1 Setting the stage for offline evaluations
AI systems now shape many product experiences, from recommendations and search to chatbots, computer vision, forecasting, and agentic workflows. The chapter introduces offline evaluations as a foundational practice for understanding whether an AI model, LLM-powered feature, agent, or even a simple heuristic is likely to improve a product before it reaches users. Offline evaluation is framed as a model’s first reality check: a way to test quality, relevance, accuracy, safety, and expected impact using pre-collected data rather than live user traffic.
The chapter explains how offline evaluations fit into the AI product development lifecycle. Teams typically move from ideation and model development into offline evaluation, then, if results are promising, into online experimentation such as A/B testing and eventual rollout. Offline evaluations help teams iterate faster, compare model versions consistently, catch underperforming candidates early, and reduce the risk of exposing users to degraded experiences. They rely heavily on representative data, including historical logs, validation data, holdout datasets, and sometimes synthetic data, while also requiring careful attention to stale data, data drift, biased logs, and whether offline metrics actually reflect real product behavior.
A central theme is that metric selection is contextual and should match the product goal. Recommendation systems may need Precision@K, Recall@K, NDCG, diversity, or coverage; LLM features may require groundedness, relevance, factuality, or instruction following; agents may need task completion, tool-call accuracy, or constraint adherence. The chapter also distinguishes between standardized evaluations for comparing model versions and deeper diagnostic evaluations that inspect behavior across user segments, content types, prompts, workflows, and edge cases. While offline evaluations are valuable for prototyping, monitoring, production observability, and informing A/B testing strategy, the chapter cautions that they cannot fully replace online evaluations, especially when real user behavior, feedback loops, UX dynamics, or long-term product effects matter.
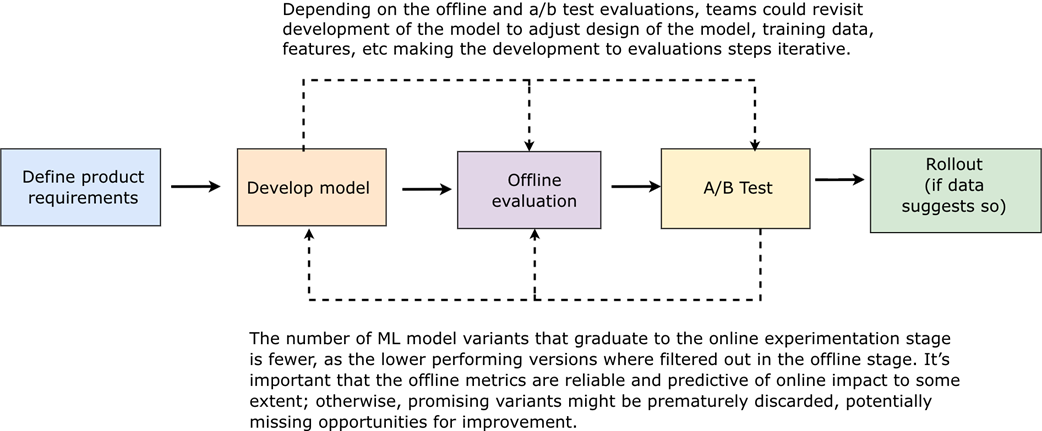
What the development lifecycle looks like in practice for a feature that relies on an AI model. The process moves left to right through five stages: defining product requirements, developing the model, offline evaluation, A/B testing, and a conditional rollout. However, it is rarely as linear as it appears. Notice that evaluation is not a single event: offline evaluation lets teams iterate quickly using historical data, catching problems cheaply before deployment, while the A/B test validates whether those improvements translate to real user impact. The final stage being conditional on data ('if data suggests so') reflects how seriously teams should treat online results as a go/no-go signal.
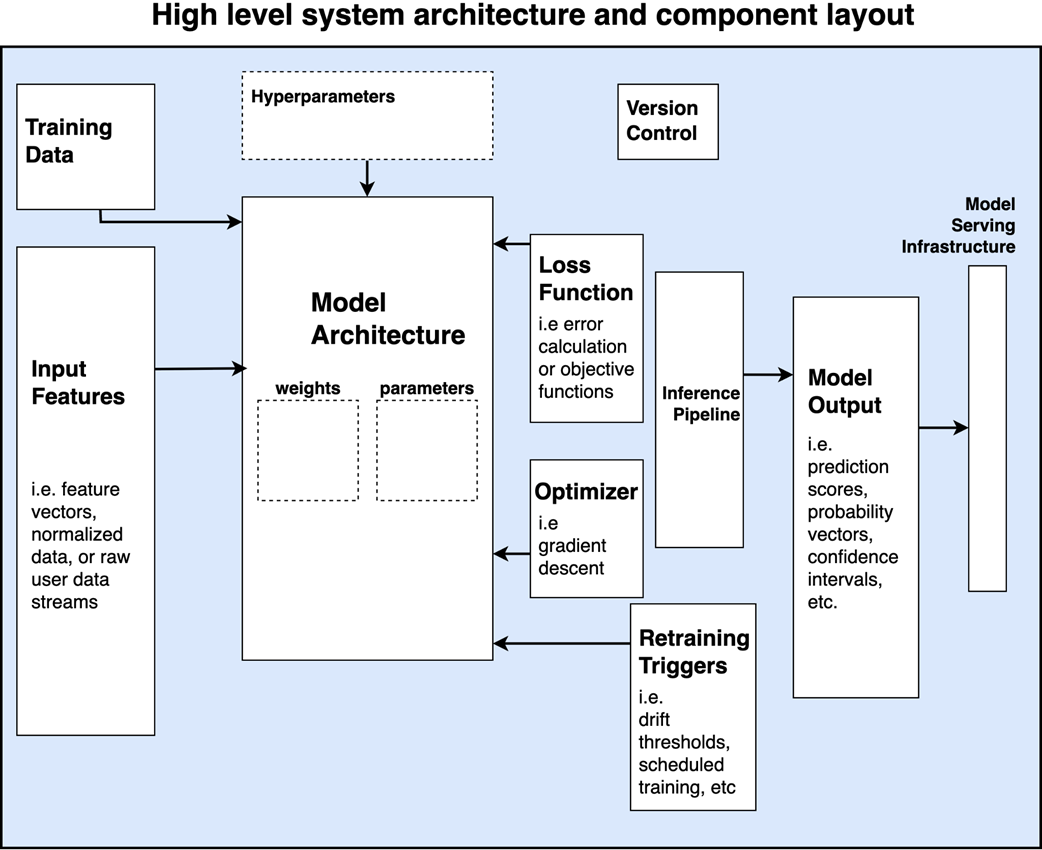
A high level conceptual overview of AI systems in an industry setting. The diagram illustrates the key components typically required to build and deploy an AI model. Starting from left to right, input features and training data are closely linked, as both are fed into the model. The model architecture, which is the core of the system, includes trainable weights and other configuration parameters. Hyperparameters, which are not trainable, are used to define the learning process. The loss function guides model training by measuring error, while the optimizer (e.g., gradient descent) updates the weights based on this feedback. Operational and deployment components include the inference pipeline, model output (such as prediction scores and confidence intervals), version control, and model serving infrastructure.
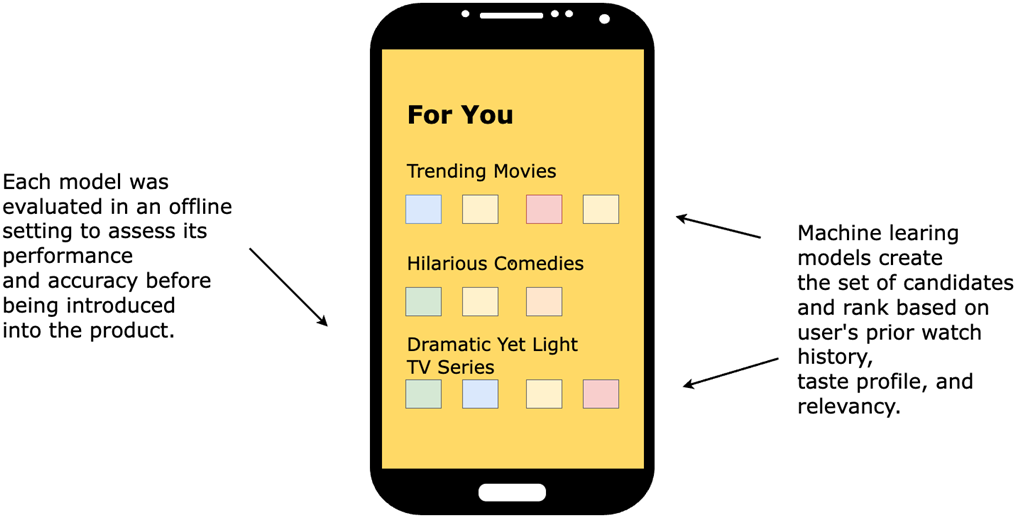
Streaming app utilizing machine learning models to recommend the most relevant content for a user to watch. Each model is evaluated offline using metrics that can assess accuracy, relevancy and overall performance of the items and rank produced by the model.
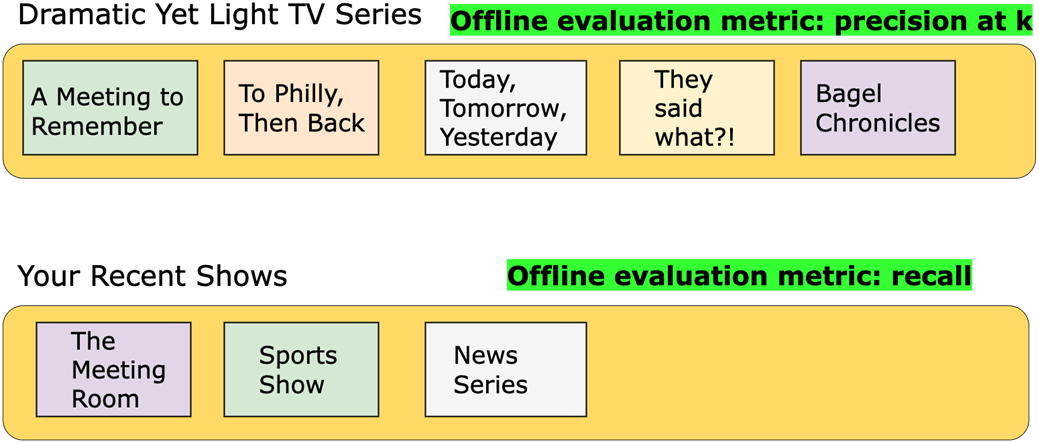
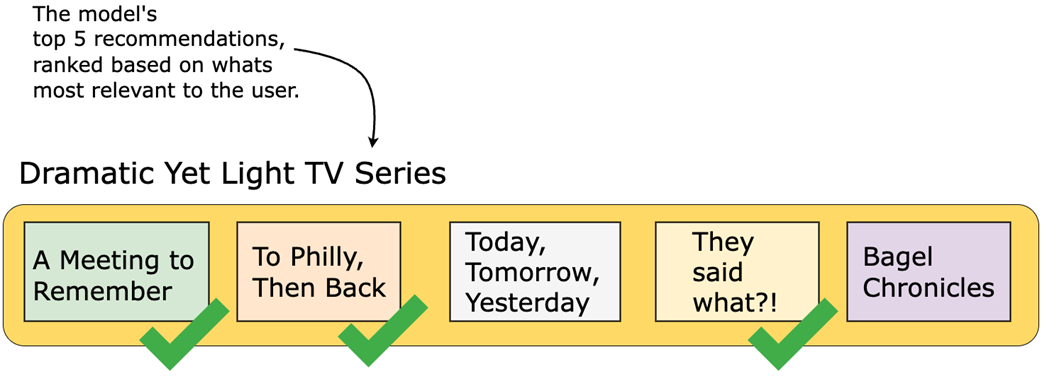
Differing offline metrics for each recommendation scenario. The Dramatic Yet Light Movies recommendation model uses Precision at K (P@K) to ensure that the top movies in the list are highly relevant movies for the user. The Your Recent Shows model relies on recall as the metric to optimize in an offline setting, as it focuses on ensuring the system retrieves all relevant past TV shows to give customers a complete and personalized experience.
Which metric to optimize toward depends on the use case. Consider Precision@K, a common offline evaluation metric for ranking applications. In this example, five TV shows are recommended to a user, and three of them are considered relevant based on prior watch history or labeled preference data. The Precision at 5, or P@5, would be 3/5, or 60%.
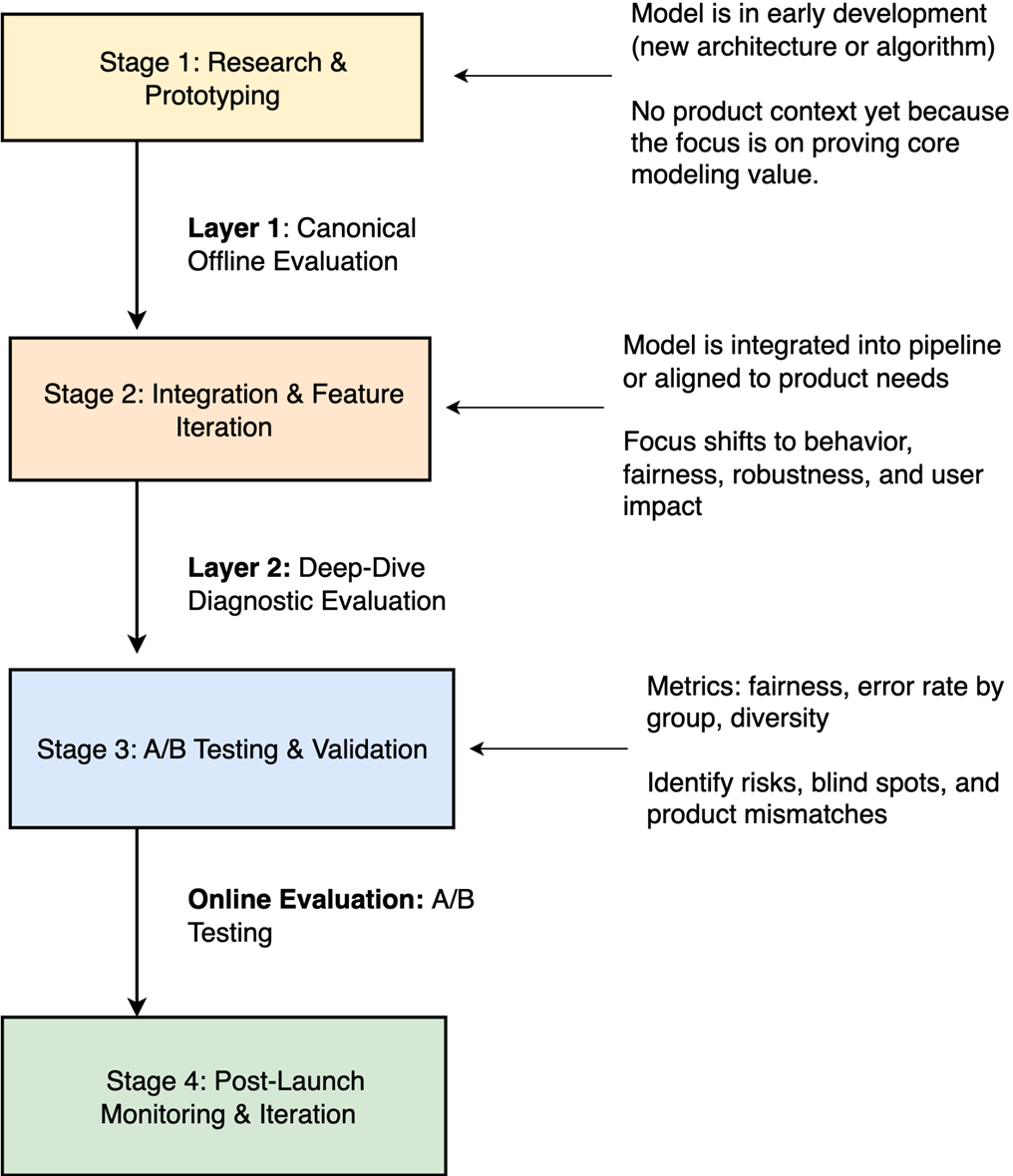
Illustrates how canonical offline evaluations, deep-dive diagnostics, and A/B testing each align with different stages of the model development lifecycle, from early prototyping to post-launch iteration. Each layer plays a distinct role in validating both the technical soundness and real-world impact of machine learning models.
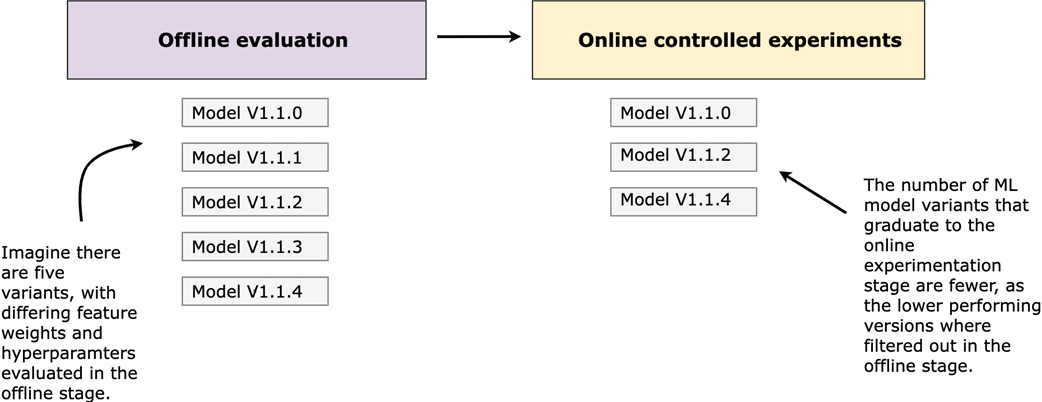
Leveraging offline evaluations to inform online experimentation strategy results in considerable optimizations. By reducing the number of model variants that graduate to the online experimentation stage, you're reducing the sample size for the A/B test, freeing up testing capacity for other A/B tests to run on the product and being more strategic with the changes you're exposing users to.
Summary
- Offline evaluations involve testing and analyzing a model's performance using historical or pre-collected data without exposing the model for real users to engage with in a live production environment.
- When iterating on a machine learning model, it's so important to gain as much insight into the impact or effect as possible before it's available in a product-user-facing setting. This is exactly what offline evaluations aim to do!
- The various offline metric categories and example metrics that ladder up to each category include Ranking Metrics and Classification Metrics.
- Recommender systems, search engines, fraud detection models, language translation systems, and predictive maintenance algorithms are typical real-world applications that benefit from offline evaluations. Offline evaluations allow such applications to be rigorously tested without exposing iterations to users, enabling teams to measure accuracy and relevancy before deploying changes to production.
- The more insight gained from an offline evaluation, the better decisions you make in the online controlled experiment phase.
- Offline evaluations become particularly powerful as a monitoring tool. By running your offline evaluation pipeline against freshly collected production logs on a regular cadence, you can track whether model quality is holding steady, improving, or declining without waiting for an A/B test to tell you something has gone wrong. The data comes from production, but the evaluation methodology remains offline.
- Correlating offline and online results enables more efficient model iterations by using offline evaluations to predict online performance, streamlining refinement and adjustments before exposing real users to the model changes.
- The product development lifecycle as it pertains to AI models and how offline evaluations are a key step in understanding impact and effectiveness. It's important to understand the complexities of integrating AI systems and to mitigate risks by using offline evaluations.
FAQ
What are offline evaluations in AI model development?
Offline evaluations are a methodology for estimating the effect of a model or product change without exposing it to real users in a live production environment. They typically use historical or pre-collected data to evaluate whether a model is likely to improve quality, accuracy, relevance, ranking, groundedness, or another product-specific goal before moving to an online experiment such as an A/B test.
Why are offline evaluations important before exposing a model to users?
Offline evaluations act as a model’s first reality check. They help teams identify underperforming models, catch bugs, compare model versions, and reduce the risk of degrading the user experience before a model reaches production. They are especially valuable because real-world data is messy, product systems are complex, and benchmark performance alone does not guarantee that a model will behave well in a live user-facing product.
How do offline evaluations differ from online evaluations or A/B tests?
Offline evaluations use static, pre-collected data and do not affect real users. Online evaluations, usually A/B tests, happen in production, where real users interact with the new model or product change. Offline evaluations help estimate potential impact and filter out weak candidates, while A/B tests measure actual behavioral impact on user, product, and business metrics.
Where do offline evaluations fit in the AI product development lifecycle?
In the model product development lifecycle, offline evaluations usually occur after ideation and model development but before A/B testing and rollout. They provide the first layer of quantitative validation, allowing teams to iterate quickly using historical data. If offline results are promising, the model may move to online experimentation; if results are negative or inconclusive, the team may refine the model before exposing it to users.
What kinds of data are used for offline evaluations?
Offline evaluations commonly rely on historical production data, such as past user behavior, system decisions, labels, outcomes, interactions, and logged model outputs. Teams often split this data into training, validation, and holdout datasets. Training data is used to teach the model, validation data supports tuning and iteration, and holdout data provides a more independent benchmark for assessing model performance. Synthetic data may also be used carefully to test rare cases or new experiences, but it should not be treated as a perfect substitute for real production data.
Why is representative data so important for offline evaluations?
Offline metrics are only useful if the evaluation data reflects the real-world product scenarios where the model will be deployed. If the data is stale, biased, incomplete, or no longer representative of user behavior, offline evaluations can be misleading. Data drift, changing product surfaces, updated inventories, and evolving user behavior can all cause a model that performs well offline to struggle in production.
How should teams choose the right offline metric?
The right offline metric depends on the product context, the model’s role, and what the system is supposed to accomplish. For example, a recommender ranking movies might use Precision@K, Recall@K, NDCG@K, diversity, or coverage. An LLM-generated recommendation explanation may require relevance, groundedness, factuality, or instruction-following metrics. Metric selection is not just a technical decision; it is a product decision that should align with user experience and business goals.
What does “@K” mean in metrics like Precision@K or Recall@K?
“@K” means the metric is evaluated over the top K results returned by the model. For example, Precision@5 asks how many of the top five recommended items are relevant. This is useful because users are most likely to see and interact with the highest-ranked results, not items buried far down a list.
What are the two layers of offline evaluations?
The chapter describes two complementary layers: canonical offline evaluations and deep-dive diagnostic evaluations. Canonical offline evaluations use a fixed dataset, consistent setup, and clearly defined metrics to compare model versions. Deep-dive diagnostic evaluations look more closely at model behavior across slices, segments, scenarios, users, content, query types, or edge cases. Canonical evaluations answer whether a model improved overall, while diagnostics help explain where and why it succeeds or fails.
Can offline evaluations replace A/B testing?
No. Offline evaluations are valuable, but they do not replace online evaluations. They help teams filter poor model candidates, understand likely performance, and improve confidence before launch. However, they cannot fully capture real user behavior, feedback loops, UX effects, or live production dynamics. A/B testing remains necessary for measuring actual impact on users and business metrics.
 AI Model Evaluation ebook for free
AI Model Evaluation ebook for free