1 Intro to enterprise RAG
This chapter introduces Retrieval Augmented Generation (RAG) as a practical way to get precise, conversational answers from company data, like having a tireless digital assistant who knows where everything is. RAG pairs a language model with search to understand natural-language questions, retrieve the most relevant information from diverse sources (databases, documents, apps), and compose clear answers in seconds. Beyond simple lookups, it adapts to user intent and language, turning fragmented, hard-to-reach information into immediate, useful responses.
The chapter contrasts Naive RAG—embedding a query and doing a basic vector search—with Enterprise RAG built for real business constraints. While Naive RAG can work for simple tasks, it often misretrieves, hallucinates, and struggles at scale. Enterprise RAG adds a robust pipeline: input validation, question triage, query rewriting, hybrid (keyword + vector) search across multiple sources, asynchronous agents, relevance ranking and filtering, and a writer step to deliver consistent, grounded answers. It also addresses operational needs like multilingual support, data freshness, access control, guardrails, reliability, and cost management, driving both higher accuracy and faster time to answer.
Why it matters for business: Enterprise RAG accelerates decisions, improves customer service, streamlines collaboration, and works across organizations of any size. The chapter illustrates use cases from small shops to global enterprises, including inventory and reordering, competitive intelligence, healthcare insights, finance summaries, and academic research support. It also previews how to build such a system: ingesting and chunking content with metadata, embedding and indexing, optimizing retrieval with query rewriting and agents, and generating polished, trustworthy responses. By the end of the book, readers will be able to implement a scalable RAG solution that makes organizational knowledge instantly usable.
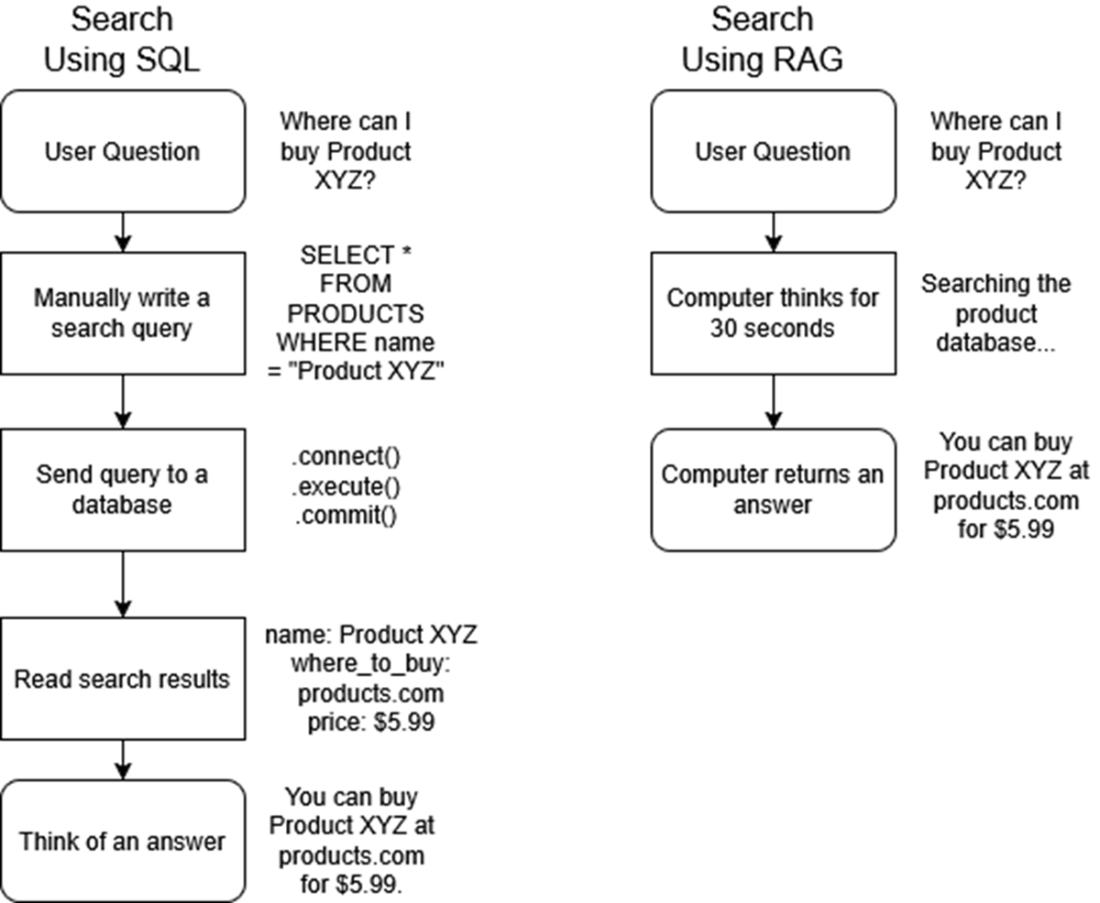
The left column shows the multiple steps and complexity of manually searching a SQL database for records. Compare this with the relative ease and simplicity of asking the question of a RAG chatbot instead,shown in the right column.
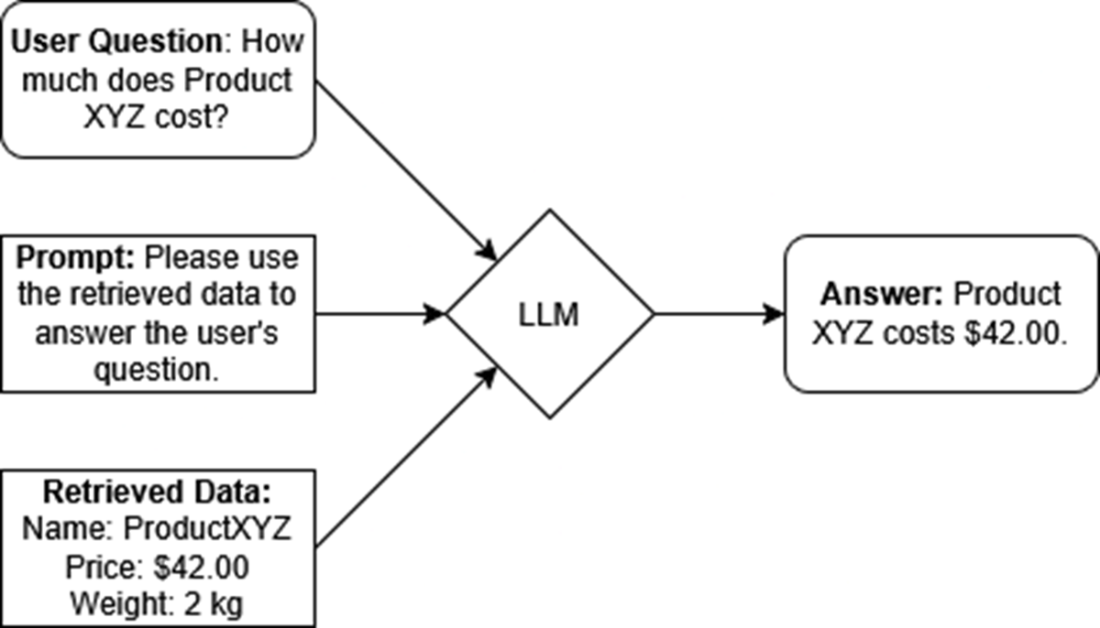
In a RAG system, the user question, the prompt, and the retrieved data are combined and sent to an LLM, which generates an answer using all that input information.
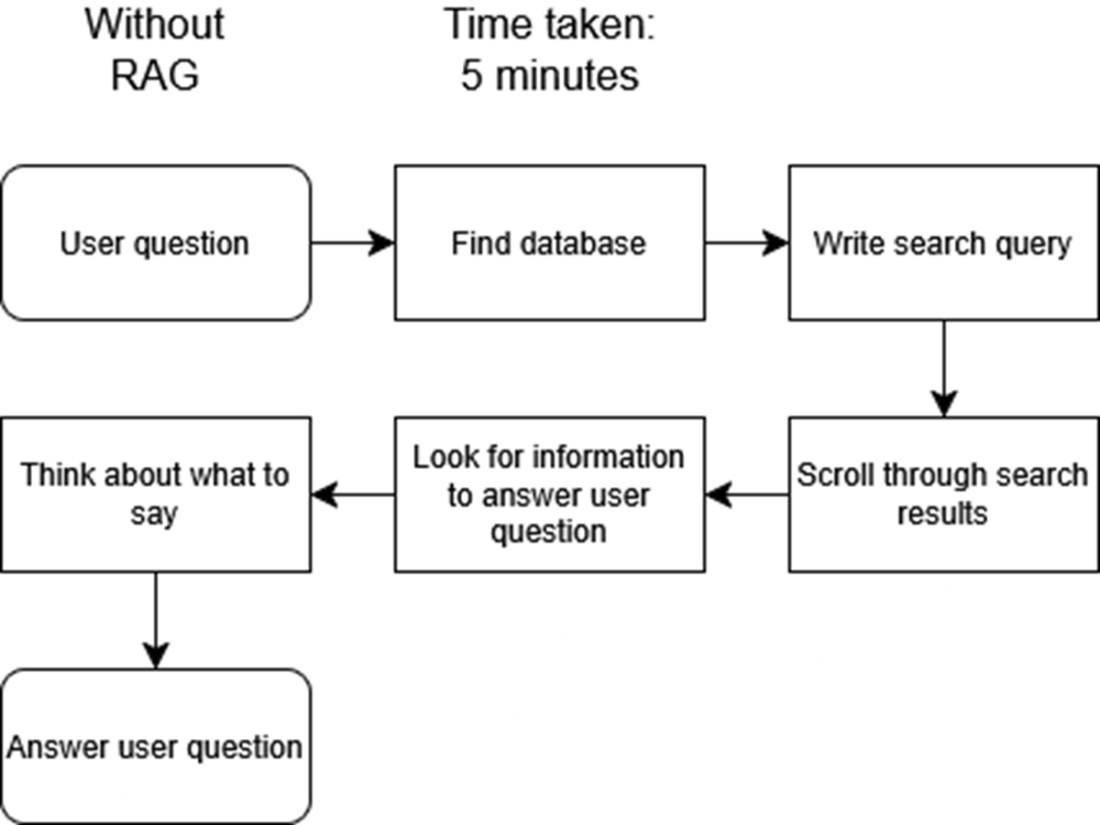
Traditional manual workflow for retrieving answers, requiring database queries, corrections, and manual review. This process is time-consuming, and requires a lot of effort.
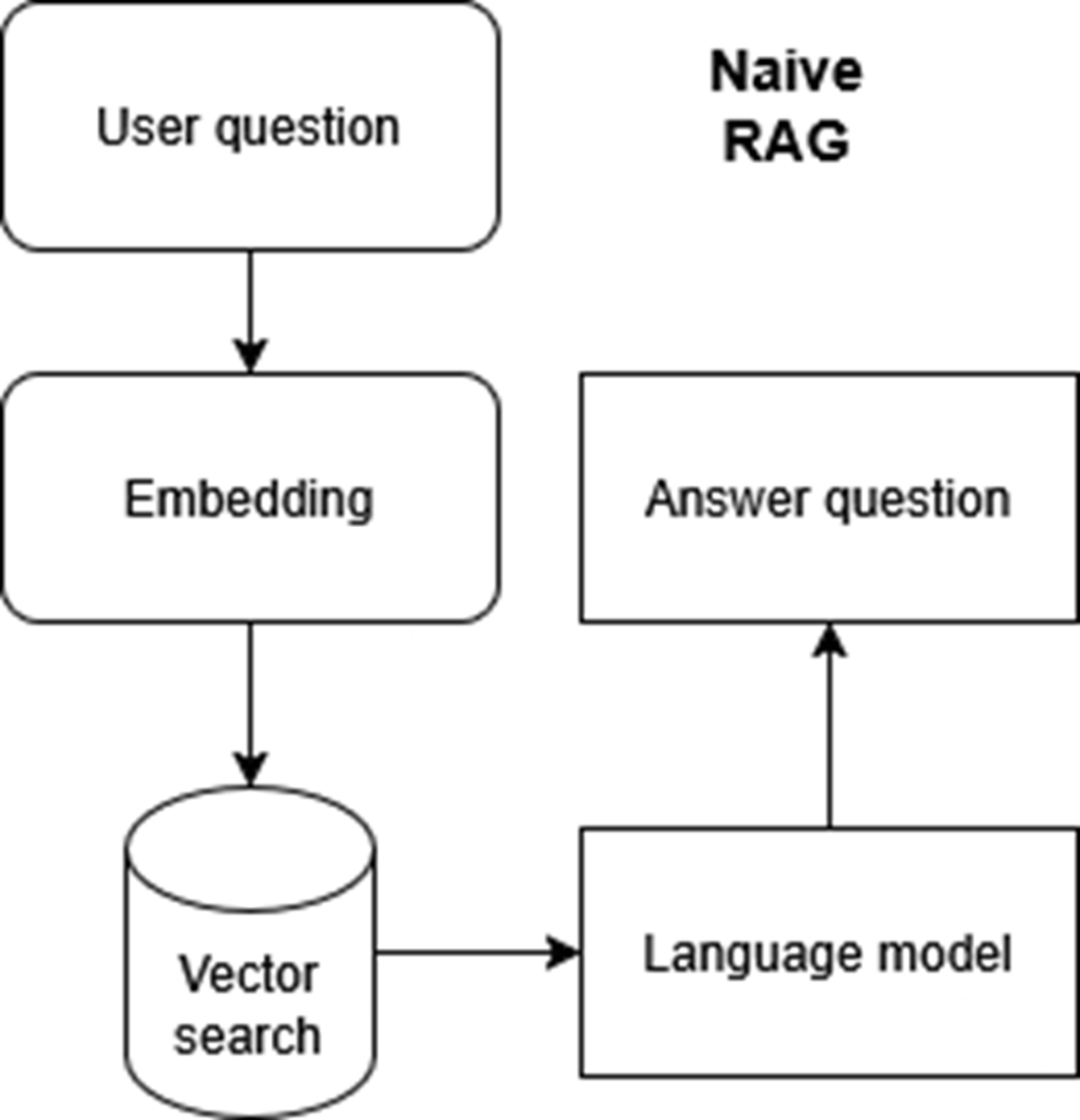
Basic RAG process with embedding, vector search, and a large language model. This simple approach is efficient but prone to errors and lacks context handling.
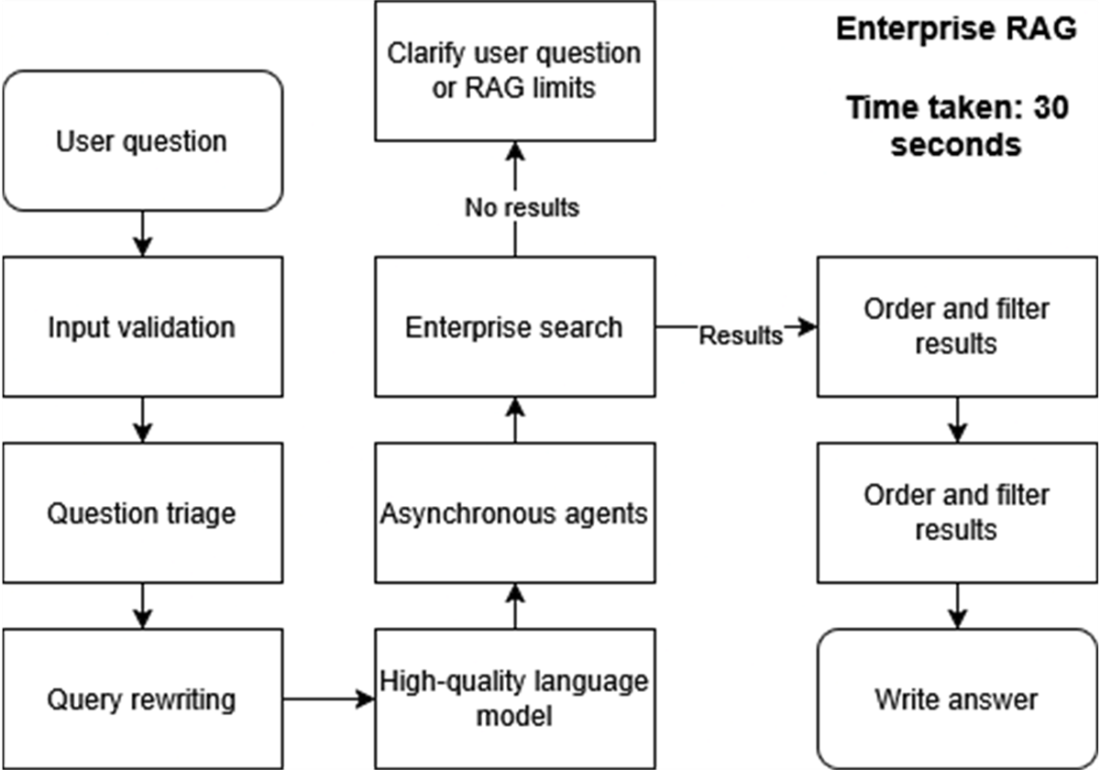
Enterprise RAG pipeline improves speed, accuracy, and scalability by incorporating validation, query rewriting, and asynchronous agents, reducing response times to 30 seconds..
A naive RAG pipeline with limited steps for retrieving answers. Suitable for simple queries but insufficient for handling complex or large-scale enterprise needs.

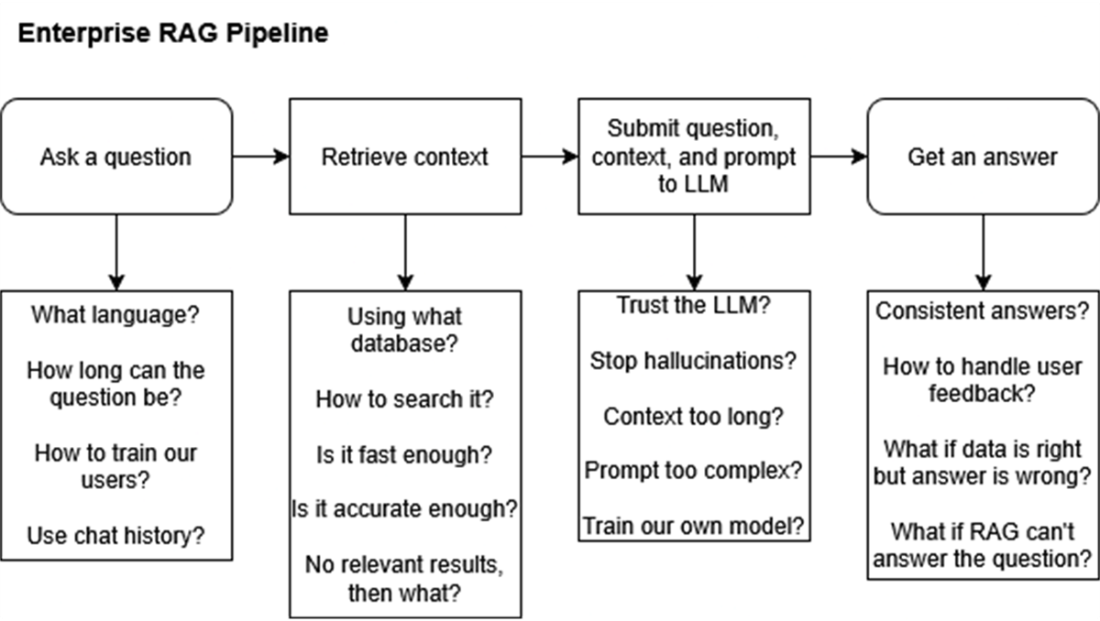
Key questions for designing enterprise RAG systems, addressing user input limits, database performance, context accuracy, and feedback management for better scalability and reliability.
Enterprise RAG system architecture showing ingestion, retrieval, and generation steps. Raw data is preprocessed, embedded, and searched to deliver accurate, context-aware answers.
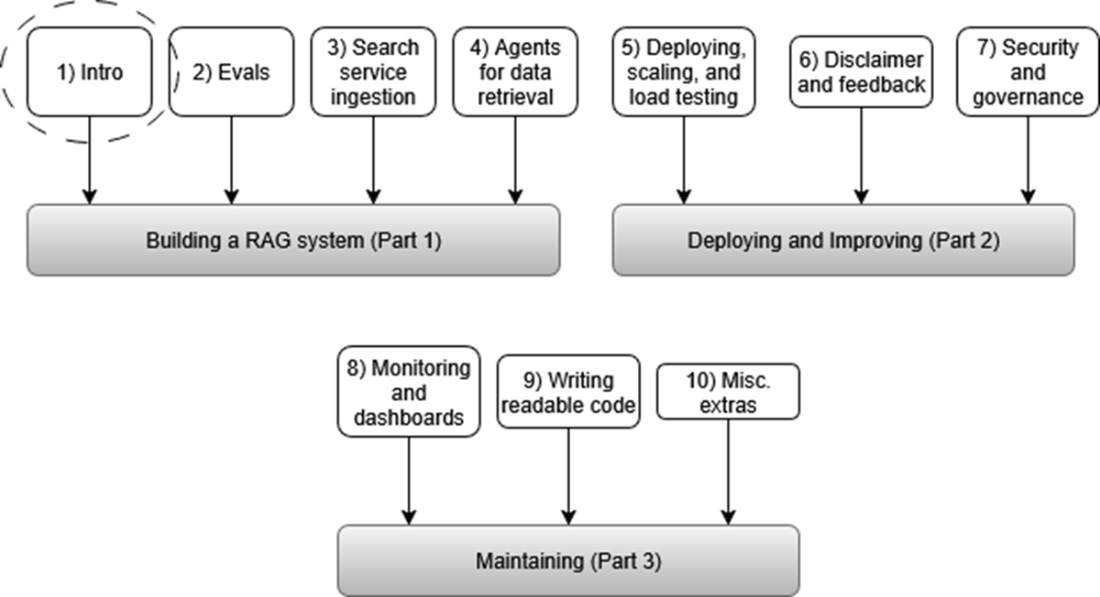
Summary
- Retrieval Augmented Generation (RAG) is an advanced AI technology that combines conversational skills with real-time data retrieval, like an efficient assistant.
- RAG allows users to ask questions in plain language and receive detailed, specific information tailored to their needs, accessing data from databases, documents, and applications like Slack.
- Naive RAG, while easy to set up, often falls short in business environments due to misunderstandings of context, retrieving incorrect data, or providing inaccurate ("hallucinated") answers.
- Enterprise RAG is designed to handle complex business scenarios, accurately processing diverse questions in different languages and grasping user intent.
- Implementing Enterprise RAG leads to streamlined operations, faster decision-making, improved collaboration, and enhanced customer service by resolving issues quickly.
- The book will guide readers step-by-step in building their own Enterprise RAG system, empowering them to harness the full potential of AI-driven data retrieval.
 Enterprise RAG ebook for free
Enterprise RAG ebook for free