1 Analyzing data with large language models
Large language models are presented as versatile neural networks that can tackle a wide range of data analysis tasks through natural-language instructions rather than task-specific training. The chapter introduces their multimodal capabilities across text, images, audio, video, tables, and graphs, and frames data analysis as either directly processing raw content with the model or indirectly using the model to generate code for specialized tools. It also sets expectations around background knowledge, practical challenges, and the importance of scalability and cost-awareness when moving from toy prompts to real pipelines.
The core usage pattern is prompting: describing the task, providing necessary context and data, specifying the desired output format, and optionally including examples (few-shot) versus relying on instructions alone (zero-shot). For repeatable workflows, prompt templates with placeholders enable programmatic generation of consistent prompts at scale. The chapter contrasts direct analysis (e.g., classifying reviews or answering questions about images by embedding the data in the prompt) with tool-mediated analysis for structured data (e.g., translating natural-language questions into SQL for relational databases or into graph queries). It covers practical interfaces—from web UIs for ad hoc trials to Python libraries for automation and integration with other data processing components.
To control costs and improve reliability, the chapter outlines strategies for model selection, configuration, and prompt engineering. It emphasizes choosing appropriately sized models, understanding token-driven pricing, constraining outputs, and using fine-tuning when it can replace more expensive models for a specific task. It advocates empirically benchmarking models and prompts, and introduces higher-level frameworks that simplify building complex applications, including agent-based approaches that plan multi-step analyses and invoke external tools on demand. Together, these practices enable building robust, efficient, and flexible data analysis systems powered by large language models.
Illustration by GPT-4o, connecting the topics “data analysis” and “large language models”.

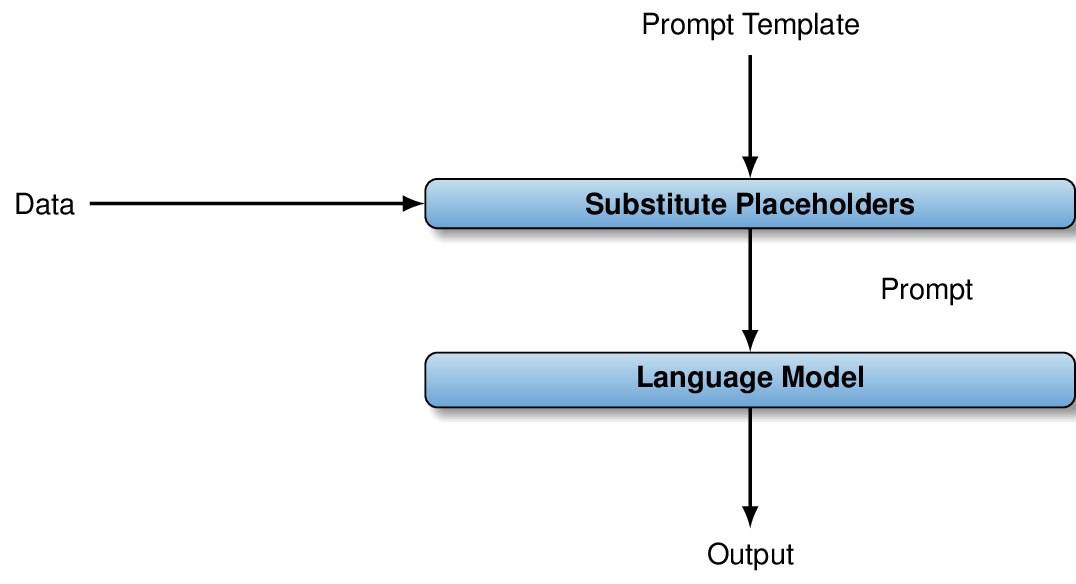
Using language models directly for data analysis: a prompt template describes the analysis task. It contains placeholders that are substituted by data to analyze. After substituting placeholders, the resulting prompt is submitted to the language model to produce output.
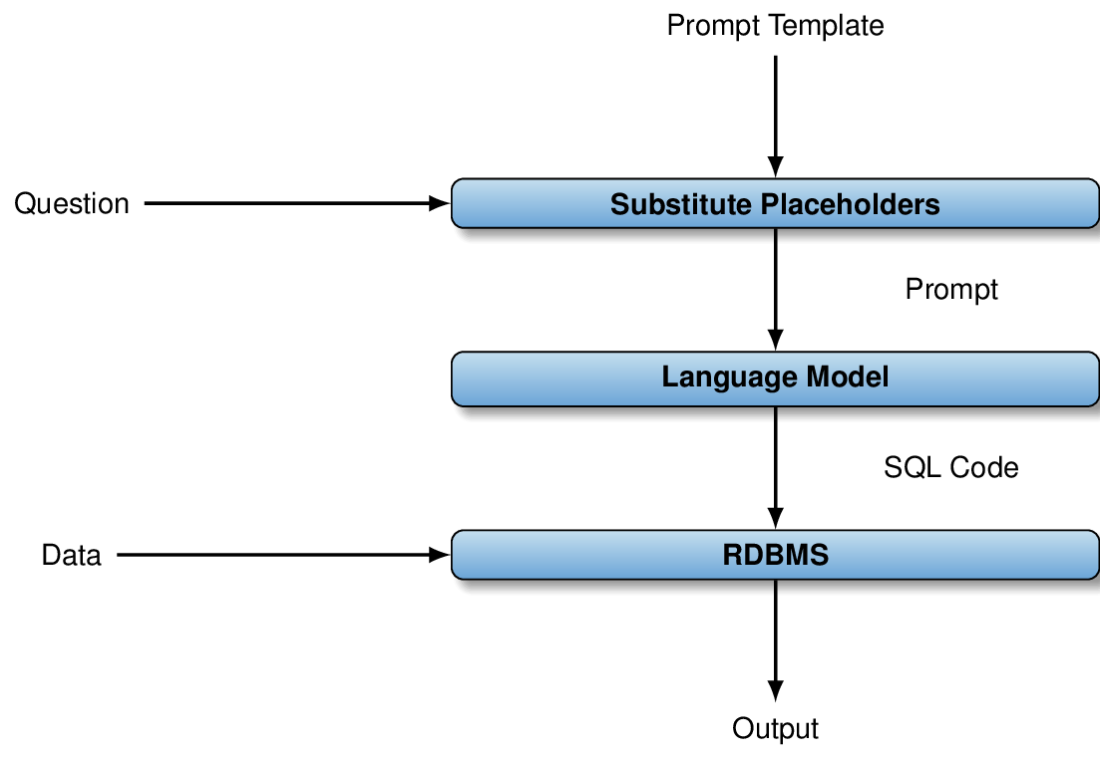
Using language models indirectly to build a natural language interface for tabular data: the prompt template contains placeholders for questions about data. After substituting placeholders, the resulting prompt is used as input for the language model. The model translates the question into an SQL query that is executed via a relational database management system.
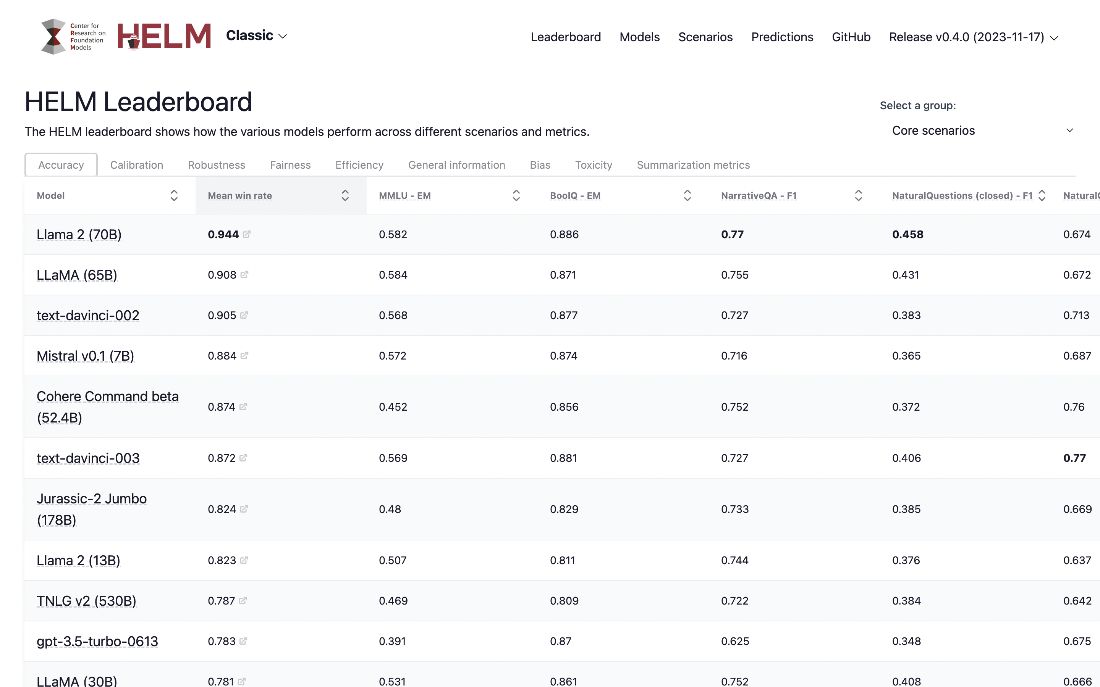
Holistic Evaluation of Language Models (HELM): comparing language models offered by different providers according to various metrics.
PromptBase: a Web site for selling and buying templates for prompts, short text documents used to describe tasks to a language model.
Summary
- Language models can solve novel tasks without specialized training.
- The prompt is the input to the language model.
- Prompts may combine text with other types of data such as images.
- A prompt contains a task description, context, and optionally examples.
- Language models can analyze certain types of data directly.
- When analyzing data directly, the data must appear in the prompt.
- Prompt templates contain placeholders, e.g., to represent data items.
- By substituting placeholders in a prompt template, we obtain a prompt.
- Language models can also help to analyze data via external tools.
- E.g., language models can instruct other tools on how to process data.
- Models are available in many different sizes with significant cost differences.
- Models can be configured using various configuration parameters.
- LangChain and LlamaIndex help to develop complex applications.
- Agents exploit language models to solve complex problems.
 Data Analysis with LLMs ebook for free
Data Analysis with LLMs ebook for free