12 Object detection
Object detection locates and labels objects in images by predicting bounding boxes, enabling tasks like counting, tracking across video frames, and cropping regions of interest for downstream models. Although instance segmentation yields richer, pixel-level information (and can imply bounding boxes), it is more computationally demanding and far costlier to label. When pixel-precise masks aren’t required, object detection is typically preferred for its speed and data-efficiency.
Modern detectors fall into two families. Two-stage models (R-CNN variants) first generate region proposals and then classify/refine them; they’re accurate but computationally heavy. Single-stage models (YOLO, SSD, RetinaNet) predict boxes and classes in one pass, offering much higher throughput with a small potential accuracy trade-off—ideal for real-time use where recent YOLO variants are especially popular. The chapter walks through training a simplified YOLO from scratch on COCO: normalizing boxes, mapping them to a prediction grid, and building a model with a ResNet backbone that outputs per-cell box coordinates, confidence, and class probabilities. A custom loss combines squared error for box parameters with an IoU-driven confidence target, and uses weighting tricks to balance empty cells and emphasize localization. With limited training, results are promising but underfit, and the chapter outlines straightforward avenues for improvement (more data/epochs, augmentation, multi-box per cell, larger grids).
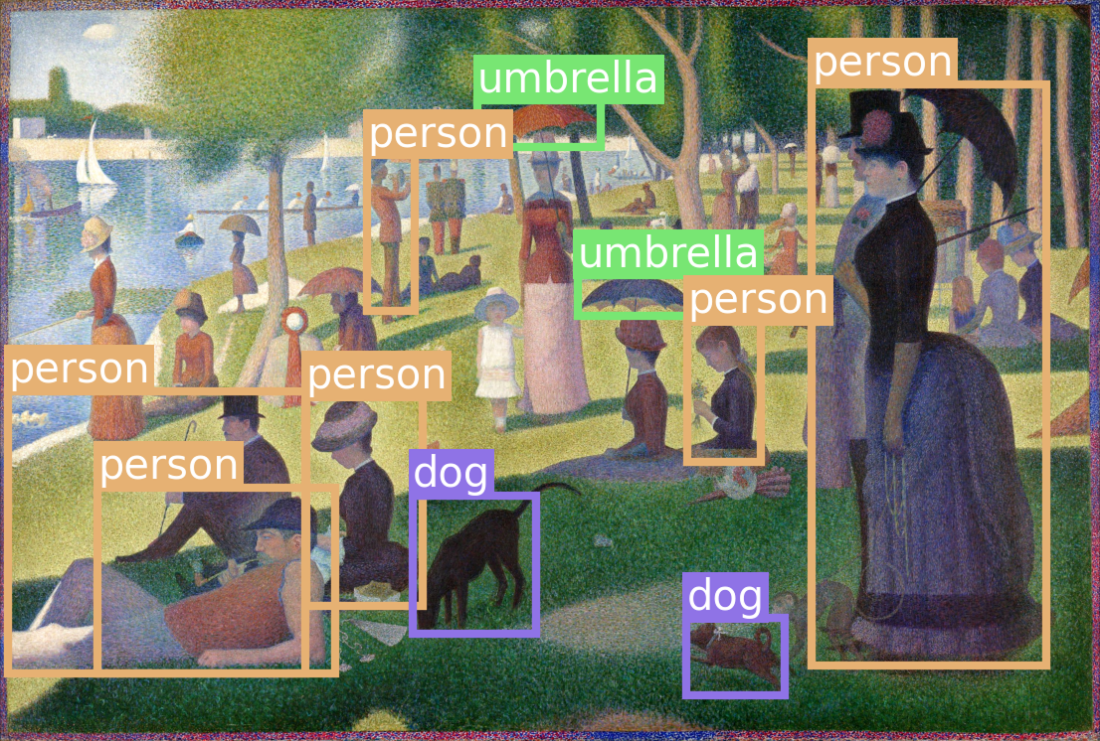
It then demonstrates inference with a pretrained RetinaNet, highlighting its feature pyramid network: upsampling deep semantic features and fusing them with higher-resolution features via lateral connections to better detect both small and large objects. This multi-scale design, now adopted by many YOLO versions, helps models generalize even to out-of-distribution imagery (e.g., pointillist paintings). The overarching guidance is to choose detection when you need object locations rather than pixel masks, pick architectures that match your latency and compute constraints, and leverage pretrained single-stage detectors for strong, practical performance.
Object detectors draw boxes around objects in an image and label them.

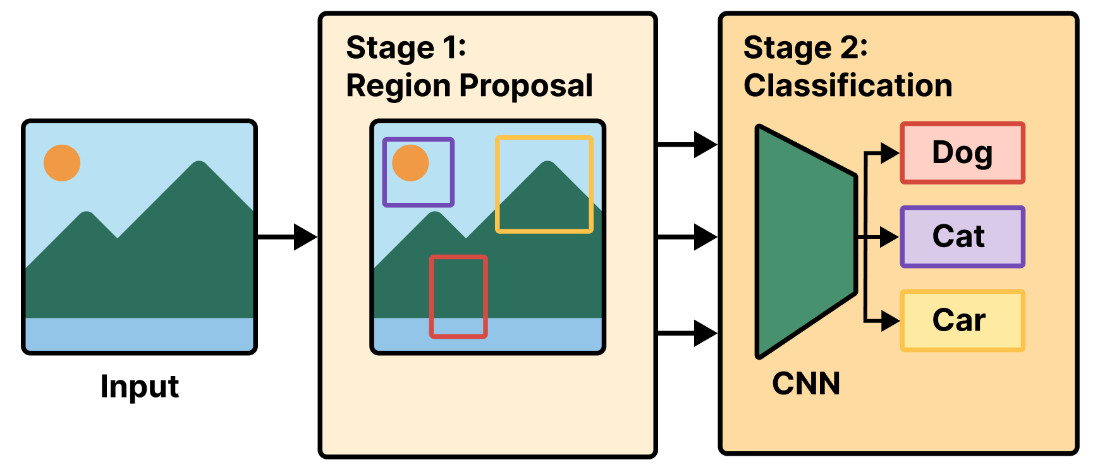
An R-CNN first extracts region proposals, then classifies the proposals with a convnet (a CNN).
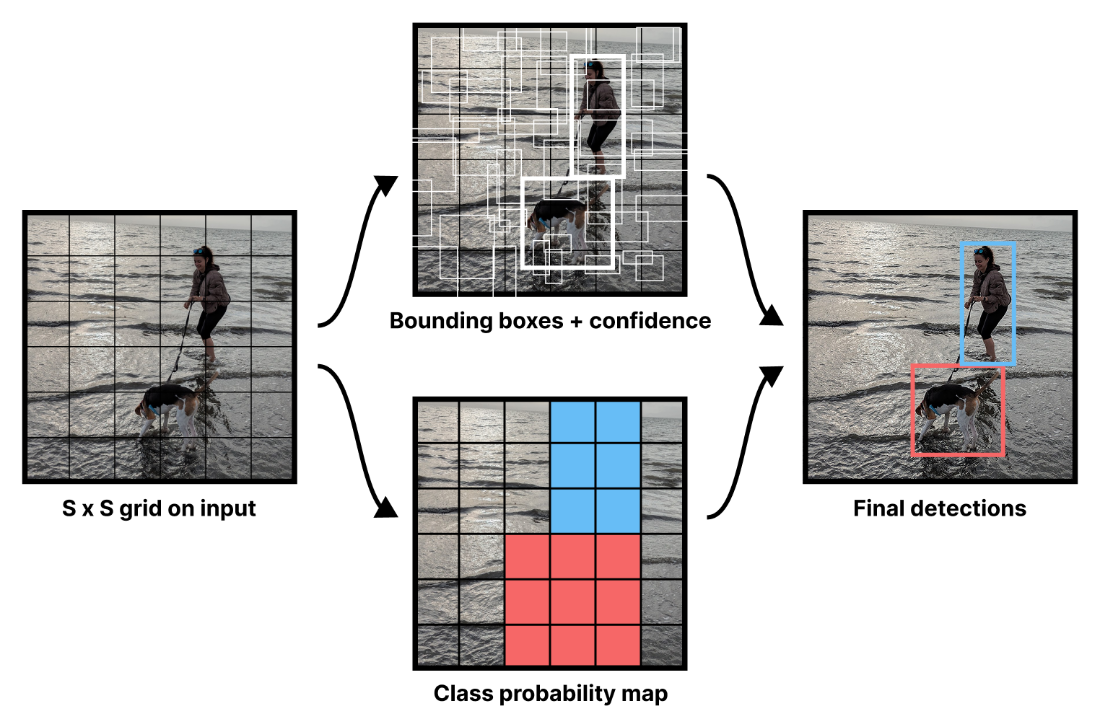
YOLO outputs a bounding box prediction and class label for each image region. [2]

YOLO outputs as visualized in the first YOLO paper.
YOLO outputs a bounding box prediction and class label for each image region. [4]

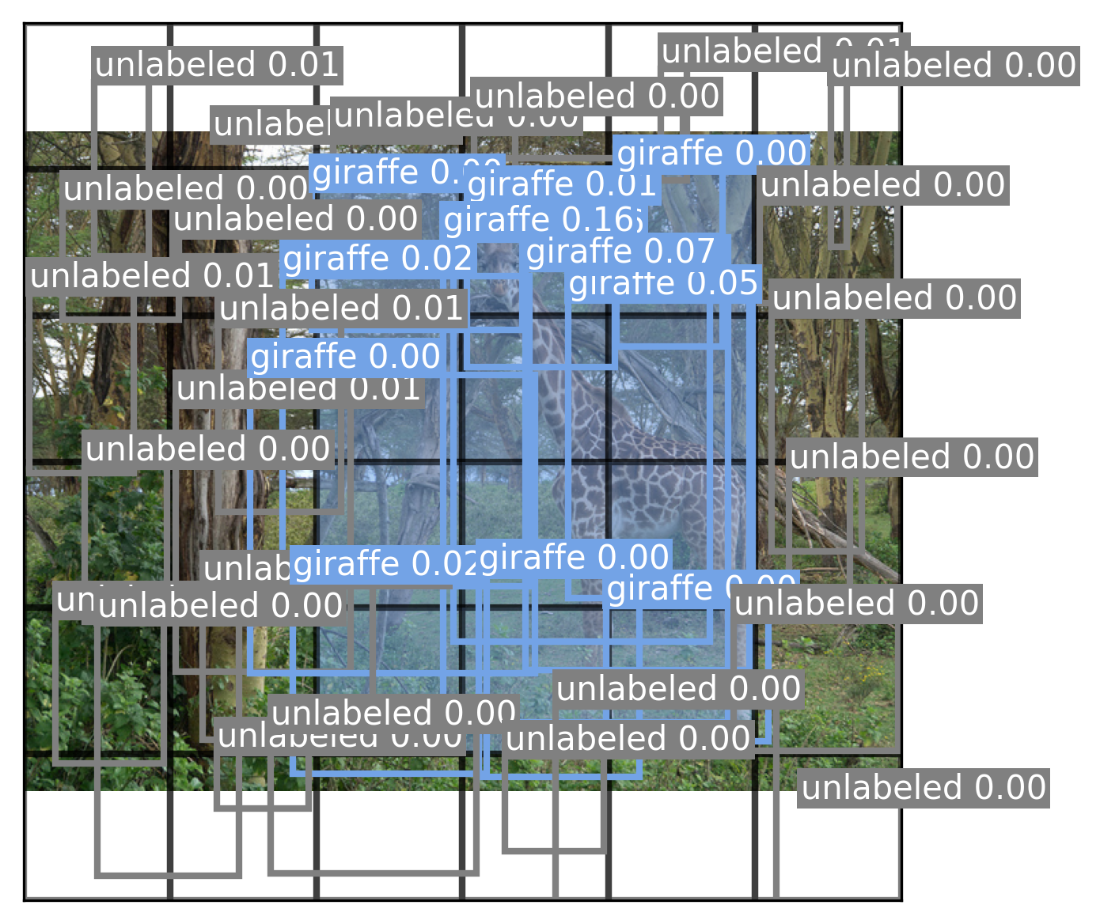
Predictions for our sample image.

Every bounding box predicted by the YOLO model.
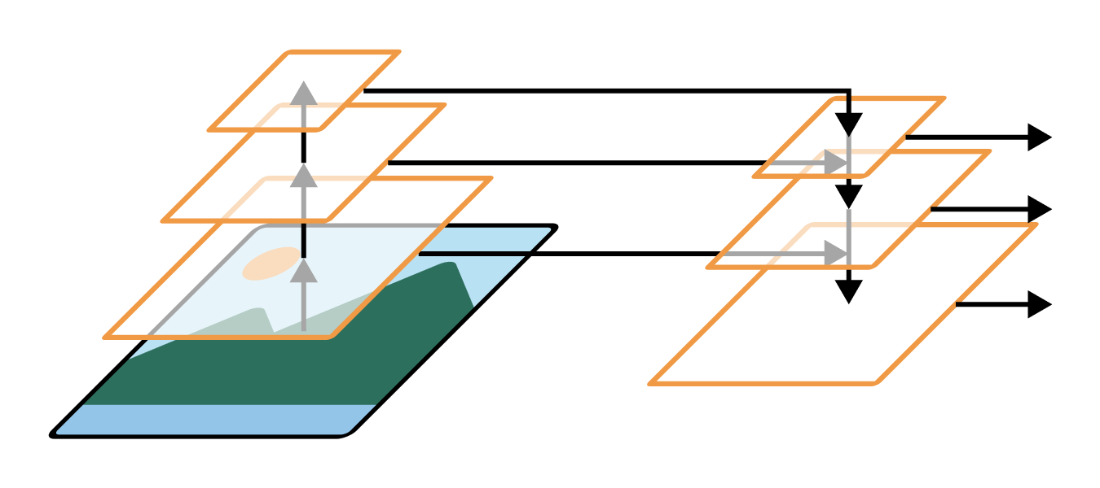
A feature pyramid network creates semantically interesting feature maps at different scales.
Predictions on a test image from the RetinaNet model.
Chapter summary
- Object detection identifies and locates objects within an image using bounding boxes. It’s basically a weaker version of image segmentation, but one that can be run much more efficiently.
- There are two primary approaches to object detection:
- Region-based Convolutional Neural Networks (R-CNNs), which are two-stage models that first propose regions of interest and then classify them with a convnet.
- Single-stage detectors (like RetinaNet and YOLO), which perform both tasks in a single step. Single-stage detectors are generally faster and more efficient, making them suitable for real-time applications (e.g., self-driving cars).
- YOLO computes two separate outputs simultaneously during training – possible bounding boxes and a class probability map.
- Each candidate bounding box is paired with a confidence score, which is trained to target the Intersection over Union of the predicted box and the ground truth box.
- The class probability map classifies different regions of an image as belonging to different objects.
- RetinaNet builds on this idea by using a feature pyramid network (FPN), which combines features from multiple convnet layers to create feature maps at different scales, allowing it to more accurately detect objects of different sizes.
[1] The COCO 2017 detection dataset can be explored at https://cocodataset.org/ Most images in this chapter are from the dataset.
[2] Image from the COCO 2017 dataset. https://cocodataset.org/ Image from Flickr, http://farm8.staticflickr.com/7250/7520201840_3e01349e3f_z.jpg, CC BY 2.0 https://creativecommons.org/licenses/by/2.0/
[3] Redmon et al., “You Only Look Once: Unified, Real-Time Object Detection”, CoRR (2015), https://arxiv.org/abs/1506.02640
[4] Image from the COCO 2017 dataset. https://cocodataset.org/ Image from Flickr, http://farm9.staticflickr.com/8081/8387882360_5b97a233c4_z.jpg, CC BY 2.0 https://creativecommons.org/licenses/by/2.0/
 Deep Learning with Python, Third Edition ebook for free
Deep Learning with Python, Third Edition ebook for free
{kind=link}
{kind=link}