1 Understanding reasoning models
This chapter introduces reasoning models as the next stage in large language model development, where the goal is to move beyond short pattern-based answers toward responses that include intermediate problem-solving steps. In this practical engineering sense, “reasoning” means that an LLM spends tokens on step-by-step work before producing a final answer, whether those steps are visible to users or hidden internally. These reasoning behaviors are especially useful for complex tasks such as math, coding, logical puzzles, planning, tool use, and agent workflows, but they do not mean that LLMs reason like humans or follow deterministic logical rules.
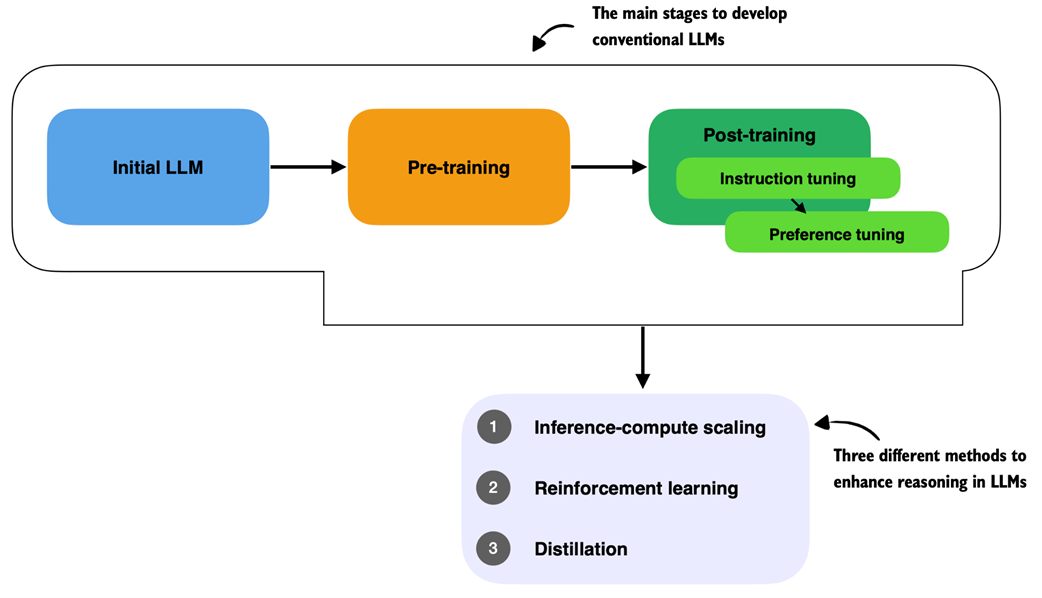
The chapter reviews the standard LLM training pipeline to explain where reasoning methods fit. Conventional LLMs are first pre-trained on massive text datasets through next-token prediction, which gives them fluency and broad capabilities through learned statistical patterns. They are then post-trained with instruction tuning and preference tuning so they can better follow user requests and produce responses aligned with human preferences. Reasoning improvements are usually added after these stages through three broad approaches: inference-time compute scaling, which improves performance without changing model weights; reinforcement learning, which trains models using reward signals such as verified correctness; and distillation, which transfers reasoning behavior from stronger models into smaller or more efficient ones.
A central distinction in the chapter is the difference between pattern matching and logical reasoning. LLMs can appear to reason because they have learned many reasoning-like patterns from data, but they do not explicitly apply formal rules or guarantee logical consistency like symbolic systems. This means they may handle familiar contradictions well while struggling with novel or highly complex reasoning tasks. The chapter argues that building reasoning methods from scratch is valuable because it reveals how these systems work, how to evaluate them, and when their added cost and latency are justified. It also lays out the book’s roadmap: start with a conventional LLM, build evaluation tools, improve reasoning at inference time, and then use training methods to develop a more dedicated reasoning model.
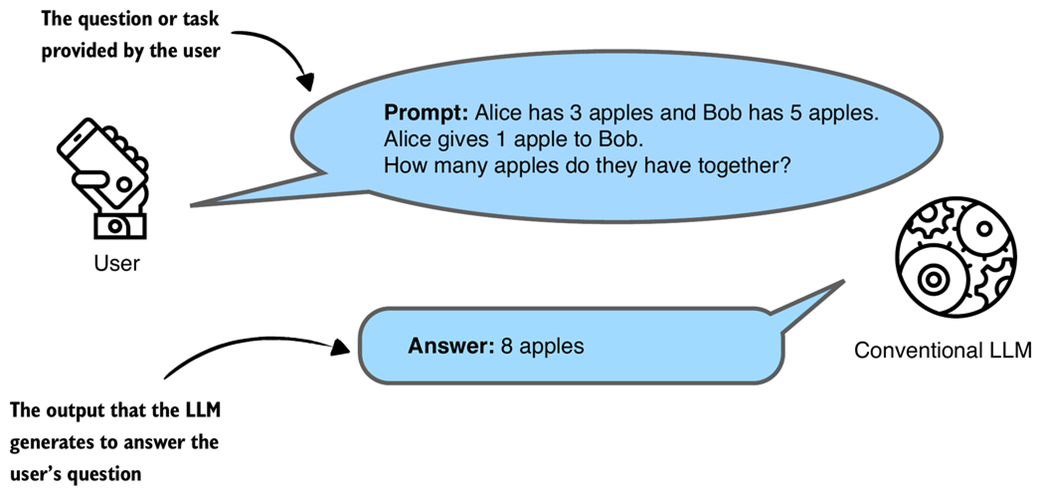
A simplified illustration of how a conventional, non-reasoning LLM might respond to a question with a short answer.
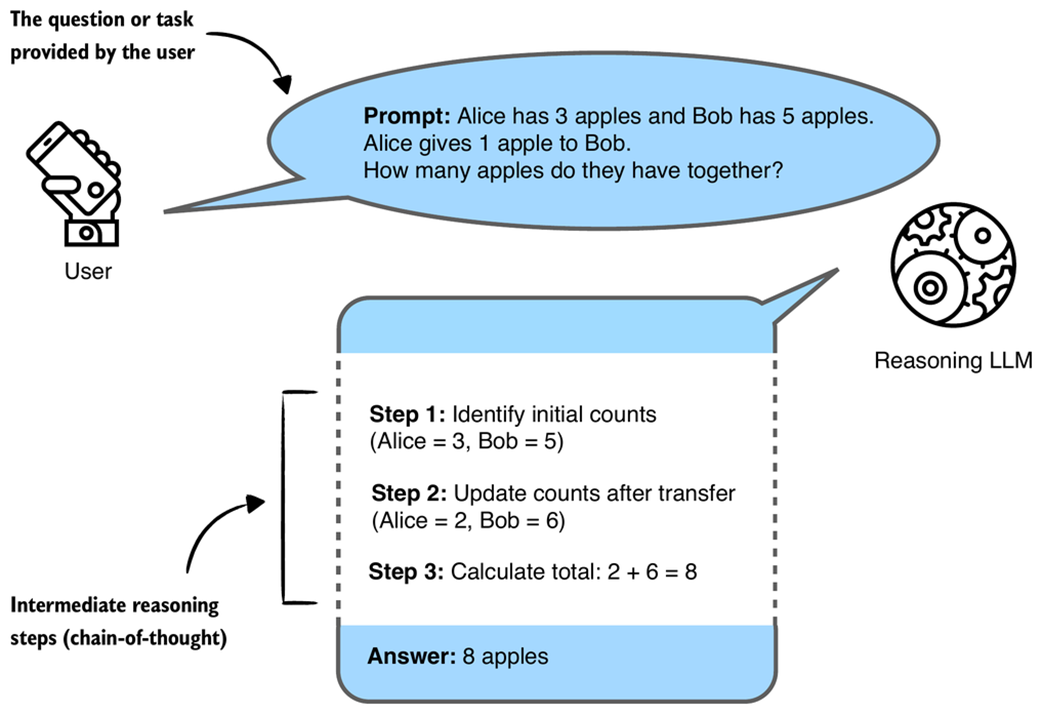
A simplified illustration of how a reasoning LLM might tackle a multi-step reasoning task using a chain-of-thought. Rather than just recalling a fact, the model combines several intermediate reasoning steps to arrive at the correct conclusion. The intermediate reasoning steps may or may not be shown to the user, depending on the implementation.
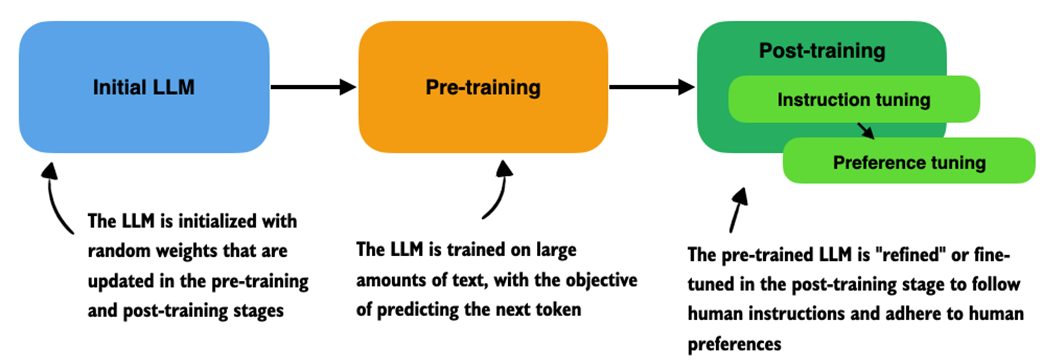
Overview of a typical LLM training pipeline. The process begins with an initial model initialized with random weights, followed by pre-training on large-scale text data to learn language patterns by predicting the next token. Post-training then refines the model through instruction fine-tuning and preference fine-tuning, which enables the LLM to follow human instructions better and align with human preferences.
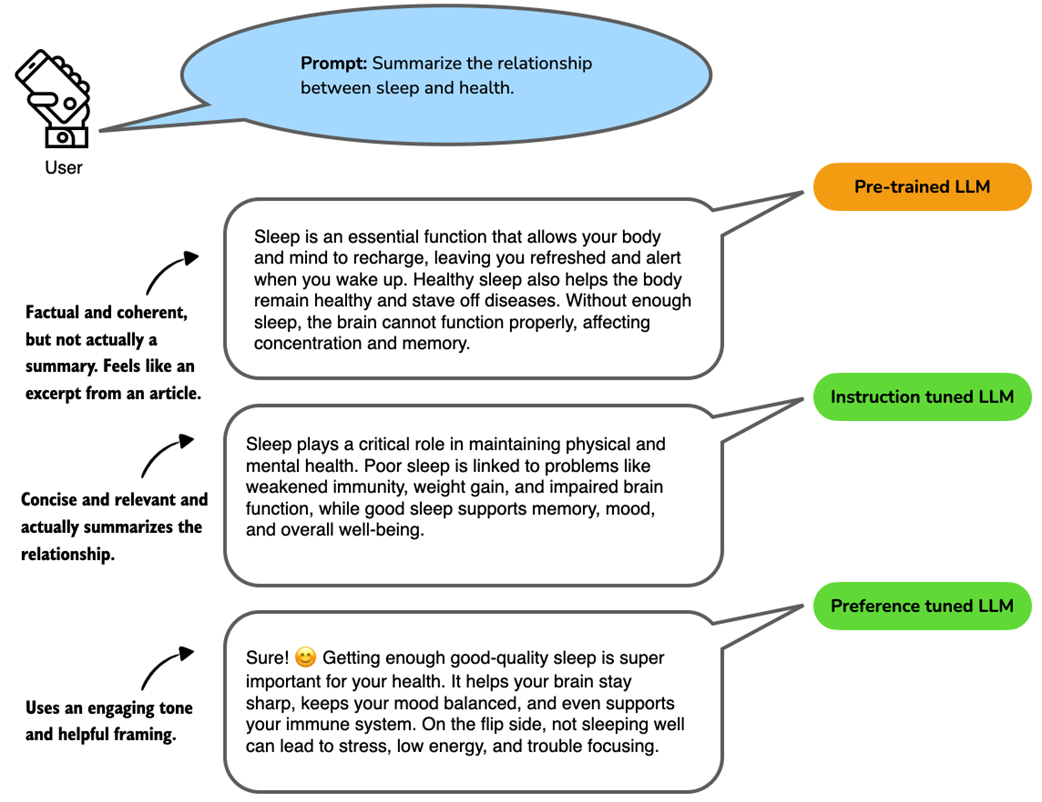
Example responses from a language model at different training stages. The prompt asks for a summary of the relationship between sleep and health. The pre-trained LLM produces a relevant but unfocused answer without directly following the instructions. The instruction-tuned LLM generates a concise and accurate summary aligned with the prompt. The preference-tuned LLM further improves the response by using a friendly tone and engaging language, which makes the answer more relatable and user-centered.
Three approaches commonly used to improve reasoning capabilities in LLMs. These methods (inference-compute scaling, reinforcement learning, and distillation) are typically applied after the conventional training stages (initial model training, pre-training, and post-training with instruction and preference tuning), but reasoning techniques can also be applied to the pre-trained base model.
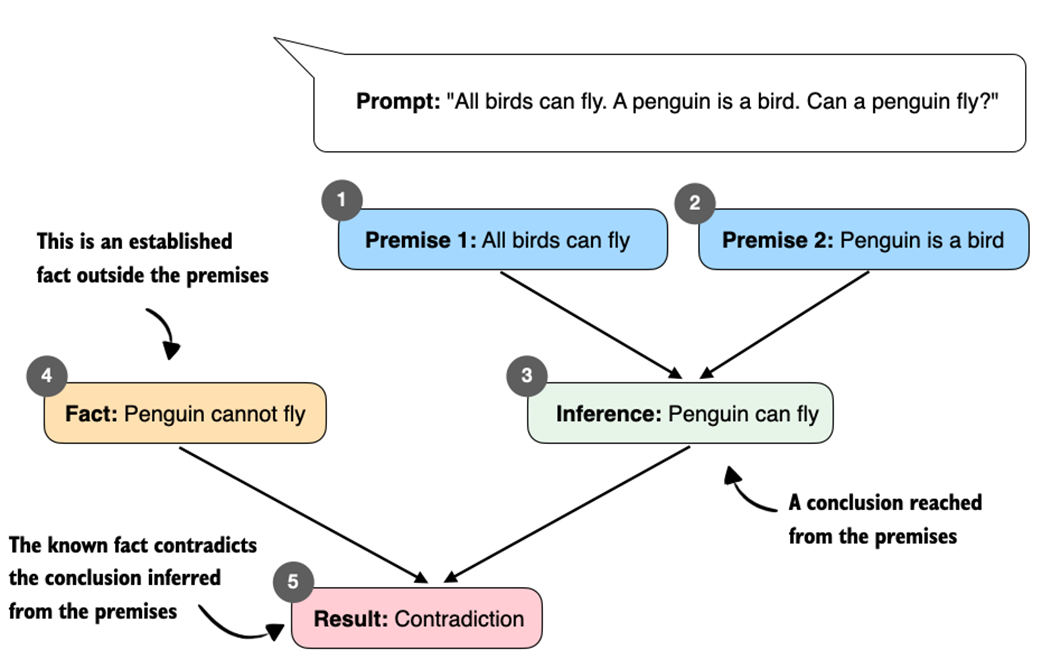
Contradictory premises lead to a logical inconsistency. From "All birds can fly" and "A penguin is a bird," we infer "Penguin can fly." This conclusion conflicts with the established fact "Penguin cannot fly," which results in a contradiction.
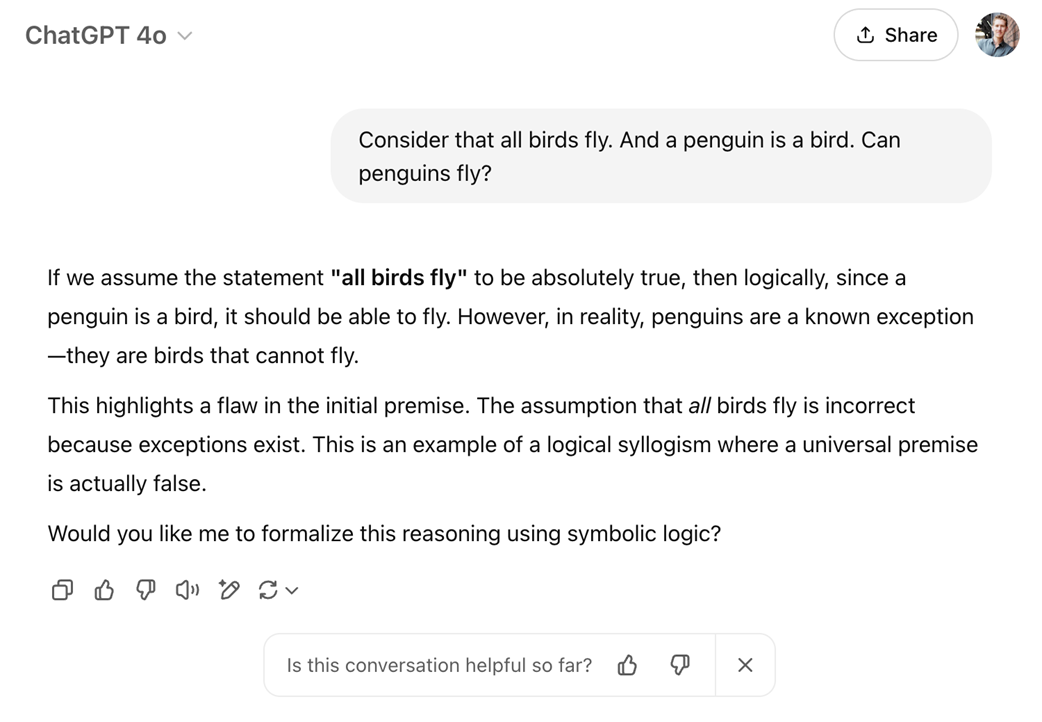
An illustrative example of how a language model (GPT-4o in ChatGPT) appears to "reason" about a contradictory premise.
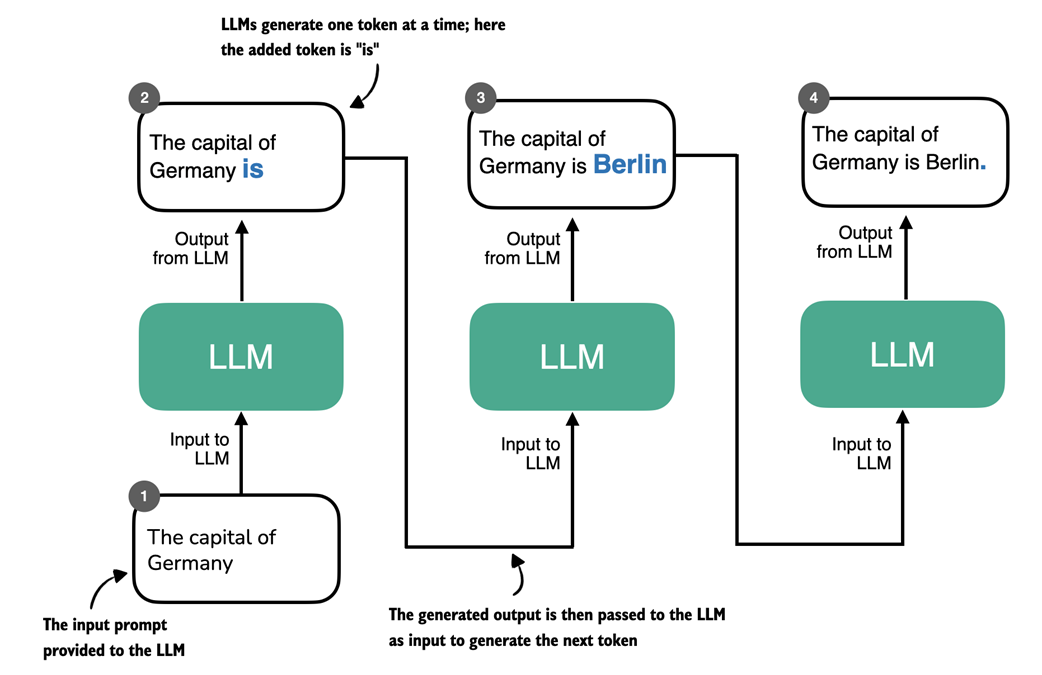
Token-by-token generation in an LLM. At each step, the LLM takes the full sequence generated so far and predicts the next token, which may represent a word, subword, or punctuation mark depending on the tokenizer. The newly generated token is appended to the sequence and used as input for the next step. This iterative decoding process is used in both standard language models and reasoning-focused models.
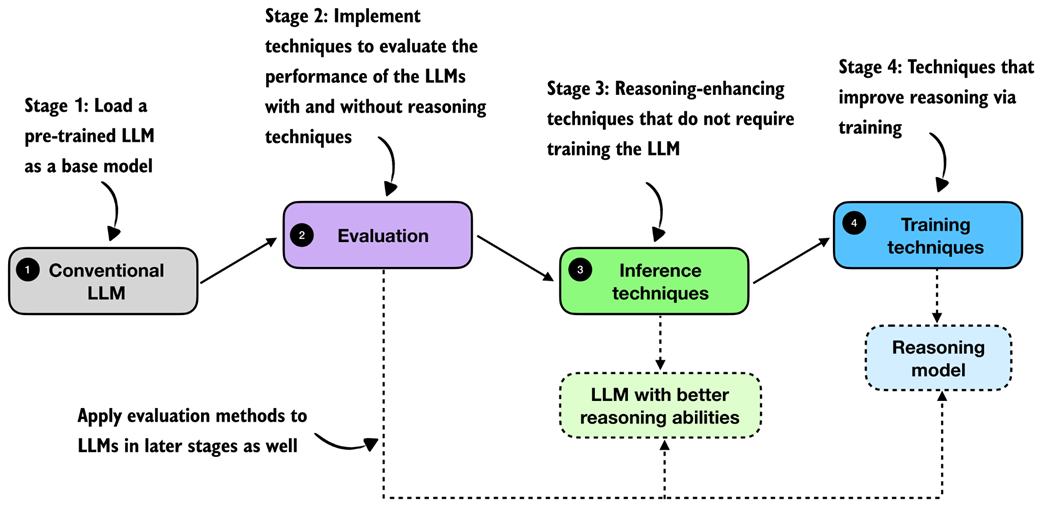
A high-level roadmap of what we build in this book. We start with a conventional LLM, add evaluation methods so that we can measure progress, and then explore two broad families of reasoning improvements, namely, inference techniques and training techniques.
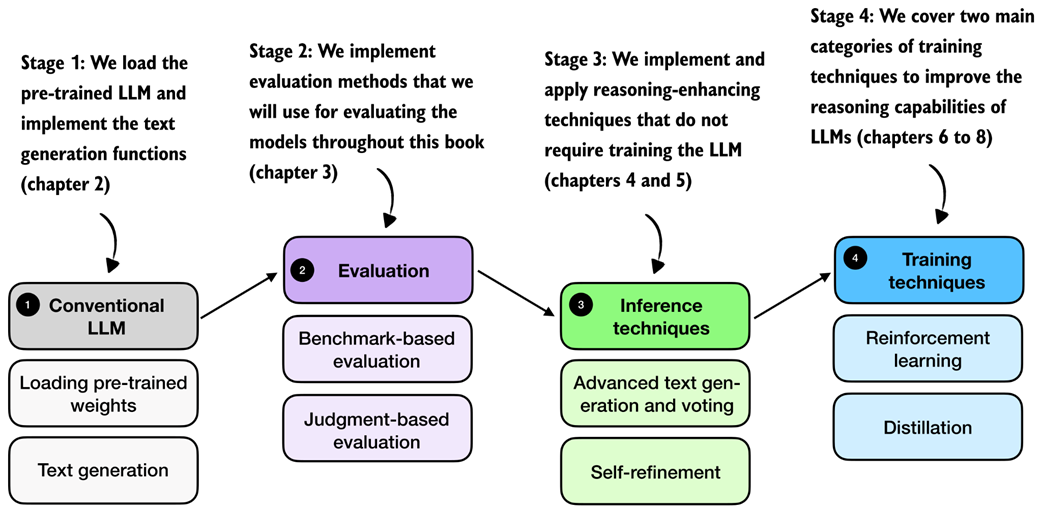
A detailed roadmap of the chapter-level substeps. After loading the base model, we cover benchmark-based and judgment-based evaluation, then inference-time methods such as advanced text generation and voting plus self-refinement, and finally training-time methods based on reinforcement learning and distillation.
Summary
- Conventional LLM training occurs in several stages:
- Pre-training, where the model learns language patterns from vast amounts of text.
- Instruction fine-tuning, which improves the model's responses to user prompts.
- Preference tuning, which aligns model outputs with human preferences.
- Reasoning methods are applied on top of a conventional LLM.
- Reasoning in LLMs refers to improving a model so that it explicitly generates intermediate steps (chain-of-thought) before producing a final answer, which often increases accuracy on multi-step tasks.
- Reasoning in LLMs is different from rule-based reasoning and it also likely works differently than human reasoning; currently, the common consensus is that reasoning in LLMs relies on statistical pattern matching.
- Pattern matching in LLMs relies purely on statistical associations learned from data, which enables fluent text generation but lacks explicit logical inference.
- Improving reasoning in LLMs can be achieved through:
- Inference-time compute scaling, enhancing reasoning without retraining (e.g., chain-of-thought prompting).
- Reinforcement learning, training models explicitly with reward signals.
- Supervised fine-tuning and distillation, using examples from stronger reasoning models.
- Building reasoning models from scratch provides practical insights into LLM capabilities, limitations, and computational trade-offs.
 Build a Reasoning Model (From Scratch) ebook for free
Build a Reasoning Model (From Scratch) ebook for free