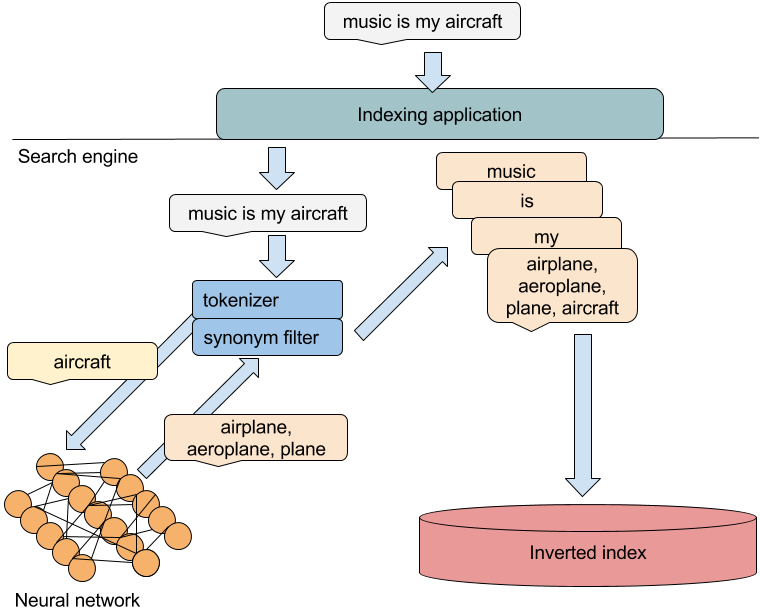
Synonyms are a practical way to boost recall in search by allowing different phrasings of the same intent to match the same documents. The chapter shows how synonym expansion can be applied at indexing or query time, and explains the trade-offs: expanding at index time increases index size but speeds up queries, while expanding at query time keeps the index lean but adds runtime cost. It first walks through a vocabulary-based approach using Lucene analyzers and token filters, then improves maintainability by loading synonyms from files and large resources like WordNet. However, static dictionaries are limited: they may not fit domain data, lag behind slang, acronyms, or evolving usage, and ignore context.
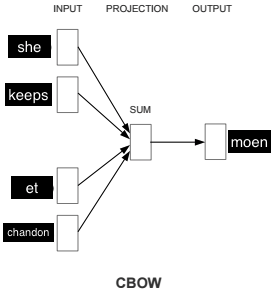
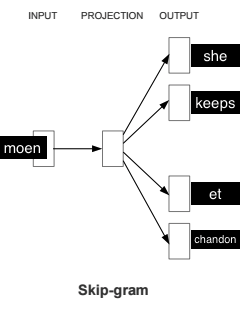
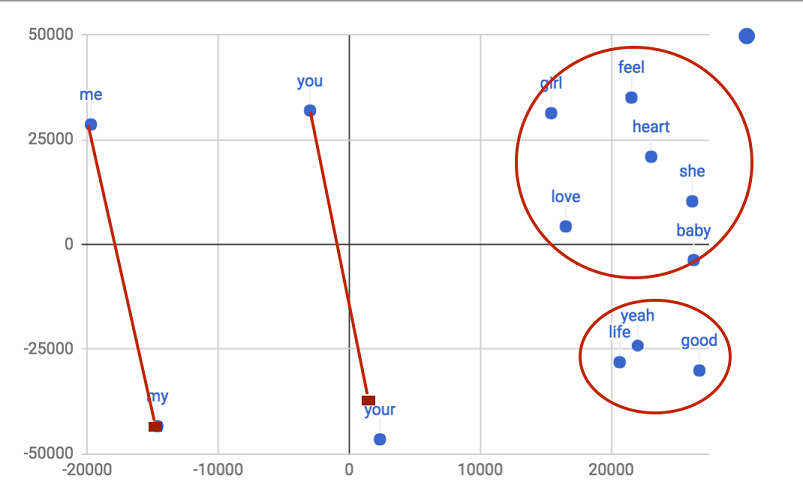
To overcome these limits, the chapter introduces learning synonyms from data via word2vec, grounded in the distributional hypothesis that words in similar contexts tend to share meaning. After a primer on feed-forward neural networks and backpropagation, it details the two word2vec architectures—CBOW and Skip-gram—and how they produce word embeddings whose proximity (e.g., cosine similarity) reveals semantic relatedness. The chapter demonstrates that higher-dimensional embeddings trained on larger, domain-relevant corpora yield much better neighbors, and shows a practical setup with Deeplearning4j to train vectors from song lyrics and query nearest words to act as synonyms.
Finally, it integrates learned synonyms into a Lucene pipeline by building a token filter that augments tokens with top, high-confidence neighbors from word2vec, while controlling index growth and noise via thresholds, part-of-speech constraints, document/term informativeness, and limits on the number of expansions. It underscores evaluation through precision, recall, zero-result rates, and model selection via cross-validation and parameter tuning (dimensions, window size, model choice). For production, it recommends retraining embeddings directly from the indexed corpus—using a custom SentenceIterator over stored field values—so synonym generation stays current as data evolves, and revisits the operational choice between index-time and query-time expansion based on performance needs.
Figure 2.1. Synonym expansion at search time, with a neural network
Figure 2.2. Synonym expansion graph
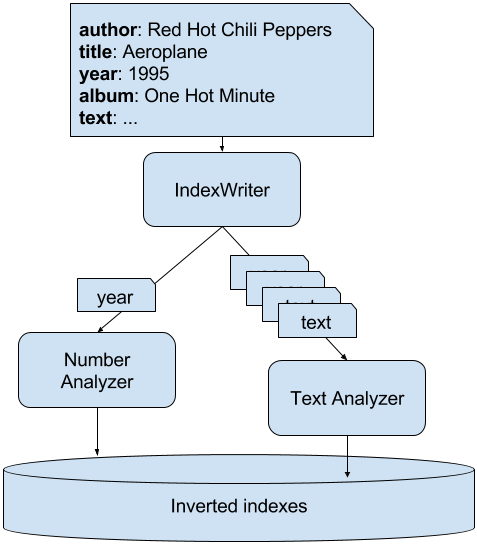
Figure 2.3. Split portions of the text depending on the type of data
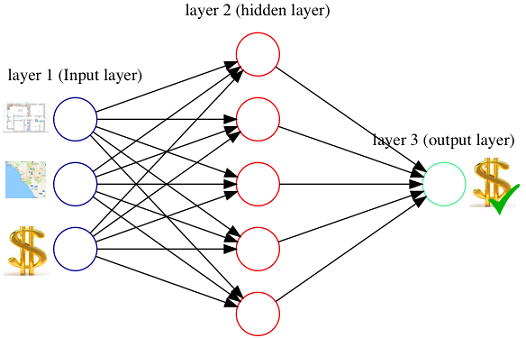
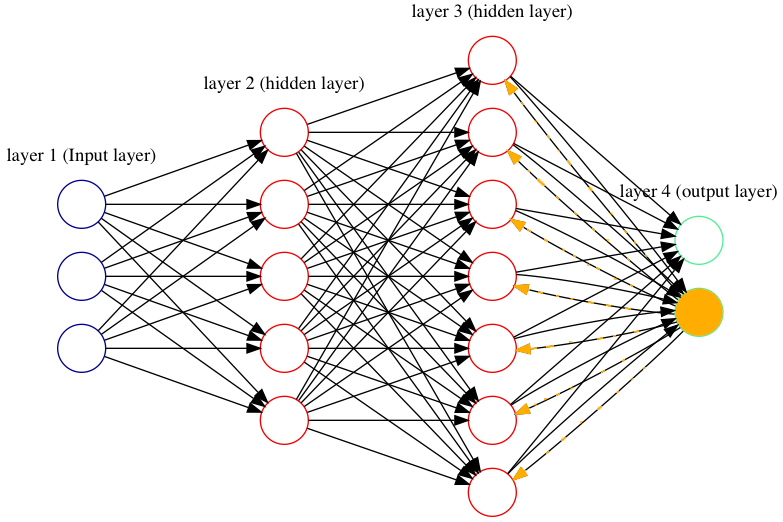
Figure 2.4. Predicting price with a feed forward neural network with 3 inputs, 5 hidden units and 1 output unit
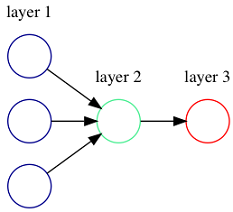
Figure 2.5. Propagating signal through the network
Figure 2.6. Backpropagating signal from output to hidden layer
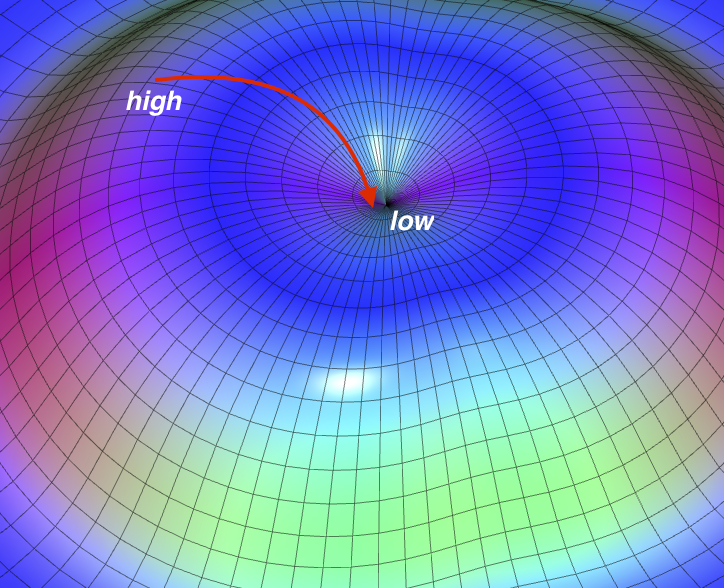
Figure 2.7. Geometric interpretation of backpropagation with gradient descent
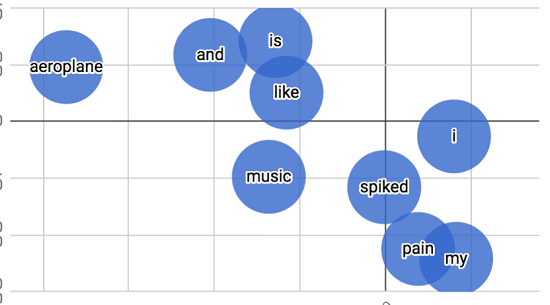
Figure 2.8. Plotted word vectors for Aeoroplane
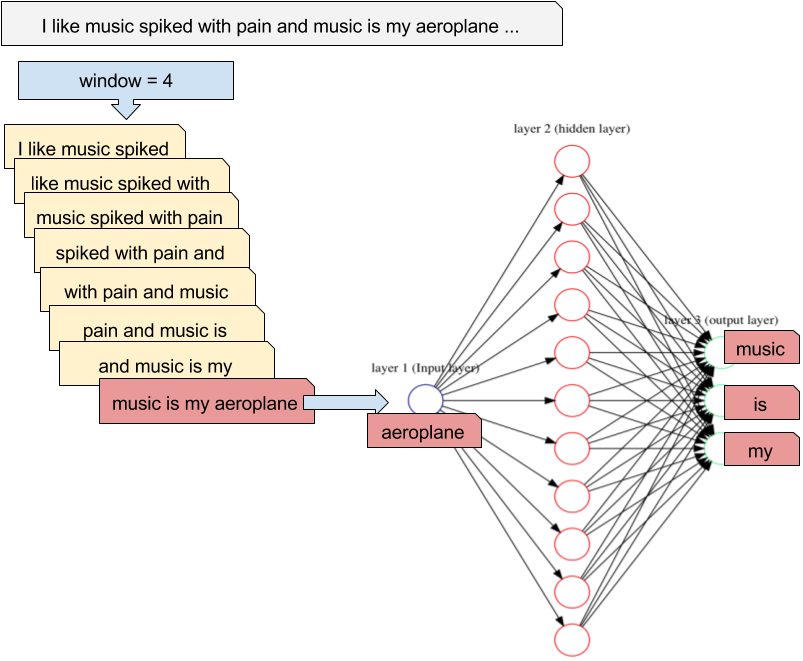
Figure 2.9. Feeding word2vec (skip gram model) with text fragments
Figure 2.10. Continuous Bag of Words model
Figure 2.11. Continuous Skip-gram Model
Figure 2.12. Highlights of Word2vec vectors over Hot 100 Billboard dataset
Figure 2.13. Token stream after word2vec synonym expansion
Summary
Synonym expansion can be an handy technique to improve recall and make the users of our search engine happier
Common synonym expansion techniques are based on static dictionaries / vocabularies which might require manual maintenance or, at least, are often very far from the data they are used for
Word2vec is a neural network based algorithm for learning vector representations for words which can be used to find words with similar meanings—or at least that appear in similar contexts so that it sounds reasonable to exploit it for synonym expansion too
Word2vec can provide good results, but we need to manage word senses or part of speech when using it for synonyms
FAQ
What is synonym expansion and why does it help search?Synonym expansion adds alternative terms with the same or very similar meaning to the query or to the indexed text at the same position. This increases the chances that differently worded queries match the same documents, boosting recall and reducing zero-result queries. Example: a query with “plane” can match a lyric indexed with “aeroplane.”Should I expand synonyms at index time or at search time?Both are valid with trade-offs. Index-time expansion makes indexing slower and the index larger, but queries run faster (no expansion at search). Search-time expansion keeps the index smaller and ingestion faster, but each query pays the expansion cost. Choose based on workload, latency, and throughput constraints.How do vocabulary-based synonym lists work, and what are their limitations?They map terms to synonyms via a maintained dictionary (e.g., a file or WordNet). Pros: predictable, easy to plug into Lucene’s SynonymGraphFilter. Cons: upkeep burden, language coverage gaps, and no awareness of corpus-specific usage or context (slang, acronyms, domain terms).How does word2vec generate synonyms from my data?Word2vec learns vector representations (embeddings) so that words used in similar contexts are close in vector space (distributional hypothesis). By finding nearest neighbors (e.g., cosine similarity), you can surface corpus-specific synonym-like terms. It’s language-agnostic and context-driven, unlike grammar-based lexicons.CBOW vs Skip-gram: which word2vec model should I use?Both learn embeddings from windows of text. CBOW predicts a target word from its context; Skip-gram predicts context words from a target. In practice, Skip-gram often performs better for infrequent words and is a common default in libraries like Deeplearning4J.What word2vec parameters matter most for synonym quality?Key settings include: embedding size (e.g., 100+ dimensions, higher for larger corpora), window size (context width, e.g., 5), training epochs, and model choice (CBOW vs Skip-gram). Too few dimensions or too little data yields poor neighbors; larger corpora and sensible windows improve results.How do I integrate word2vec synonyms into a Lucene pipeline?Train word2vec (e.g., with DL4J), then implement a TokenFilter that, for each token, looks up the top-k nearest words above a similarity threshold and emits them at the same position. Use SynonymGraphFilter-compatible behavior so phrase queries and positions still align.How can I prevent index bloat or noisy expansions with word2vec?Use safeguards: limit top-k synonyms, enforce a minimum similarity score, restrict to certain parts of speech (e.g., nouns and verbs), prioritize short or low-recall documents, and skip low-weight or very common terms. These controls keep expansions precise and manageable.How do I evaluate if synonym expansion improved my search?Compare metrics before/after enabling it: recall, precision, and zero-result rates. Use held-out sets or A/B tests. For model tuning, apply cross-validation: train on a subset, select parameters on a validation set, and report final effectiveness on a separate test set.How do I keep synonyms up to date in production as the corpus changes?Retrain embeddings periodically from the indexed data itself (e.g., iterate stored field values via a custom SentenceIterator over the Lucene index). This avoids needing original source files, adapts to evolving language/terms, and lets you refresh the synonym filter on a schedule.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!


 Deep Learning for Search ebook for free
Deep Learning for Search ebook for free