1 Improving LLM accuracy
Large language models have transformed how we generate and interact with text, combining broad world knowledge with strong instruction-following to handle varied tasks. Yet they remain constrained by knowledge cutoffs, drifting into outdated answers, and producing confident but incorrect hallucinations. They also lack access to proprietary data and do not store facts explicitly, instead relying on learned statistical patterns. This chapter frames these accuracy gaps as the central challenge for building dependable, up-to-date AI assistants and sets the stage for practical remedies aimed at precision, reliability, and explainability.
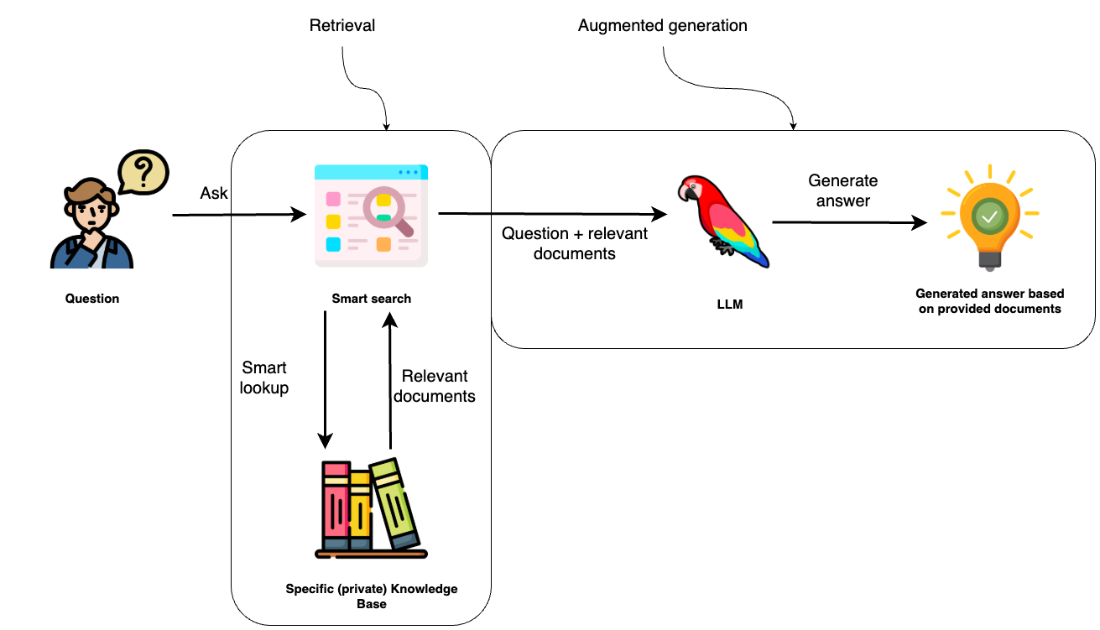
Two strategies to inject domain knowledge are examined: supervised finetuning and retrieval-augmented generation (RAG). While finetuning can improve behavior, it is resource-intensive, operationally complex, and shows mixed results for reliably teaching new facts at production scale. RAG, by contrast, retrieves trusted information at runtime and feeds it to the model in context, shifting the model’s role from open-ended recall to task-oriented synthesis grounded in evidence. In practice, the system handles retrieval behind the scenes, enriching prompts with relevant passages or records so the model can generate answers that are more current, specific, and verifiable, with fewer hallucinations.
The chapter argues that knowledge graphs are an ideal backbone for RAG because they semantically connect structured and unstructured data. Graphs enable precise operations—filtering, counting, aggregations—while linking entity mentions in text to authoritative records for rich, contextual answers. This fusion supports both crisp, data-driven queries and open-ended explanations, improving traceability and trust. Readers are guided toward building GraphRAG pipelines—augmenting existing systems or creating new ones—gaining practical skills in data modeling, graph construction, retrieval workflows, and evaluation to deliver robust, accurate, and explainable results across domains.
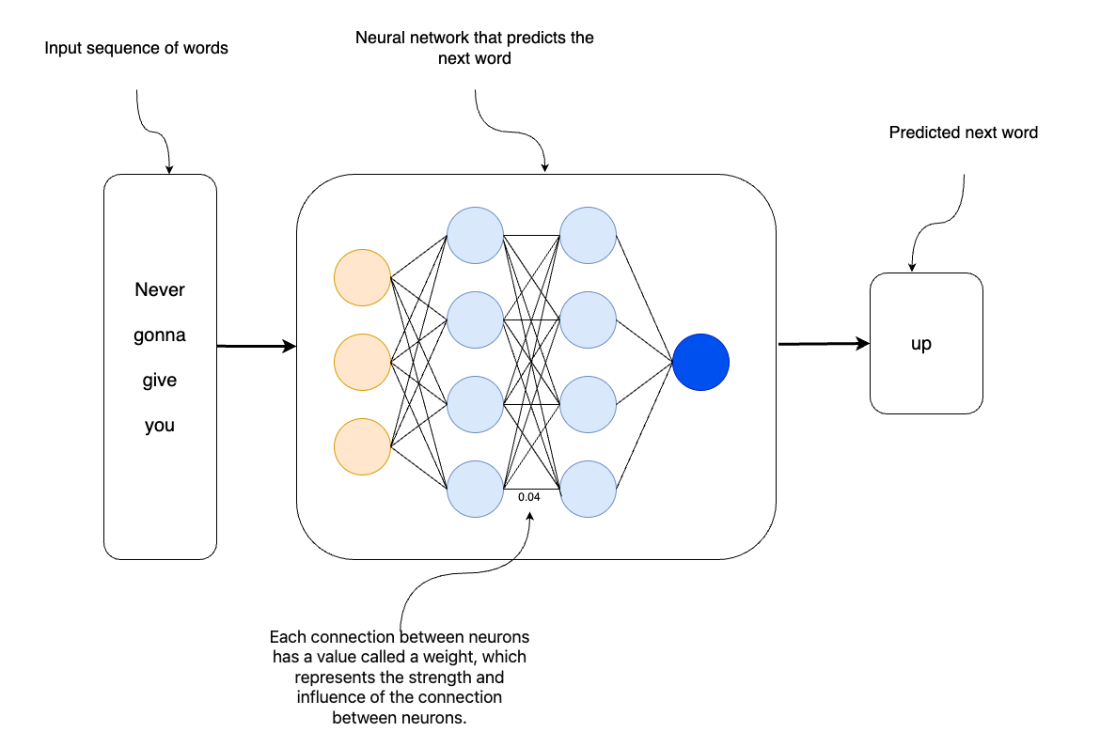
LLMs are trained to predict the next word
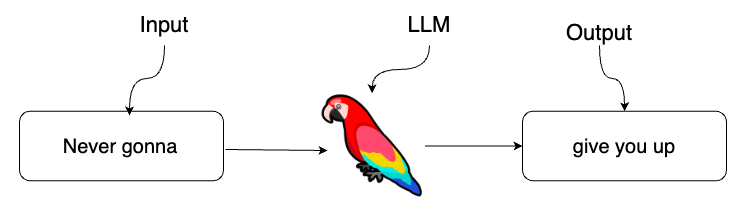
Writing a haiku with ChatGPT
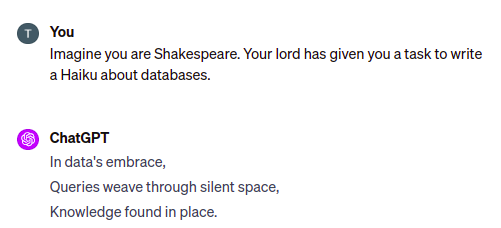
Retrieving factual information from ChatGPT
Neural network trained to predict the next word based on the input sequence of words
Example of a knowledge cutoff date prompt

Sometimes ChatGPT responds with outdated information

ChatGPT can produce responses with incorrect information

ChatGPT didn’t have access to some private or confidential information during training

Sample record of a supervised finetuning dataset
Providing relevant information to the LLM as part of the input
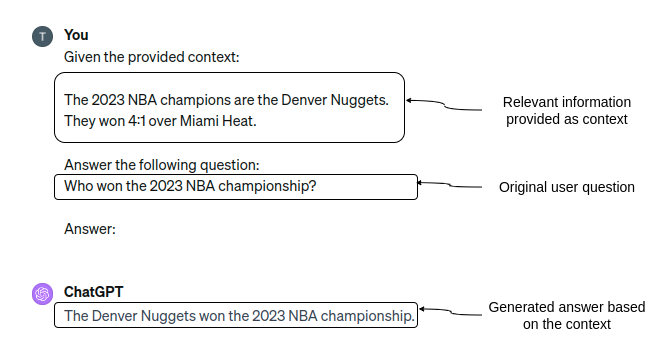
Providing relevant information to the answer as part of the prompt
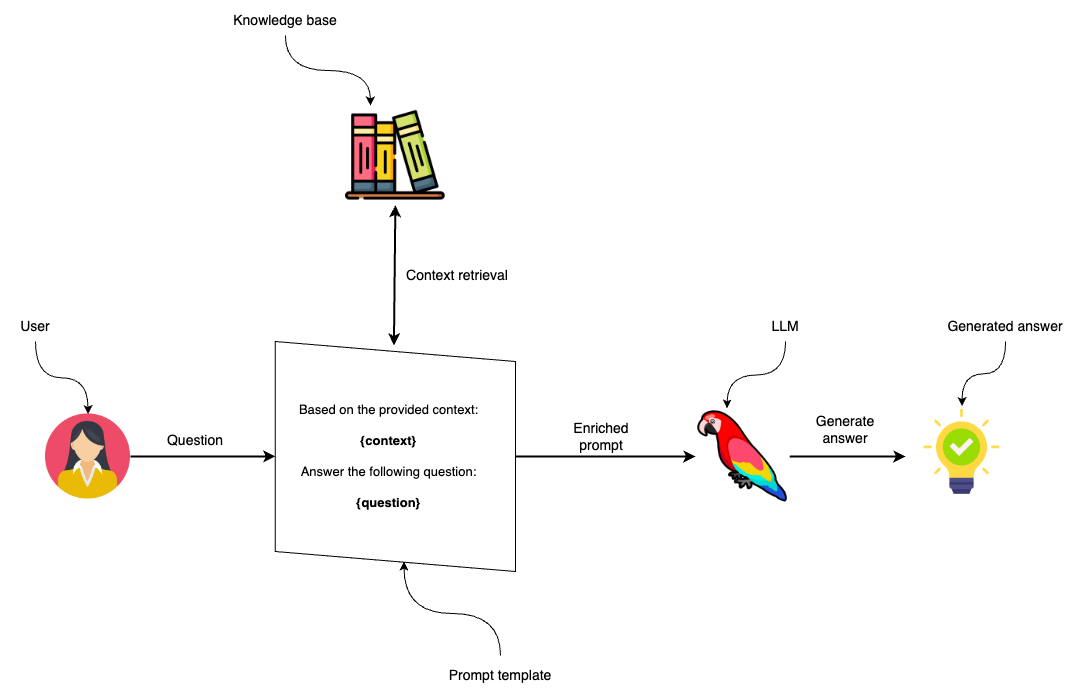
Populating the relevant data from the user and knowledge base into the prompt template and then passing it to an LLM to generate the final answer
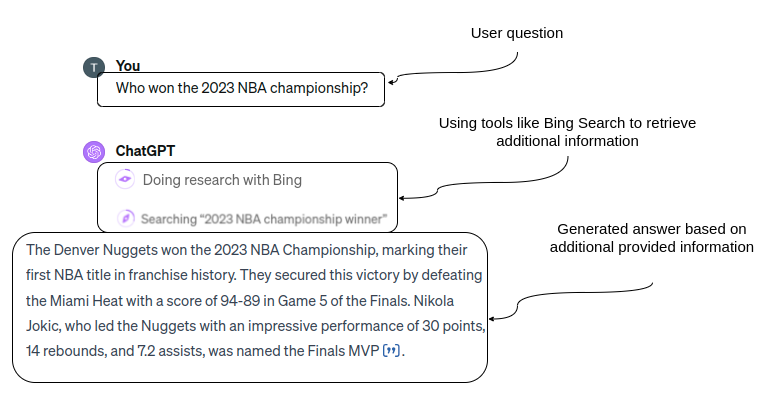
ChatGPT uses Web Search to find relevant information to generate an up-to-date answer
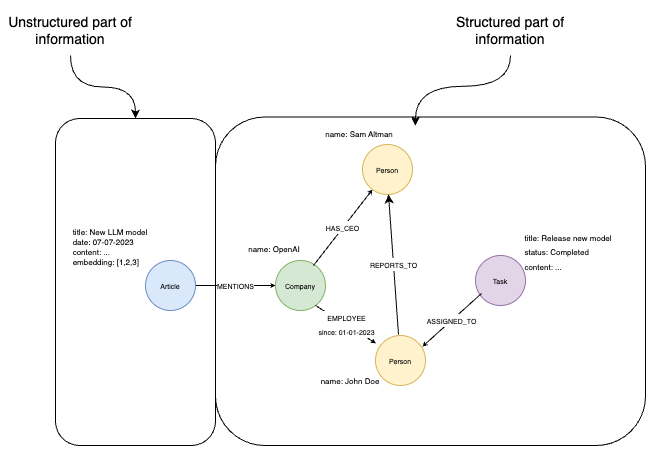
Knowledge graph can store complex structured and unstructured data in a single database system
Summary
- Large Language Models (LLMs), such as ChatGPT, are built on transformer architecture, enabling them to process and generate text efficiently by learning patterns from extensive textual data.
- While LLMs exhibit remarkable abilities in natural language understanding and generation, they have inherent limitations, such as a knowledge cutoff, potential to generate outdated or hallucinated information, and inability to access private or domain-specific knowledge.
- Continuous fine-tuning of LLMs to enhance their internal knowledge base is not practical due to resource constraints and the complexity of updating the models regularly.
- Retrieval-Augmented Generation (RAG) addresses LLM limitations by combining them with external knowledge bases, providing accurate, context-rich responses by injecting relevant facts directly into the input prompt.
- RAG implementations have traditionally focused on unstructured data sources, limiting their scope and effectiveness for tasks requiring structured, precise, and interconnected information.
- Knowledge Graphs (KGs) use nodes and relationships to represent and connect entities and concepts, integrating structured and unstructured data to provide a holistic data representation.
- Integrating Knowledge Graphs into RAG workflows enhances their capability to retrieve and organize contextually relevant data, allowing LLMs to generate accurate, reliable, and explainable responses.
FAQ
What problem is this chapter trying to solve?
This chapter focuses on improving the factual accuracy and timeliness of Large Language Model (LLM) answers. It explains why LLMs alone can be inaccurate or outdated and introduces Retrieval-Augmented Generation (RAG) and Knowledge Graphs to reduce hallucinations, incorporate up-to-date and private data, and produce reliable, explainable results.How do Large Language Models (LLMs) work at a high level?
LLMs are transformer-based neural networks trained to predict the next token in text. They learn patterns, grammar, and some reasoning from vast corpora and can follow instructions to generate useful outputs. They do not store explicit facts; instead, they encode statistical associations in learned weights and generate answers from those representations.What are the key limitations of LLMs covered here?
- Knowledge cutoff: models don’t know about events after their last training date (e.g., post–Oct 2023).- Outdated information: they may confidently state facts that have since changed.
- Hallucinations: they can produce plausible-sounding but false details (e.g., bogus IDs or citations).
- Lack of private data: they can’t answer about proprietary/internal information not seen during training.
Why do LLMs hallucinate?
LLMs are probabilistic language models, not fact databases or reasoning engines. They generate the most likely next tokens based on patterns, which can yield confident but incorrect specifics (such as URLs, IDs, or citations), even for pre-cutoff topics.Why isn’t continuous fine-tuning a complete fix for LLM limitations?
Pretraining is too costly to run continuously, and supervised finetuning (SFT) shows mixed results for reliably teaching new facts. LLM training typically includes: (1) Pretraining, (2) Supervised Finetuning, (3) Reward Modeling, and (4) Reinforcement Learning. While SFT can help, deploying a consistently accurate, finetuned model for factual updates remains challenging in production.What is Retrieval-Augmented Generation (RAG) and how does it work?
RAG pairs an LLM with an external knowledge base so the model can ground answers in retrieved facts at runtime. It has two stages: (1) Retrieval: fetch relevant documents/data; (2) Augmented Generation: combine the retrieved context with the user’s question in the prompt so the LLM produces a context-grounded answer. RAG reduces (but does not eliminate) hallucinations.When should I prefer RAG over finetuning?
Use RAG when you need current information, access to private or domain-specific data, explainability, or quick updates without retraining. Finetuning can improve style or task adherence, but RAG is the simpler, more reliable way to inject fresh, verifiable knowledge into answers.What are Knowledge Graphs and why add them to RAG?
Knowledge Graphs (KGs) are structured representations of entities, attributes, and relationships. In RAG, they: (1) bridge structured and unstructured data, (2) enable precise, explainable retrieval, and (3) connect text passages to concrete entities and relations—for example, linking a customer’s query to their exact order, or a drug question to clinical guidelines and patient history.What kinds of questions need structured data vs. unstructured text?
- Structured data (ideal for precise queries): filtering, counting, aggregations (e.g., “How many tasks are completed?”, “Who reports to whom?”, “Who is the CEO?”).- Unstructured text (ideal for open-ended context): explanations, narratives, and nuanced descriptions (e.g., article content about a new model).
Combining both in a KG lets you answer a broader range of questions accurately and with context.
 Essential GraphRAG ebook for free
Essential GraphRAG ebook for free