4 Kafka as a distributed log
This chapter introduces Kafka through the lens of logs: ordered, append-only sequences of events that answer the question “what happened?” It explains core log properties—temporal ordering, append-at-end writes, immutability—and how offsets make large logs navigable while enabling consumers to track progress. Kafka elevates the log to a first-class storage and transport abstraction, using topics as logs and offsets to coordinate reading, but it cautions against treating Kafka as a query system or key-value store. Instead, Kafka acts as a central data backbone, where event streams are shared reliably and different systems materialize the forms they need (databases for queries, caches for fast lookups, search engines for discoverability).
To scale and remain resilient, Kafka is presented as a distributed log. Topics are partitioned so processing can be parallelized, with ordering guaranteed per partition and preserved for records sharing the same key. Without keys, producers use round-robin partitioning (now optimized via batching). Consumer groups enable horizontal consumption by assigning each partition to exactly one consumer instance within a group while storing per-group offsets for continuity. Reliability is delivered through replication: each partition has a leader and followers (replicas), with in-sync replicas (ISR) ready to take over on failure. Replication is log-based and efficient, and leaders are distributed across brokers to balance load and maintain throughput.
The chapter also outlines Kafka’s building blocks and their roles at scale. A coordination cluster manages cluster metadata, broker membership, partition leadership, and failover; Kafka now recommends KRaft for this role, replacing the operationally heavier ZooKeeper in most cases. Brokers store and serve data, while clients—producers, consumers, Kafka Streams, and Kafka Connect—write, read, process, and integrate data with external systems. In corporate environments, Kafka becomes a data hub: Connect links databases and other systems, Streams enables real-time processing, schema registries standardize data formats across teams, MirrorMaker 2 supports multi-datacenter mirroring, and robust operations (monitoring, automation, governance) turn Kafka into a dependable streaming platform for near–real-time, data-driven decisions.
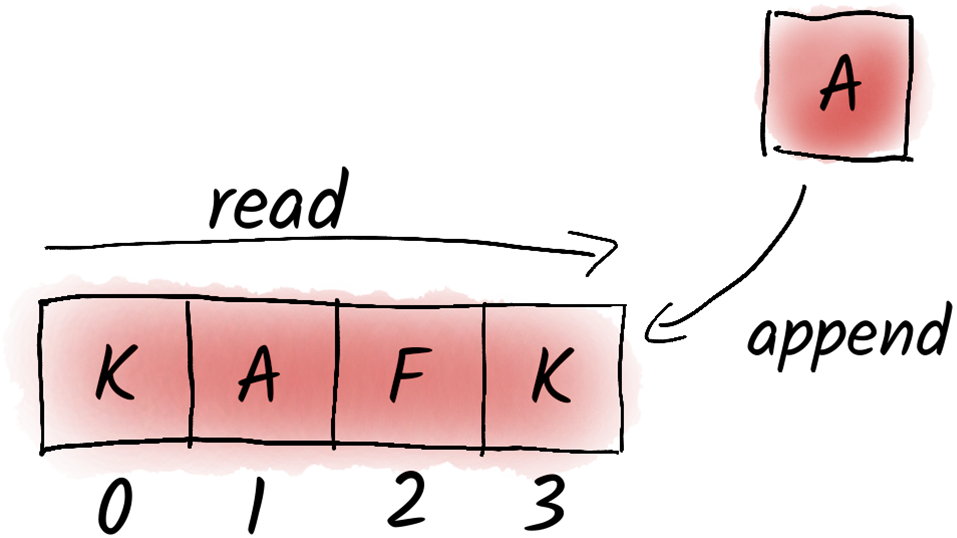
A log is a sequential list where we add elements at the end and read them from a specific position (offset). For example, we read from offset 0, then choose to read from offset 4, and so on.
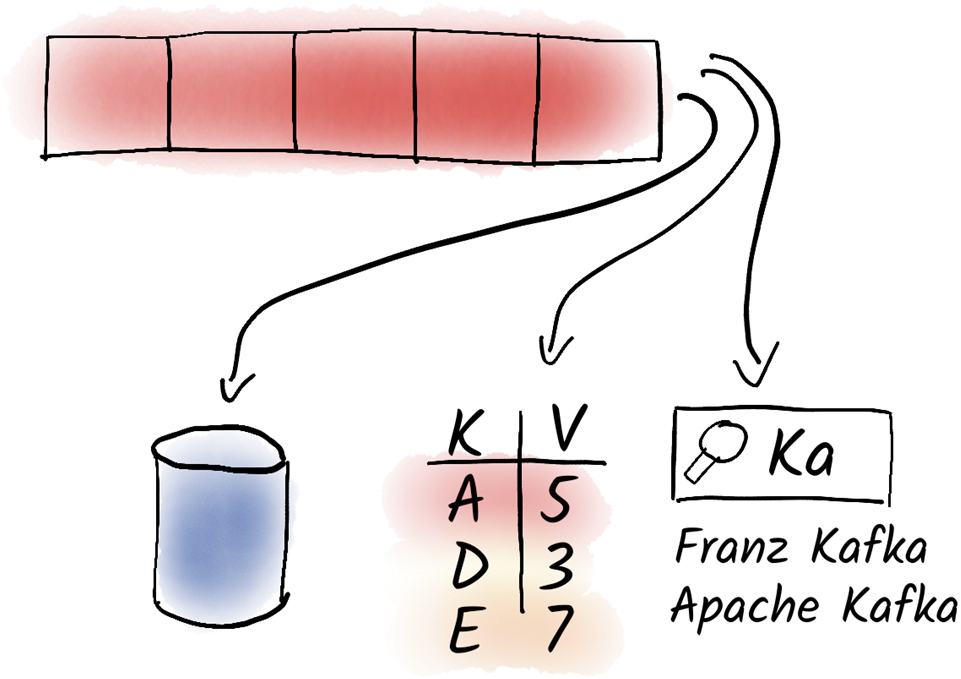
A log is a perfect data structure to exchange data between systems. Typically, we do not work directly with the data in the log, but store it in a data format that is best suited for our particular use case. For example, we can use relational databases to perform complex queries over our data. If we want to access prepared data quickly, we can use an in-memory key-value store like Redis, for example. If we want to provide a search function over the data in the log, we can use a search engine for that.
Scaling vertically means adding more resources to a single instance. Scaling horizontally means adding more instances to a system.

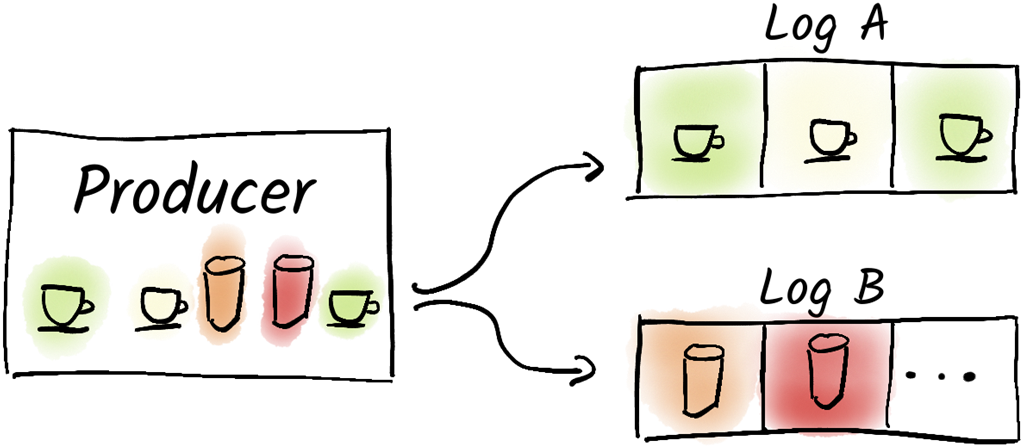
Log A holds all the data for coffee pads and log B holds all data for cola.
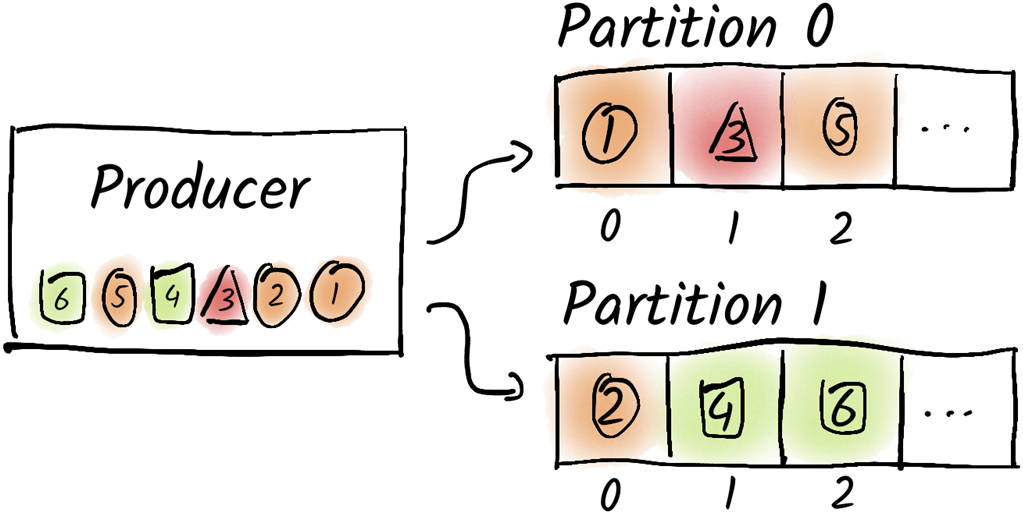
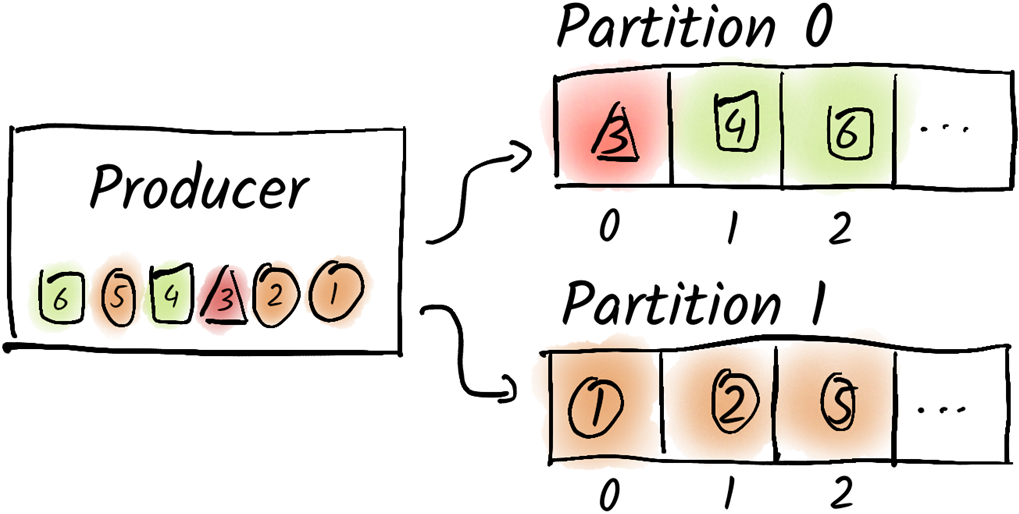
Every odd message was produced to partition 0 and every even message was produced to partition 1.
Messages with the same key (here the form) were produced to the same partition
If we have only one consumer that needs to read data from all partitions, it may not be able to keep up and we may not be able to process the data in a timely manner.
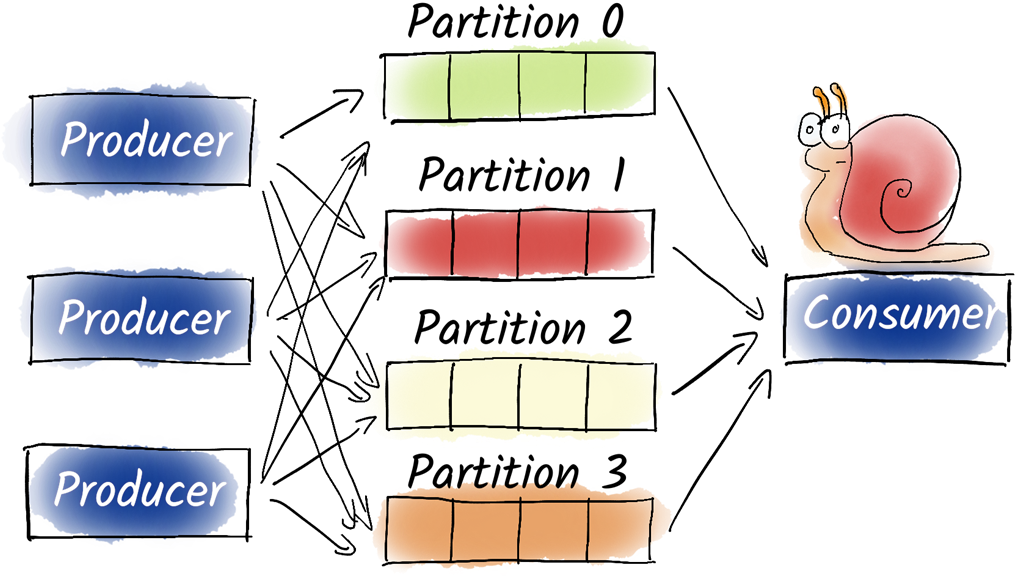
Consumer groups allow us to split the processing of multiple partitions between different instances of the same service. Often, not only one consumer group consumes the data from a topic, but several. Consumer groups are isolated from each other and do not influence each other.

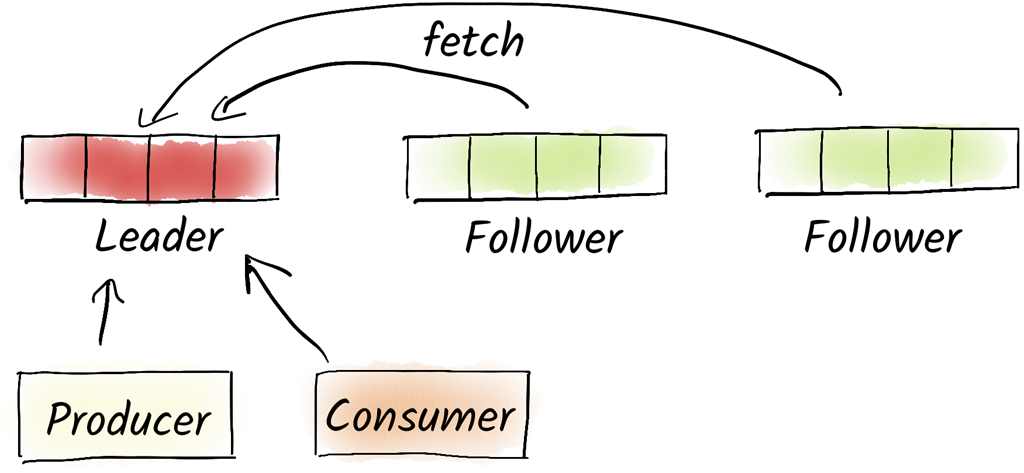
Consumer and producer communicate exclusively with the leader (with rare exceptions). Followers are only there to continuously replicate new messages from the leader. If the leader fails, one of the followers takes over.
A typical Kafka environment consists of the Kafka cluster itself and the clients that write and read data to Kafka. Before the KRaft-based coordination cluster, a Zookeeper-ensemble was used as a coordination cluster. Without Zookeeper, brokers can take over the task of the coordination cluster themselves or outsource it to a standalone coordination cluster.
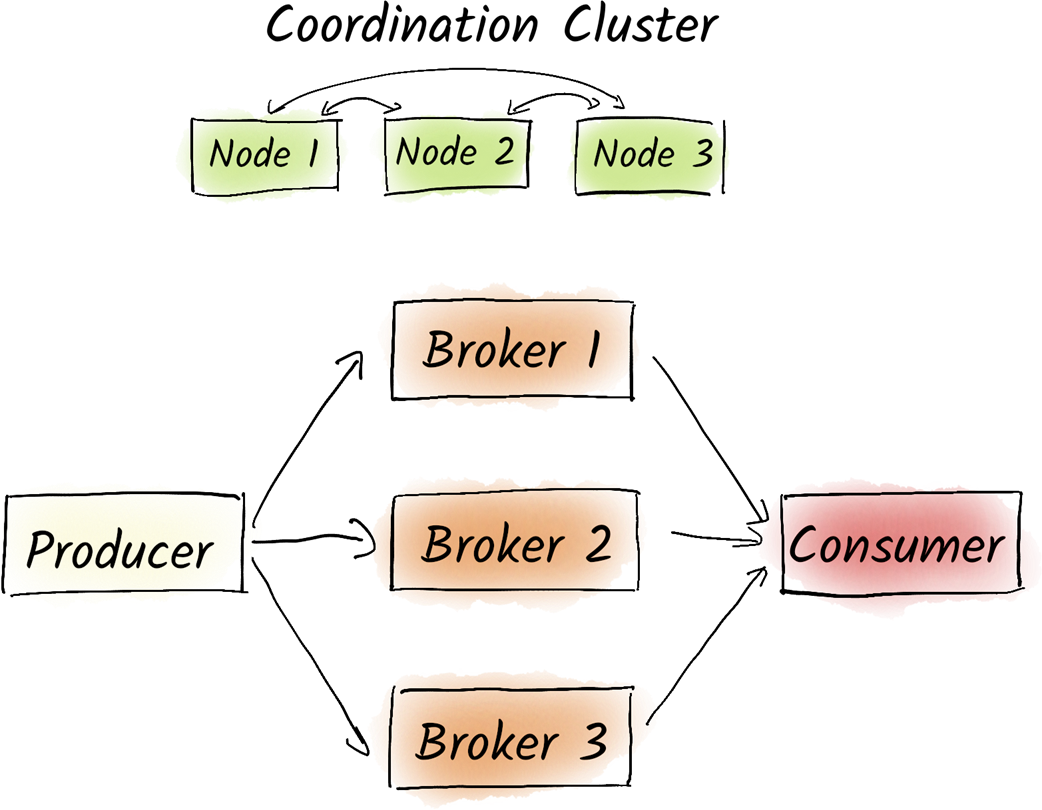
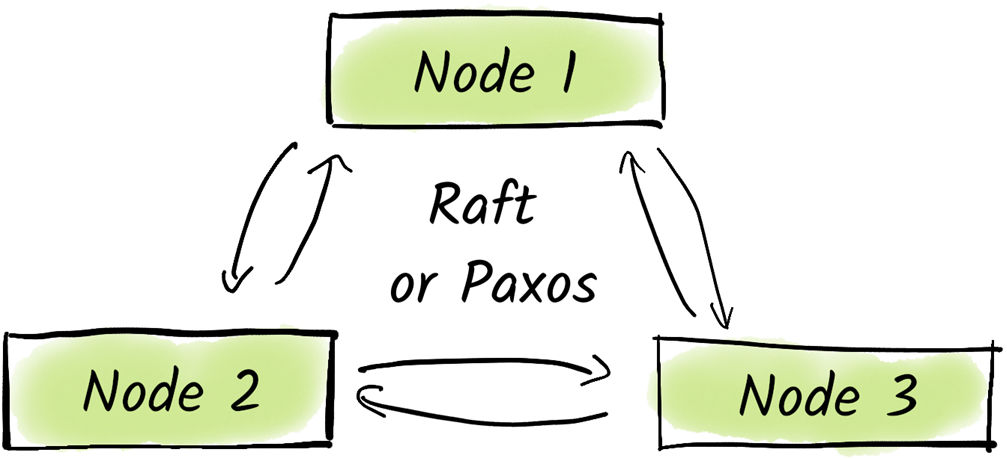
Kafka uses either a KRaft-based or a Zookeeper-based coordination cluster. Both should consist of an odd number (usually 3 or 5) of nodes and are using a protocol to find a consensus.
Kafka alone is usually not enough. The Kafka ecosystem offers numerous components to integrate Kafka into our enterprise landscape and thus build a streaming platform.

Summary
- A log is a sequential list where we add elements at the end and read them from a specific position.
- Kafka is a distributed log, the data of a topic is distributed to several partitions on several brokers.
- Offsets are used to define the position of a message inside a partition.
- Kafka is used to exchange data between systems, it does not replace databases, key-value stores, or search engines.
- Partitions are used to scale topics horizontally and enable parallelization of processing.
- Producers use partitioners to decide into which partition to produce to.
- Messages with the same keys end up in the same partition.
- Consumer groups are used to scale consumers and allow them to share the workload, one partition is always consumed by one consumer inside a group.
- Replication is used to ensure reliability by duplicating partitions across multiple brokers within a Kafka cluster.
- There is always one leader replica per partition which is responsible for the coordination of the partition.
- Kafka consists of a coordination cluster, brokers, and clients.
- The coordination cluster is responsible for orchestrating the Kafka cluster, in other words for managing brokers.
- Brokers form the actual Kafka cluster, they are responsible for receiving, storing, and making messages available for retrieval.
- Clients are responsible for producing or consuming messages, they connect to brokers.
- There are various frameworks and tools to easily integrate Kafka into an existing corporate infrastructure.
 Apache Kafka in Action ebook for free
Apache Kafka in Action ebook for free