1 AI Reliability: Building LLMs for the Real World
Modern large language models have moved far beyond simple text generation: they can reason through complex problems, write code, use tools, browse information, and coordinate multi-step workflows. Yet the chapter emphasizes that benchmark performance is not the same as production reliability. Many generative AI pilots fail because systems that look impressive in demos break down under real-world conditions, producing hallucinations, brittle behavior, unsafe actions, poor evaluations, or unclear business value. Reliable AI is defined as systems that produce accurate outputs, act safely, and maintain quality over time in realistic operating environments.
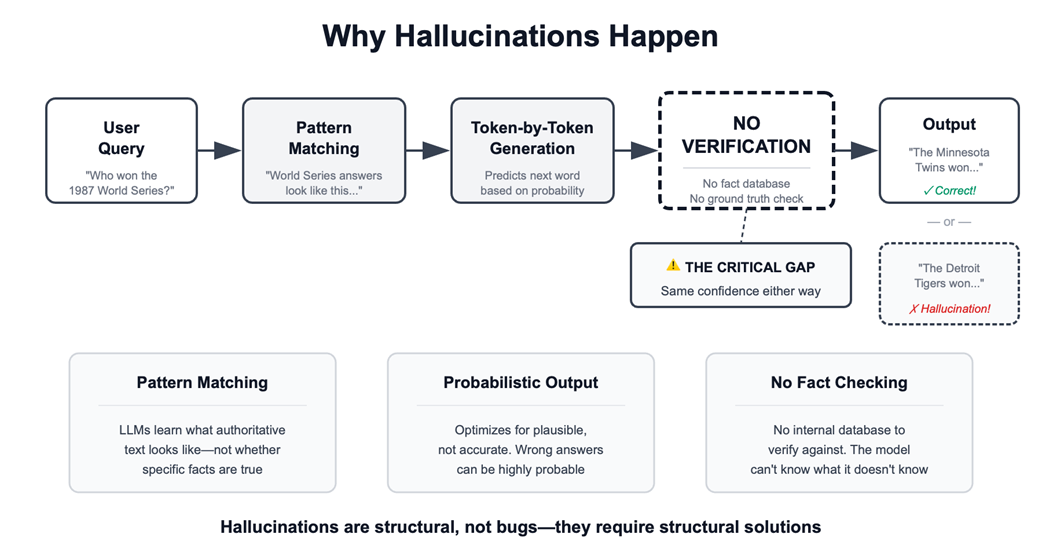
The chapter explains why reliability is now urgent across industries such as law, customer service, software development, and enterprise automation. LLMs can deliver major productivity gains, but they also introduce serious risks: fabricated legal citations, incorrect policy guidance, insecure or buggy code, biased outputs, and autonomous agents that take harmful actions. A central challenge is hallucination, where models generate false or unsupported information with confidence. Because LLMs generate plausible text probabilistically and lack built-in truth verification, reliability requires engineering practices that ground outputs in verified data, detect failures, and ensure human oversight where stakes are high.
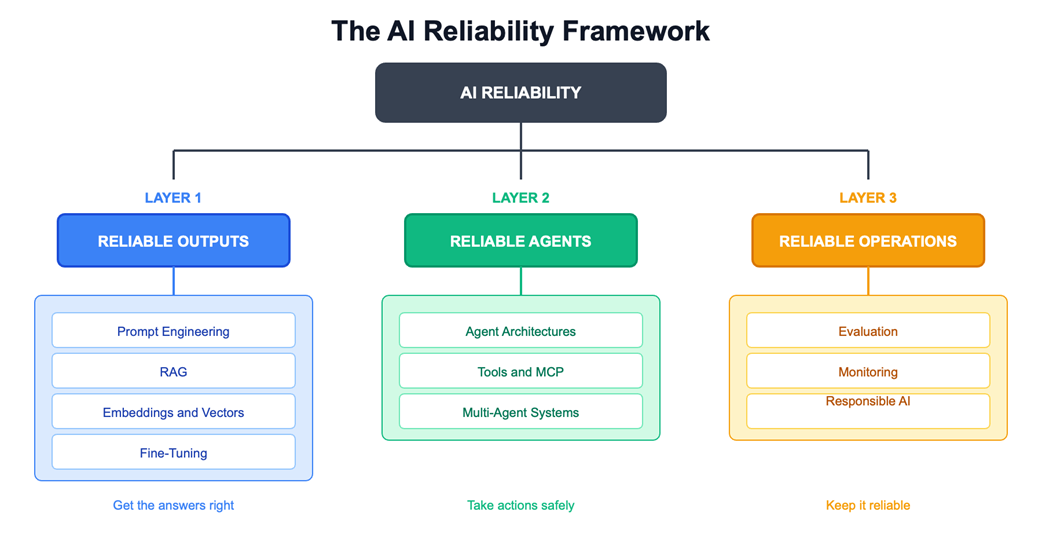
The chapter presents a three-layer framework for building reliable AI systems. The first layer focuses on reliable outputs through prompt engineering, retrieval-augmented generation, embeddings, vector search, fine-tuning, and distillation. The second layer focuses on reliable agents that can reason, plan, use tools, coordinate workflows, and act within safe boundaries using permissions, traceability, reversibility, and failure containment. The third layer focuses on reliable operations, including evaluation, red teaming, monitoring, drift detection, responsible AI, privacy, fairness, and governance. The overall message is to start simple, add complexity only when needed, and build evaluation and monitoring into every production AI system from the beginning.
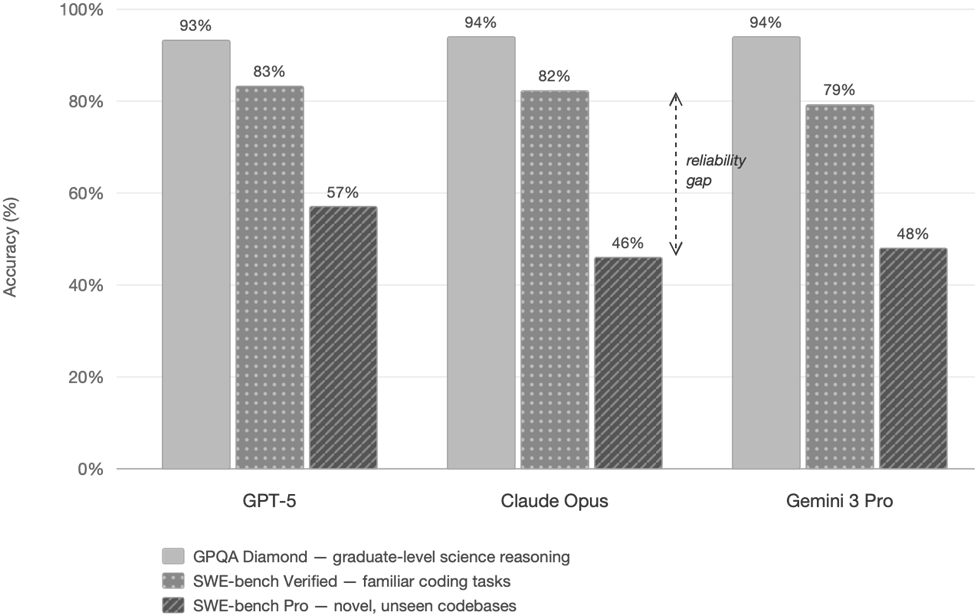
LLM performance across benchmarks: the gap between familiar tests and real-world tasks
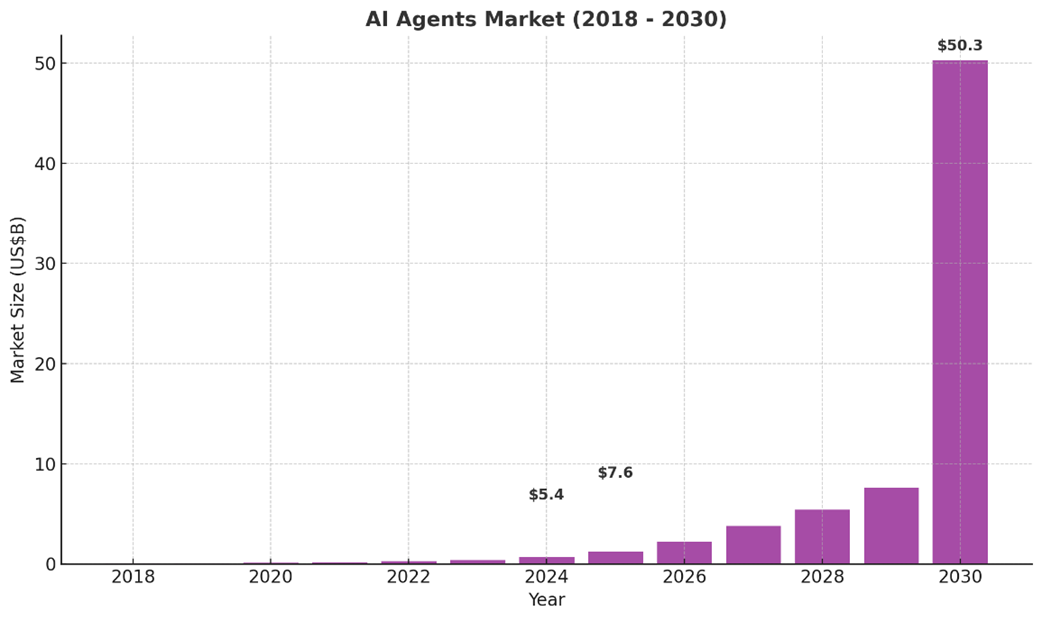
Global AI agents market size by year, 2018-2030 (projected)
Why hallucinations happen from query to fabricated output
The AI Reliability Framework - three layers from outputs to operations
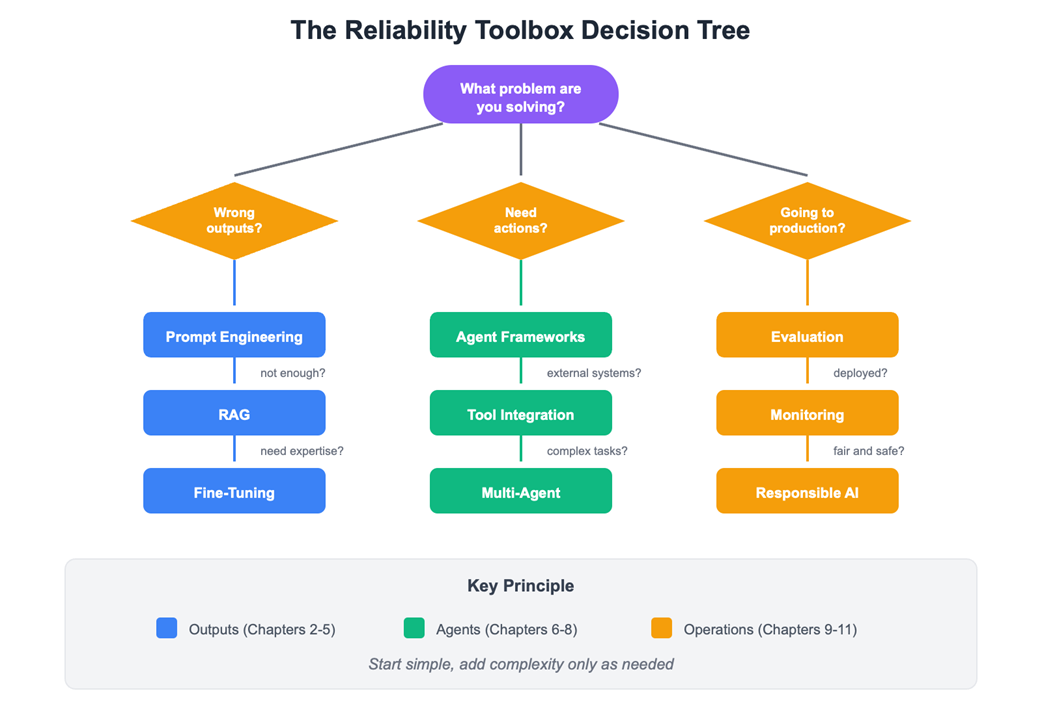
The Reliability Toolbox Decision Tree - choosing the right technique for your AI System
Summary
- LLMs have immense potential to transform industries. Their applications span content creation, customer service, healthcare, and more.
- Agentic AI systems that take real-world actions introduce new categories of risk requiring sophisticated reliability engineering.
- The three-layer framework organizes reliability: reliable outputs (grounded, accurate answers), reliable agents (safe tool use and multi-step workflows), and reliable operations (evaluation, monitoring, and responsible AI).
- Curbing hallucination risks is key to keep outputs honest and grounded in facts.
- Performance optimization ensures LLMs meet speed responsiveness demands, and quality of real-world applications.
- Multi-agent systems require coordination protocols, error handling, and monitoring to prevent cascading failures.
- The reliability toolbox includes prompt engineering, RAG, embeddings, fine-tuning, agent frameworks, tool integration, and evaluation - start simple, add complexity as needed but always build in evaluation and monitoring.
- This book covers promising solutions to these challenges that will enable safely harnessing LLMs to create groundbreaking innovations across healthcare, science, education, entertainment, and more while building vital public trust.
FAQ
What does reliability mean for production AI systems?
Reliability means an AI system produces accurate outputs, takes safe actions, and maintains quality over time under real-world conditions. In this chapter, reliable AI includes factual correctness, consistency, graceful failure, grounding in verified sources, fairness, efficiency, safe agency, and resilience to model updates or data drift.
Why is benchmark performance not the same as production reliability?
Benchmarks measure model capability on controlled tasks, but production systems face unfamiliar inputs, changing data, tool failures, latency constraints, and user expectations. The chapter highlights that models performing strongly on SWE-bench Verified dropped significantly on SWE-bench Pro, showing the gap between familiar benchmark tasks and harder real-world problems.
Why do many generative AI pilots fail to deliver measurable ROI?
Many pilots fail because teams encounter hallucinations, inconsistent outputs, brittle tool integrations, weak evaluations, and poorly defined problems. AI can seem impressive in a demo but fail in production when it must be accurate, safe, monitored, and useful over time.
What is an AI hallucination?
A hallucination occurs when an LLM generates content that is factually incorrect, nonsensical, or unfaithful to source material while presenting it confidently. Hallucinations are especially dangerous because they often look plausible, such as fabricated legal citations or incorrect policy information.
Why do LLMs hallucinate?
LLMs generate text probabilistically, one token at a time, based on learned patterns from large datasets. They optimize for plausible continuations rather than verified truth, and they do not inherently check outputs against ground truth. When information is missing, contradictory, or outside their training data, they may fabricate convincing answers.
What are the three layers of the AI reliability framework?
The chapter organizes AI reliability into three layers: reliable outputs, reliable agents, and reliable operations. Reliable outputs focus on grounded and truthful answers. Reliable agents focus on safe tool use and multi-step workflows. Reliable operations focus on evaluation, monitoring, governance, fairness, privacy, and maintaining quality in production.
What techniques help create reliable AI outputs?
Reliable outputs can be improved through prompt engineering, retrieval-augmented generation, semantic search with embeddings, fine-tuning, knowledge distillation, and quantization. Prompt engineering is usually the first step, while RAG is especially useful when answers must be grounded in documents or verified data.
What makes reliable agents different from reliable outputs?
Reliable outputs are about whether the AI says the right thing. Reliable agents are about whether the AI can safely act, use tools, call APIs, and complete multi-step workflows. Because actions can have real consequences, agents require permissions, reversibility, tool robustness, traceability, and failure containment.
Why are evaluation and monitoring essential for AI systems?
Evaluation and monitoring are necessary because AI quality can degrade after deployment as models update, data drifts, and user behavior changes. Production AI monitoring must track more than uptime and latency; it must also measure semantic quality, hallucination rates, user satisfaction, bias, and safety.
What tools are included in the reliability toolbox?
The chapter’s reliability toolbox includes model selection, prompt engineering, RAG, vector search, fine-tuning, agent frameworks, tool integration through MCP, multi-agent systems, evaluation, and monitoring. The key principle is to start simple, add complexity only when needed, and build evaluation and monitoring from day one.
 Building Reliable AI Systems ebook for free
Building Reliable AI Systems ebook for free