1 Introduction to DeepSeek
This chapter introduces the book’s central idea: that DeepSeek is not just another large language model, but a milestone showing that open-source AI can compete with the strongest proprietary systems. It frames the book as a hands-on journey for technically curious readers who want to understand how modern models work by rebuilding key ideas from the ground up, combining theory with code rather than treating the model as a black box.
At a high level, the chapter explains why DeepSeek matters in the history of AI. It highlights how the model and its research reports helped narrow the gap between open and closed models, especially with DeepSeek-R1’s strong reasoning performance and relatively low training cost. The chapter also emphasizes that DeepSeek’s impact comes from more than released weights: its unusually detailed documentation of data, training, and post-training methods makes the system much more reproducible and educational for learners and researchers.
The rest of the chapter gives a roadmap of what will be built across the book. Readers will work through the main architectural changes, including Multi-Head Latent Attention and Mixture-of-Experts, then move into training innovations such as Multi-Token Prediction, FP8 quantization, and efficient pipeline scheduling, before ending with post-training methods like supervised fine-tuning, reinforcement learning, distillation, and compression. The chapter also sets expectations by noting that the book focuses on a scaled-down, reproducible DeepSeek-style model that can run on ordinary hardware, and that readers need only basic Python, PyTorch, and introductory deep learning knowledge to follow along.
A simple interaction with the DeepSeek chat interface.

The title and abstract of the DeepSeek-R1 research paper.

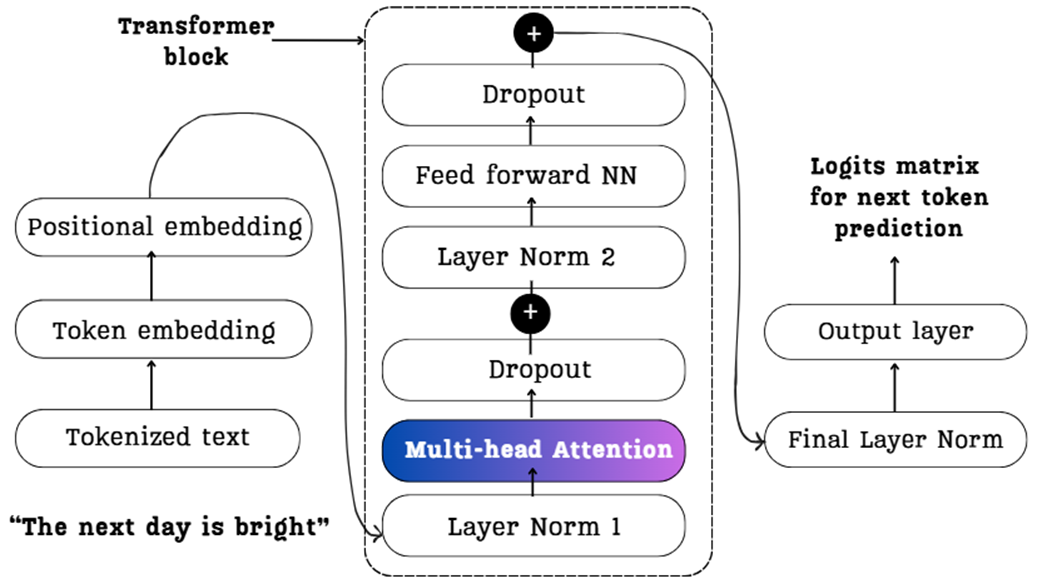
A detailed view of a standard Transformer block, the foundational architecture used in models like LLaMA and the GPT series. It is composed of a multi-head attention block and a feed-forward network (NN).
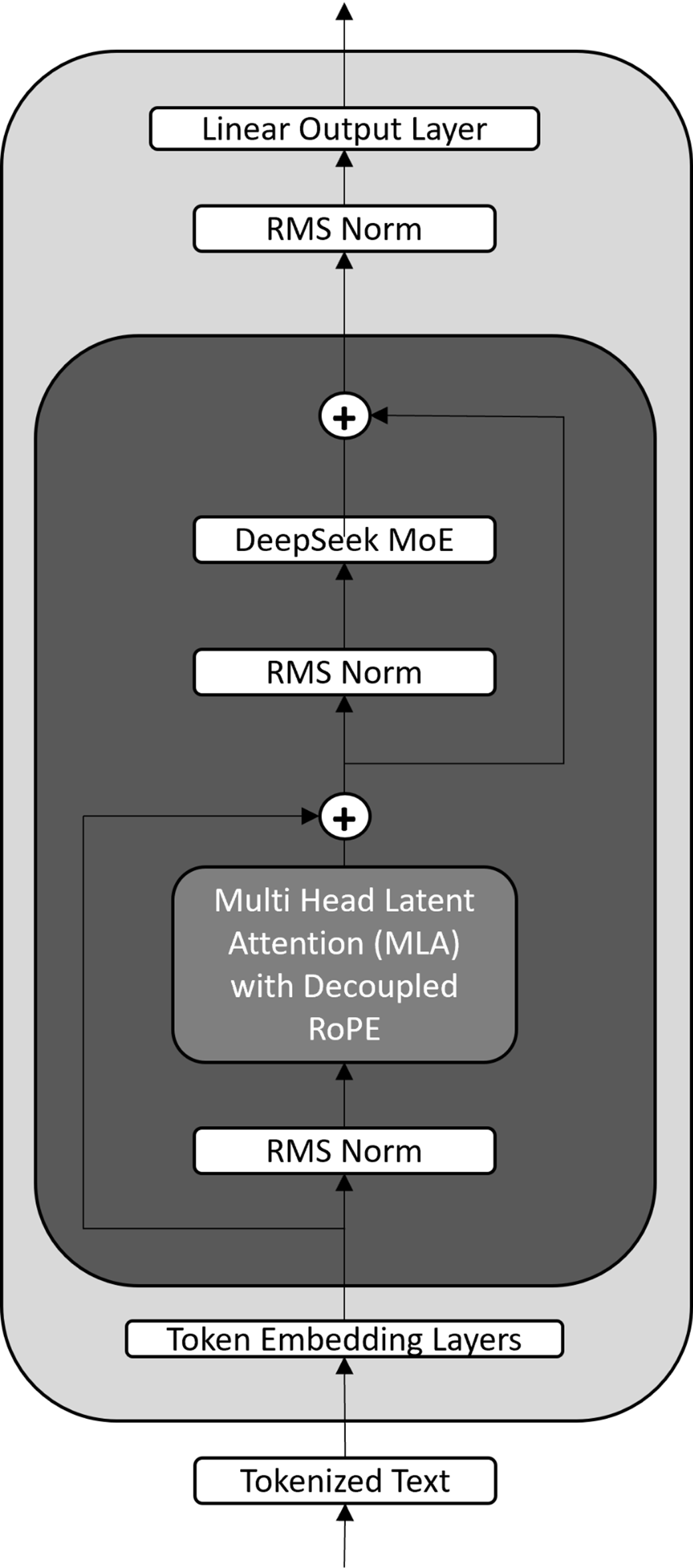
A simplified view of the DeepSeek model architecture. It modifies the standard Transformer by replacing the core components with Multi-Head Latent Attention (MLA) and a Mixture-of-Experts (MoE) layer. This design also utilizes RMS Norm (Root Mean Square Normalization) and a specialized Decoupled RoPE (Rotary Position Embedding).
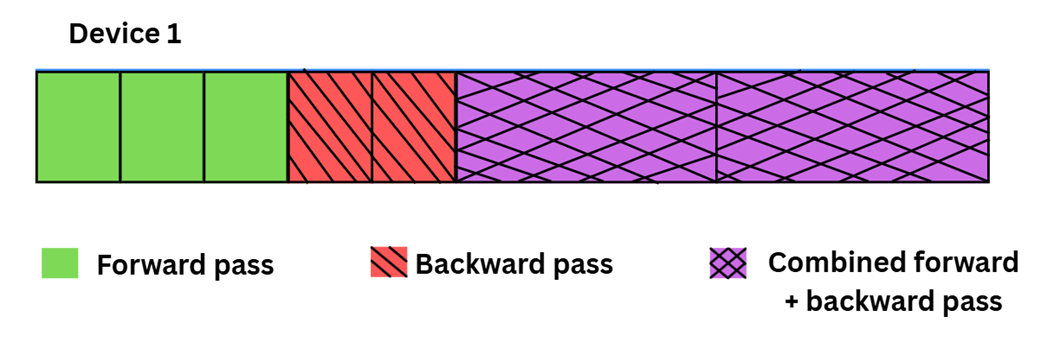
An illustration of the DualPipe training pipeline on a single device. By overlapping the forward pass (the initial blocks), backward pass (the hatched blocks), and combined computations, this scheduling strategy minimizes GPU idle time and maximizes hardware utilization during large-scale training.
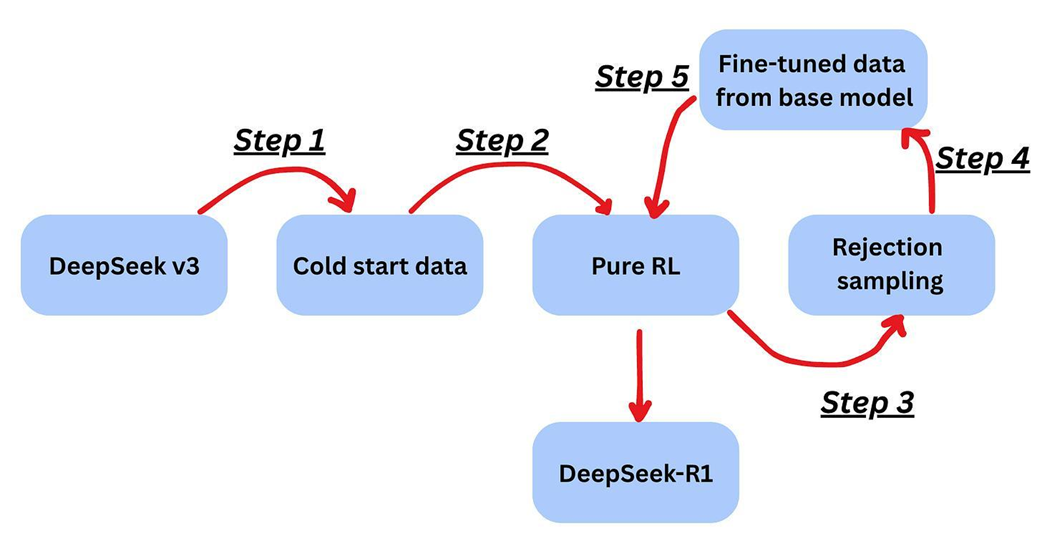
The multi-step post-training pipeline used to create DeepSeek-R1 from the DeepSeek-V3 base model. This process involves a combination of reinforcement learning (Pure RL), data generation (Rejection sampling), and fine-tuning to instill advanced reasoning capabilities.
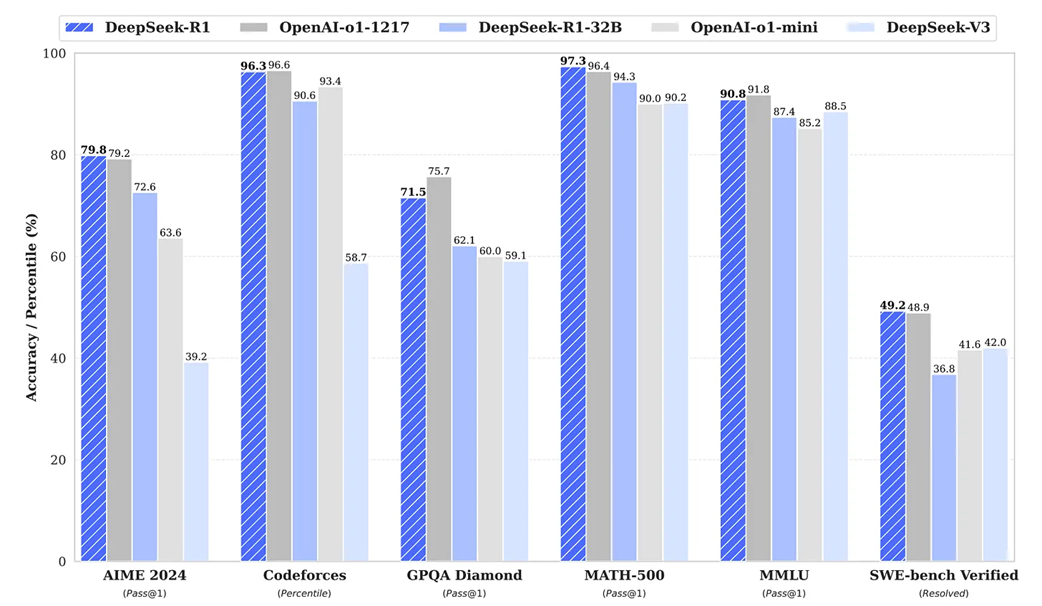
Benchmark performance of DeepSeek-R1 against other leading models (as of January 2025).
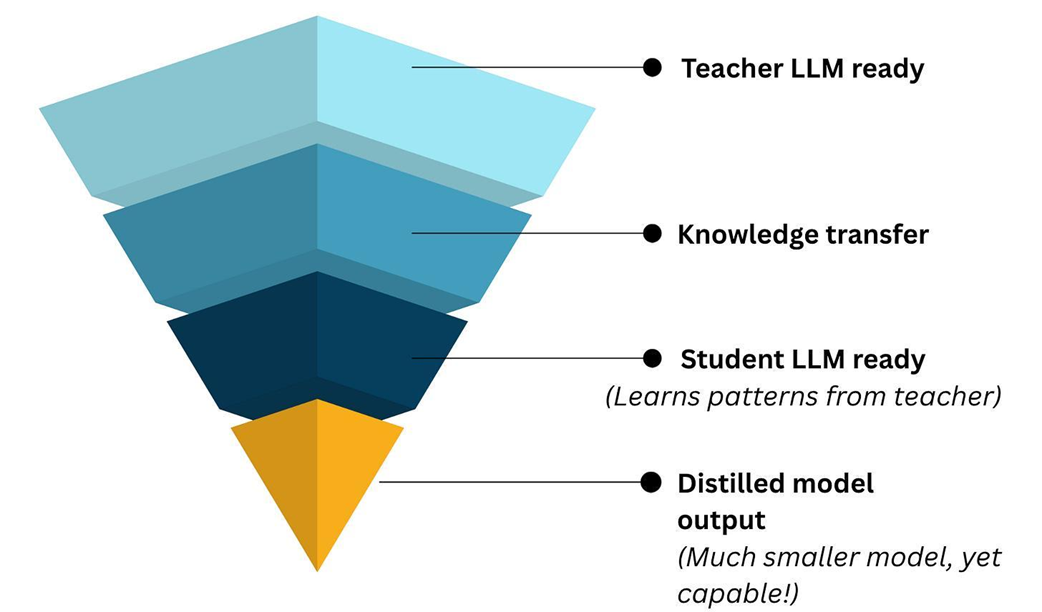
The concept of knowledge distillation. A large, powerful "teacher" model (like DeepSeek-R1) is used to generate training data to teach a much smaller, more efficient "student" model, transferring its capabilities without the high computational cost.
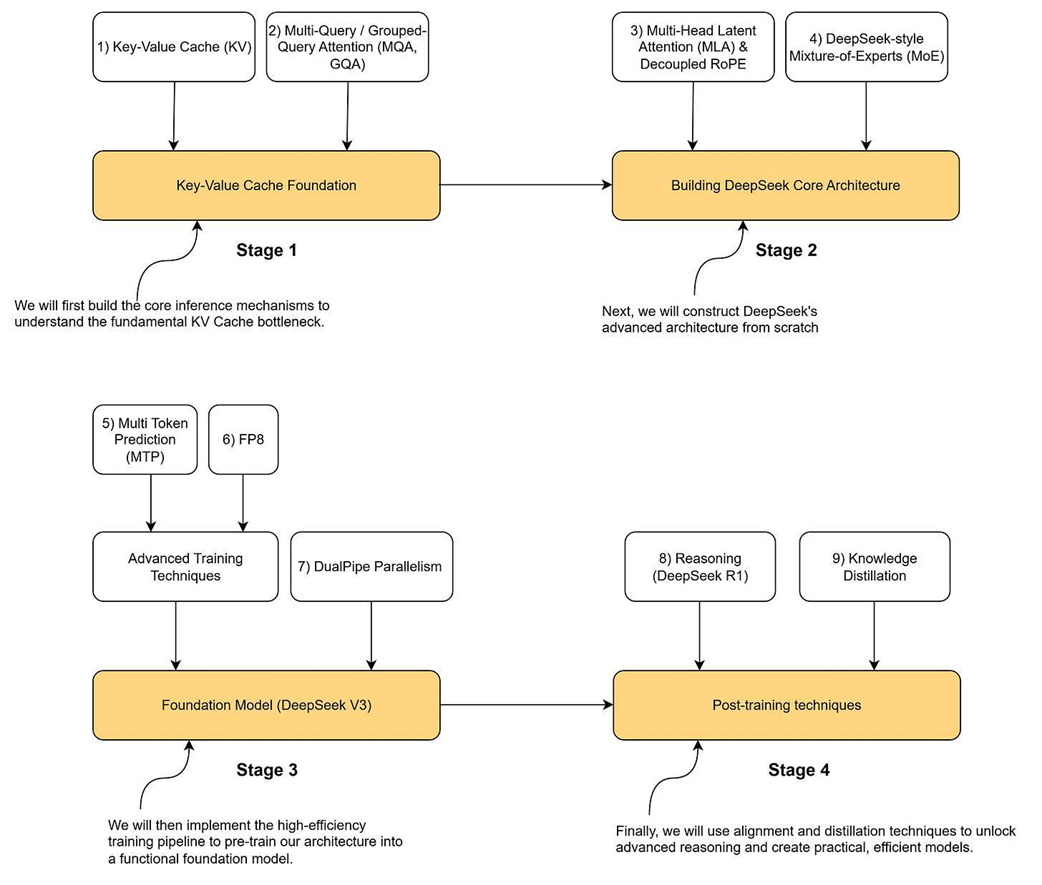
The four-stage roadmap for building a mini-DeepSeek model in this book. We will progress from foundational concepts (Stage 1) and core architecture (Stage 2) to advanced training (Stage 3) and post-training techniques (Stage 4), implementing each key innovation along the way.
Summary
- Large Language Models (LLMs) have become a dominant force in technology, but the knowledge to build them has often been confined to a few large labs.
- DeepSeek marked a pivotal moment by releasing open-source models with performance that rivaled the best proprietary systems, demonstrating that cutting-edge AI could be developed and shared openly.
- This book will guide you through a hands-on process of building a mini-DeepSeek model, focusing on its key technical innovations to provide a deep, practical understanding of modern LLM architecture and training.
- The core innovations we will implement are divided into four stages: (1) KV Cache Foundation, (2) Core Architecture (MLA & MoE), (3) Advanced Training Techniques (MTP & FP8), and (4) Post-training (RL & Distillation).
- By building these components yourself, you will gain not just theoretical knowledge but also the practical skills to implement and adapt state-of-the-art AI techniques.
FAQ
What is the main goal of Chapter 1 in “Build a DeepSeek Model (From Scratch)”?
The chapter introduces DeepSeek as the model this book will recreate from scratch, explains why it matters, outlines the major innovations the book will build, and sets expectations for the book’s scope and prerequisites.
Why is DeepSeek considered a turning point in open-source AI?
DeepSeek showed that an openly available model could rival top proprietary models in performance, narrowing the gap between open and closed AI more than before.
What makes DeepSeek’s openness different from earlier open models?
DeepSeek did not just release weights openly; it also provided unusually detailed technical reporting about its data and training pipelines, making its methods more reproducible and study-friendly.
Which DeepSeek model is the main focus of the book’s reasoning story?
DeepSeek-R1 is the key reasoning-focused model discussed in the chapter. It was built on top of the earlier DeepSeek-V3 base model and became important because of its strong benchmark performance.
What are the four core innovations highlighted in the chapter?
The chapter highlights Multi-Head Latent Attention (MLA), Mixture-of-Experts (MoE), Multi-Token Prediction (MTP), and FP8 quantization as the main technical pillars of DeepSeek.
How do MLA and MoE improve the standard Transformer architecture?
MLA replaces standard multi-head attention to improve efficiency, especially for long sequences, while MoE replaces the feed-forward network to increase model capacity more efficiently by routing tokens to specialized experts.
What is the purpose of Multi-Token Prediction (MTP)?
MTP is an auxiliary training technique that predicts more than one token at a time, which can improve learning and potentially speed up inference depending on implementation.
Why is FP8 quantization important in DeepSeek?
FP8 quantization reduces computational cost and improves resource efficiency by using 8-bit floating-point arithmetic, though it must be handled carefully to avoid numerical instability.
What will the book teach, and what will it not cover?
The book will teach the theory and implementation of DeepSeek-inspired components such as MLA, MoE, MTP, FP8, training, RL, and distillation. It will not reproduce DeepSeek’s proprietary data, exact weights, or massive-scale production training infrastructure.
What background and hardware do readers need to follow along?
Readers should be comfortable with Python, basic deep learning, backpropagation, PyTorch-style operations, and have some exposure to Transformers. The implementations are designed to run on accessible hardware such as a laptop or a consumer GPU, with some chapters also suitable for Google Colab.
 Build a DeepSeek Model (From Scratch) ebook for free
Build a DeepSeek Model (From Scratch) ebook for free