2 Immutable stacks and queues
This chapter motivates and demonstrates immutable data structures through practical, production-minded examples. It argues that immutability simplifies correctness and reasoning (facts don’t go stale), preserves history, mitigates TOCTOU security risks, and enables safe sharing across threads. It also highlights performance tradeoffs: memoization can speed computation but needs thread-safe caches, and persistence allows structural sharing that saves memory when multiple versions coexist. With a functional attitude, the chapter balances theory with pragmatic C# techniques, showing how immutability can reduce bugs, ease testing, and still fit into everyday, object-oriented codebases.
Starting from an ADT-first design, an immutable stack is built over a refined linked-list approach with a singleton empty instance and a non-empty node (item plus tail), yielding O(1) Push/Peek/Pop and linear enumeration, while avoiding nulls via a “null object” pattern. A neat C# variance trick makes the stack interface covariant by moving the input-taking Push off the interface into an extension method. The immutable queue follows by composing two immutable stacks—one for enqueues, one for dequeues—preserving the invariant that any non-empty queue has a non-empty dequeue stack. This design gives O(1) time for Enqueue, Peek, IsEmpty, and O(1) amortized Dequeue, with the worst case triggered when reversing the enqueue stack into the dequeue stack; enumeration is linear in time and can require linear extra memory in the worst case.
To add convenient mutability without sacrificing safety, the chapter wraps immutable structures in small mutable shells and then layers universal undo-redo support via an UndoRedo helper that snapshots states with persistent sharing. This delivers cheap snapshots, straightforward redo (often “for free”), and reasonable memory cost—but it also exposes a caveat: repeated worst-case operations (like repeatedly triggering a large reverse between undo/redo) defeat amortization. The finale introduces the Hughes list (difference list): a list represented by a function that concatenates its content onto a supplied tail. It makes Push, Append, and Concatenate O(1) by deferring work, but materializing (ToStack), Peek, and Pop become O(n). Internally, closures form a binary graph, which is elegant but raises stack-depth concerns on materialization. As a capstone, the chapter shows how ReverseOnto enables O(1) construction of a “reversed” Hughes list whose costs are paid only when realized—underscoring the broader theme: build flexibly and cheaply now, pay precisely when you actually need the data.
Each variable in the example code references a particular immutable stack. Stacks that have the same tail can both refer to the same immutable object.
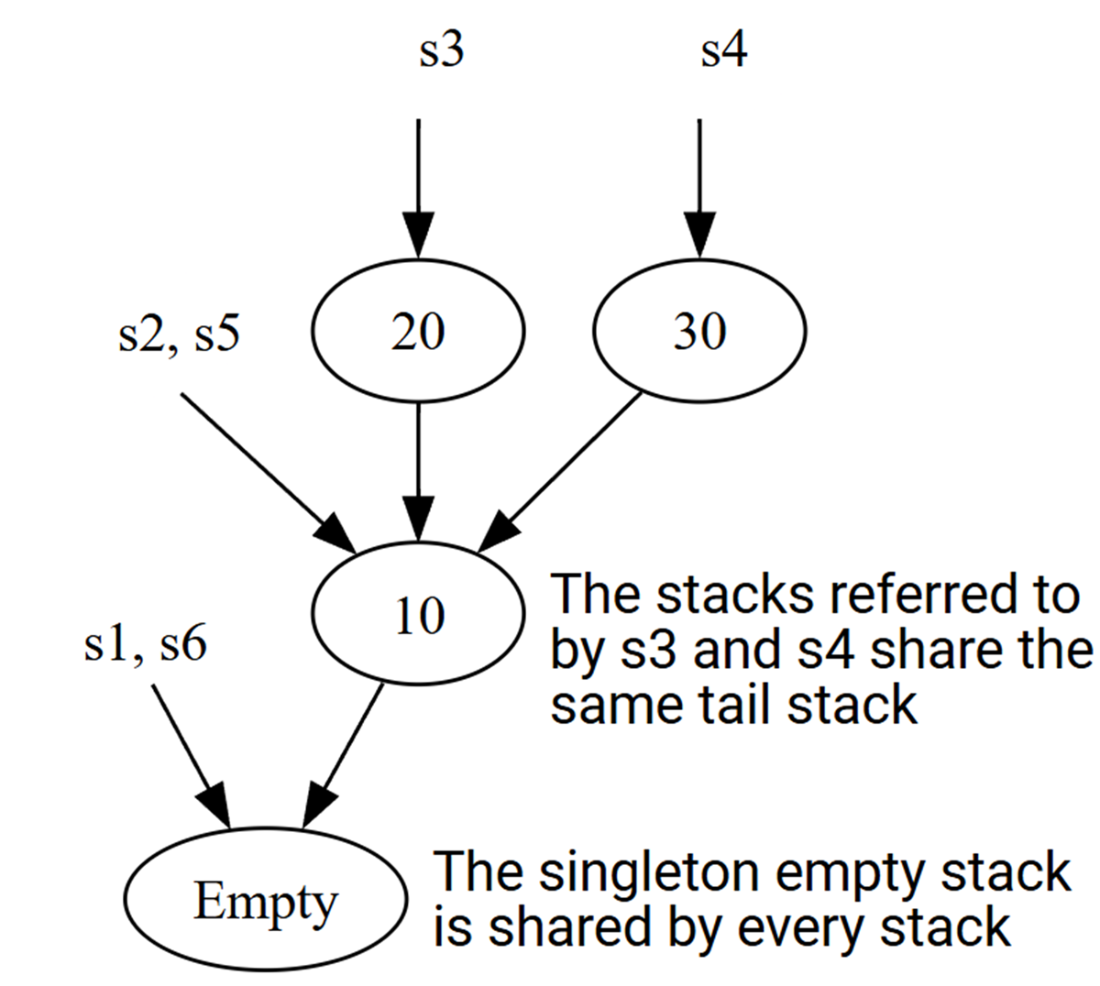
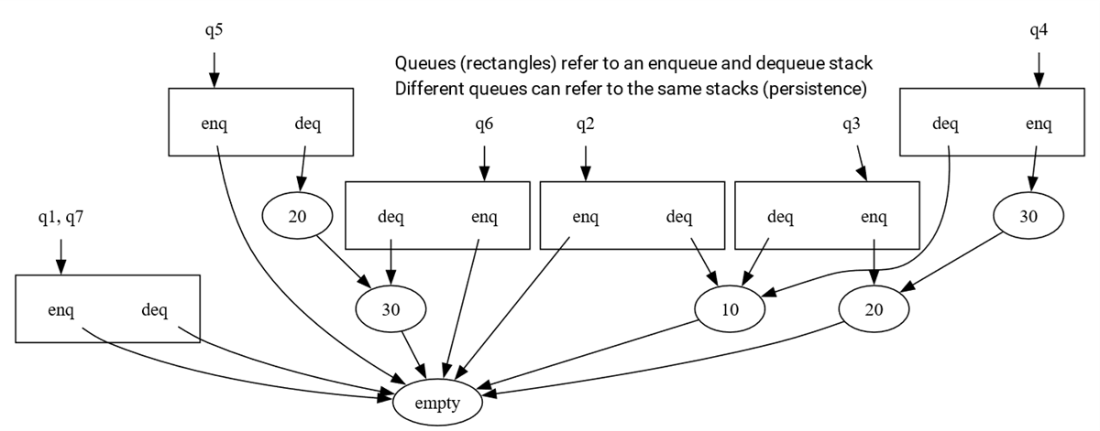
There are six different immutable queues in the example and six different immutable stacks. Since the data structures are persistent and immutable, objects can be reused across different queues.
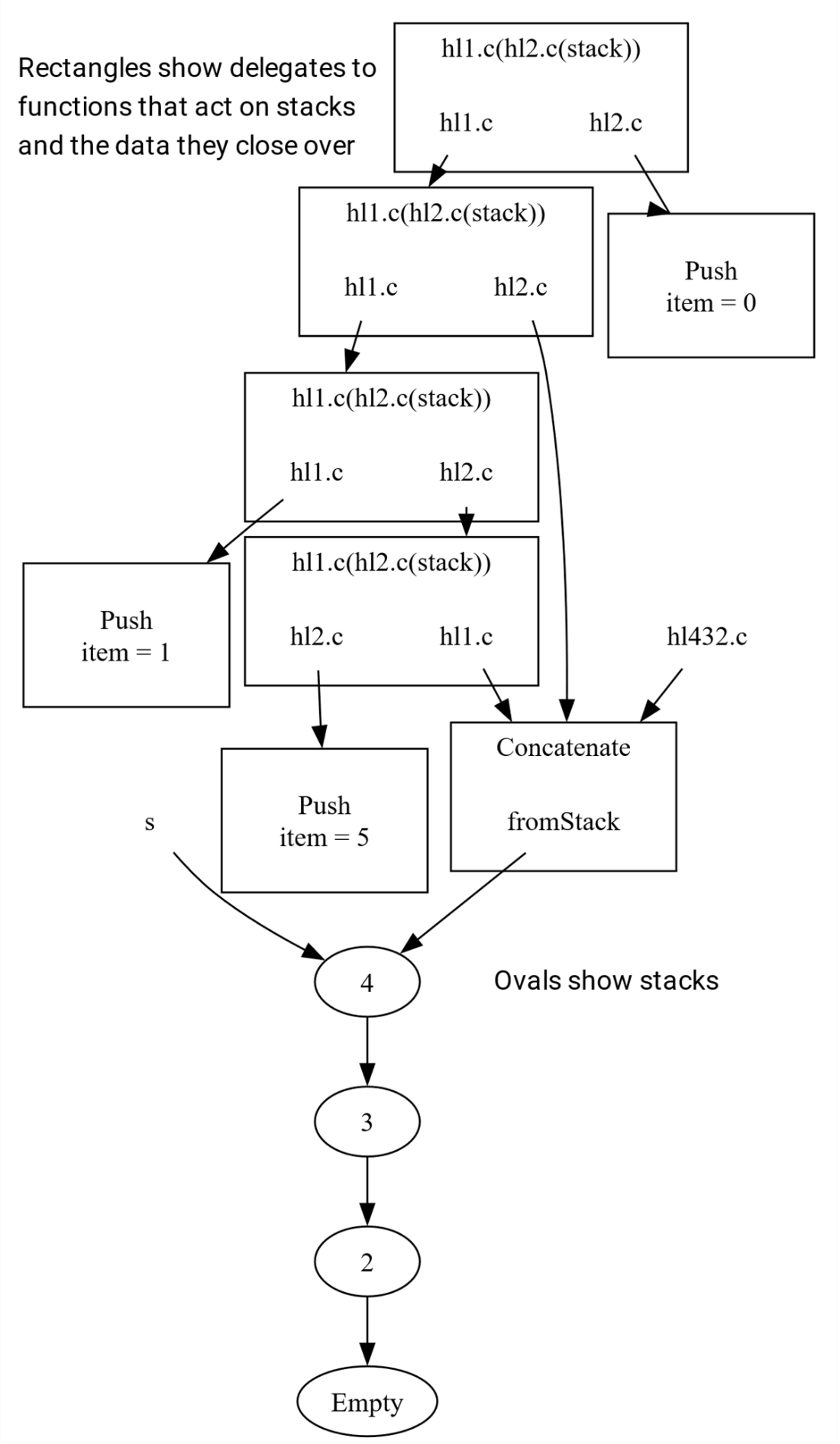
A Hughes list is secretly a binary graph! Delegates created from lambda bodies have automatically-created closure classes with fields hl1 and hl2 that refer to the left and right lists being concatenated.
Summary
- Immutable data structures are easier to reason about and often safer than the equivalent mutable data structure
- Persistence makes immutable data structures efficient in space
- Immutable data structures can be made efficient in time as well, though there are pitfalls to be wary of when some operations are expensive
- Undo-redo operations are straightforward when program state is immutable
- The Hughes list changes the performance costs of seemingly expensive operations by performing them in the optimal order in the future, but it makes some normally cheap operations such as Pop expensive. There’s no free lunch, but costs can be pushed into the future.
- We still haven’t got a truly double-ended queue (or “deque”) where pushing and popping on either end of the list is cheap. In the next chapter we’ll implement a deque using finger trees.
FAQ
What are the key benefits of immutable data structures highlighted in this chapter?
They make code easier to reason about (facts don’t change), improve correctness and testability, preserve history (e.g., ledgers, source control), mitigate TOCTOU security bugs, enable safe sharing across threads, unlock memoization (time) and persistence (space via structural sharing), and encourage a functional programming mindset while remaining usable from OO languages like C#.How is an immutable stack implemented without using null, and how is the empty stack represented?
It uses the null object pattern: anEmptyStack singleton implements the same interface as non-empty nodes. Peek/Pop on the empty stack throw, enumeration yields nothing, and construction is only via pushing onto the empty stack. This avoids null checks and accidental dereferences.Why can’t a straightforward immutable stack interface be covariant in C#, and how does the chapter make it covariant anyway?
Covariance requires the varying type parameter to appear only in output positions. APush(T) method takes T as input, so the interface isn’t covariant. The workaround: remove Push from the interface, mark the interface out T, provide a static factory on the implementation and an extension method Push. Call sites stay the same, and covariance (e.g., IImStack<Tiger> to IImStack<Animal>) becomes legal.How does the immutable queue use two stacks, and what are its time complexities?
It maintains two stacks: enqueues push onto the enqueue stack; dequeues pop from the dequeue stack. When the dequeue stack empties, it reverses the enqueue stack to become the new dequeue stack, preserving the invariant “non-empty queue ⇒ non-empty dequeue stack.” AmortizedDequeue is O(1), but the worst-case call that triggers reversal is O(n) time and space. Peek/IsEmpty are O(1), enumeration is O(n) time and can be O(n) extra memory during reversal.Why is persistence a memory win with immutable stacks/queues?
New versions share structure with old versions (e.g., shared tails). Creating “modified” versions typically allocates only a few new nodes and reuses the rest, so each snapshot adds about O(1) extra memory on average instead of copying the whole structure.What is a “mutable-over-immutable” wrapper and why use it?
It’s a thin mutable class holding a private reference to an immutable structure. “Mutating” methods just assign the field to a new immutable version. Benefits: ergonomic, thread-friendly snapshots, easy undo/redo, and clear reasoning while preserving the advantages of immutability under the hood.How does the generic UndoRedo helper work, and what are its costs?
It keeps two immutable stacks of states:undo and redo. Do(newState) pushes the old state to undo and clears redo. Undo/Redo move the current state between these stacks. Extra time is O(1) per operation; extra memory is O(n) in the number of undoable actions. Thanks to persistence, each stored state shares most of its memory with neighbors.What is a Hughes list (difference list), and when is it useful?
A Hughes list represents a list as a function (delegate) that, given a tail, produces the full list by concatenation. Building withPush, Append, and Concatenate is O(1) each, regardless of size, making it ideal for assembling large results in pieces before reading them.Where does the work happen with Hughes lists, and what are the trade-offs?
The cost is deferred to materialization:ToStack, Peek, Pop, and enumeration traverse the captured closures and run in O(n) time (and use O(n) call stack depth). Pros: constant-time building/concatenation. Cons: deferred O(n) read, potential stack overflow for very large lists due to recursion depth. Fabulous Adventures in Data Structures and Algorithms ebook for free
Fabulous Adventures in Data Structures and Algorithms ebook for free