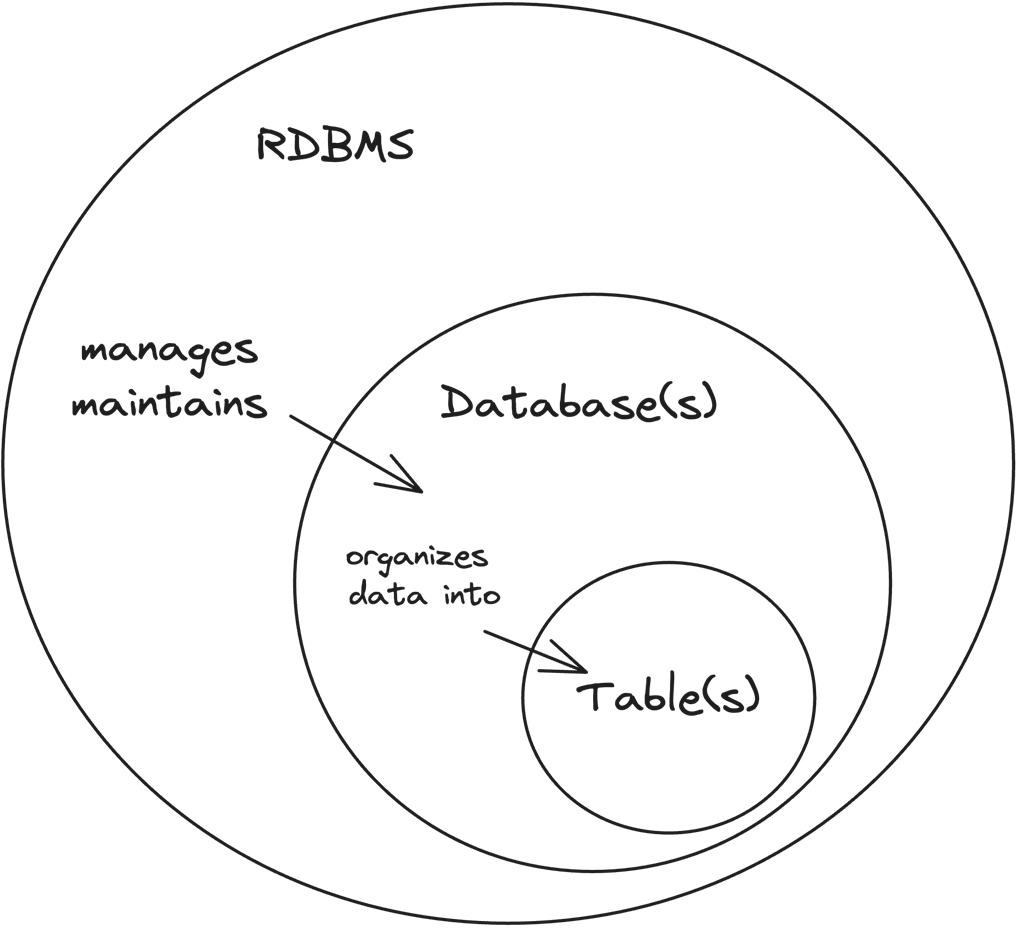
A relational database is a collection of tables that store data.
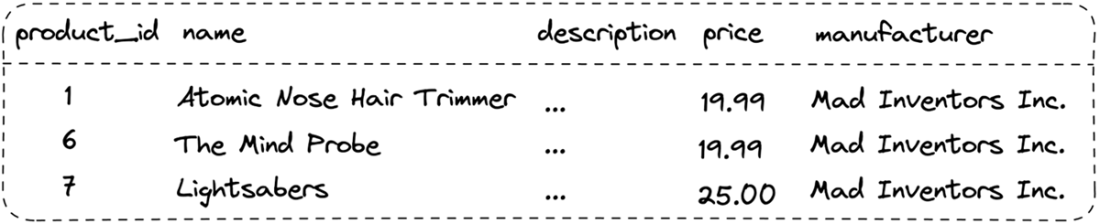
A table is used to represent an entity or a relationship between entities in a database.
An entity is an object or concept that can be described by many attributes.
An RMDBS is software that interacts with the underlying hardware and operating system to physically store and manage data in relational databases.
Filtering data requires help from at least three SQL clauses, SELECT, FROM, and WHERE.
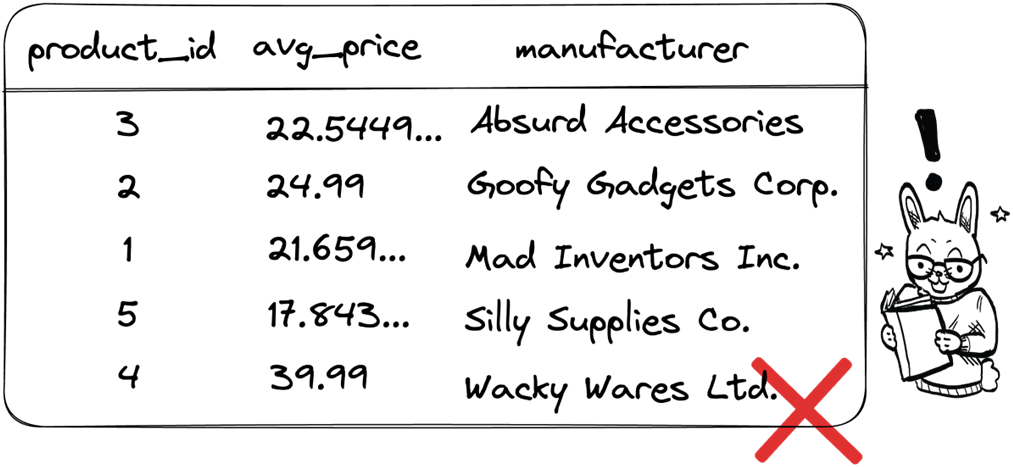
Data aggregation functions are often used in combination with the GROUP BY clause.
SQL commands that are used to manage tables are known as data definition language. Table management typically involves three commands, including CREATE TABLE, ALTER TABLE, and DROP TABLE.
You can insert a single row or multiple rows of data into a table via the INSERT TO … VALUE … statement.
FAQ
Why does database design matter?Good design keeps data organized and structured, enabling efficient queries and updates. Poor design leads to redundancy, inconsistencies, slow queries, bugs, and a poor user experience.When should I use a relational database instead of a spreadsheet?Spreadsheets are fine for very small, simple datasets. As data volume and complexity grow—or when you need access control, consistency, integrity, scalability, and routine analysis—you should use a relational database.What are tables, entities, attributes, and primary keys?A table is like a spreadsheet: rows are records and columns are attributes. An entity is an object or concept (e.g., a product with name, description, price, manufacturer). A primary key uniquely identifies each row; there is exactly one primary key per table.Why is it a bad idea to store multiple entities in one table?Mixing entities causes redundancy and anomalies. For example, deleting a product might also delete a customer in the same row (delete anomaly), and adding a new product may be blocked if customer data is required (insert anomaly). Separate entities into their own tables.What is an RDBMS, and how does SQL fit in?An RDBMS (Relational Database Management System) stores and manages relational data and provides tools for creation, modification, querying, and security. Examples include MySQL, MariaDB, PostgreSQL, and SQLite. SQL is the standardized language used to create, modify, and query data across these systems (with minor variations).Why is SQL called declarative, and what are the core clauses of a basic query?SQL is declarative: you state what you want, not how to compute it. A basic query uses SELECT (which columns), FROM (which table), and WHERE (filter conditions). Terminate statements with a semicolon.How do I filter results and combine conditions?Use WHERE with comparison operators (e.g., =, <, >). Wrap string values in quotes. Combine conditions with AND and OR. List multiple columns after SELECT, separated by commas, or use SELECT * to return all columns.What SQL data types will I commonly encounter?Common categories include numeric (e.g., INT, DECIMAL), string (e.g., TEXT, VARCHAR), date/time (e.g., DATE), binary, and miscellaneous (e.g., XML). DECIMAL(p, s) controls precision; DECIMAL(5,2) allows five digits total with two after the decimal.How do aggregation and GROUP BY work, and what pitfalls should I avoid?Aggregate functions (COUNT, SUM, AVG, MAX, MIN) go in SELECT. Use GROUP BY to aggregate per group, and include grouped columns in SELECT. Do not include non-grouped, non-aggregated columns in SELECT; some RDBMS will error (e.g., PostgreSQL), others may return misleading results (e.g., SQLite). Use AS to rename result columns.How do I create, alter, drop tables, and load the chapter’s sample data?Create tables with CREATE TABLE, defining columns, data types, and a PRIMARY KEY; use NOT NULL to avoid unknown (NULL) values causing unexpected results. Insert data with INSERT INTO (single or multiple rows). Alter tables with ALTER TABLE (e.g., add a column); note some systems (SQLite) don’t support changing a column’s data type directly. Drop tables with DROP TABLE (this permanently deletes the table). To load samples, use the book’s GitHub repo (chapter_01) and run the scripts via your RDBMS or SQLite Online; if you’ve already created the table, re-running CREATE/INSERT may fail due to duplicates—reset or drop the table first.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!







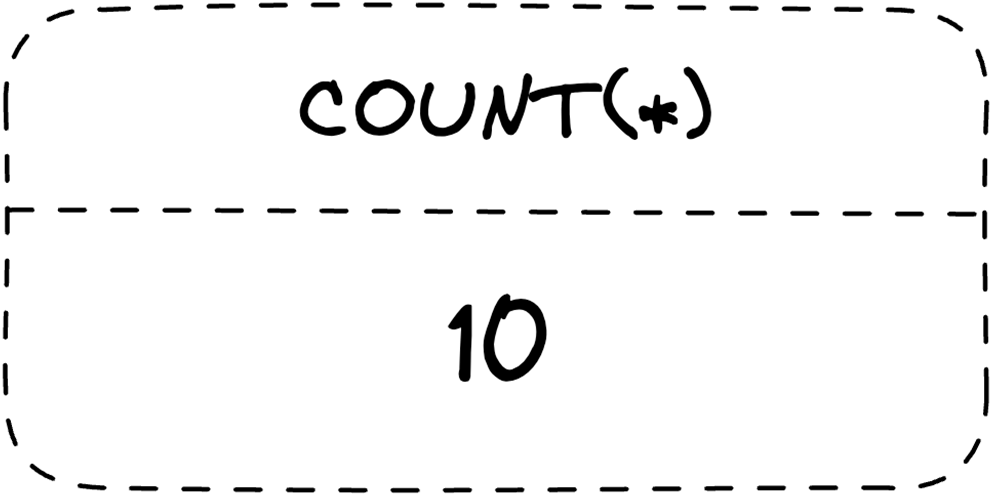








 Grokking Relational Database Design ebook for free
Grokking Relational Database Design ebook for free