16 Disaster management
Disaster management in Kafka focuses on anticipating failures, minimizing business impact, and restoring service with integrity. The chapter outlines how outages can translate into financial loss, customer dissatisfaction, compliance exposure, and reputational damage, and emphasizes distinguishing critical from noncritical scenarios to prioritize recovery strategies. It highlights both technical and human causes of incidents, advocates for strong monitoring and runbooks, and underscores Kafka’s resilience—durable logs and asynchronous design—while reminding teams that application behavior during outages (especially producers) ultimately determines end-to-end reliability.
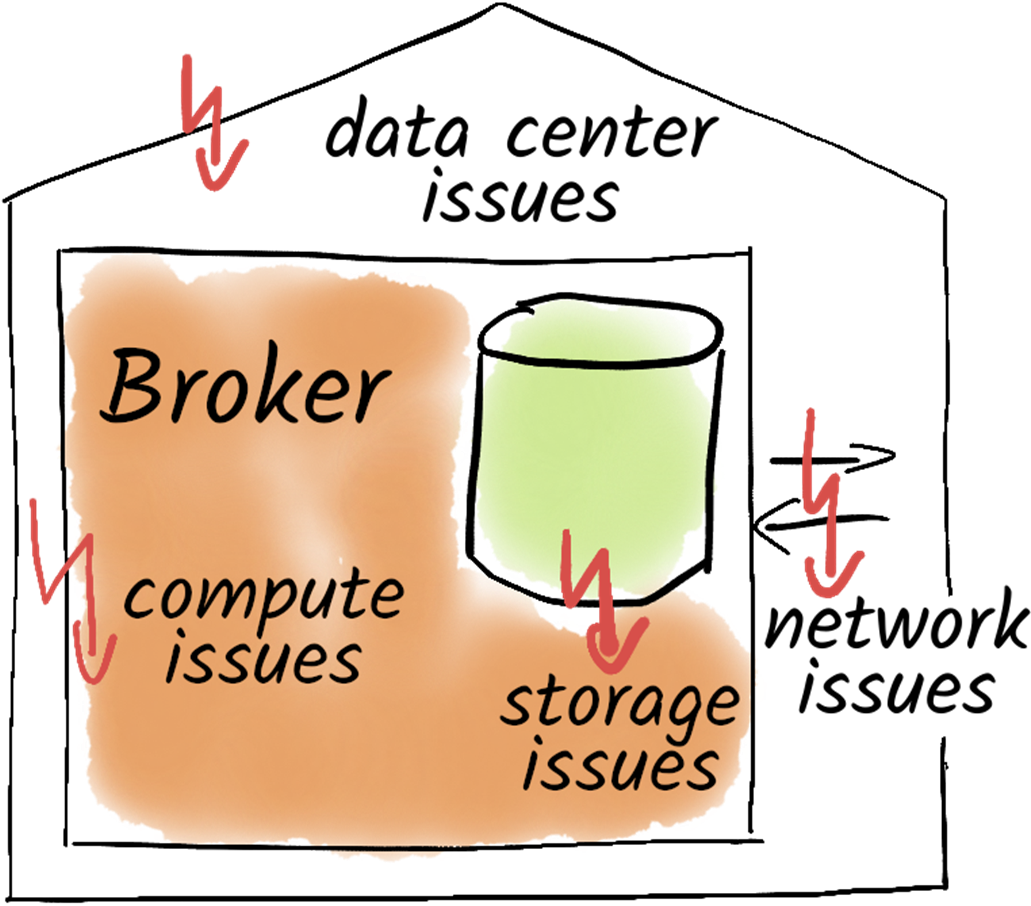
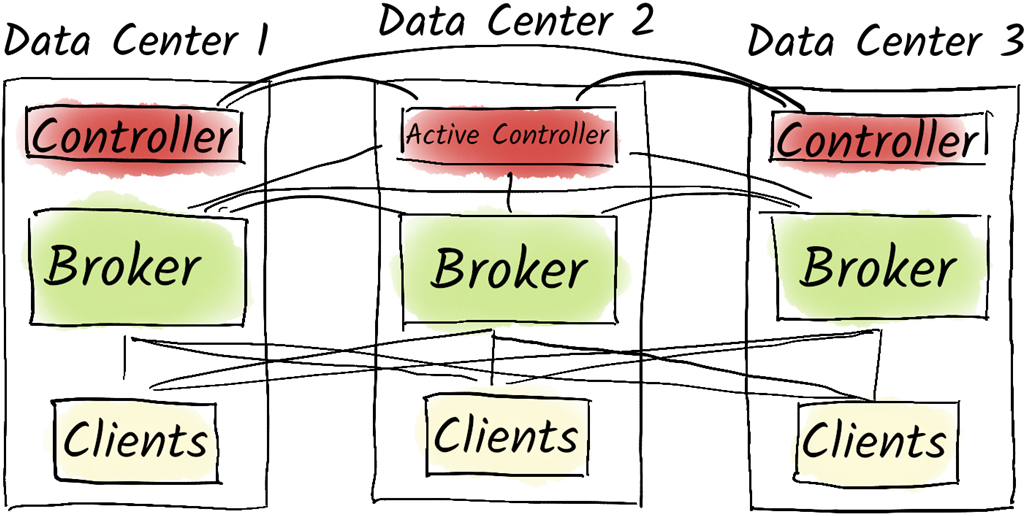
Core failure modes include network, compute, storage, and full datacenter events. Client–broker network issues cause producer backlogs and require application choices (block, buffer, drop, or fail fast), while inter-broker partitions can disrupt replication and leadership until connectivity returns. Compute failures are mitigated by replication and write guarantees—using appropriate replication factor, min.insync.replicas, and acks=all—plus straightforward broker recovery with the same broker.id. Storage risks center on full disks and failed volumes; proactive capacity monitoring, stopping Kafka before exhaustion, and using multiple log directories help limit loss. For datacenter failures, a stretched cluster across at least three sites with rack-aware placement (broker.rack) improves tolerance, and client.rack can reduce cross-zone traffic by consuming from local replicas, though costs and latency constrain multi-region setups; where multi-DC is not viable, distribute brokers across independent racks within a single site.
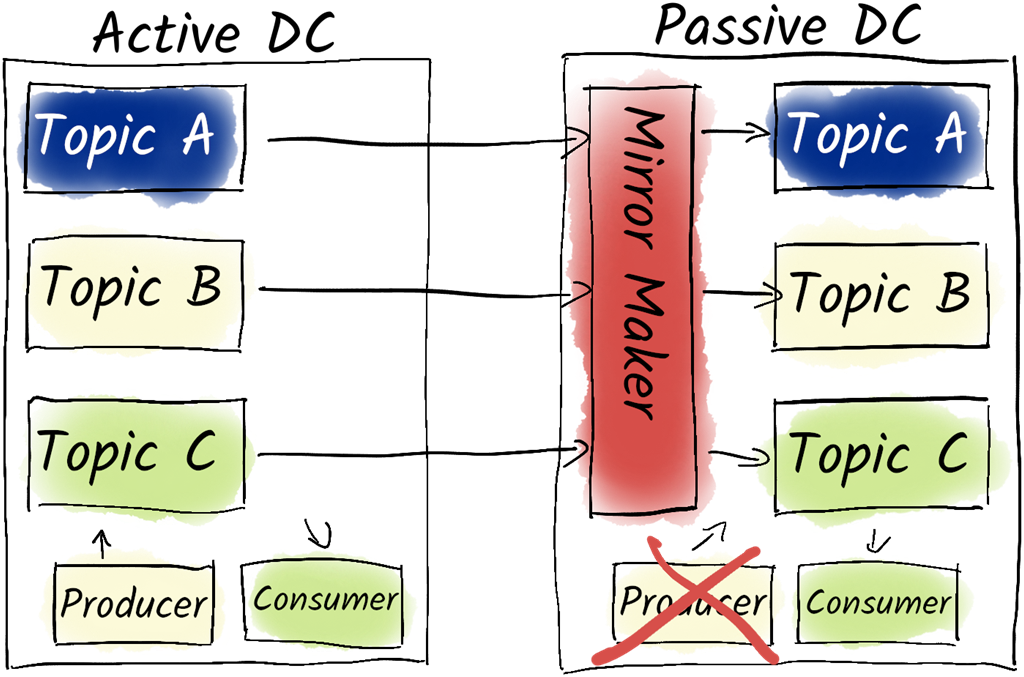
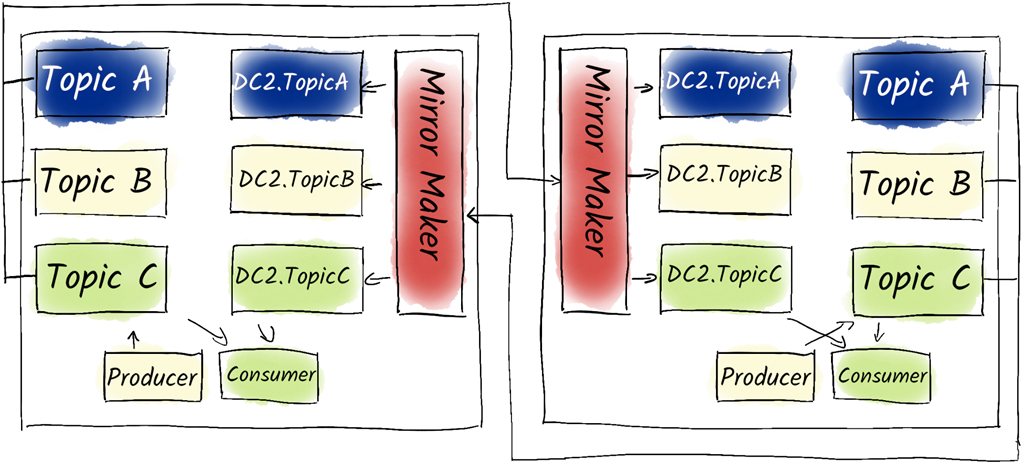
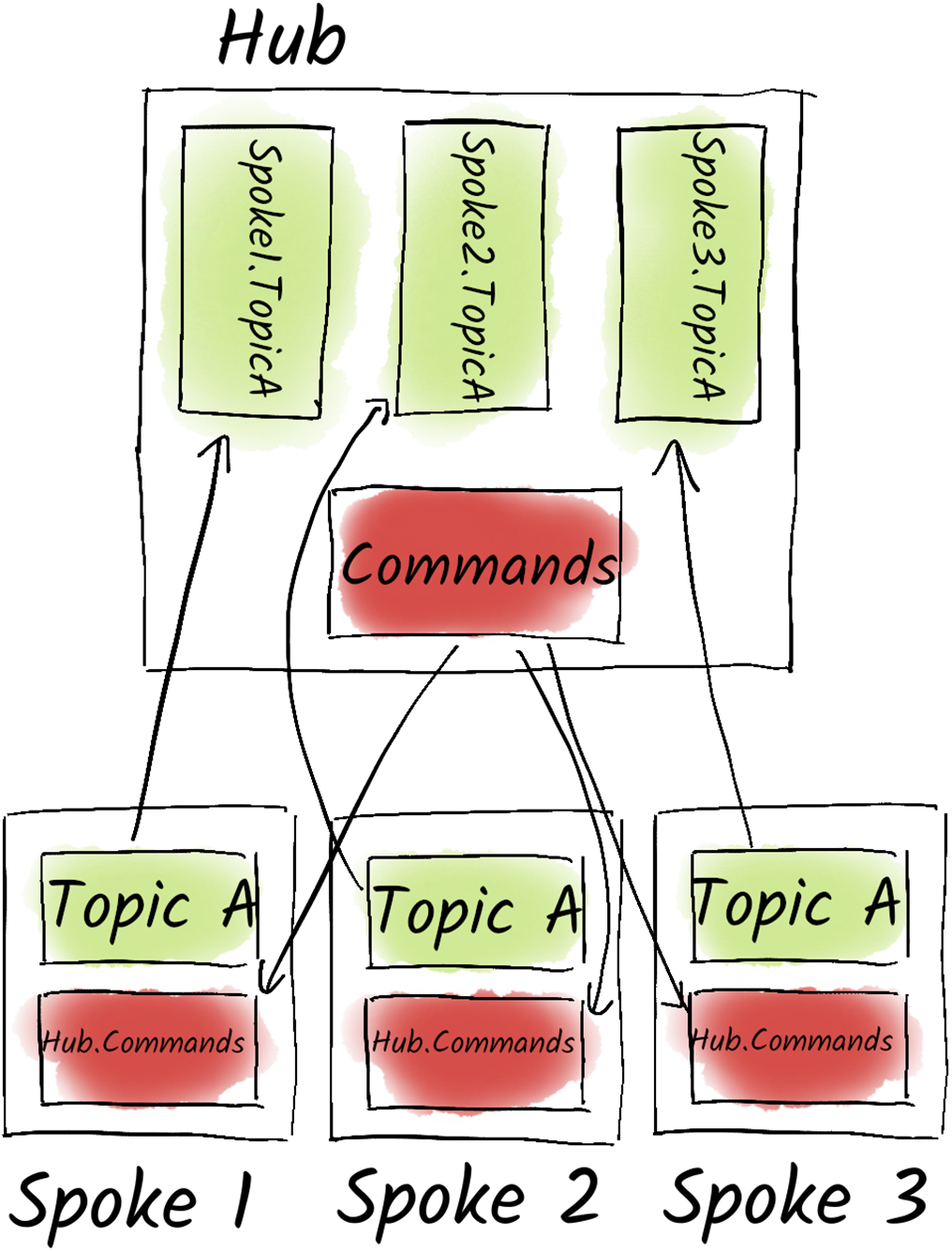
Backup strategies are nuanced: some deployments can re-import from source systems or treat Kafka as transient, while others need stronger recovery plans. Filesystem snapshots are familiar but can be inconsistent across brokers and store redundant replicas; continuous exports via Kafka Connect (for example to object storage) capture data but often miss consumer offsets; tiered storage remains limited for certain topic types and predictability. Mirroring with MirrorMaker 2 provides continuous protection and portability by replicating topics, ACLs, and consumer offsets. Common topologies include active–passive (simple failover but post-event re-seeding complexity), active–active (bi-directional mirroring with remote topics to avoid loops and read-only protections, requiring care to prevent double-processing via idempotence and transactions), and hub-and-spoke (central aggregation plus selective fan-out to edges), enabling resilient operations even under intermittent connectivity.
We need to consider many different failure cases when operating Kafka or other distributed systems.
In a stretched cluster, our Kafka brokers are distributed among multiple data centers.
An Active-Passive cluster with MirrorMaker.
An Active-Active cluster with MirrorMaker 2.
A Hub-and-Spoke Topology which uses MirrorMaker 2 (Kafka Connect) to replicate topics from the spokes to the hub. And replicating the commands topic from the hub to the spokes.
Summary
- Disaster management in Kafka focuses on strategies to handle failures and minimize the likelihood of disasters.
- There are three types of failures in Kafka: network issues, broker problems, and persistent storage failures, often exacerbated by human error.
- Network failures are common in distributed systems. Individual client connection issues can arise, but these are typically resolved quickly.
- Broker issues can lead to data loss if messages are not properly committed before a broker failure. Ensuring acks=all and a sufficient number of in-sync replicas is critical for data delivery assurance.
- Persistent storage failures are one of the most severe problems in Kafka. Ideally, these failures only affect a single broker, but they can lead to irreversible data corruption if not handled properly.
- Conventional backups are not very practical in Kafka due to continuous message production and consumption, which can lead to potential data loss and inconsistencies.
- Stretched clusters reduce the likelihood of total failure by operating a Kafka cluster across multiple data centers, mitigating risks from data center outages.
- An active-passive pairing involves one active cluster mirroring another passive cluster, taking over in case of a failure, but not reverting back to active.
- Active-active pairing consists of two equally capable clusters mirroring each other, allowing continuous operation without needing to rebuild clusters during a failure.
- In active-active configurations, consumers can read from both clusters and need to aggregate data appropriately.
- Remote topics and partitions, introduced in MirrorMaker 2, prevent endless loops of topic mirroring while ensuring seamless data availability during failures.
- The hub-and-spoke topology features a central cluster that aggregates data from smaller local clusters, allowing independent operation even if the central cluster is down.
- Both active-active and hub-and-spoke topologies aim to maintain data consistency even during failures.
- It is recommended to avoid active-passive pairings and prefer active-active configurations for better resilience and performance.
- Confluent Replicator provides a proprietary alternative to MirrorMaker for mirroring clusters.
 Apache Kafka in Action ebook for free
Apache Kafka in Action ebook for free