18 Kafka’s role in modern enterprise architectures
Kafka’s role in modern enterprise architectures is to serve as a real-time, scalable backbone that connects operational and analytical systems while decoupling teams. The chapter surveys how organizations use Kafka to integrate heterogeneous domains, act on streams for analytics and automation, and modernize legacy landscapes. It balances enthusiasm with caution, emphasizing that Kafka delivers the most value when paired with clear ownership, good governance, and fit-for-purpose patterns—and that it is not a universal solution for every data challenge.
In a data mesh, departments publish “data products” and own their schemas, while a platform team supplies self-service infrastructure and guardrails; Kafka underpins this with high-throughput topics, schema enforcement, access controls, and economical retention via tiered storage. The chapter shows how to liberate data from core systems using CDC, reshape raw, normalized records into consumable streams, and choose where to perform heavy joins (often a relational database feeding Kafka via an outbox). It also revisits Kafka’s big-data heritage—moving vast clickstreams reliably and buffering load spikes—capabilities that remain central for bulk data movement with low operational overhead.
For industrial IoT, Kafka aggregates device and sensor data for predictive maintenance, factory automation, supply-chain visibility, and energy management, often bridging protocols like MQTT and supporting both real-time and batch consumers; tiered storage, self-service access, and careful multi-cluster choices round out the operating model. Equally important are the antipatterns: Kafka is not a relational database, not for synchronous request–response, and not a file-transfer bus; messages should be denormalized, and large documents belong in object storage with Kafka carrying references. For small, single-team workloads, simpler tools may suffice. Above all, success depends on sound architecture, disciplined governance, and pragmatic use of Kafka where it truly fits.
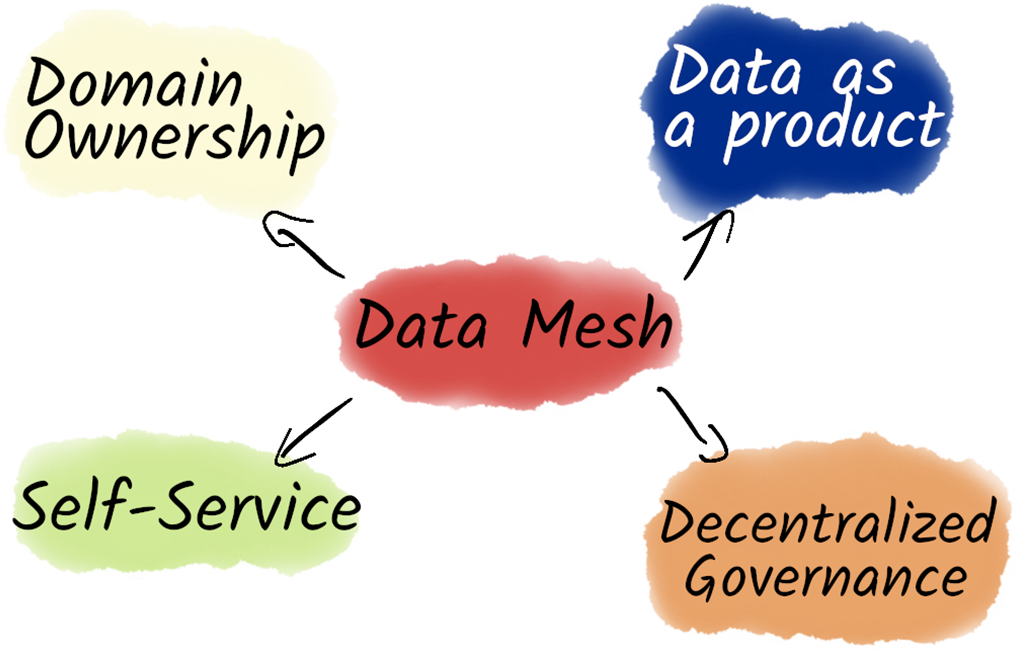
The core principles of a data mesh.
A team of data engineers ensures that all data from all services is centrally collected in a data lake. Since these teams cannot accurately assess the quality of the data, the data lake often turns into a data swamp.
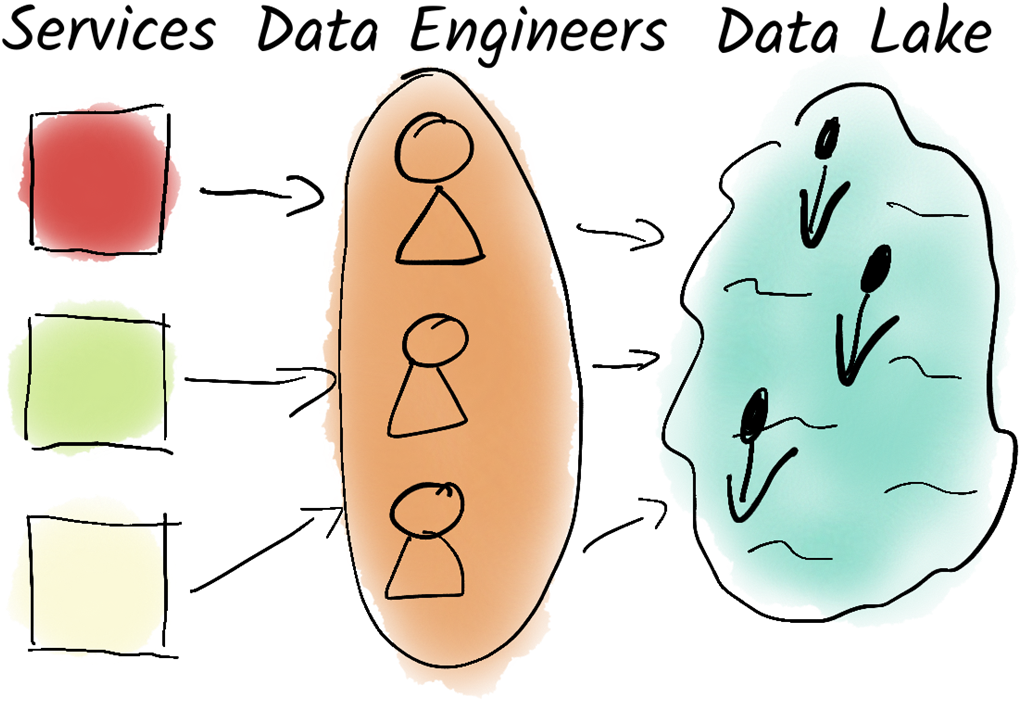
Kafka in a data mesh architecture.

With Kafka, we can cost-effectively provide data from mainframes or core systems to other services.

Debezium accesses the commit log of the database directly.

Kafka was originally developed at LinkedIn to quickly, securely, and efficiently move large amounts of data from sensors on the website and app into their Hadoop cluster.

Kafka as an interface between Message Queuing Telemetry Transport (MQTT) and other applications.

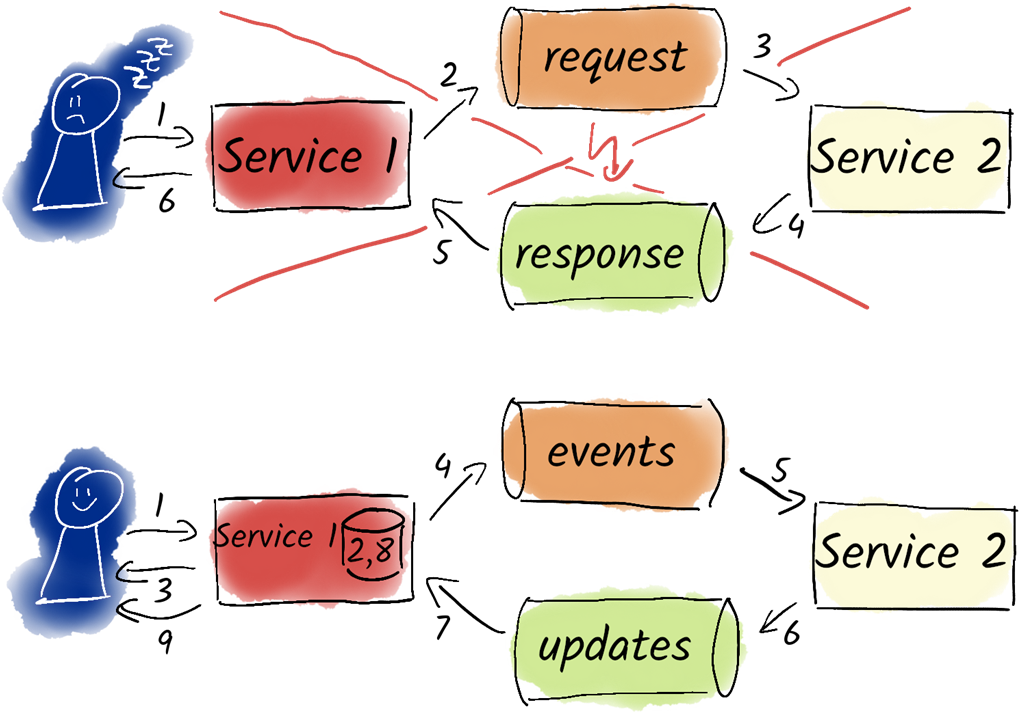
Do not use Kafka for synchronous request-response communication. Instead, notify users about asynchronous processes and confirm the process when it is done.
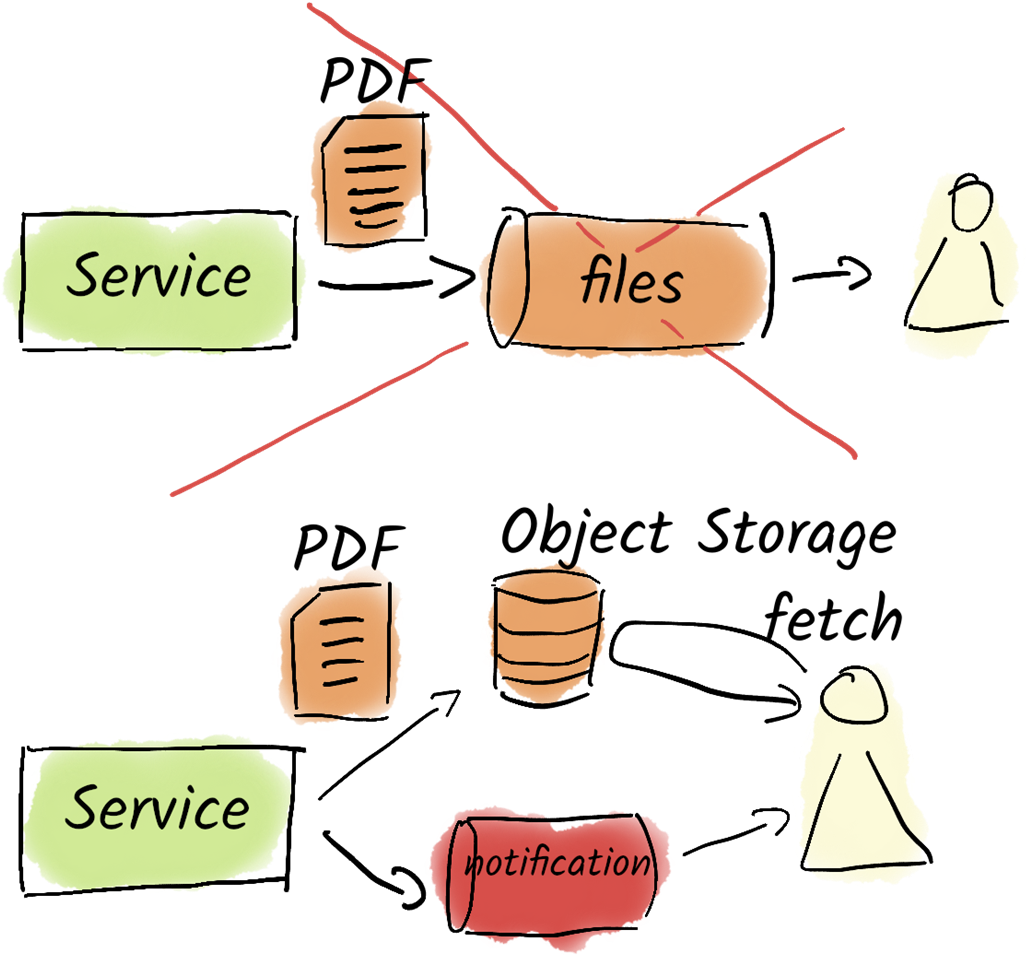
Do not use Kafka to exchange files between systems. Use, for example, an object storage solution and use Kafka to notify others about the file that was uploaded or changed.
Summary
- The data mesh decentralizes data management, empowering departments to take ownership of their data products while the data team focuses on technical support.
- Key principles of the data mesh include treating data as a product, domain ownership, self-service data infrastructure, and decentralized governance.
- Apache Kafka acts as a central hub for real-time data exchange within a data mesh, enhancing data quality and accelerating data movement across the organization.
- Core systems are essential but rigid; liberating data from them with Kafka enables agile services while minimizing direct interaction and maintenance costs.
- Debezium facilitates real-time data exchange using Change Data Capture, but new data structures must be created to avoid complexity and improve usability for other applications.
- Kafka was designed for efficiently transferring large volumes of data in big data environments, utilizing a log-based architecture for reliable delivery and buffering against load spikes.
- Kafka efficiently handles the growing data volumes from industrial applications, enabling real-time monitoring, predictive maintenance, and centralized data collection for various use cases.
- Tiered storage in Kafka allows organizations to balance performance and cost by retaining frequently accessed data while offloading historical data to lower-cost storage, streamlining data management.
- Effective data integration and access management can be achieved through protocols like Message Queuing Telemetry Transport (MQTT) for reliable data transmission, while centralized Kafka clusters simplify management and support self-service tools for teams.
- Kafka is not a relational database, making it unsuitable for complex queries or maintaining the current state, as it lacks full ACID guarantees, particularly transactional isolation.
- Kafka is not a synchronous communication interface; it operates asynchronously and requires relational databases for immediate feedback.
- Kafka is not a file exchange platform, as it is not designed for large files like PDFs; it is more effective to send machine-readable data or links to files stored externally.
- Kafka is not ideal for small applications with low data volumes. In these cases, simpler solutions like a database may be more effective.
FAQ
What problems in traditional data management does a data mesh address?
- Centralized data teams become bottlenecks for ETL and quality control.
- Frequent source changes (e.g., CRM/ERP schema tweaks) break pipelines.
- Lack of domain ownership creates poor documentation and inconsistent data.
- Data lakes drift into “data swamps” without governance and standards.
What are the four core principles of a data mesh?
- Domain ownership: business domains own and publish their data.
- Data as a product: data is treated like a product with clear contracts and consumers.
- Self-service data platform: domain-agnostic tooling to publish/consume safely.
- Decentralized governance: shared standards for security, semantics, and interoperability.
How does Kafka support a data mesh in practice?
- Real-time publishing and consumption of data products at scale.
- Schema enforcement for reliable, compatible data exchange.
- Integration with governance tools for ACLs, quotas, and compliance.
- Cost-effective long-term retention with tiered storage.
Who is responsible for what in a Kafka-backed data mesh?
- Producing business units: define, document, and publish data products; manage lifecycle and access; honor schema contracts.
- Consuming business units: request access; comply with schemas, security, and governance.
- Data platform team: provide the platform, tooling, and guardrails; enable self-service.
How can Kafka help “liberate” data from core systems?
- Use CDC (e.g., Debezium) to stream changes from core databases into Kafka.
- Avoid exposing raw, normalized core schemas broadly; build consumable, denormalized data products.
- Derive consolidated streams with Kafka Streams (noting complexity of large joins) or perform joins in a separate relational DB and publish results via outbox/CDC.
When should you avoid large joins in Kafka Streams, and what are alternatives?
- Avoid when joins span many tables and require heavy state; operational complexity and cost rise sharply.
- Prefer pre-joining in a relational DB fed by CDC, then publish curated results via outbox.
- Design messages to be self-contained and denormalized to minimize downstream joins.
What IIoT use cases fit Kafka, and how do devices send data?
- Use cases: predictive maintenance, factory automation, supply chain optimization, energy management, real-time production analytics.
- Ingestion: write directly to Kafka if devices/networks are robust; otherwise use MQTT brokers that bridge into Kafka.
- Security: avoid direct broker access from untrusted devices; handle outages with buffering; apply topic-level ACLs and consider a Kafka proxy for finer control.
How should organizations handle Kafka data retention and historical data?
- Retain long enough for all consumers to process.
- Use tiered storage to keep hot data on brokers and cold data on cheaper storage.
- Plan for historical access patterns (e.g., ML training) and retrieval by data age.
When does it make sense to run multiple Kafka clusters?
- Performance isolation for workloads with different latency/throughput needs.
- Data security and regulatory isolation (e.g., HR vs. manufacturing).
- Geographic distribution for latency and data sovereignty.
- Extreme scale and fault tolerance by splitting domains.
- Otherwise, prefer a single cluster to reduce operational overhead.
What is Kafka not well-suited for, and what are common antipatterns?
- Not a relational database: avoid current-state queries and heavy multi-table joins.
- Not for synchronous request–response: use DB/REST for sync, and CDC/Outbox for async workflows.
- Not a file exchange platform: store files in object storage; send references or split large payloads into events.
- Often overkill for small, single-team, low-volume monoliths.
- Not a substitute for sound architecture and domain understanding.
 Apache Kafka in Action ebook for free
Apache Kafka in Action ebook for free