This introduction explains why modern organizations need to handle data as events in real time and how Apache Kafka addresses that need. As customer expectations and data volumes rise, traditional batch architectures fall short. Kafka provides a durable, distributed log that enables both streaming and replay, scales horizontally for massive throughput, and supports fault tolerance, making it a backbone for event-driven systems across industries. The chapter sets expectations for the book: practical guidance for architects, operators, and developers on using Kafka effectively rather than a language-specific developer manual.
The chapter positions Kafka as the “central nervous system” for enterprise data, where every significant event is published to topics and consumed by downstream systems asynchronously. This model decouples producers and consumers, easing integration between legacy systems and modern services, and supports independently evolving microservices through resilient, event-driven communication. Kafka’s design embraces standard hardware and tolerates component failures, helping organizations transition from batch to real time while maintaining reliability and operational simplicity.
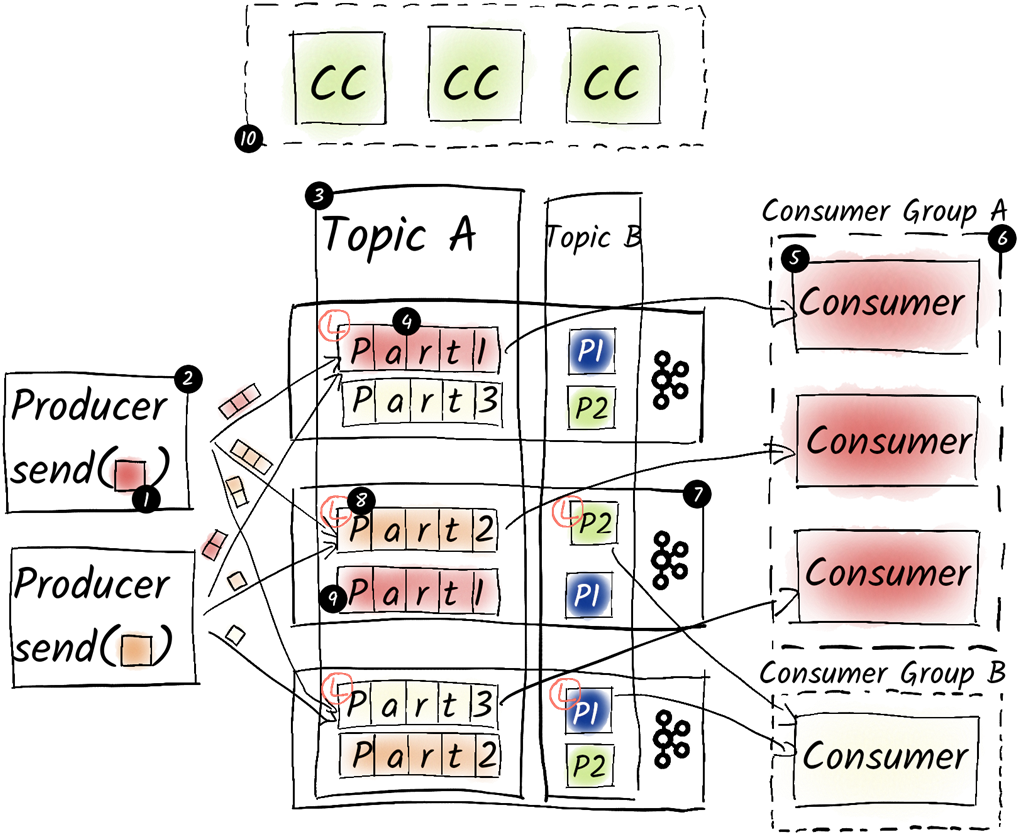
An architectural overview introduces core components—producers, topics, partitions, brokers, leaders and followers, consumers, and consumer groups—and explains how coordination is handled by KRaft (replacing ZooKeeper). Through an example flow (such as bank transfers), the chapter illustrates partitioned parallelism, durable storage, and failover behavior that enable scalable, accurate processing. It closes with guidance on running Kafka: right-sizing infrastructure, planning topics and partitions, building producer/consumer applications, monitoring and operations, and considering managed services alongside in-house expertise. The learning path ahead emphasizes hands-on, step-by-step examples that build practical skills for designing, operating, and integrating Kafka in real-world environments.
Kafka as the central nervous system for data in a company. Every event that takes place in the enterprise is stored in Kafka. Other services can react to these events asynchronously and process them further.
The components of Apache Kafka and the data flow.
Summary
Kafka is a powerful distributed streaming platform operating on a publish-subscribe model, allowing seamless data flow between producers and consumers.
Widely adopted across industries, Kafka excels in real-time analytics, event sourcing, log aggregation, and stream processing, supporting organizations in making informed decisions based on up-to-the-minute data.
Kafka's architecture prioritizes fault tolerance, scalability, and durability, ensuring reliable data transmission and storage even in the face of system failures.
From finance to retail and telecommunications, Kafka finds applications in real-time fraud detection, transaction processing, inventory management, order processing, network monitoring, and large-scale data stream processing.
Beyond its core messaging system, Kafka offers an ecosystem with tools like Kafka Connect and Kafka Streams, providing connectors to external systems and facilitating the development of stream processing applications, enhancing its overall utility.
Kafka can serve as a central hub for diverse system integration.
Producers send messages to Kafka for distribution.
Consumers receive and process messages from Kafka.
Topics organize messages into channels or categories.
Partitions divide topics to parallelize and scale processes.
Brokers are Kafka servers managing storage, distribution, and retrieval.
ZooKeeper/KRaft coordinates and manages tasks in a Kafka cluster.
Kafka ensures data resilience through replication.
Kafka scales horizontally by adding more brokers to the cluster.
Kafka can run on general purpose hardware.
It is implemented in Java and Scala but there also exist clients for other programming languages as for example Python.
FAQ
What is Apache Kafka and why is it relevant today?Apache Kafka is an open-source distributed streaming platform that serves as a persistent, distributed log for data events. It enables organizations to handle high-volume, real-time data flows, supporting both immediate processing and reliable replay. This helps companies meet modern expectations for instant responses and continuous data-driven operations.How does Kafka act as the “central nervous system” for enterprise data?Kafka stores business events from across the enterprise in topics, allowing services to publish (produce) and subscribe (consume) asynchronously. By centralizing events, it decouples systems, lets teams evolve services independently, and enables real-time reactions without brittle point-to-point integrations.What problems does Kafka solve compared to batch processing and point-to-point integrations?Kafka addresses real-time processing needs, reducing delays inherent in batch systems. It avoids the complexity and fragility of point-to-point connections by providing a scalable, durable event backbone, enabling independent team deployments and reliable data flow across many services.How does Kafka’s publish-subscribe (producer-consumer) model work, and what sets it apart?Producers write messages to topics; consumers read them as needed. Unlike many traditional messaging systems, Kafka persists data for configurable periods, so multiple consumers can read the same data at different times and systems can replay history after failures or for new use cases.What are the core components of Kafka’s architecture?Key elements include messages (records), producers, topics, partitions, consumers, consumer groups, brokers, leaders, followers (replicas), and a coordination layer (KRaft). Together they provide horizontal scalability, fault tolerance, and efficient parallel processing of data streams.What are topics and partitions, and why are partitions important?Topics group related messages, similar to tables in a database. They are split into partitions to enable parallelism and scale. Partitions are replicated across brokers for resiliency, and a leader handles reads/writes while followers replicate data for failover.How do consumer groups provide scalable and fault-tolerant processing?A consumer group shares the workload of a topic’s partitions so that each partition is processed by exactly one consumer in the group. This enables parallel processing and, if a consumer fails, the remaining consumers in the group take over, ensuring continuity.What is KRaft and how does it differ from ZooKeeper?KRaft is Kafka’s built-in coordination layer based on the Raft protocol, replacing the need for an external ZooKeeper ensemble. It simplifies operations and improves scalability by keeping coordination inside Kafka itself.What do I need to run Kafka effectively?You need a set of servers (brokers) with low-latency, high-bandwidth networking, appropriate topic and partition design, well-built producer/consumer applications, and comprehensive monitoring and management. Kafka runs on the JVM (JRE required) and offers clients for languages like Java, Scala, and Python.Should I self-manage Kafka or use a managed service?Self-managing is possible but operationally demanding. Managed options include AWS MSK, Azure HDInsight, and specialized providers like Confluent and Aiven; Kafka-compatible platforms such as Redpanda and Warpstream also exist. Regardless of choice, in-house expertise is still essential to succeed with streaming architectures.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!

 Apache Kafka in Action ebook for free
Apache Kafka in Action ebook for free