1 The world of the Apache Iceberg Lakehouse
Modern data architecture has evolved through a series of trade-offs among performance, cost, flexibility, governance, and accessibility. Traditional transactional databases were excellent for operational workloads but struggled with analytics at scale, leading to enterprise data warehouses and later cloud data warehouses. Although warehouses improved analytical performance and cloud platforms added elasticity, they often introduced high costs, data duplication, complex ETL pipelines, and vendor lock-in. Data lakes addressed storage cost and flexibility by allowing organizations to keep large volumes of structured, semi-structured, and unstructured data in distributed storage, but they frequently suffered from poor governance, slow queries, weak consistency, and “data swamp” problems.
Apache Iceberg is presented as a key technology that makes the lakehouse architecture practical. It is an open, vendor-neutral table format that adds a metadata layer over files in a data lake, allowing them to behave like managed database tables while preserving the low-cost, scalable nature of object storage. Iceberg improves lakehouse reliability and performance through ACID transactions, schema evolution, partition evolution, hidden partitioning, time travel, snapshot-based queries, and metadata pruning. Its layered metadata structure helps query engines avoid unnecessary file scans, while its open ecosystem allows multiple tools and engines to work on the same canonical datasets without forcing organizations into a single platform.
The chapter frames the Apache Iceberg lakehouse as a modular architecture made up of interoperable layers for storage, ingestion, cataloging, federation, and consumption. Storage holds data and metadata in scalable object stores or filesystems; ingestion tools load batch and streaming data into Iceberg tables; catalogs track table metadata and support governance; federation layers model, unify, and accelerate data across systems; and consumption tools deliver value through BI, AI, machine learning, APIs, and applications. By combining warehouse-like consistency and performance with lake-like openness and cost efficiency, an Iceberg lakehouse reduces duplication, supports a single source of truth, improves collaboration across teams, and enables organizations to build flexible, future-ready data platforms.
The evolution of data platforms from on-prem warehouses to data lakehouses.

The role of the table format in data lakehouses.
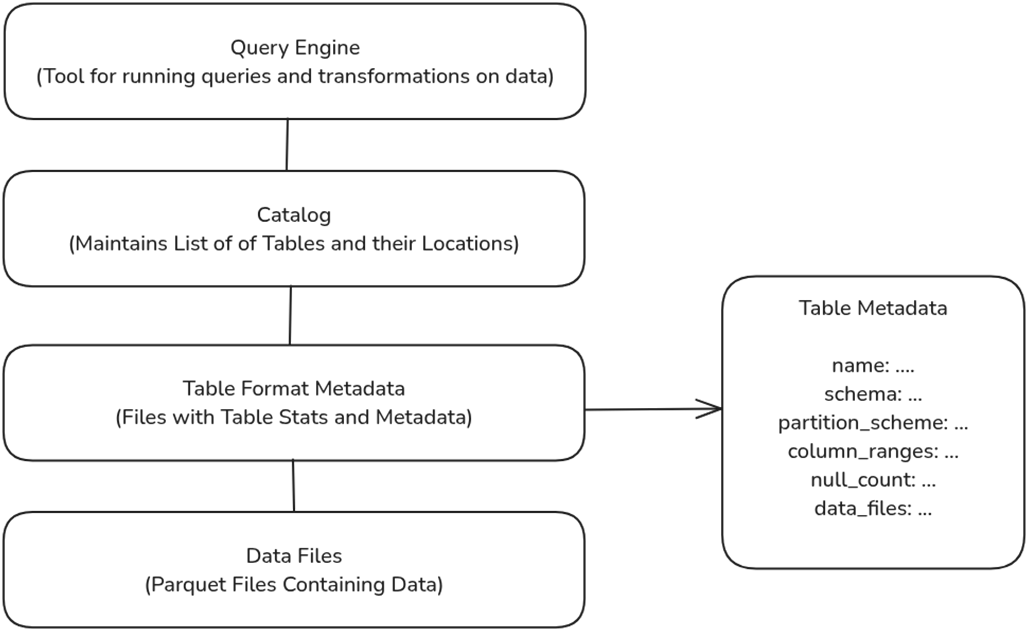
The anatomy of a lakehouse table, metadata files, and data files.
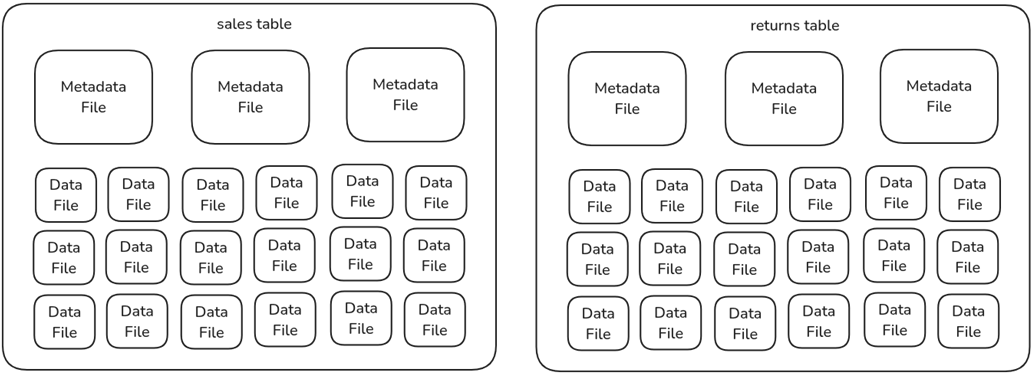
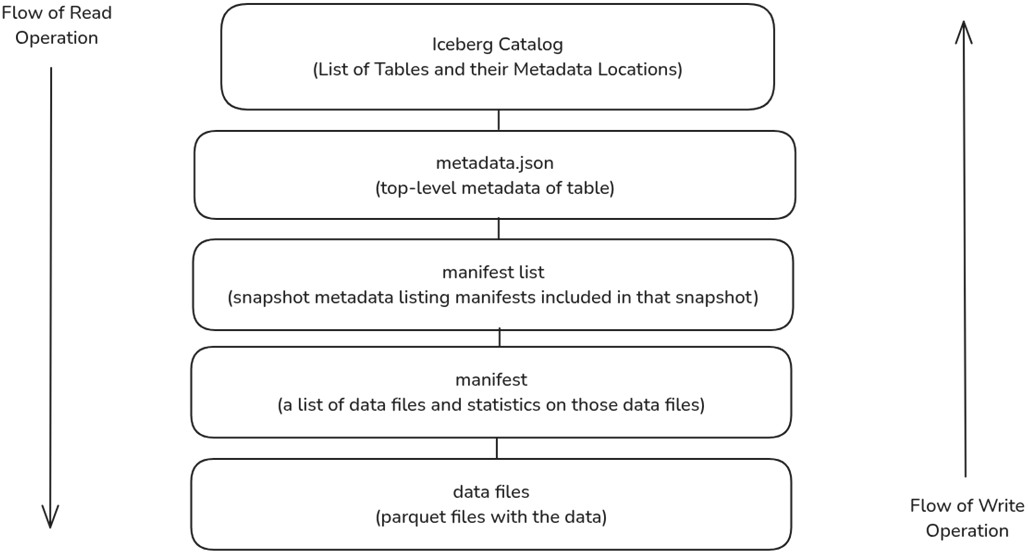
The structure and flow of an Apache Iceberg table read and write operation.
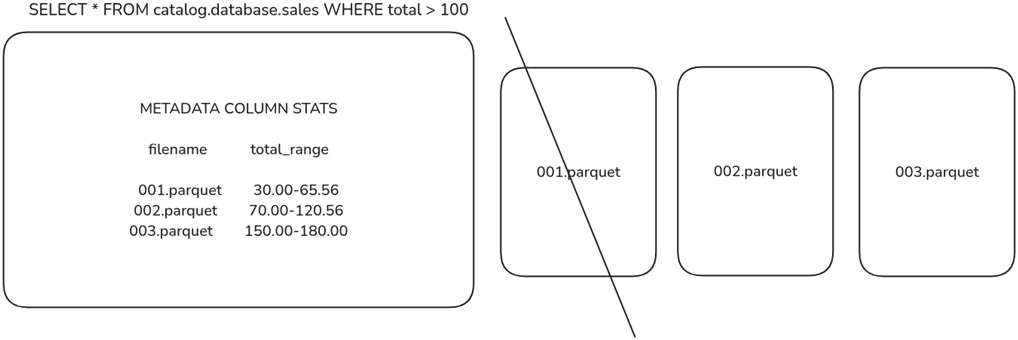
Engines use metadata statistics to eliminate data files from being scanned for faster queries.
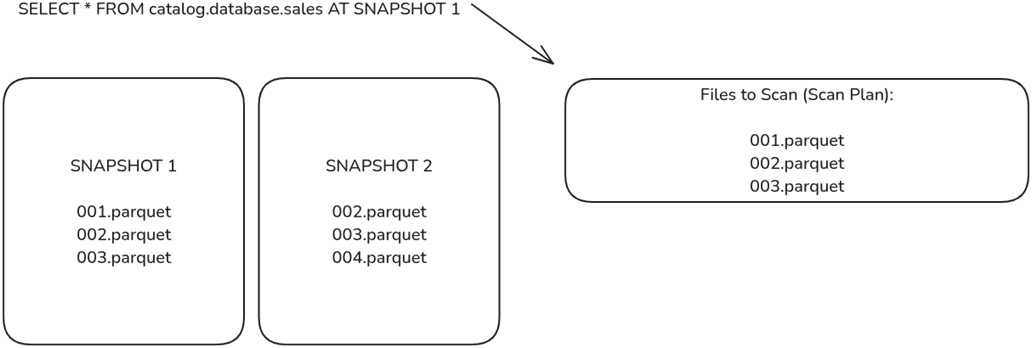
Engines can scan older snapshots, which will provide a different list of files to scan, enabling scanning older versions of the data.
The components of a complete data lakehouse implementation

Summary
- Data lakehouse architecture combines the scalability and cost-efficiency of data lakes with the performance, ease of use, and structure of data warehouses, solving key challenges in governance, query performance, and cost management.
- Apache Iceberg is a modern table format that enables high-performance analytics, schema evolution, ACID transactions, and metadata scalability. It transforms data lakes into structured, mutable, governed storage platforms.
- Iceberg eliminates significant pain points of OLTP databases, enterprise data warehouses, and Hadoop-based data lakes, including high costs, rigid schemas, slow queries, and inconsistent data governance.
- With features like time travel, partition evolution, and hidden partitioning, Iceberg reduces storage costs, simplifies ETL, and optimizes compute resources, making data analytics more efficient.
- Iceberg integrates with query engines (Trino, Dremio, Snowflake), processing frameworks (Spark, Flink), and open lakehouse catalogs (Nessie, Polaris, Gravitino), enabling modular, vendor-agnostic architectures.
- The Apache Iceberg Lakehouse has five key components: storage, ingestion, catalog, federation, and consumption.
 Architecting an Apache Iceberg Lakehouse ebook for free
Architecting an Apache Iceberg Lakehouse ebook for free