6 Performance
This chapter frames Kafka performance as a balance of throughput, latency, and resource efficiency, then explains how Kafka’s design choices serve those goals. Kafka relies on a simple, append-only log and predictable sequential I/O, leans on the operating system’s page cache, and, when possible, benefits from zero-copy transfers. Brokers focus on moving bytes while clients do most of the heavy lifting, and the platform avoids a one-size-fits-all approach by letting you tune guarantees and performance per topic, producer, consumer, and broker. The overarching message is to optimize deliberately: understand the workload, measure, and then adjust configurations in ways that respect both reliability and cost.
Performance starts with topics and partitions: partitioning enables parallelism and load balancing across brokers and within consumer groups, yet ordering is guaranteed only per partition and is strongest when enable.idempotence=true. Choosing partition counts is a trade-off—too few limits parallelism, too many strains CPU, memory, file handles, and operational complexity (with KRaft easing previous ZooKeeper limits). A practical approach is to size for consumer bottlenecks and begin with a sensible default (often around a dozen), increasing only when needed and mindful of costs. Because partitions can be increased but not decreased, and adding them changes key-to-partition mapping, preserving order often requires creating a new topic and migrating data and consumers; proposals like shared groups (queues) may relax the partitions-to-consumers constraint at the expense of strict ordering.
On the producer side, batching and compression are the key levers: larger batch.size and a modest linger.ms can dramatically lift throughput and even reduce latency, while compression.type (commonly zstd or lz4) cuts network and storage use as entire batches remain compressed end-to-end; ACKs trade reliability for speed. Producer tests with kafka-producer-perf-test.sh help quantify gains. Broker tuning emphasizes system-level settings (file descriptors, virtual memory, swappiness), right-sizing network and I/O threads, and capacity planning for storage, replication (often factor 3), and network bandwidth. Consumers are fetch-based and self-paced; fetch.min.bytes and fetch.max.wait.ms shape their throughput/latency profile, and scaling typically comes from consumer groups, which also manage offsets. Consumer performance can exceed producer rates in isolation, but real bottlenecks are often downstream processing—so always validate with production-like tests using kafka-consumer-perf-test.sh and end-to-end workloads.
We can configure performance in Kafka in many places: in the topic configuration, the brokers and all clients.
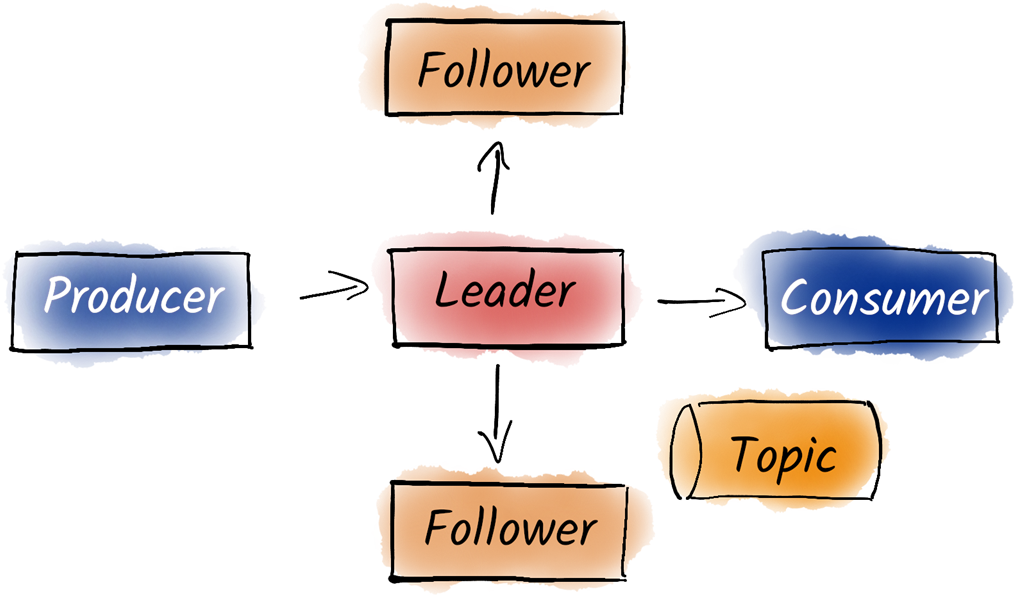
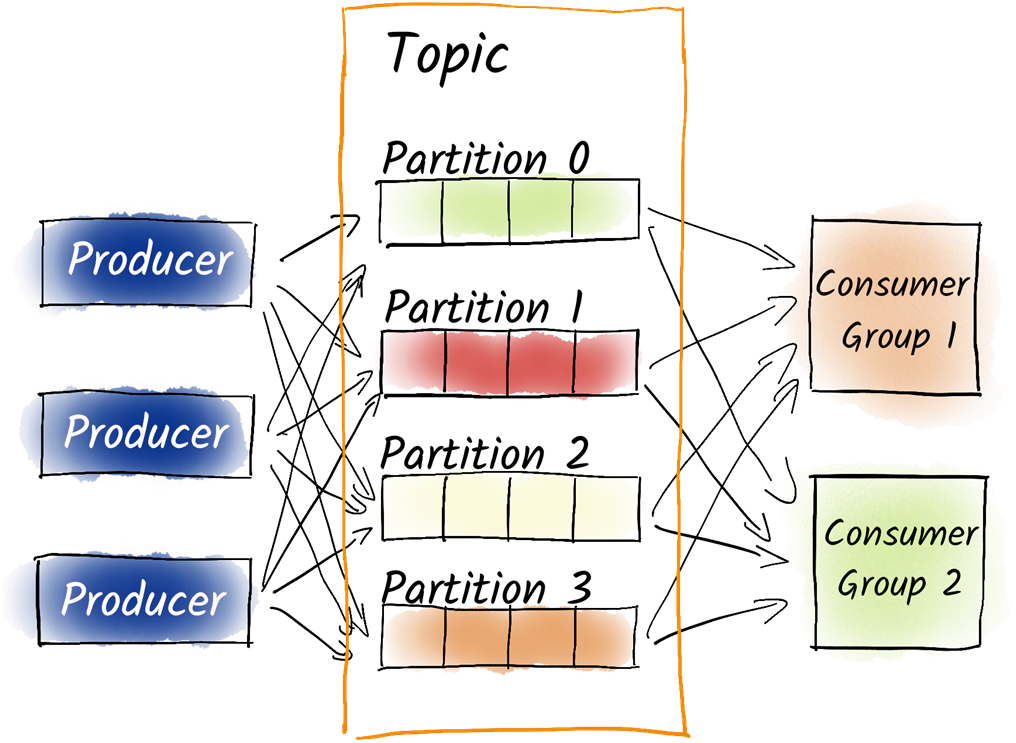
In Kafka, we partition topics for better load balancing and parallelization. We distribute the partitions to different brokers for better load balancing. Producers decide on which partition to produce the message to based on the key or round-robin. On the consumer side, we use consumer groups to process the partitions in parallel. Different consumer groups are isolated from each other.
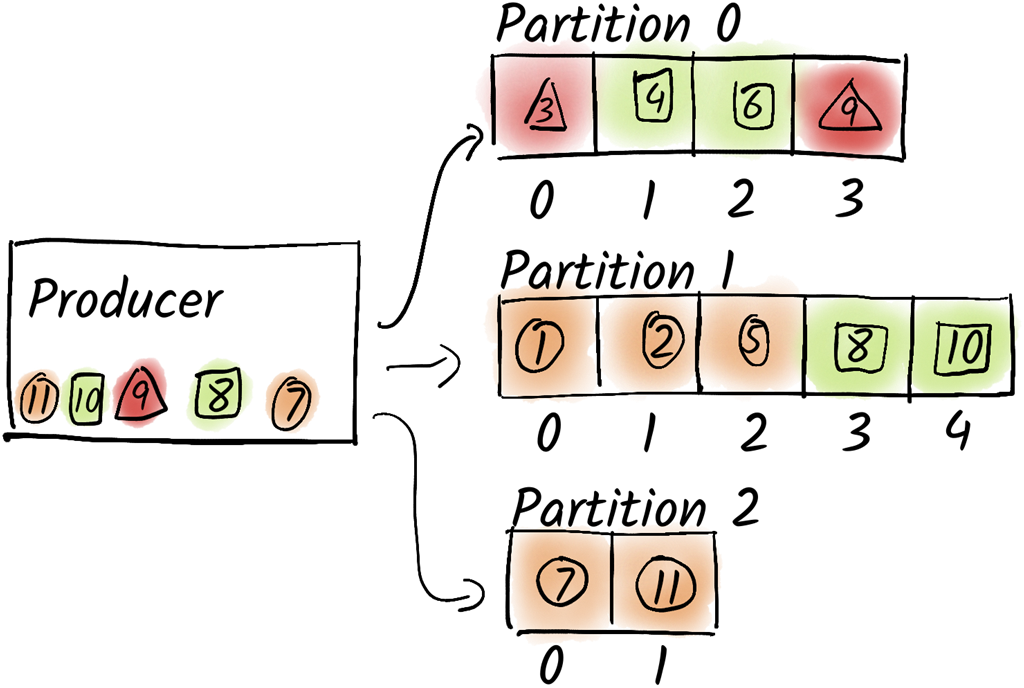
After changing the number of partitions, the partition number for a particular message key changes usually. In this example, messages with the key circle are now produced to partition 2 instead of partition 1 and messages with the key square are now produced to partition 1 instead of partition 0.
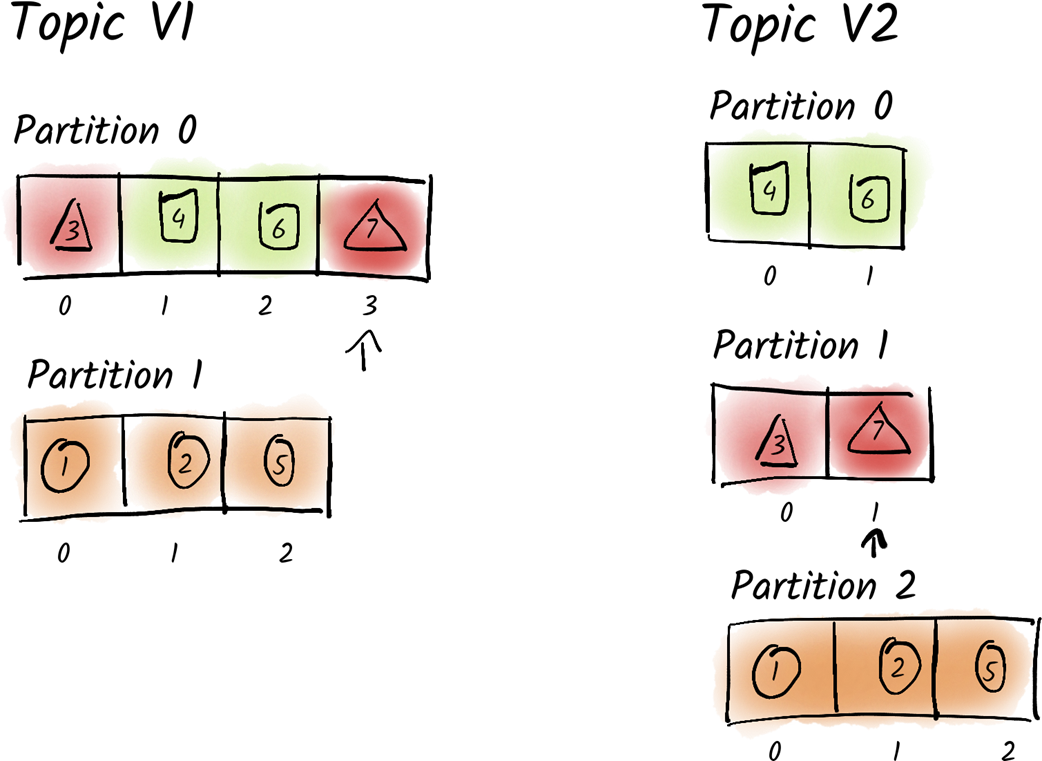
The message 7 with the key triangle was previously stored at offset 3 of partition 0. After creating a new topic with three partitions and migrating the data, this message is now stored at offset 1 of partition 1.
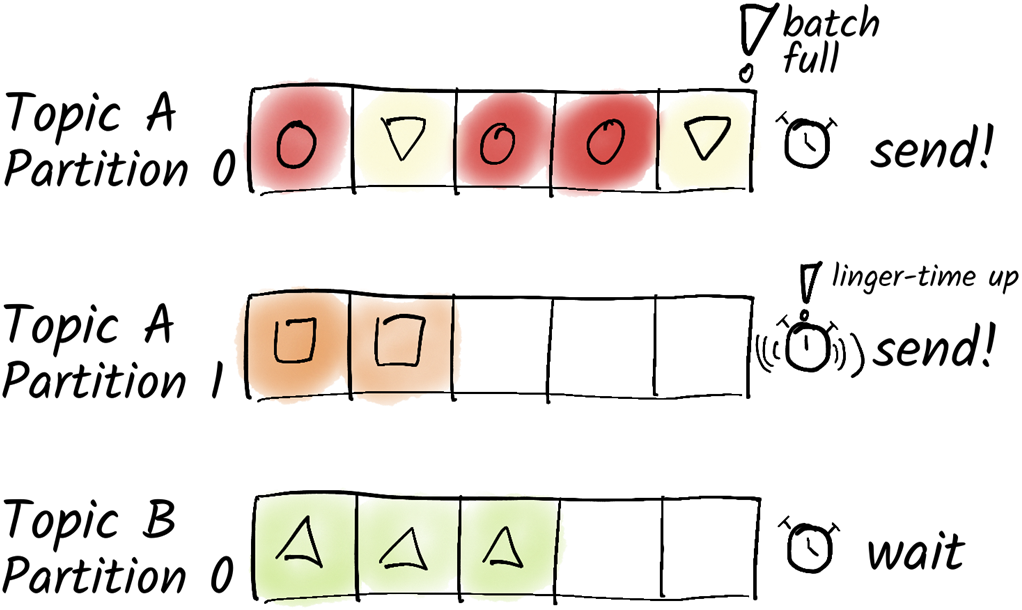
The producer batches messages for each topic and partition. A message is sent as soon as either the batch is full or the linger time is up.
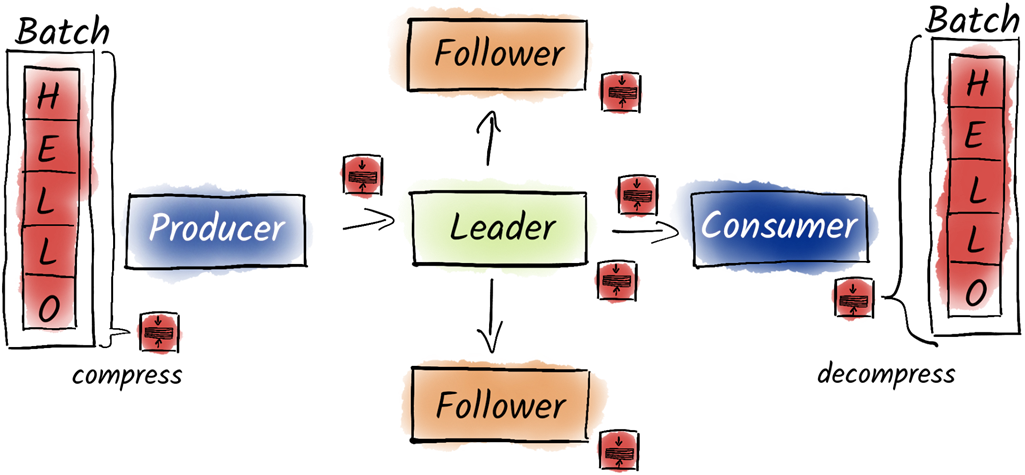
When we turn on compression, the producer compresses entire batches. Not only do we send these compressed batches over the network, but they are also stored on the brokers in compressed form. Only the consumer has to finally unpack the batch to extract the individual messages.
Summary
- High throughput does not imply low latency but both can be equally important
- Partitioning allows distributing the load and therefore increase performance
- Partitioning strategy involves identifying performance bottlenecks in consumers or Kafka and adjusting partitions accordingly.
- Consider balancing partition counts to manage client RAM usage and operational complexity.
- Start with a default of 12 partitions, scaling up as needed for high throughput, while considering operational and cost implications.
- The number of partitions can never be decreased.
- Increasing the number of partitions can lead to consuming messages in the wrong order.
- A Consumer group distributes load across its members.
- Batching can increase the bandwidth but also the latency.
- Batching can be configured with batch.size and linger.ms.
- Producers can compress batches to reduce the required bandwidth but this might increase latency.
- The usage of acks=all reduces the performance of producers by a bit, the same goes for idempotence.
- Brokers will not decompress batches, this is the task of the consumer.
- In most cases, Brokers do not require any further finetuning.
- Brokers open file descriptors for every partition.
- Kafka heavily depends on the operating system, necessitating specific OS-related optimizations to maximize its performance.
- Consumer performance depends mostly on the number of consumers in a consumer group but can be also tuned by setting fetch.max.wait.ms and fetch.min.bytes.
FAQ
What does “performance” mean in Kafka: bandwidth, latency, or something else?
Performance spans three dimensions: bandwidth (bytes per second), latency (end-to-end responsiveness), and resource friendliness (CPU, RAM, disk, and cost/energy efficiency). While bandwidth is important, users typically care more about latency; optimizing should balance all three.How do partitions enable scaling, and how many should I create?
- Partitions allow parallelism: producers distribute load, brokers spread partitions, and consumer groups process partitions in parallel while preserving order per partition.- Start by locating the bottleneck, often the consumer. Size partitions to support the required number of parallel consumers. Example: if a consumer needs ~100 ms per message (≈10 msg/s) and you need 100 msg/s peak, use at least 10 consumers and thus 10 partitions.
- Prefer easily divisible counts and a small buffer above the current consumer count for fault tolerance. A practical default is 12 partitions; double if you need more parallelism (e.g., 12 → 24 → 48).
What are the risks of having too many partitions?
- Higher client resource usage (RAM, file handles) and broker load (CPU, memory, descriptors).- Longer recovery and operational complexity, especially in older ZooKeeper-based clusters (leader movements during outages could take time).
- General guidance: up to ~4,000 partitions per broker and ~200,000 per ZooKeeper-based cluster; KRaft can handle more. Also consider cloud pricing models that charge per partition.
Can I change the number of partitions later?
- You can only increase partitions, not decrease for an existing topic.- Increasing partitions can disrupt key-based ordering because partition selection is key-hash modulo partition count; after a change, keys may map to different partitions. Expect temporary imbalance and ordering discontinuity until old data ages out per retention.
- If strict ordering must be preserved, create a new topic with the desired partition count and migrate: switch producers, let consumers drain, or copy with Kafka Streams when retaining data indefinitely. Plan offset translation and duplicate handling (e.g., include an event ID for idempotent consumption).
How is message ordering guaranteed, and what role do consumer groups play?
- Ordering is guaranteed only within a single partition. Across partitions there is no order guarantee.- Multiple producers writing to the same topic do not guarantee inter-producer ordering; to preserve order, messages with the same key must go to the same partition, and the producer should have enable.idempotence=true (with acks=all/-1).
- Consumer groups scale processing by assigning entire partitions to consumers, preserving partition-level order.
Which producer settings most affect throughput and latency?
- batch.size (bytes) and linger.ms (ms) control batching. Larger batches and a small wait often improve throughput and may even help latency if batches were too small. Common guidance: batch.size up to 1 MB and linger.ms around 10 ms; adjust based on traffic and monitor results.- compression.type: none, gzip, snappy, lz4, zstd. zstd or lz4 typically balance ratio and CPU well. Kafka compresses whole batches end-to-end (producer → broker disk → replicas) and only decompresses at the consumer, reducing network and storage load. Mixed compression across producers is allowed but standardizing per topic is preferable.
- acks: 0/1 vs all (-1) trades reliability for marginal throughput; usually set by reliability needs rather than performance alone.
How do I benchmark producer performance effectively?
- Use kafka-producer-perf-test.sh to explore settings (message size, batch.size, linger.ms, compression, etc.). Be cautious: it can generate many GB of data.- Run multiple repetitions and interpret averages/percentiles; initial runs may be slower due to JVM warmup and buffer allocations.
- Treat it as a microbenchmark. For end-to-end tests with real workloads, complement it with tools like Apache JMeter and production-like data.
How can I tune consumer performance, and what should I avoid?
- Key settings: fetch.min.bytes (how much data to accumulate before responding) and fetch.max.wait.ms (max wait before responding). Raising them increases throughput at the cost of latency.- Never set fetch.min.bytes or fetch.max.wait.ms to 0; this can overload brokers with fetch storms (potentially tens of thousands of requests/sec).
- Use kafka-consumer-perf-test.sh with a config file to measure impact. Remember consumers are fetch-based; to scale processing and manage offsets, use consumer groups.
Which broker and OS-level optimizations matter most?
- Kafka relies on the OS page cache: it acks after writing to memory, relying on replication for durability; it avoids forced fsync on every write for performance.- Zero-copy networking can move data efficiently from socket to disk/page cache, but it doesn’t apply when TLS is enabled.
- System tuning: raise file descriptor limits, tune virtual memory and swappiness, and adjust networking. For heavy TLS, consider increasing num.network.threads (e.g., from 3 to 6). Align num.io.threads with the number of disks and consider raising queued.max.requests for large client counts. Defaults are good, but monitor and tune in production.
How do I choose the number of brokers and size the cluster?
- Start with three brokers for small deployments to support a replication factor of 3 and tolerate maintenance plus an additional failure.- Size for storage (retention × daily volume × replication), throughput, network capacity, and machine specs. Example: 1 TB/day retained for 7 days = 7 TB raw; with RF=3 that’s 21 TB of replicated storage. On 2 TB nodes, you’d need roughly 11 brokers just for capacity, plus headroom.
- Balance many small vs few large brokers: more brokers reduce blast radius but increase management overhead. In environments like Kubernetes you may not control OS-level tunables; monitor to stay ahead of limits. Follow the rule: first understand, then measure, then optimize.
 Apache Kafka in Action ebook for free
Apache Kafka in Action ebook for free