10 Reinforcement learning
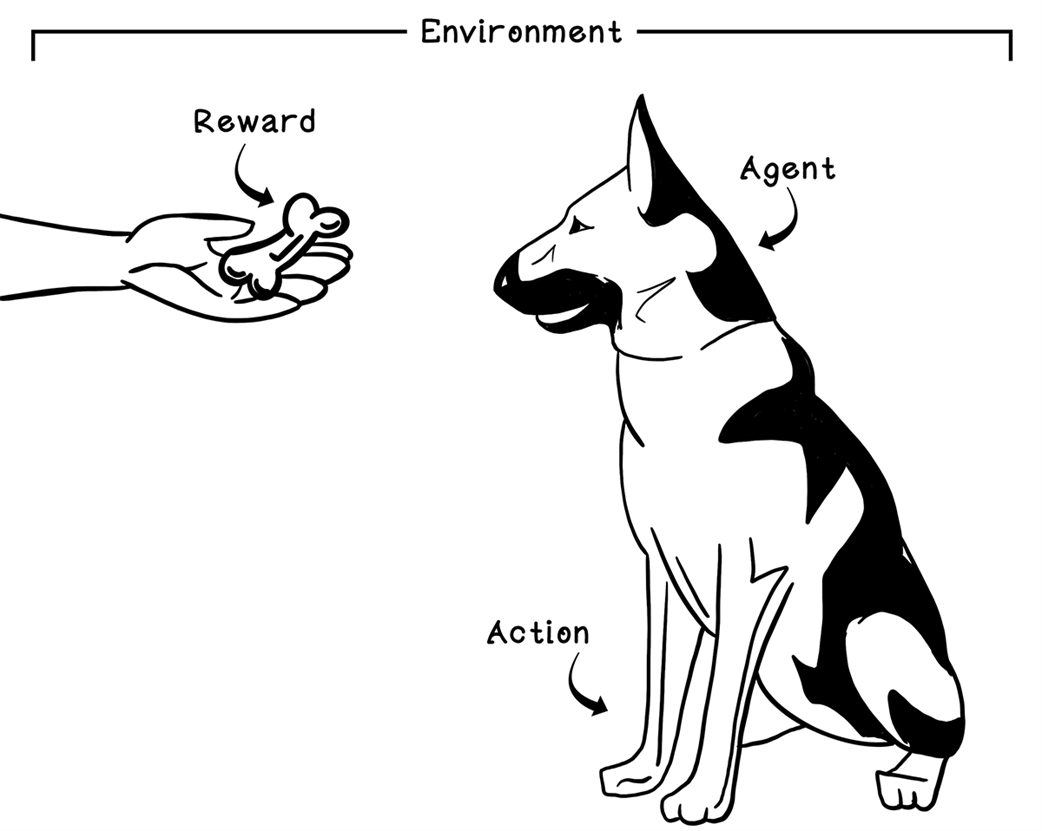
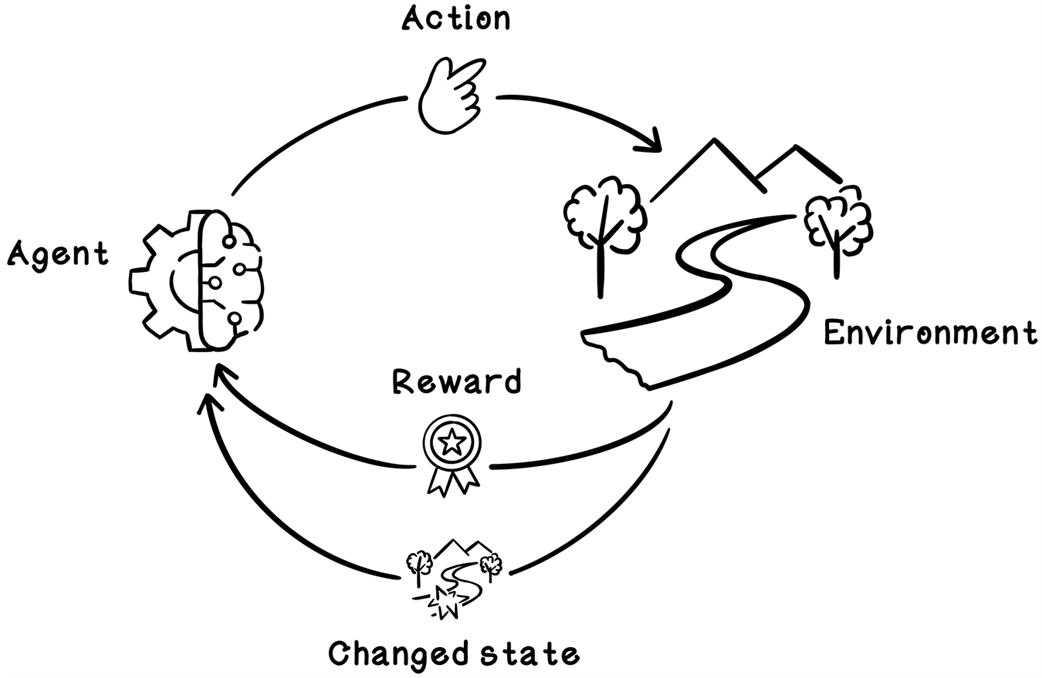
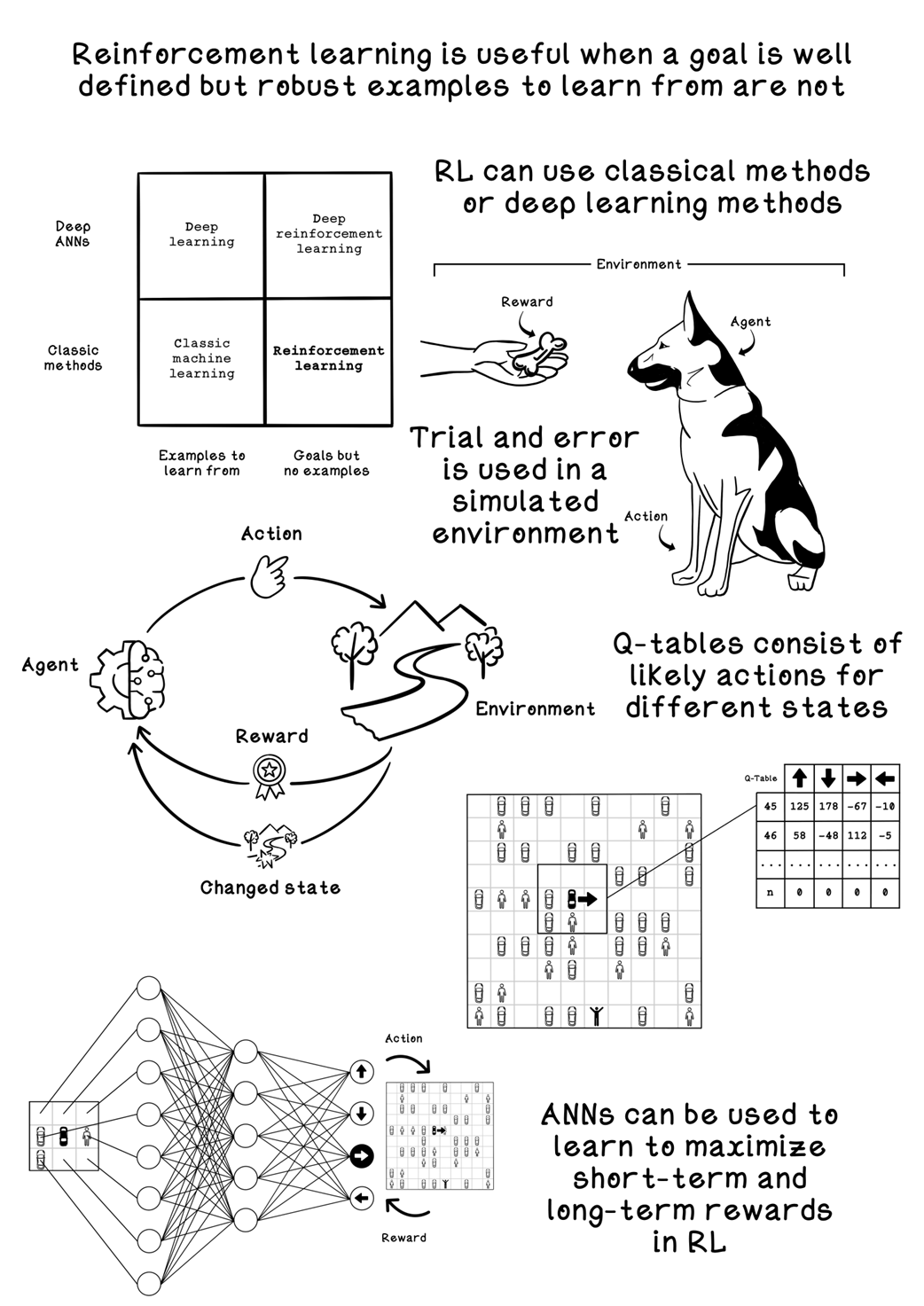
Reinforcement learning is presented as a trial‑and‑error approach to decision making inspired by behavioral psychology, where an agent interacts with an environment and learns through rewards and penalties to maximize long‑term cumulative return. Unlike supervised and unsupervised learning, it does not rely on labeled datasets or purely pattern discovery; instead, it learns action sequences that achieve a known goal, balancing short‑term gains against long‑term outcomes. Time, order of actions, and feedback loops are central, and the overall process is framed with the Markov Decision Process to quantify states, actions, transitions, and rewards.
The chapter grounds these ideas in a simulated parking‑lot scenario, defining clear states, actions, rewards, and terminal conditions, and shows how design choices in the simulator shape what the agent can learn. It develops Q‑learning as a model‑free method that stores estimated action values in a Q‑table and improves them via an exploration–exploitation strategy, a learning rate, and a discount factor using a Bellman‑style update across many episodes so that value propagates backward from goals. Practical considerations include crafting reward functions to avoid perverse behaviors, choosing state representations that generalize beyond a single map, measuring progress via penalties or average reward, and understanding the trade‑offs between model‑free and model‑based approaches.
To scale beyond tabular methods, the chapter introduces deep reinforcement learning, where neural networks approximate Q‑values directly from state inputs and are trained with temporal‑difference targets and backpropagation. It compares compact scalar encodings with more expressive one‑hot encodings of local surroundings, outlines sensible network architectures and ReLU activations, and highlights techniques such as randomized starts and the evolving shift from exploration to exploitation. The discussion closes with impactful use cases—robotics, recommendation systems, financial trading, and game playing—emphasizing the need for realistic simulators and carefully designed reward signals so agents can learn robust, long‑horizon strategies in complex, dynamic environments.
How reinforcement learning fits into machine learning
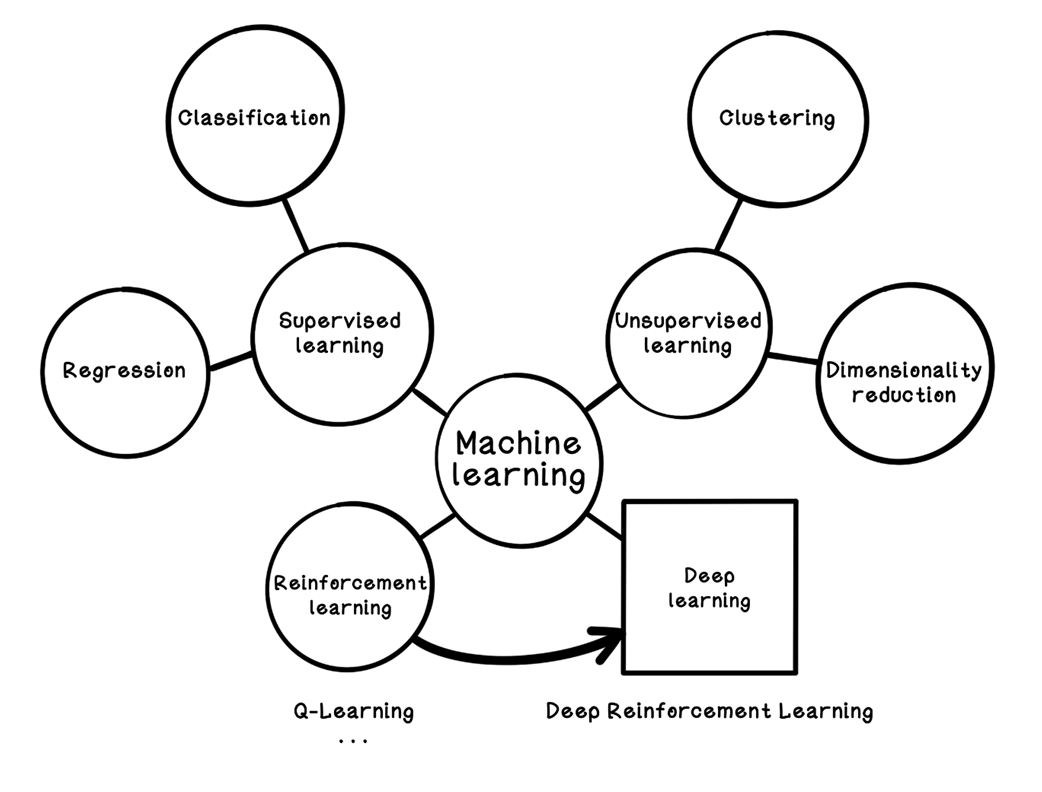
Categorization of machine learning, deep learning, and reinforcement learning
Example of reinforcement learning: teaching a dog to sit by using food as a reward
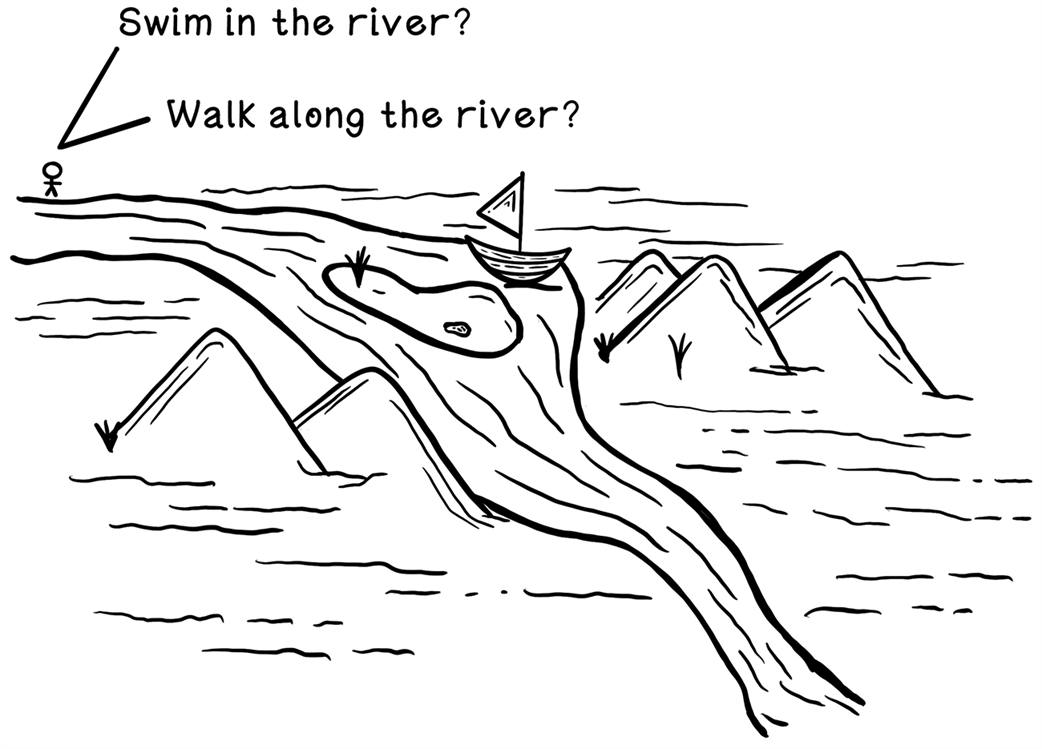
An example of possible actions that have long-term consequences
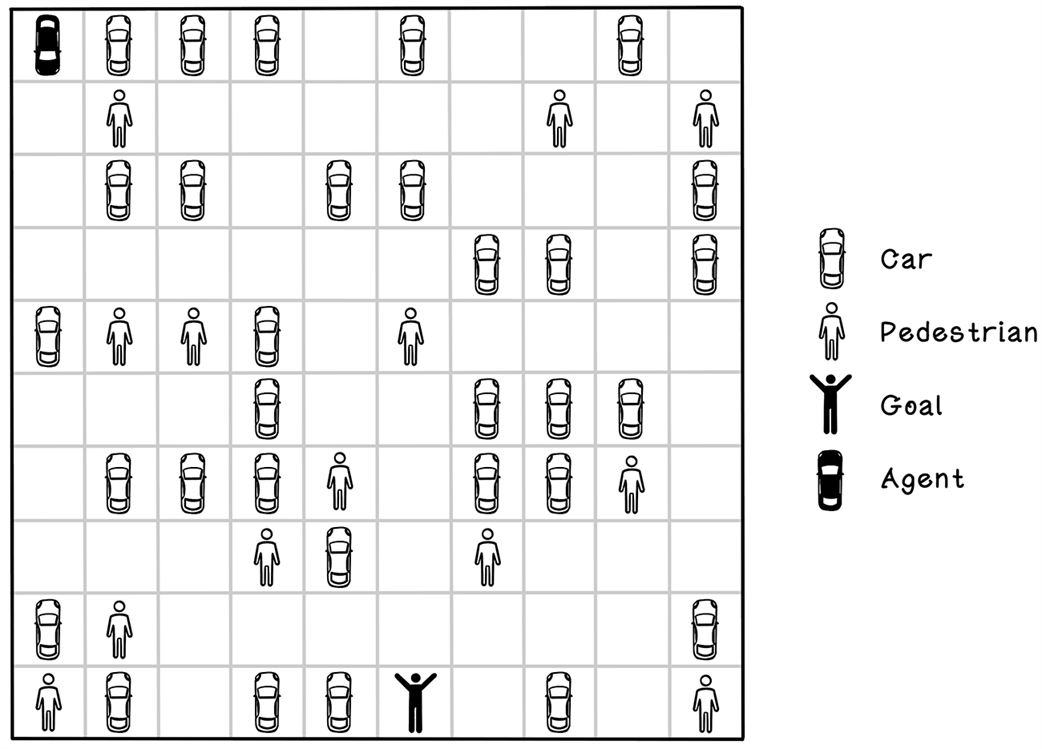
The self-driving car in a parking lot problem
The Markov Decision Process for reinforcement learning
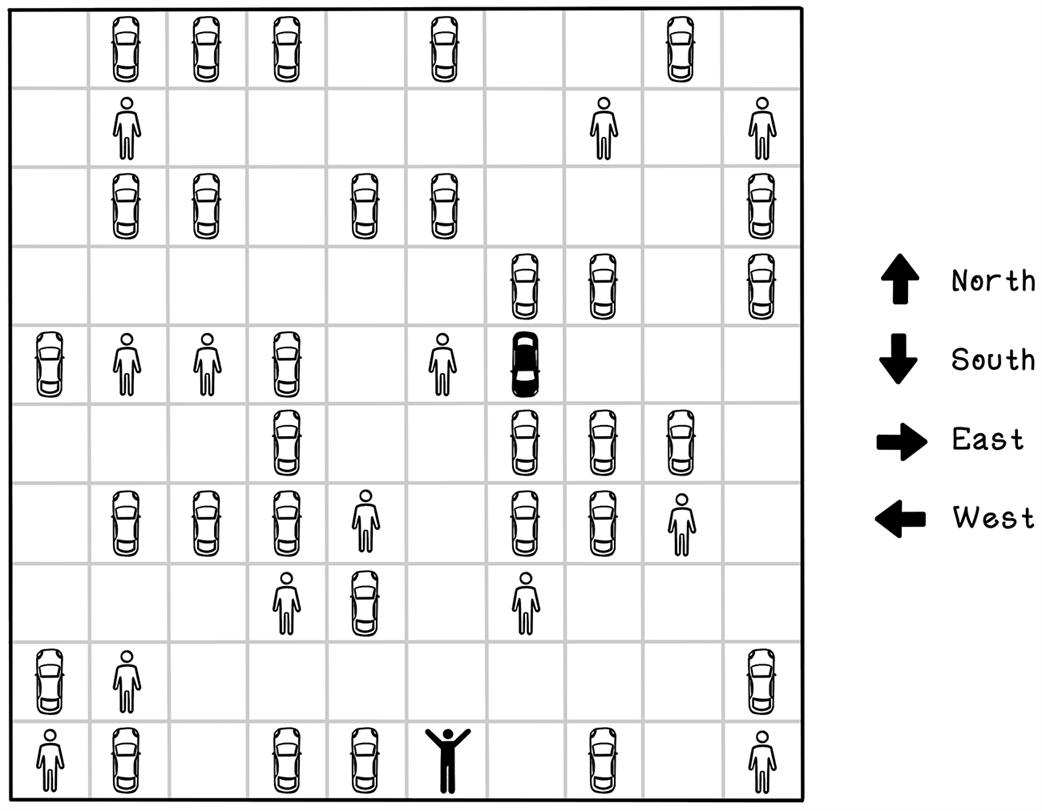
Agent actions in the parking-lot environment
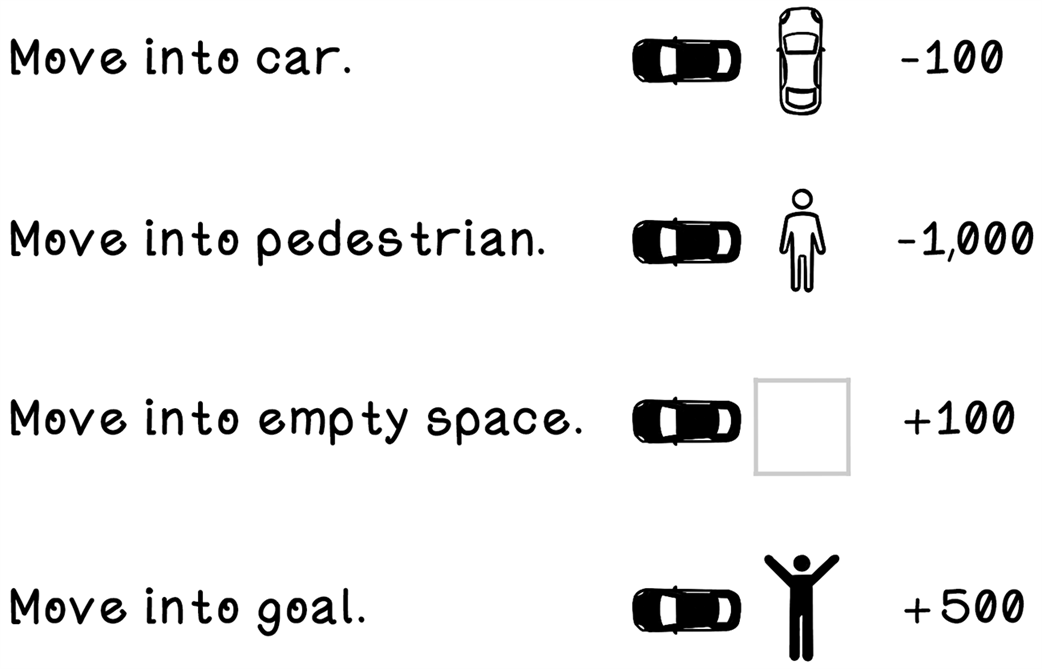
Rewards due to specific events in the environment due to actions performed
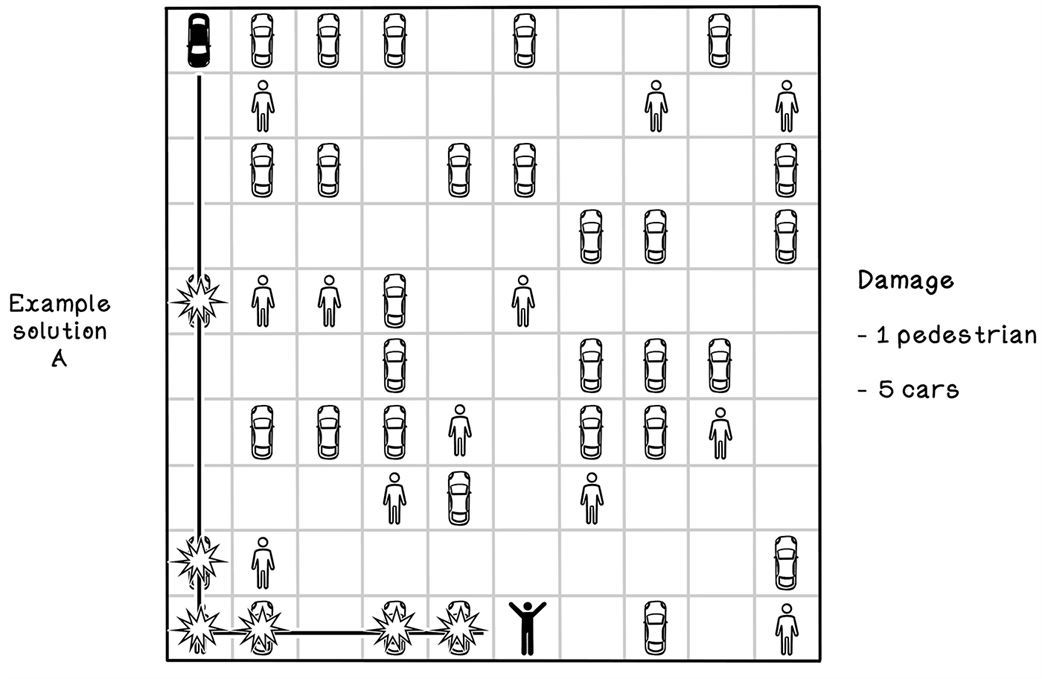
A bad solution to the parking-lot problem
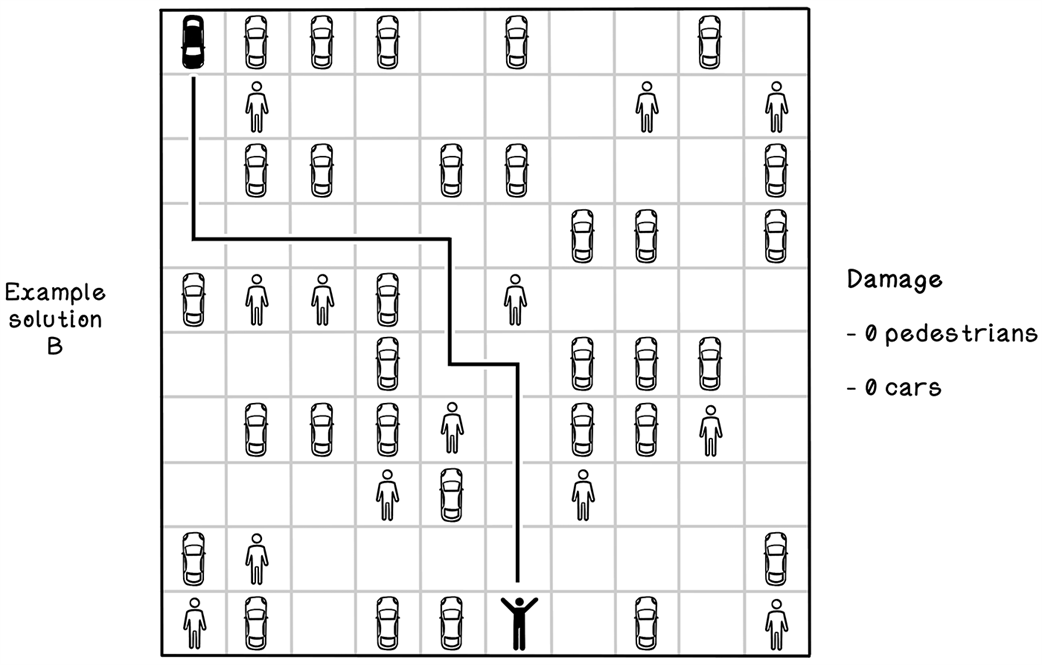
A good solution to the parking-lot problem
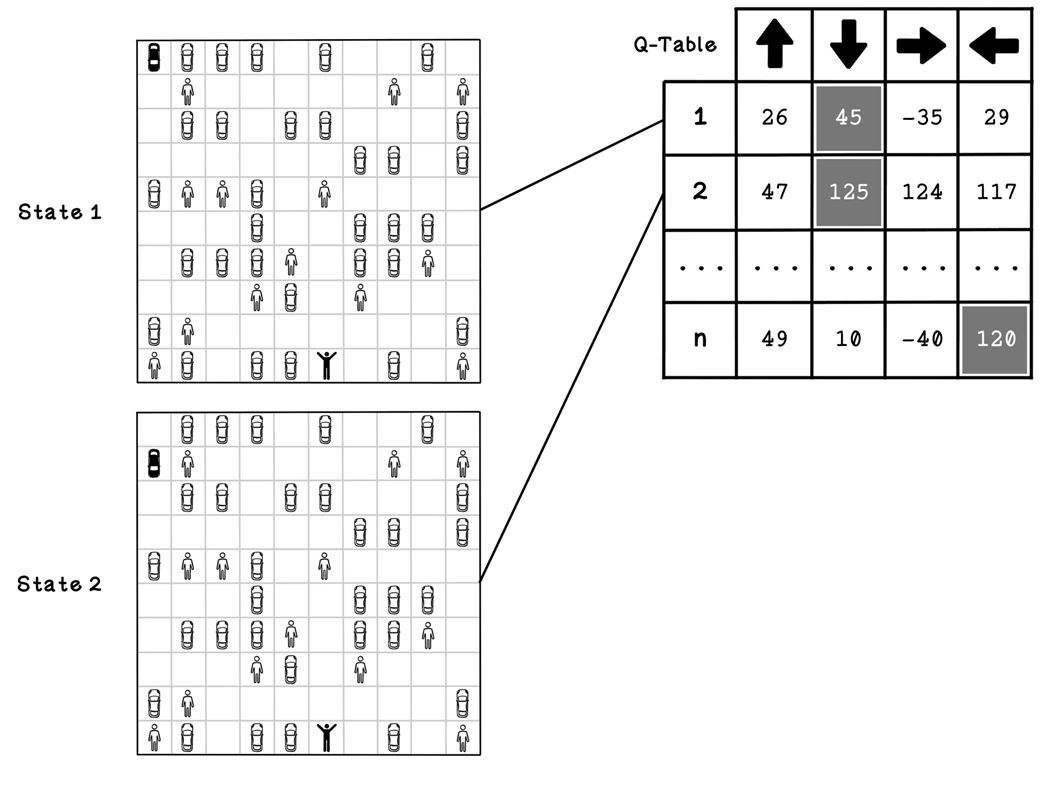
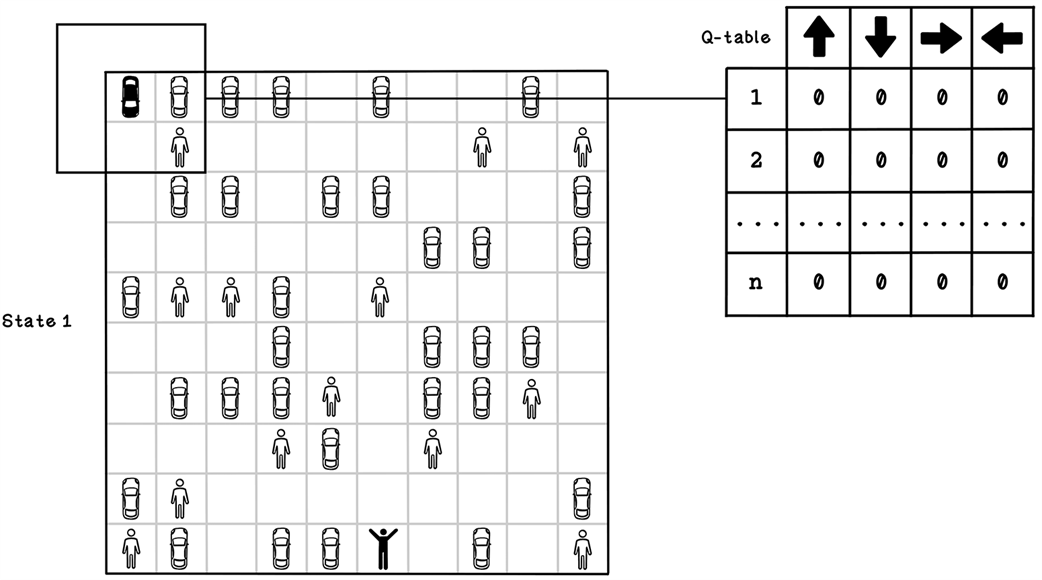
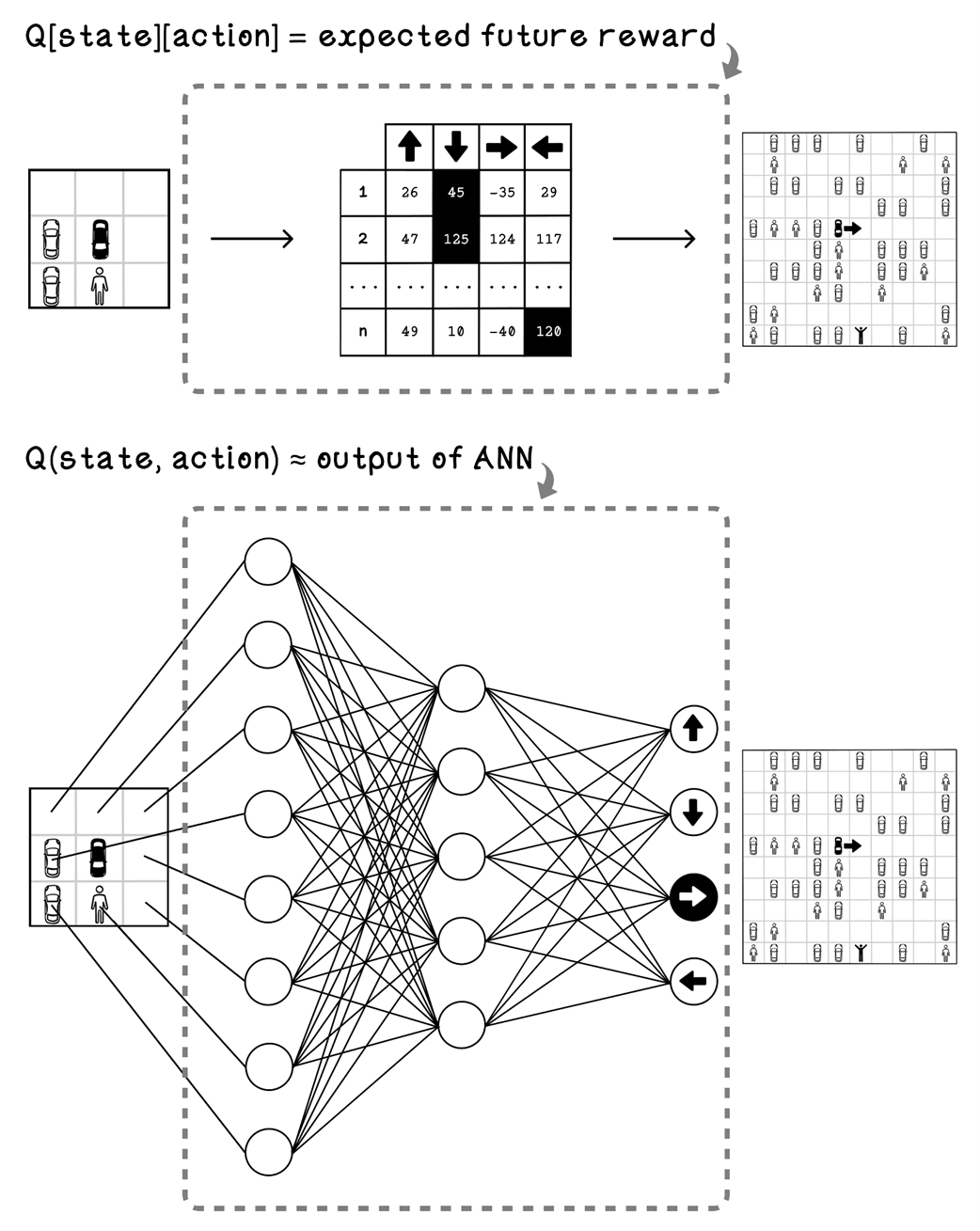
An example Q-table and states that it represents
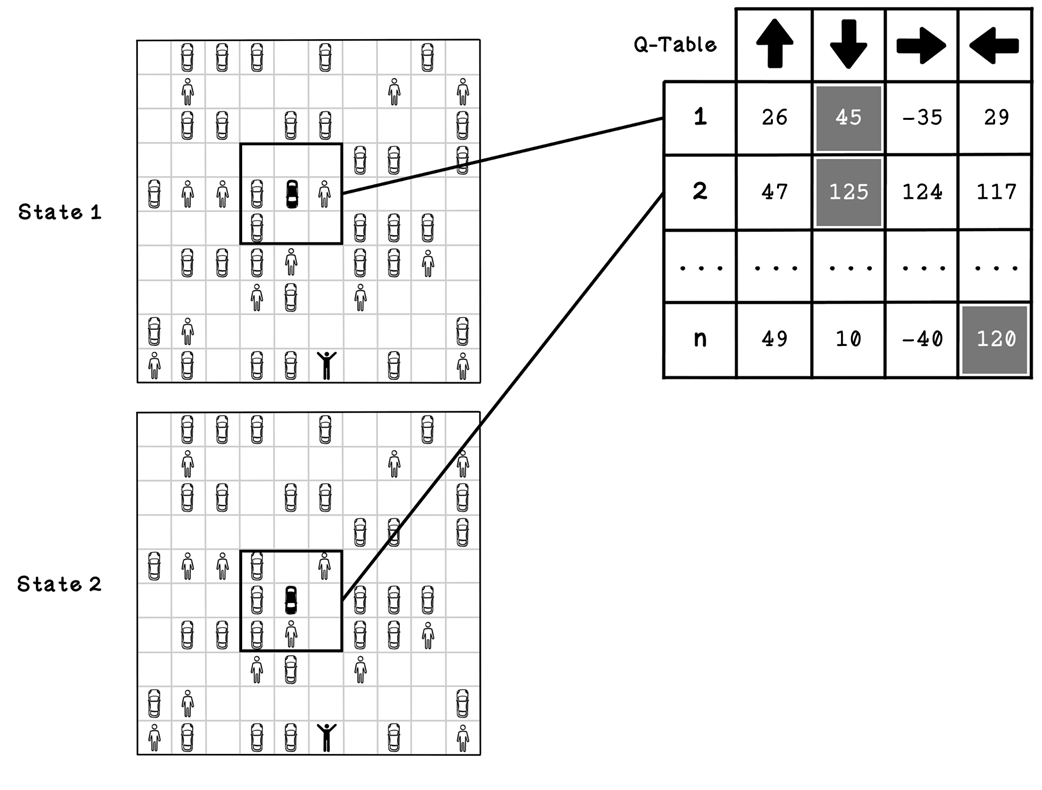
A better example of a Q-table and states that it represents
Life cycle of a Q-learning reinforcement learning algorithm
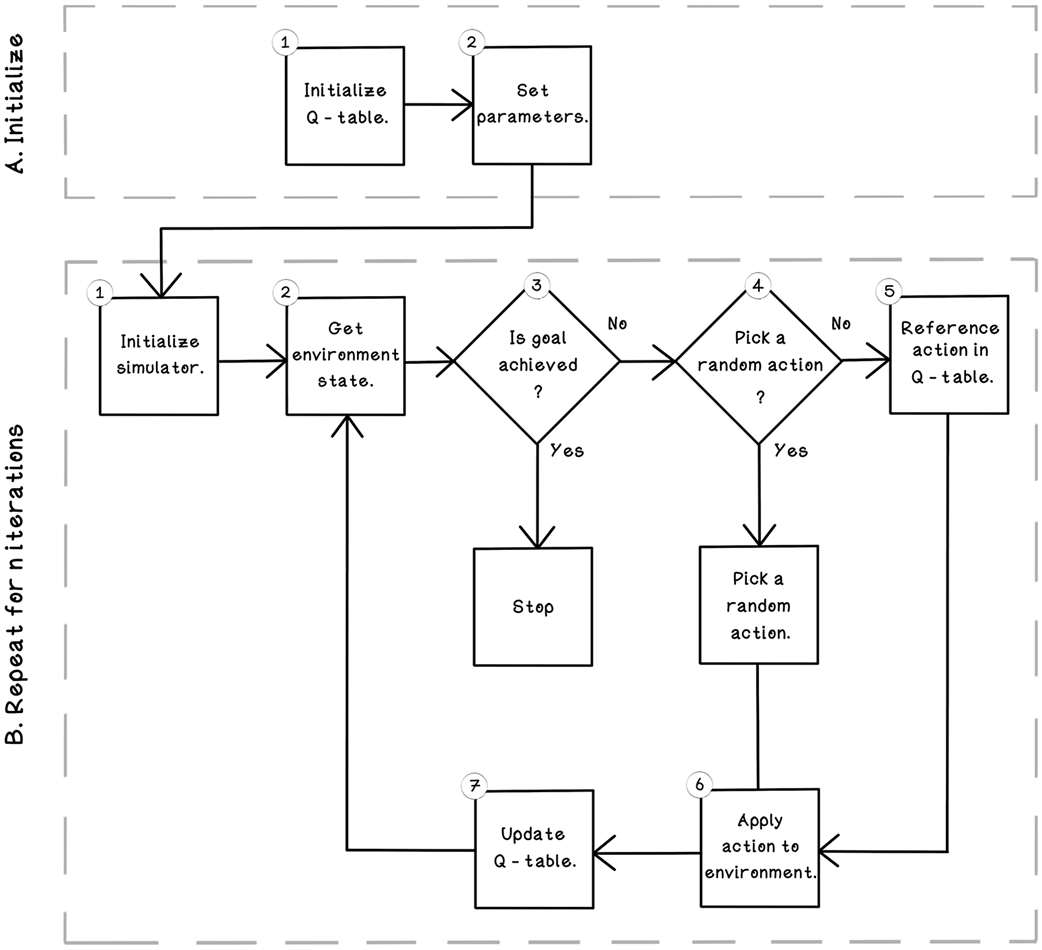

An example initialized Q-table
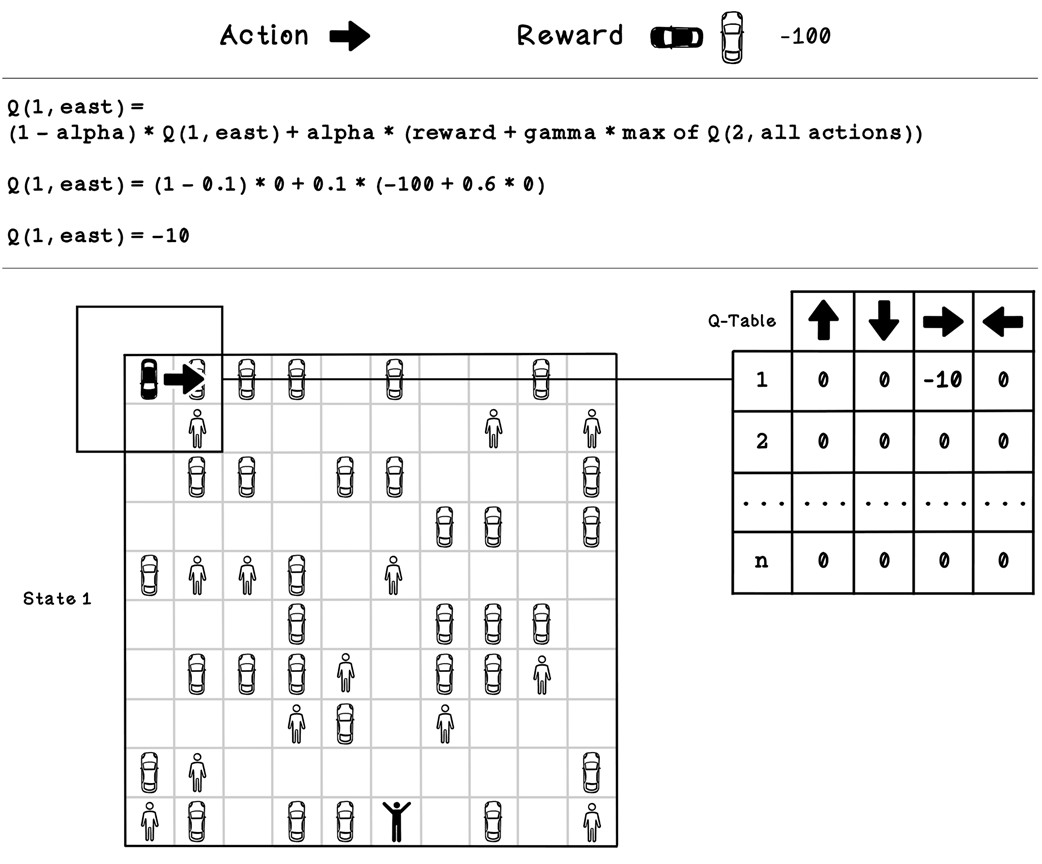
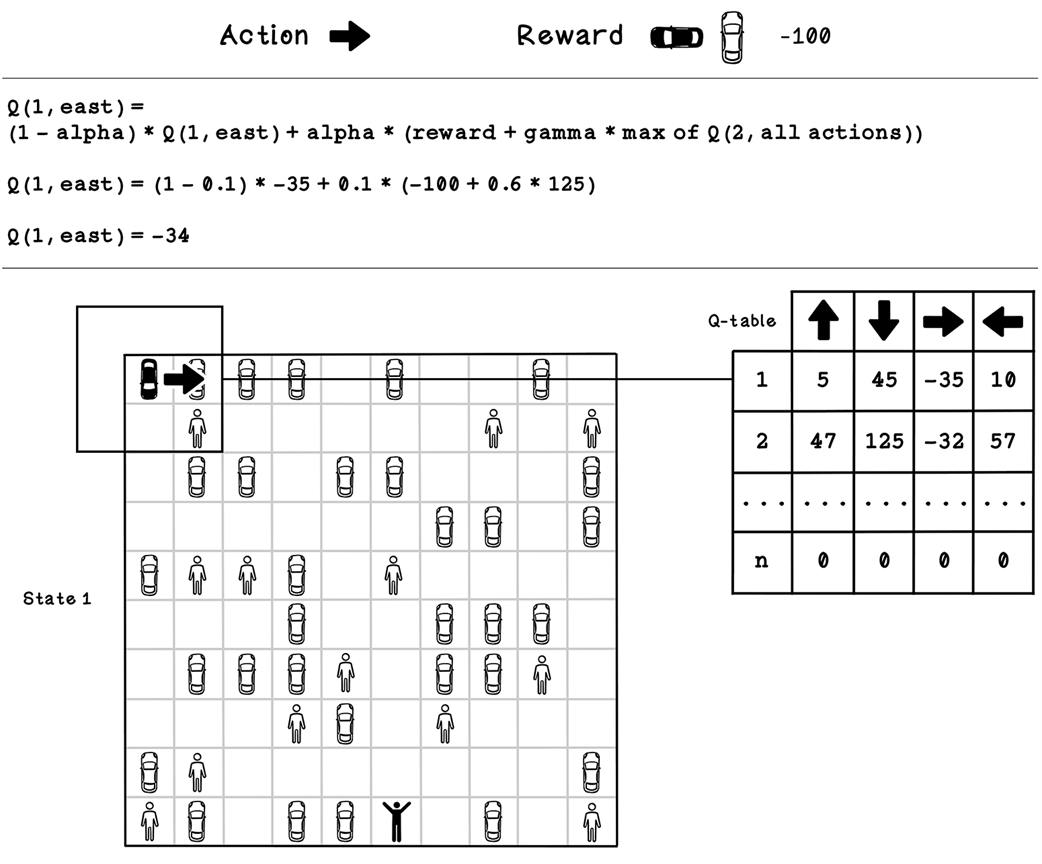
Example Q-table update calculation for state 1
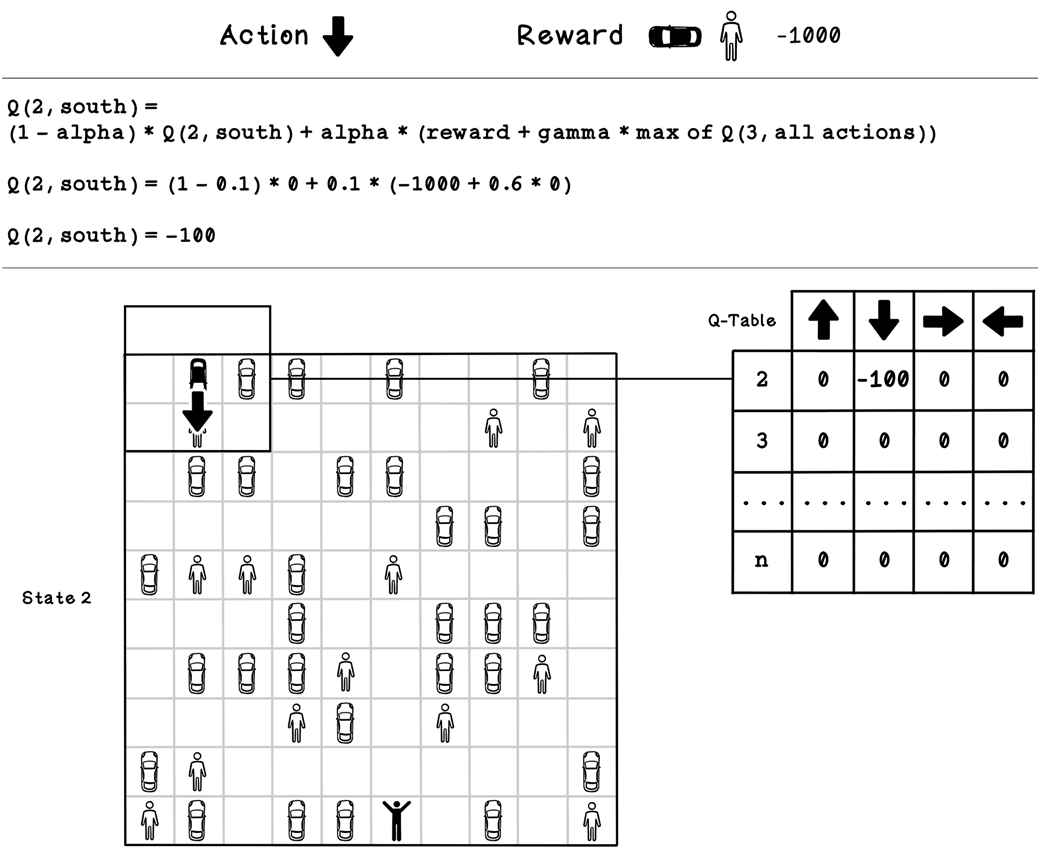
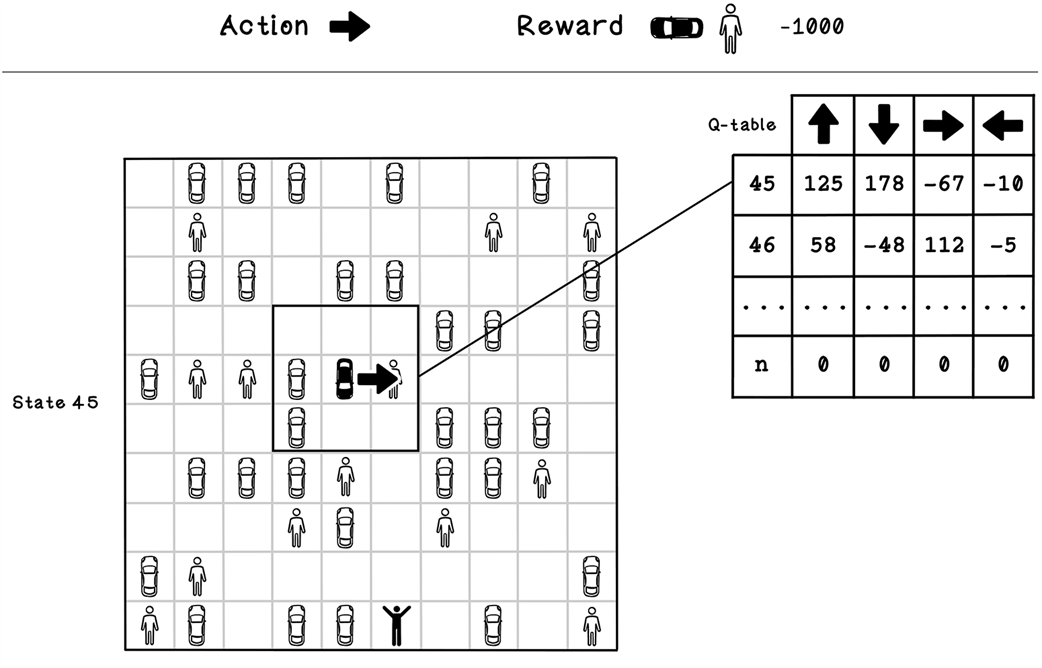
Example Q-table update calculation for state 2
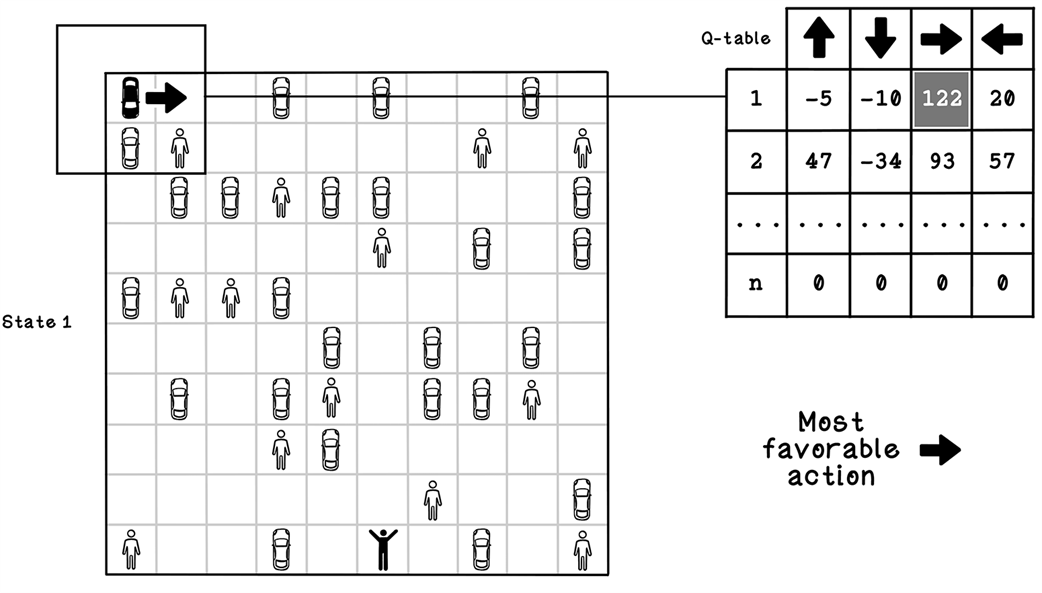
Example Q-table update calculation for state 1 after several iterations


Referencing a Q-table to determine what action to take
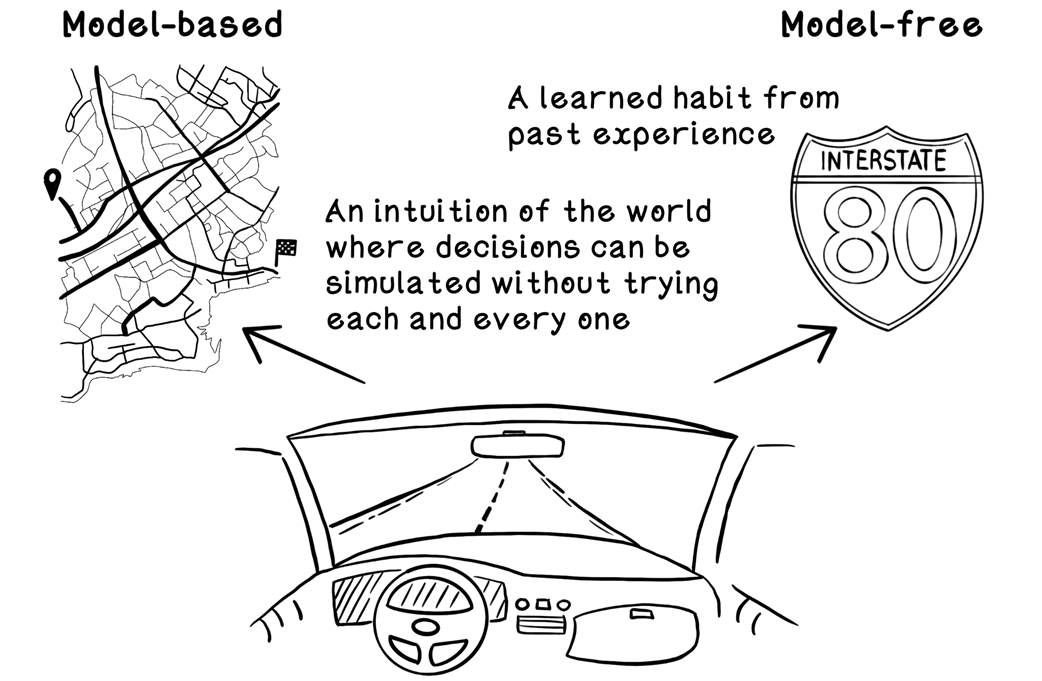
Examples of model-based and model-free reinforcement learning
The difference between using a Q-table and ANN for the parking-lot problem
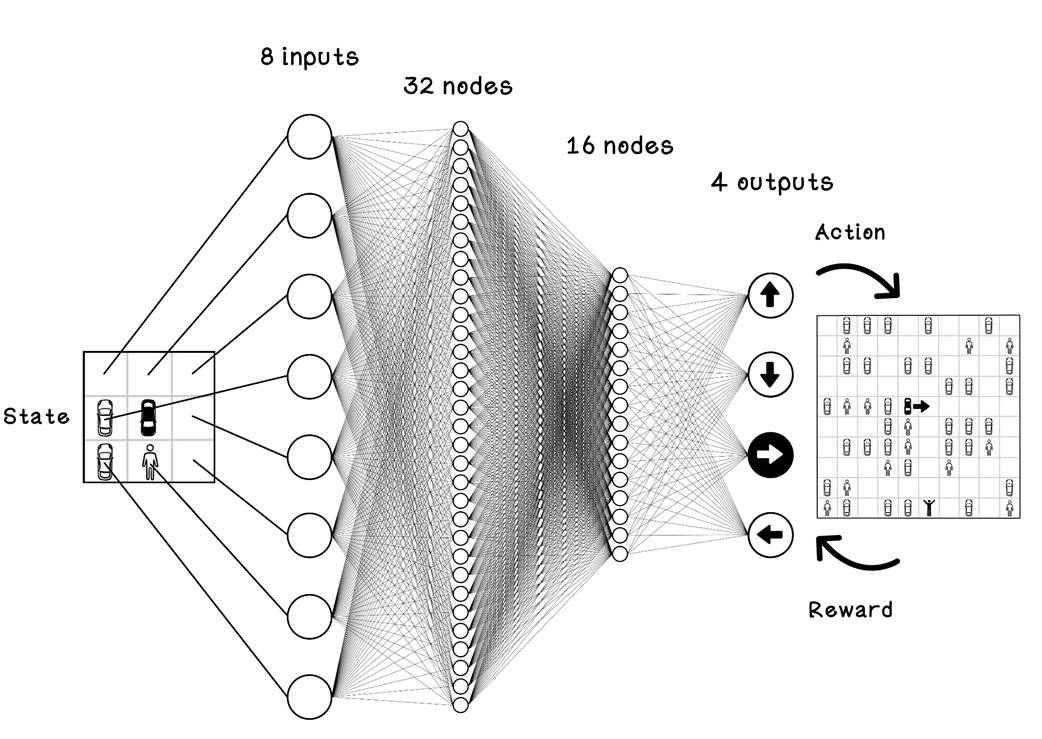
Example 8 input ANN for the parking-lot problem
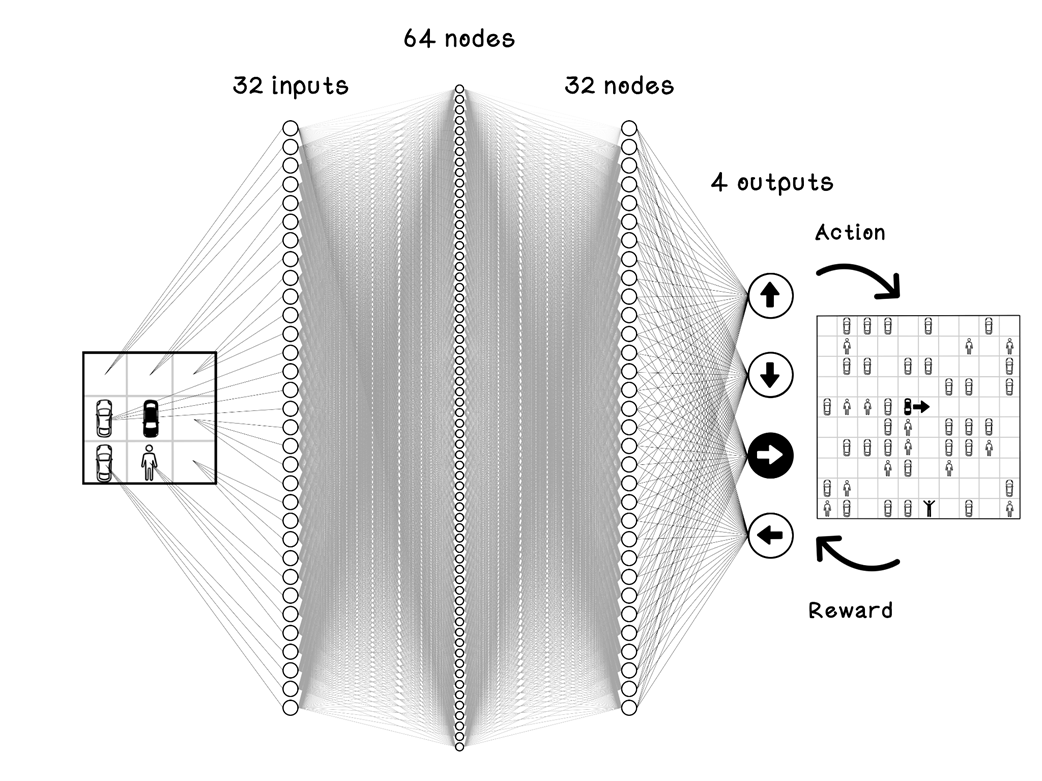
Example 32 input ANN for the parking-lot problem
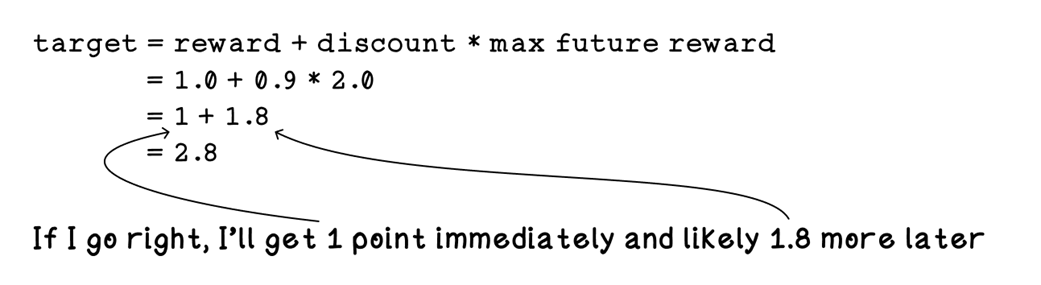
Summary of reinforcement learning
FAQ
What is reinforcement learning, and how does it differ from supervised and unsupervised learning?
Reinforcement learning (RL) is inspired by behavioral psychology. Instead of learning from labeled examples (supervised) or discovering structure in unlabeled data (unsupervised), an RL agent learns by interacting with an environment, taking actions, and receiving rewards or penalties. The goal is to learn a policy that maximizes cumulative (long-term) reward.When is reinforcement learning a good fit for a problem?
RL is best when you know the goal and the allowed actions, but not the best sequence of actions to achieve the goal. It excels in sequential decision-making where actions compound over time, such as strategic planning, robotics, and industrial control, and where cumulative reward matters more than individual step rewards.What are the key terms: agent, environment, state, action, and reward?
- Agent: The decision-maker (e.g., the car).- Environment: The world the agent interacts with (e.g., the parking lot).
- State: The situation or observation at a point in time (e.g., agent’s position and nearby cells).
- Action: A choice the agent makes (e.g., move north/south/east/west).
- Reward: Feedback after an action (positive for good outcomes, negative for bad ones).
 Grokking AI Algorithms, Second Edition ebook for free
Grokking AI Algorithms, Second Edition ebook for free