1 Meet Apache Airflow
Modern organizations rely on timely, trustworthy data, and Apache Airflow addresses the challenge of coordinating the growing volume of data operations by orchestrating them as workflows. The chapter introduces data pipelines as directed acyclic graphs (DAGs) of tasks, showing how representing dependencies explicitly enables reliable, repeatable execution. It situates Airflow within the broader ecosystem of workflow managers, highlighting its flexible, code-driven approach (primarily Python), rich integrations, scheduling capabilities, and monitoring features, then frames the core question of determining when Airflow is the right fit.
The text explains why DAGs are powerful: they make ordering and dependencies explicit, prevent cycles, and enable parallelism where tasks are independent—advantages over monolithic, sequential scripts. It sketches a simple algorithm for executing DAGs and maps it to Airflow’s runtime, covering key components—DAG Processor, Scheduler, Workers, Triggerer, and API server/metastore—and how they coordinate parsing, scheduling, queuing, and running tasks. Airflow’s scheduler supports cron-like schedules, retries, and observability through a web UI with graph and grid views for tracking runs, diagnosing failures, and selectively rerunning tasks. Crucially, its time-based semantics enable incremental processing and backfilling, which reduce cost and speed up pipelines by operating on data deltas and easily recreating historical outputs.
Finally, the chapter compares Airflow with alternative workflow tools, noting trade-offs in how workflows are defined (code versus static formats) and in built-in features (scheduling, monitoring, UI). Airflow excels for batch or event-driven pipelines on recurring or irregular schedules, deep integrations across systems, engineering best practices, and straightforward backfilling—benefits reinforced by its open-source maturity and managed offerings. It is less suitable for real-time streaming or teams seeking low-code, UI-first authoring, and it demands sound engineering to manage growing DAG complexity; features like full data lineage or versioning may require complementary tools. The chapter closes by outlining how the rest of the book progresses from Airflow fundamentals to advanced patterns and production deployment concerns.
For this weather dashboard, weather data is fetched from an external API and fed into a dynamic dashboard.
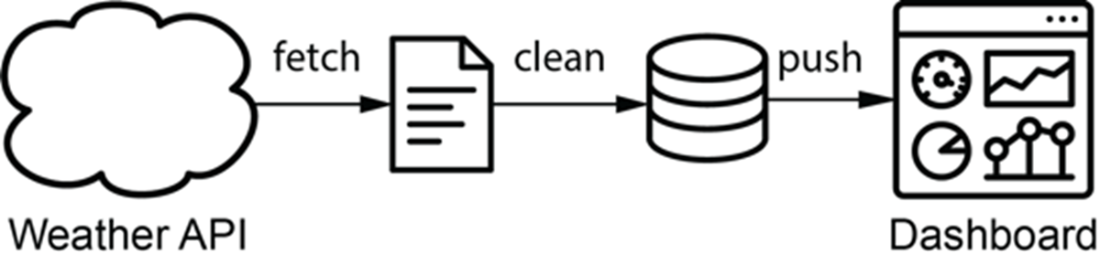
Graph representation of the data pipeline for the weather dashboard. Nodes represent tasks and directed edges represent dependencies between tasks (with an edge pointing from task 1 to task 2, indicating that task 1 needs to be run before task 2).

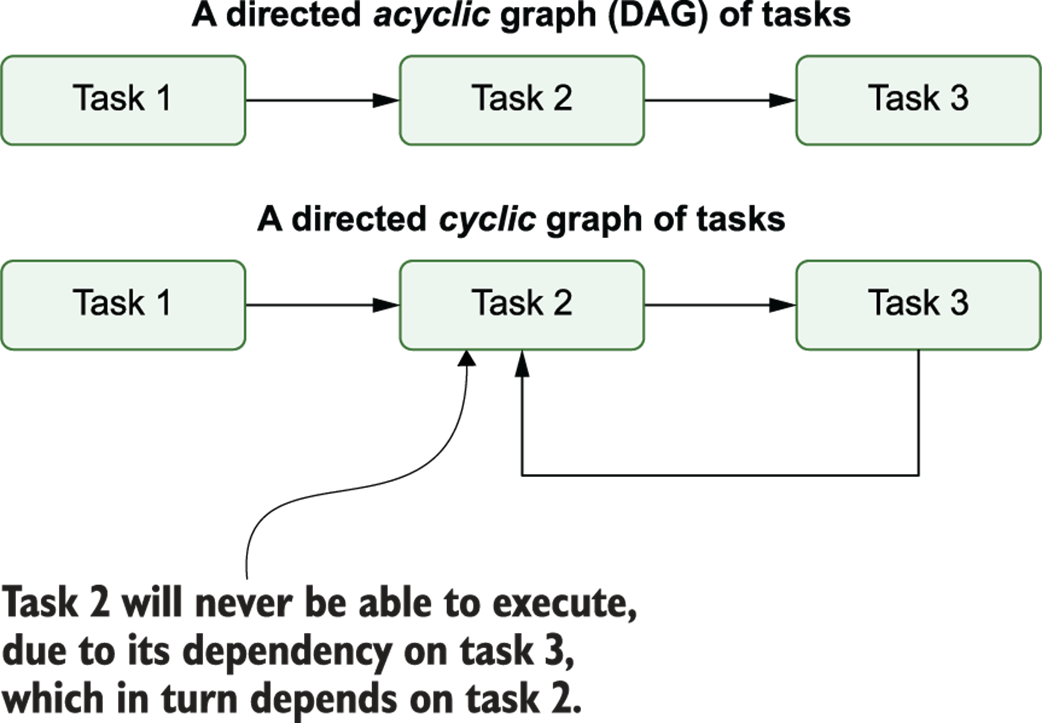
Cycles in graphs prevent task execution due to circular dependencies. In acyclic graphs (top), there is a clear path to execute the three different tasks. However, in cyclic graphs (bottom), there is no longer a clear execution path due to the interdependency between tasks 2 and 3.
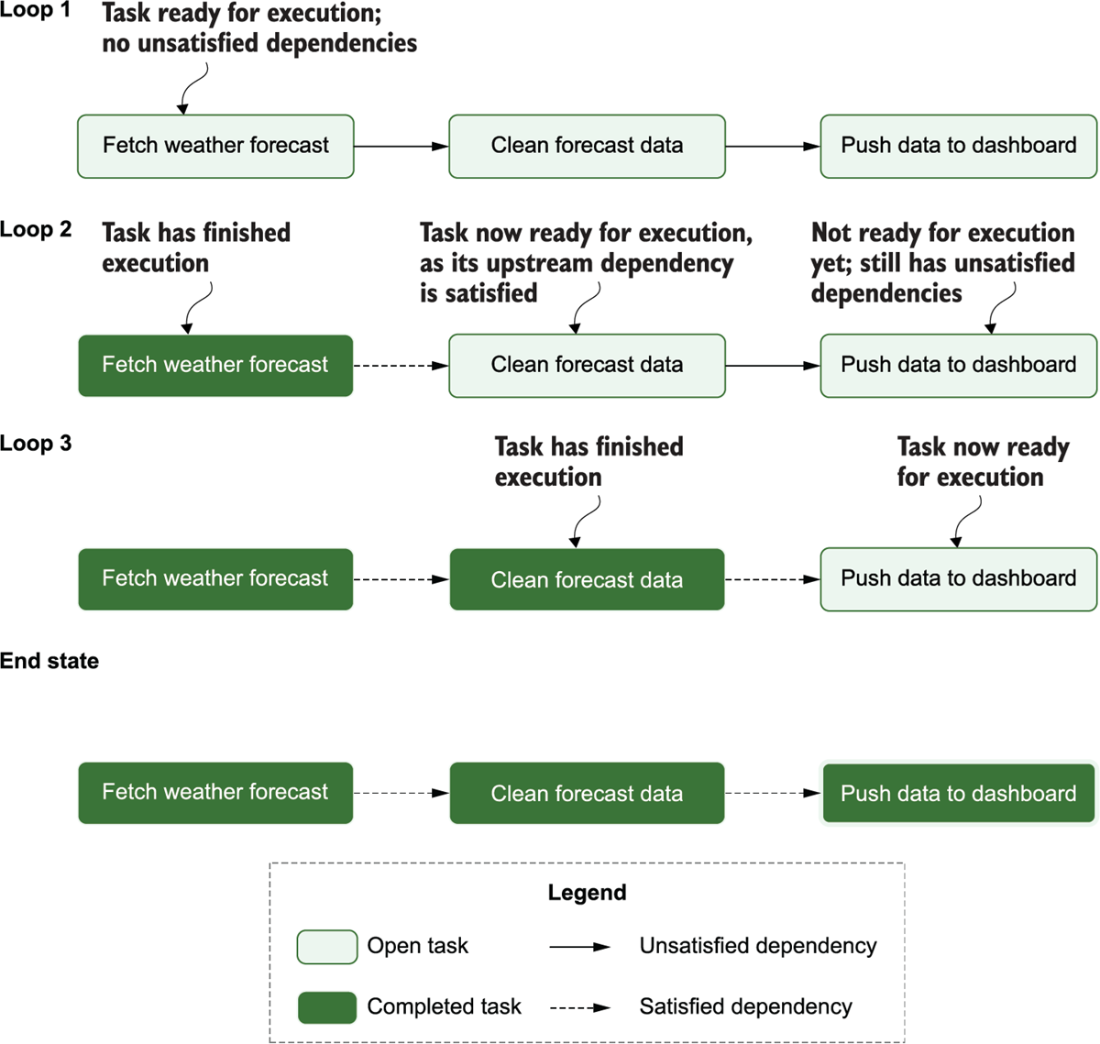
Using the DAG structure to execute tasks in the data pipeline in the correct order: depicts each task’s state during each of the loops through the algorithm, demonstrating how this leads to the completed execution of the pipeline (end state)
Overview of the umbrella demand use case, in which historical weather and sales data are used to train a model that predicts future sales demands depending on weather forecasts
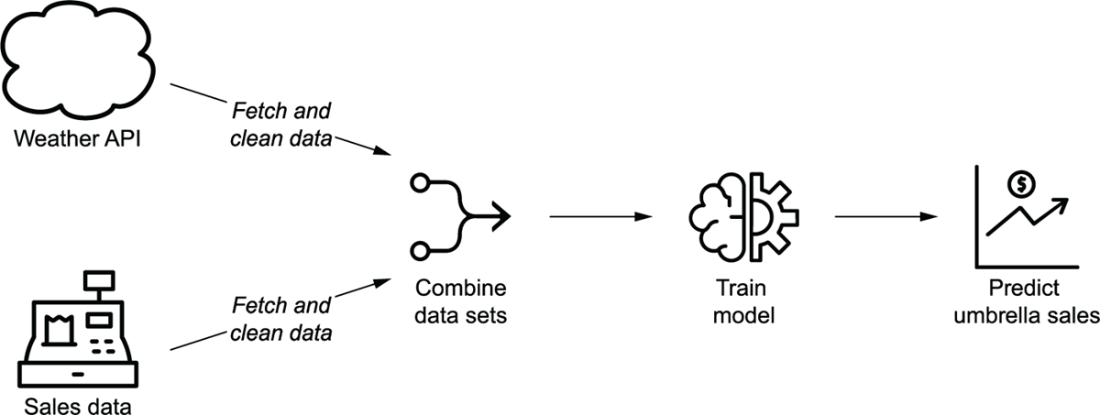
Independence between sales and weather tasks in the graph representation of the data pipeline for the umbrella demand forecast model. The two sets of fetch/cleaning tasks are independent as they involve two different data sets (the weather and sales data sets). This independence is indicated by the lack of edges between the two sets of tasks.

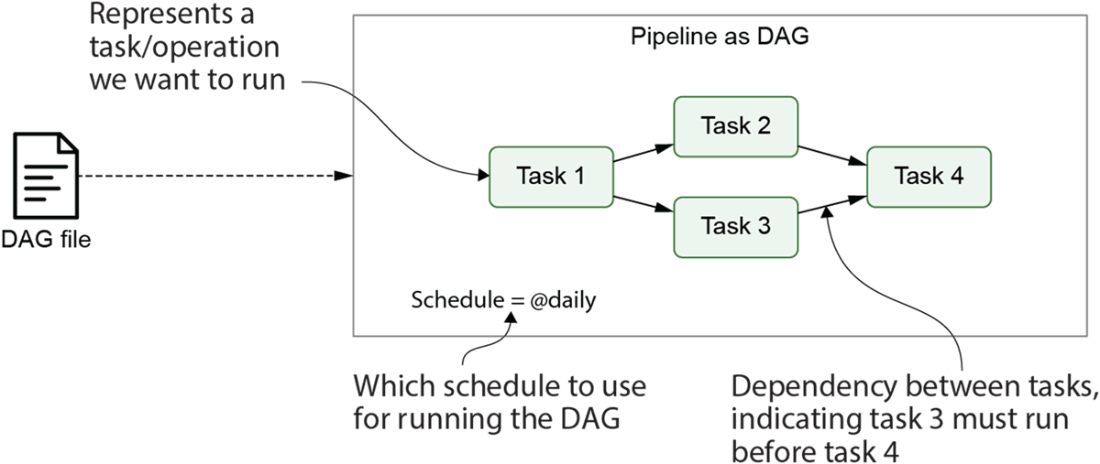
Airflow pipelines are defined as DAGs using Python code in DAG files. Each DAG file typically defines one DAG, which describes the different tasks and their dependencies. Besides this, the DAG also defines a schedule interval that determines when the DAG is executed by Airflow.
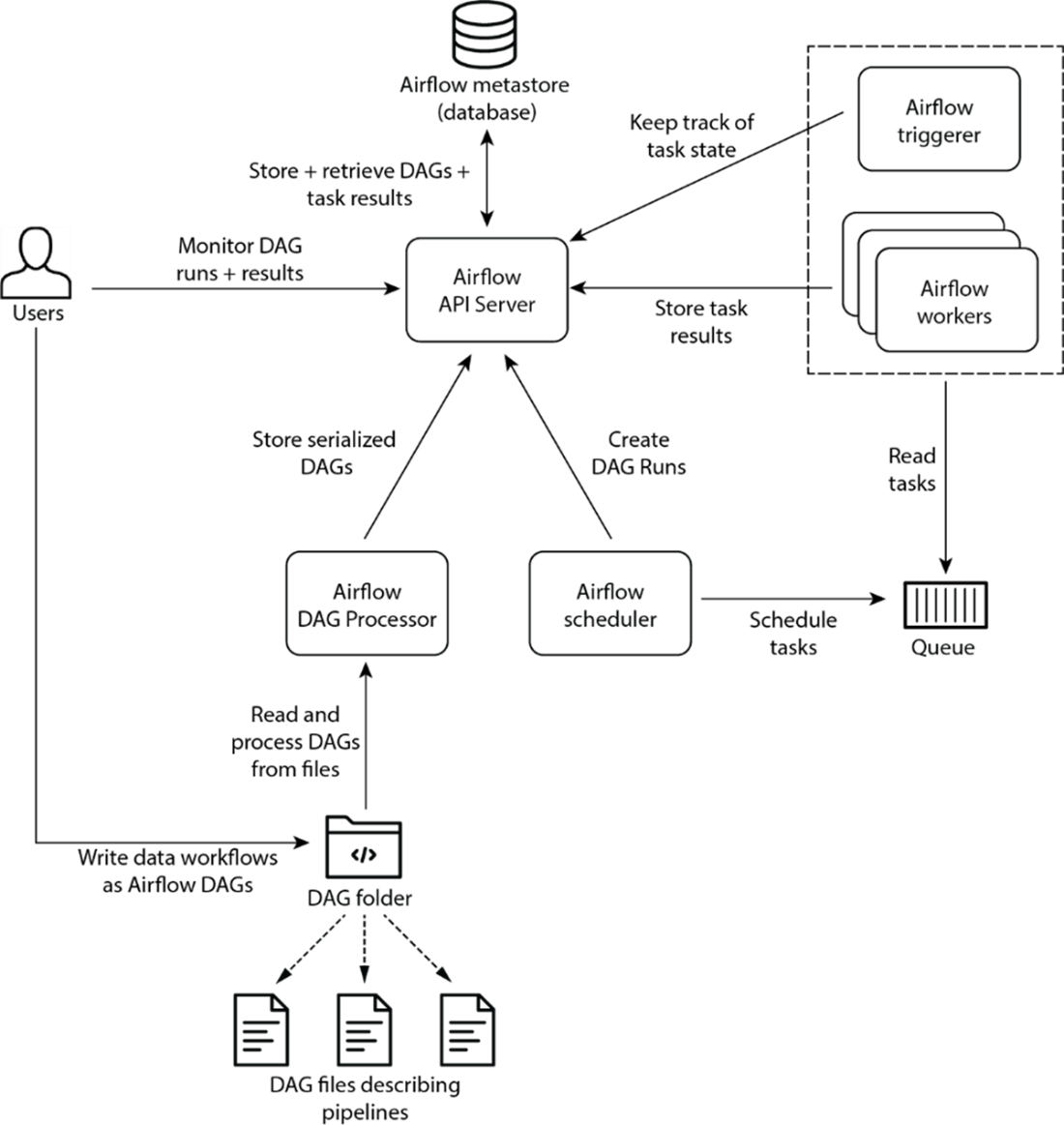
The main components involved in Airflow are the Airflow API server, scheduler, DAG processor, triggerer and workers.
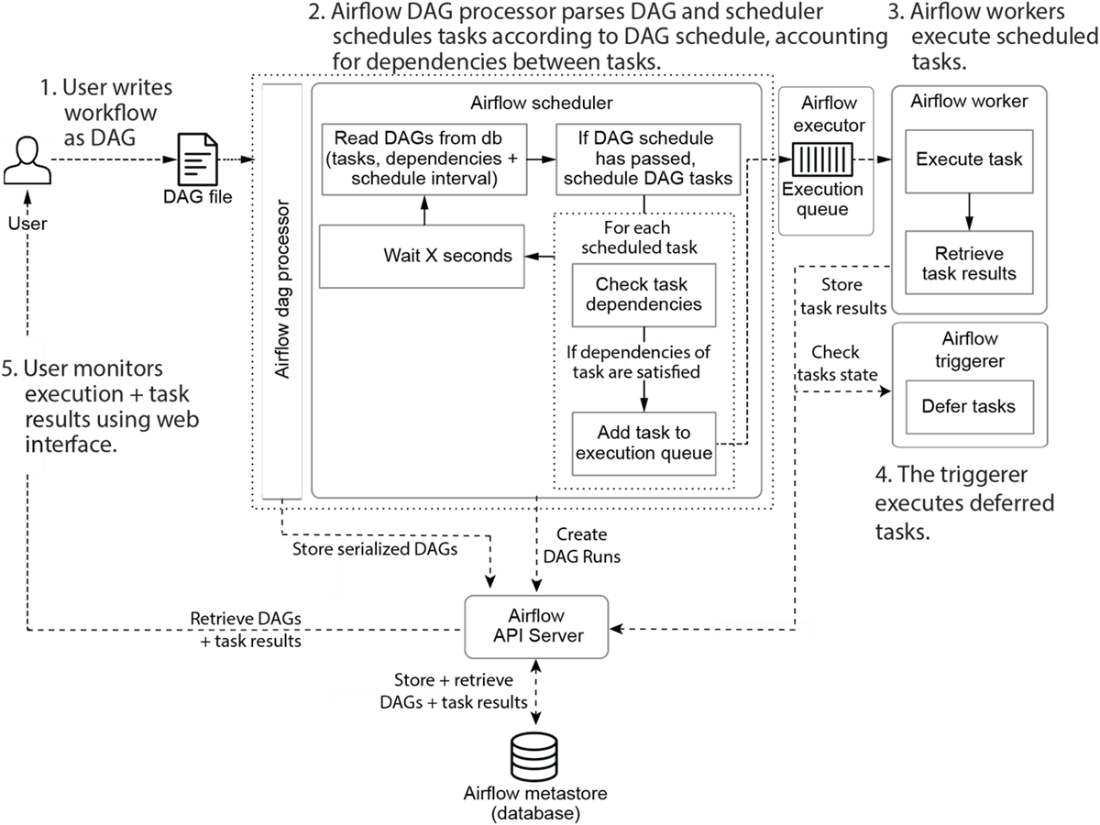
Developing and executing pipelines as DAGs using Airflow. Once the user has written the DAG, the DAG Processor and scheduler ensure that the DAG is run at the right moment. The user can monitor progress and output while the DAG is running at all times.
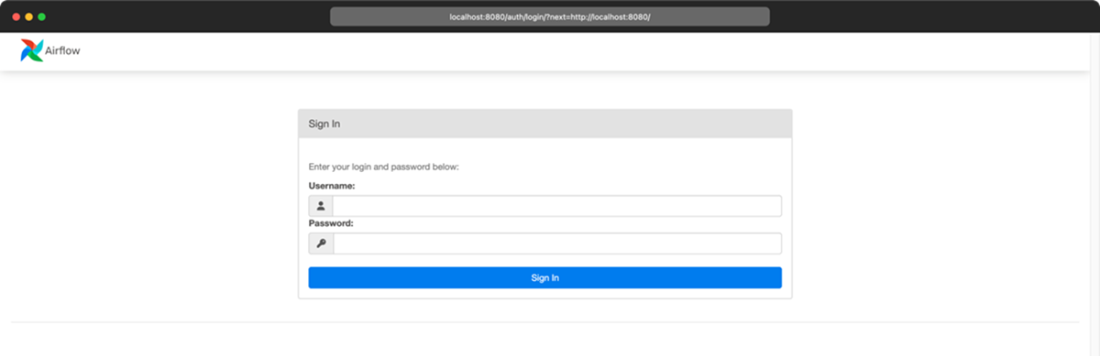
The login page for the Airflow web interface. In the code examples accompanying this book, a default user “airflow” is provided with the password “airflow”.
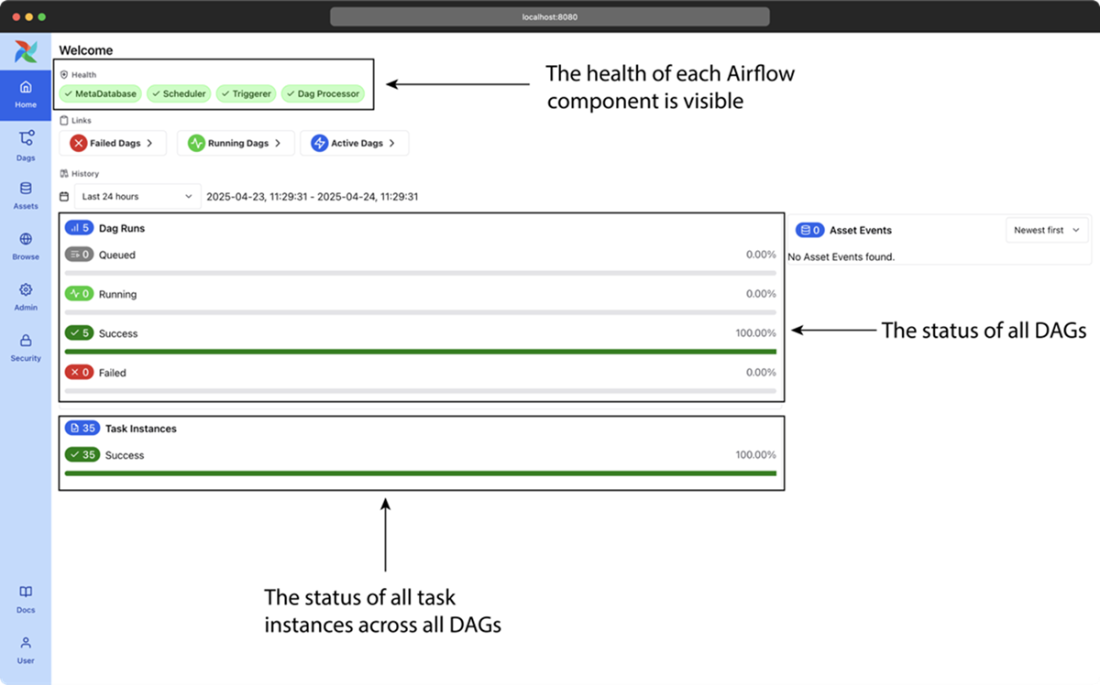
The main page of Airflow’s web interface, showing a high-level overview of all DAGs and their recent results.
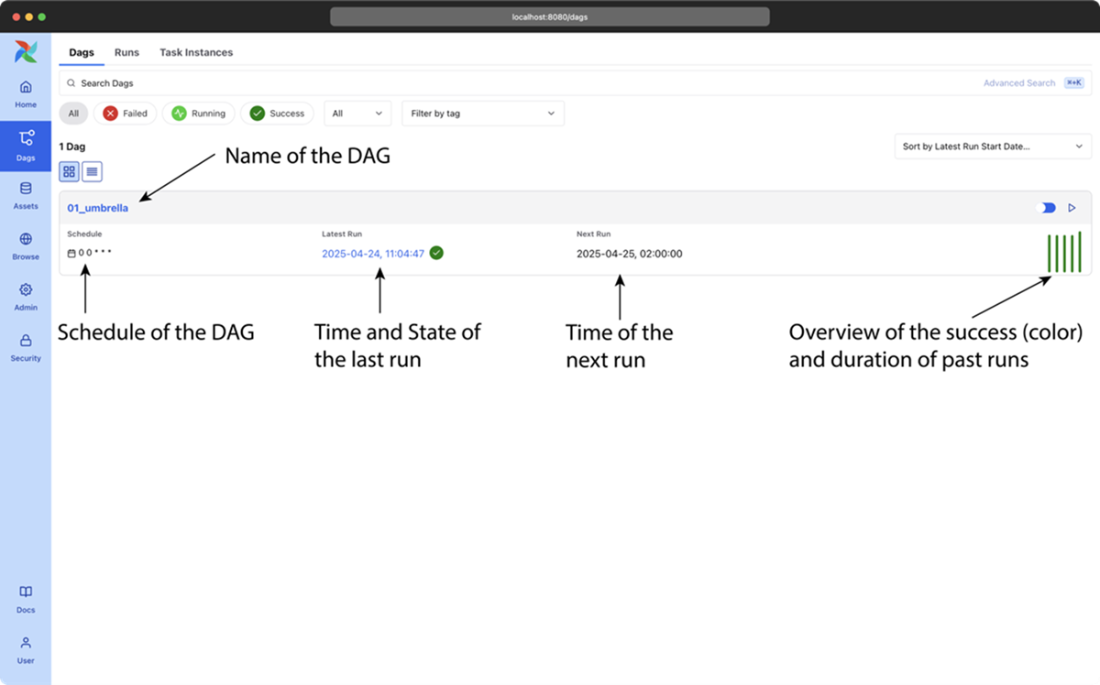
The DAGs page of Airflow’s web interface, showing a high-level overview of all DAGs and their recent results.
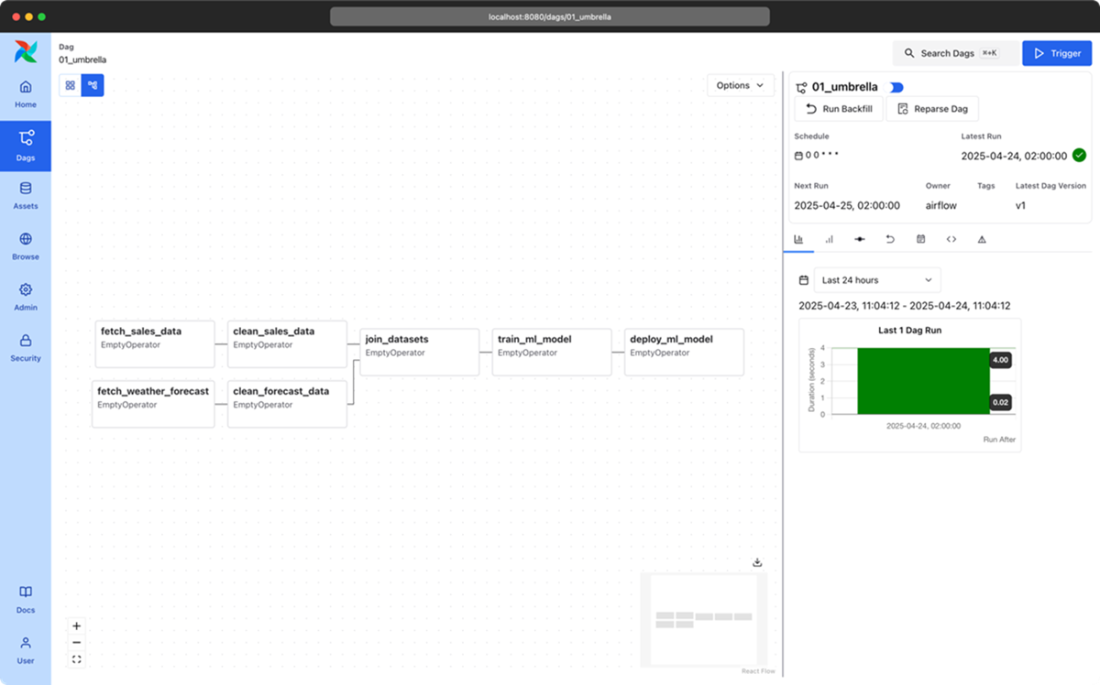
The graph view in Airflow’s web interface, showing an overview of the tasks in an individual DAG and the dependencies between these tasks
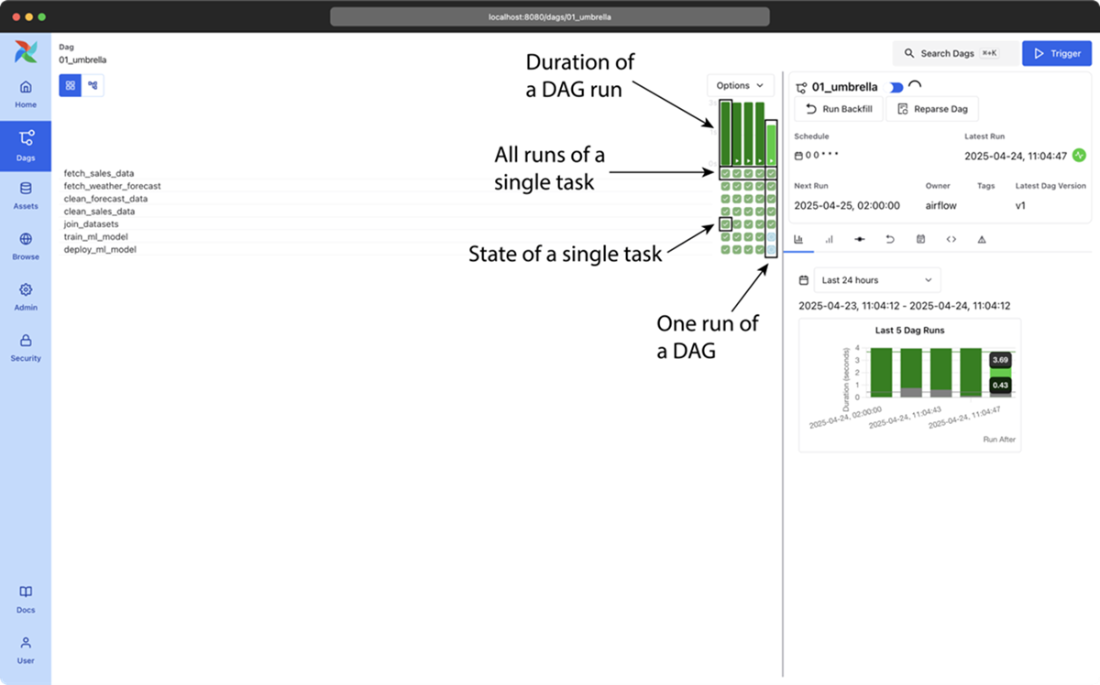
Airflow’s grid view, showing the results of multiple runs of the umbrella sales model DAG (most recent + historical runs). The columns show the status of one execution of the DAG and the rows show the status of all executions of a single task. Colors (which you can see in the e-book version) indicate the result of the corresponding task. Users can also click on the task “squares” for more details about a given task instance, or to manage the state of a task so that it can be rerun by Airflow, if desired.x
Summary
- Directed Acyclic Graphs (DAGs) are a visual tool used to represent data workflows in data processing pipelines. A node in a DAG denote the task to be performed, and edges define the dependencies between them. This is not only visually more understandable but also aids in better representation, easier debugging + rerunning, and making use of parallelism compared to single monolithic scripts.
- In Airflow, DAGs are defined using Python files. Airflow 3.0 introduced the option of using other languages. In this book we will focus on Python. These scripts outline the order of task execution and their interdependencies. Airflow parses these files to construct and understand the DAG's structure, enabling task orchestration and scheduling.
- Although many workflow managers have been developed over the years for executing graphs of tasks, Airflow has several key features that makes it uniquely suited for implementing efficient, batch-oriented data pipelines.
- Airflow excels as a workflow orchestration tool due to its intuitive design, scheduling capabilities, and extensible framework. It provides a rich user interface for monitoring and managing tasks in data processing workflows.
- Airflow is comprised of five key components:
- DAG Processor: Reads and parses the DAGs and stores the resulting serialized version of these DAGs in the Metastore for use by (among others) the scheduler
- Scheduler: Reads the DAGs parsed by the DAG Processor, determines if their schedule intervals have elapsed, and queues their tasks for execution.
- Worker: Execute the tasks assigned to them by the scheduler.
- Triggerer: It handles the execution of deferred tasks, which are waiting for external events or conditions.
- API Server: Among other things, presents a user interface for visualizing and monitoring the DAGs and their execution status. The API Server also acts as the interface between all Airflow components
- Airflow enables the setting of a schedule for each DAG, specifying when the pipeline should be executed. In addition, Airflow’s built-in mechanisms are able to manage task failures, automatically.
- Airflow is well-suited for batch-oriented data pipelines, offering sophisticated scheduling options that enable regular, incremental data processing jobs. On the other hand, Airflow is not the right choice for streaming workloads or for implementing highly dynamic pipelines where DAG structure changes from one day to the other.
 Data Pipelines with Apache Airflow, Second Edition ebook for free
Data Pipelines with Apache Airflow, Second Edition ebook for free