1 What is an AI agent?
The chapter introduces AI agents as systems built around large language models that can decide what to do next, use tools, and repeat that process until a goal is reached. It begins by showing the broad landscape of agents today, including personal assistants, customer-facing support systems, and specialized tools for coding or research. Although these systems look different on the surface, they all depend on LLMs as the core decision-maker, which is why the book treats AI agents and LLM agents as essentially the same idea.
At the heart of an agent is autonomous control flow: instead of following a fixed sequence written entirely by a developer, the model helps determine the next action based on context and progress. The chapter explains that this autonomy comes from combining three parts: an LLM, tools that connect it to the outside world, and a loop that lets it act, observe results, and continue or stop. It also draws a clear distinction between workflows and agents, showing that workflows are developer-defined and predictable, while agents are LLM-directed and flexible. In practice, the two are often mixed, with workflows providing structure and agents handling the parts of a task that require adaptation.
The chapter then focuses on when agents are worth using and how to measure them. It argues that LLMs should only be introduced when tasks involve unstructured data or diverse inputs, and that agents are best reserved for problems that are complex, valuable enough to justify higher cost and latency, and tolerant of occasional errors. To support development, the book uses GAIA as a benchmark for agentic tasks that require research, synthesis, and multi-step reasoning. Finally, it introduces context engineering as the key discipline for making agents work well: instead of just writing prompts, developers must carefully manage what information enters, leaves, and stays in the model’s context, since the quality of that context often determines whether the agent succeeds or fails.
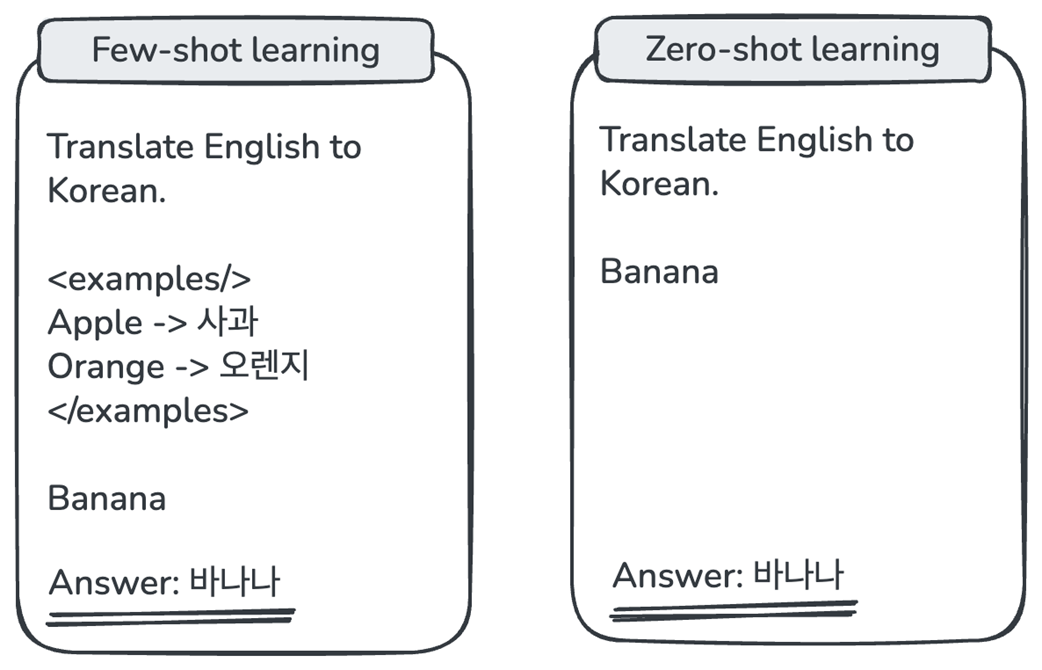
Example of a language model’s generalization capability.
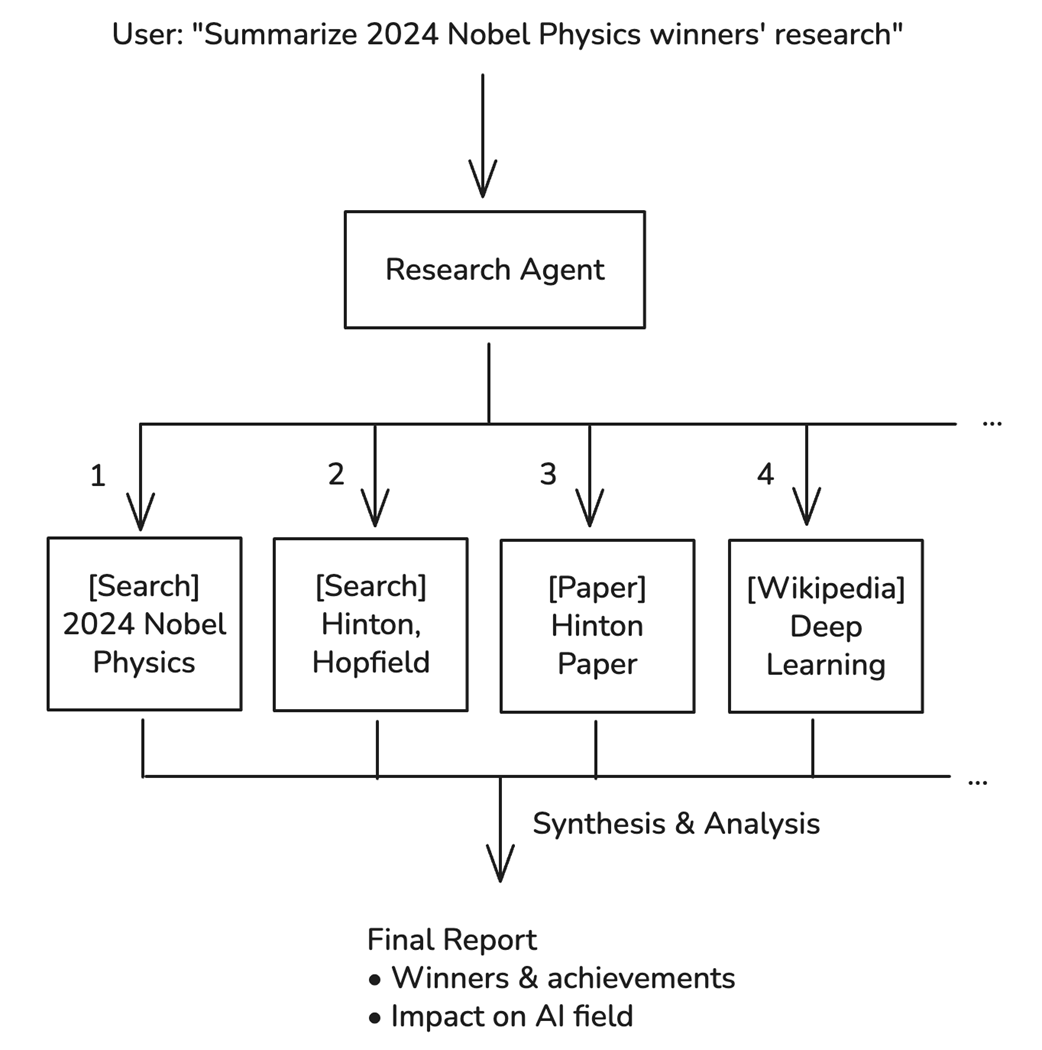
User requests flow through the research agent, which branches into multiple searches and synthesis.
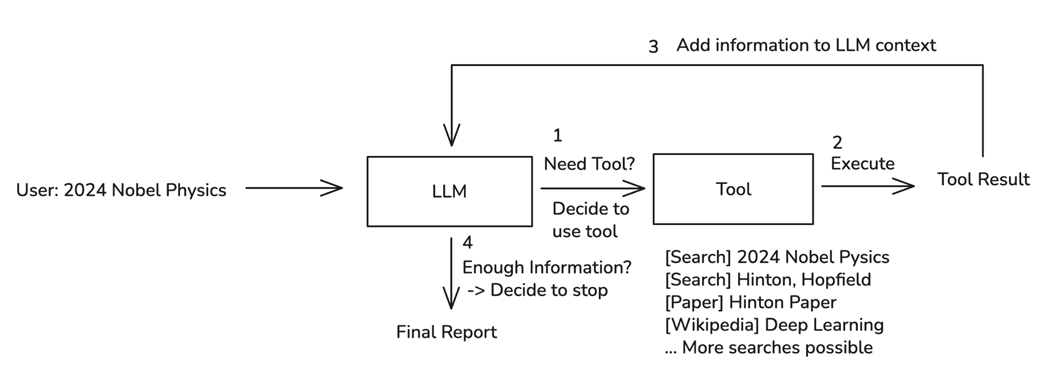
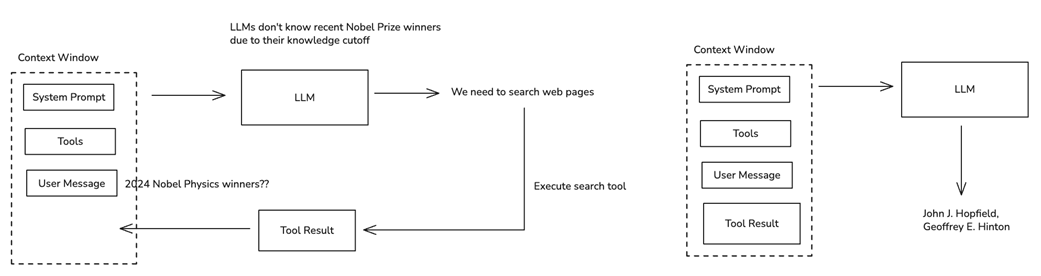
The LLM Agent's decision loop is an iterative process of LLM decision-making and tool use.
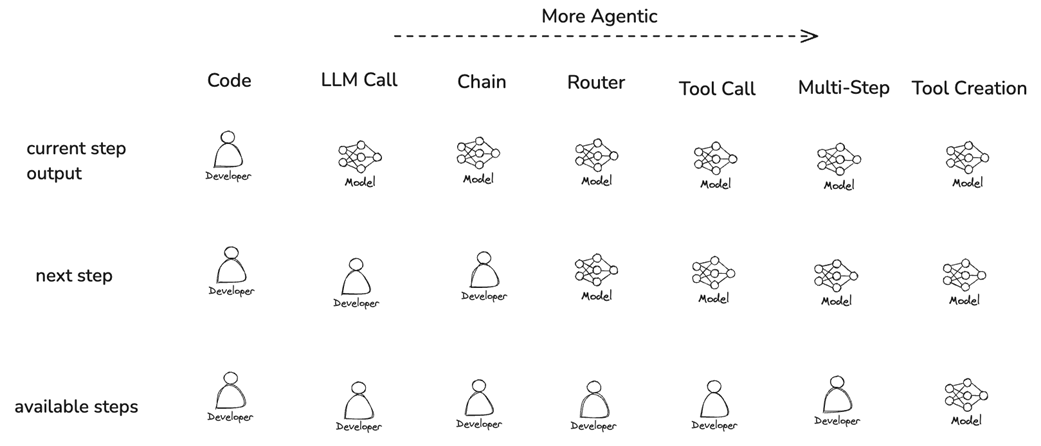
Progression of agency levels in LLM applications.
LLMs can only produce accurate, high-quality responses when sufficient information is provided in the context.
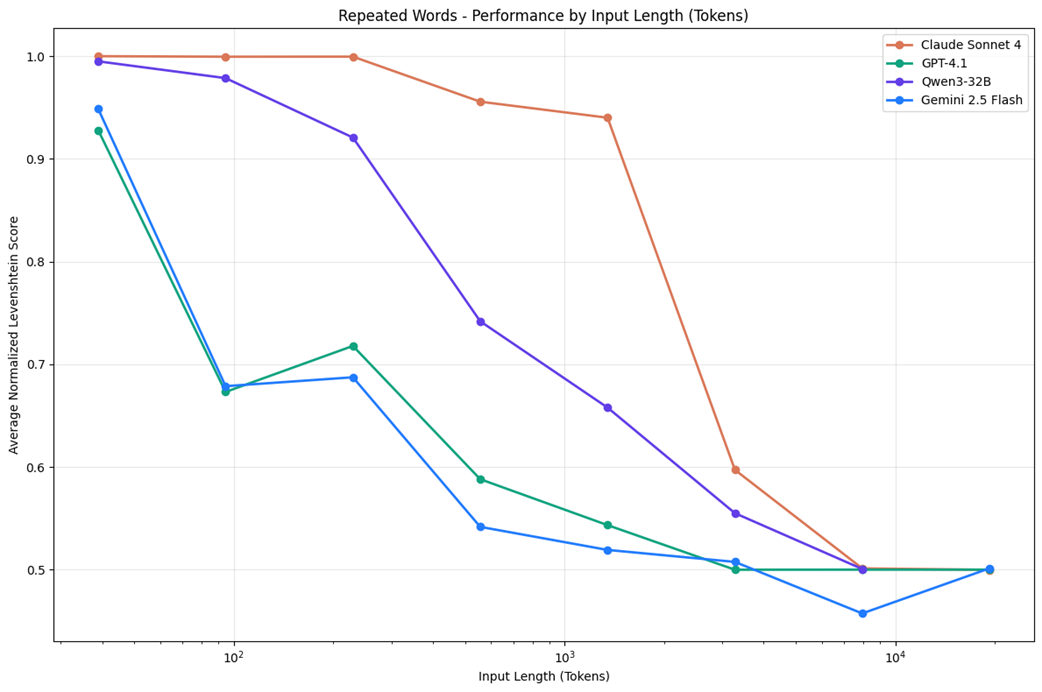
Even with large context windows, longer inputs can degrade model performance(Source: https://research.trychroma.com/context-rot).
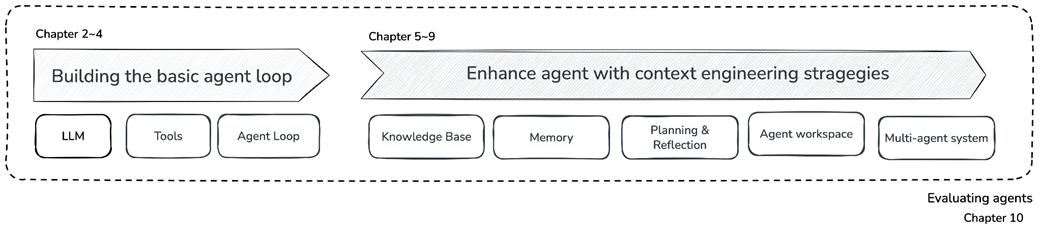
An overview of the journey through the book.
Summary
- AI agents span a wide spectrum, from personal assistants like ChatGPT and Claude to customer-facing agents and specialized tools like Claude Code and Cursor. All share a common foundation: LLMs as their decision-making core.
- An LLM agent consists of three elements: the LLM (brain), tools (means of interacting with the external world), and a loop (iterative process until goal completion). The LLM decides which tool to use and when to stop.
- Workflows are developer-defined execution flows where LLMs perform specific steps. Agents are LLM-directed flows where the model dynamically determines its own process. Production systems often combine both approaches.
- Use agents when tasks require multiple unpredictable steps, provide sufficient value to justify costs, and allow for error detection. The GAIA benchmark provides ideal practice problems for agent development.
- Context engineering is the discipline of providing the right information at the right time. Five strategies (Generation, Retrieval, Write, Reduce, Isolate) form the framework for building effective agents throughout this book.
 Build an AI Agent (From Scratch) ebook for free
Build an AI Agent (From Scratch) ebook for free