Modern data science is increasingly constrained by the limits of single-machine computing: long runtimes, unstable code, and fragile workflows emerge as datasets grow. While Python’s open data science stack (NumPy, Pandas, SciPy, scikit-learn) democratized analytics, it shines primarily on small datasets that fit in memory. The chapter frames a practical taxonomy—small, medium, and large data—to clarify when memory pressure, disk paging, and single-core execution become bottlenecks, motivating scalable computing as a core competency. It sets the stage for Dask as a way to carry familiar Python workflows beyond a single machine without forcing a wholesale shift in tools or mindset.
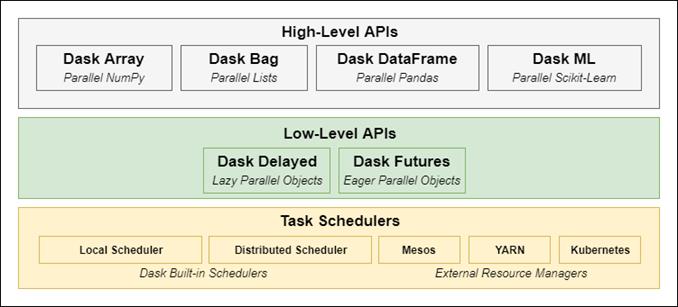
Dask is presented as a Python-native framework designed to scale the existing ecosystem by combining a task scheduler with low-level (Delayed, Futures) and high-level (Array, DataFrame, Bag) APIs. Its collections are composed of underlying NumPy and Pandas partitions, enabling parallel execution over chunks while keeping syntax familiar. The same code can run locally or on clusters with minimal configuration, and Dask’s lightweight setup, flexible parallelism, and fault tolerance make it effective for both medium data on a laptop and large data in distributed environments. A comparison with Spark highlights Dask’s advantages for Python practitioners—reduced JVM overhead, quicker learning curve, and greater flexibility for custom Python logic—while acknowledging Spark’s strengths for large-scale collection operations.
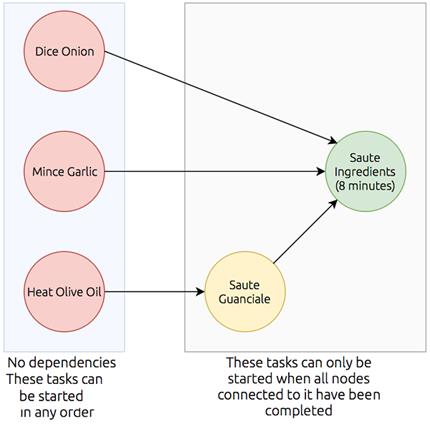
To explain how Dask orchestrates parallel work, the chapter introduces directed acyclic graphs (DAGs), using a cooking analogy to illustrate nodes, dependencies, directionality, and transitive reduction. DAGs allow the scheduler to prioritize tasks near the final result, keep workers busy, reduce memory pressure, and emit partial outputs sooner. The chapter also covers practical distributed computing concerns: choosing scale up versus scale out, handling concurrency and resource locks, and recovering from failures ranging from worker loss to data loss and even scheduler failure by replaying task lineage. It concludes by introducing a real-world companion dataset—New York City parking citations—used in subsequent chapters to apply these concepts to hands-on data preparation, analysis, and modeling with Dask.
The components and layers than make up Dask
My favorite recipe for bucatini all'Amatriciana

A graph displaying nodes with dependencies
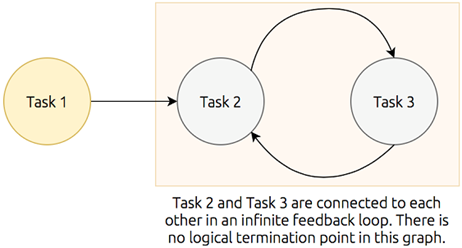
An example of a cyclic graph demonstrating an infinite feedback loop
The graph represented in figure 1.3 redrawn without transitive reduction
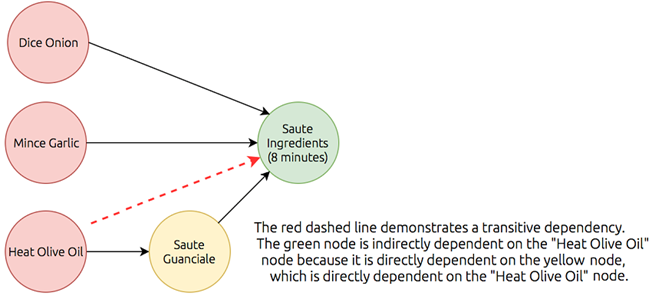
The full directed acyclic graph representation of the bucatini all’Amatriciana recipe.

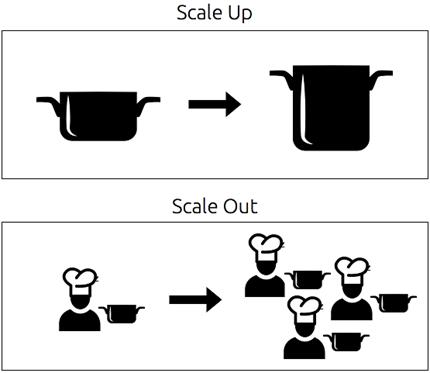
Scaling up replaces existing equipment with larger/faster/more efficient equipment, while scaling out divides the work between many workers in parallel.
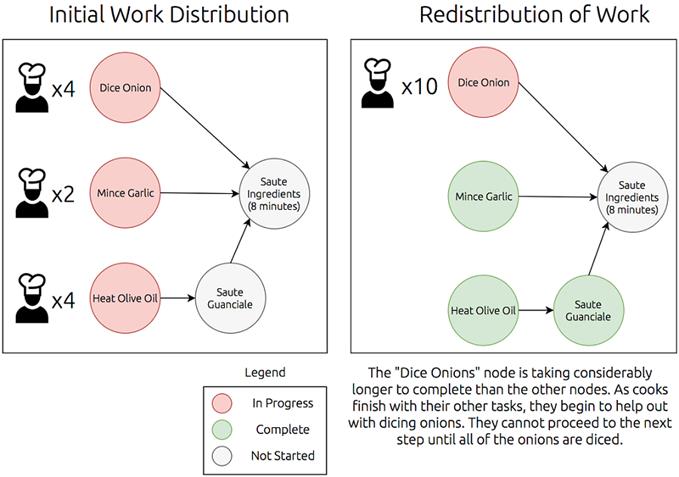
A graph with nodes distributed to many workers depicting dynamic redistribution of work as tasks complete at different times.
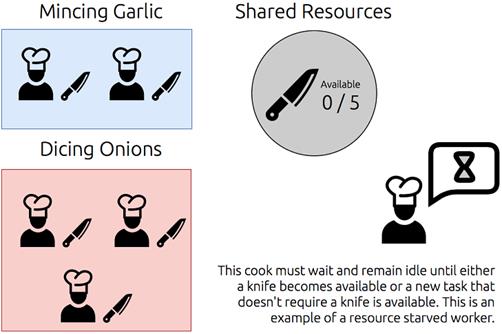
An example of resource starvation
Summary
In this chapter you learned
- Dask can be used to scale popular data analysis libraries such as Pandas and NumPy, allowing you to analyze medium and large datasets with ease.
- Dask uses directed acyclic graphs (DAGs) to coordinate execution of parallelized code across CPU cores and machines.
- Directed acyclic graphs are comprised of nodes, have a clearly defined start and end, a single traversal path, and no looping.
- Upstream nodes must be completed before work can begin on any dependent downstream nodes.
- Scaling out can generally improve performance of complex workloads, but it creates additional overhead that might substantially reduce those performance gains.
- In the event of a failure, the steps to reach a node can be repeated from the beginning without disturbing the rest of the process.
FAQ
When should I consider using Dask instead of just Pandas/NumPy/Scikit-learn?
Dask becomes valuable when your dataset pushes beyond single-machine RAM or when computations take painfully long, require paging (spilling to disk), or are hard to parallelize. The Python Open Data Science Stack excels on small, in-memory data; Dask extends those familiar tools to medium and large datasets with native parallelism and distributed execution.How does the book define small, medium, and large datasets?
Small: up to roughly 2–4 GB, fits comfortably in RAM. Medium: about 10 GB to 2 TB, fits on local disk but not RAM (often incurs paging and benefits from parallelism). Large: greater than ~2 TB, doesn’t fit in RAM or on a single machine’s disk. Boundaries are fuzzy and depend on hardware; think in orders of magnitude.What are Dask’s main components and layers?
At the core is a task scheduler that executes and monitors computations. Low-level APIs (Dask Delayed and Dask Futures) express work as tasks. High-level collections (Dask DataFrame, Array, Bag, etc.) build on these to provide familiar NumPy/Pandas-like interfaces whose operations translate into many parallel low-level tasks.What makes Dask stand out for scalable computing?
- It’s Python-native and natively scales NumPy, Pandas, and Scikit-learn by chunking data into partitions of real underlying objects.- It works well for medium data on a single machine and large data on a cluster, with minimal code changes.
- It can parallelize general Python workflows via Delayed/Futures, not just collection operations.
- It has low setup and maintenance overhead (pip/conda install, easy cluster images, sensible defaults).
 Data Science with Python and Dask ebook for free
Data Science with Python and Dask ebook for free