1 Introduction to AI agents and applications
Large language models now underpin a wide range of software, from question answering and summarization to tool coordination and decision-making with AI agents. Despite varied use cases, most systems share a common pattern: accept natural language, enrich it with context, and prompt a model to produce useful output. Building reliable products introduces recurring challenges—data ingestion, prompt design, orchestration, evaluation, and cost control—which modern frameworks such as LangChain, LangGraph, and LangSmith address through modular abstractions and proven practices.
LLM-powered solutions cluster into three archetypes. Engines deliver focused capabilities like summarization and search; Q&A engines typically use Retrieval-Augmented Generation, transforming documents into embeddings stored in vector databases to ground answers in retrieved context. Chatbots add dialogue management, memory, role instructions, and optional retrieval to maintain coherent, safe, and adaptive conversations. Agents represent the most advanced class: they plan and execute multi-step workflows, choose and invoke tools and services, integrate structured and unstructured data, and can incorporate human-in-the-loop safeguards. Emerging standards such as the Model Context Protocol simplify tool integration and expand an agent’s reachable capabilities.
To build these systems effectively, LangChain offers a composable architecture—document loaders, text splitters, embedding models, vector stores, retrievers, prompt templates, model interfaces, caching, and output parsers—wired consistently via the Runnable interface and LCEL, and extended to graph-shaped flows with LangGraph for agentic control. The chapter outlines core adaptation techniques (prompt engineering, RAG, and fine-tuning) and guidance for model selection across accuracy, latency, and cost trade-offs. It also previews a hands-on path: constructing engines and chatbots, advancing to agents with LangGraph, deep-diving into RAG, and instrumenting with LangSmith—equipping you to design, evaluate, and scale production-grade AI applications.
A summarization engine efficiently summarizes and stores content from large volumes of text and can be invoked by other systems through REST API.
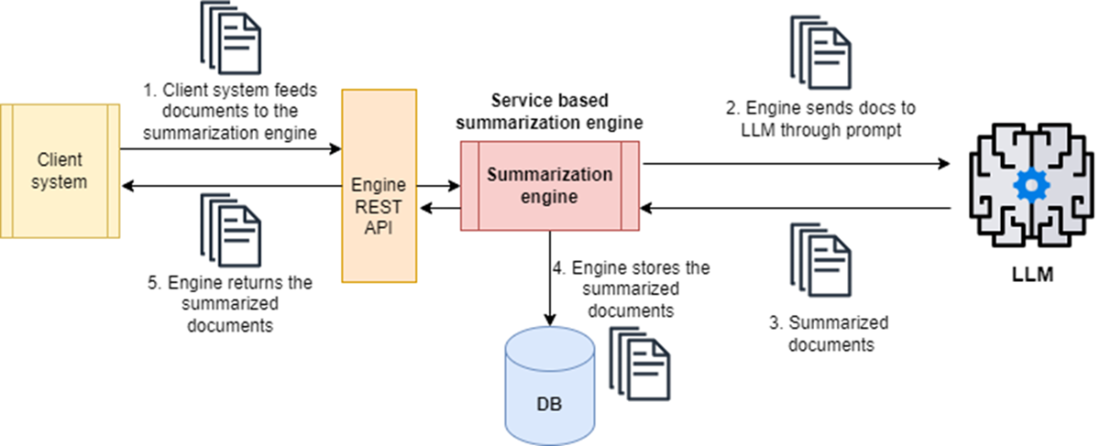
A Q&A engine implemented with RAG design: an LLM query engine stores domain-specific document information in a vector store. When an external system sends a query, it converts the natural language question into its embeddings (or vector) representation, retrieves the related documents from the vector store, and then gives the LLM the information it needs to craft a natural language response.
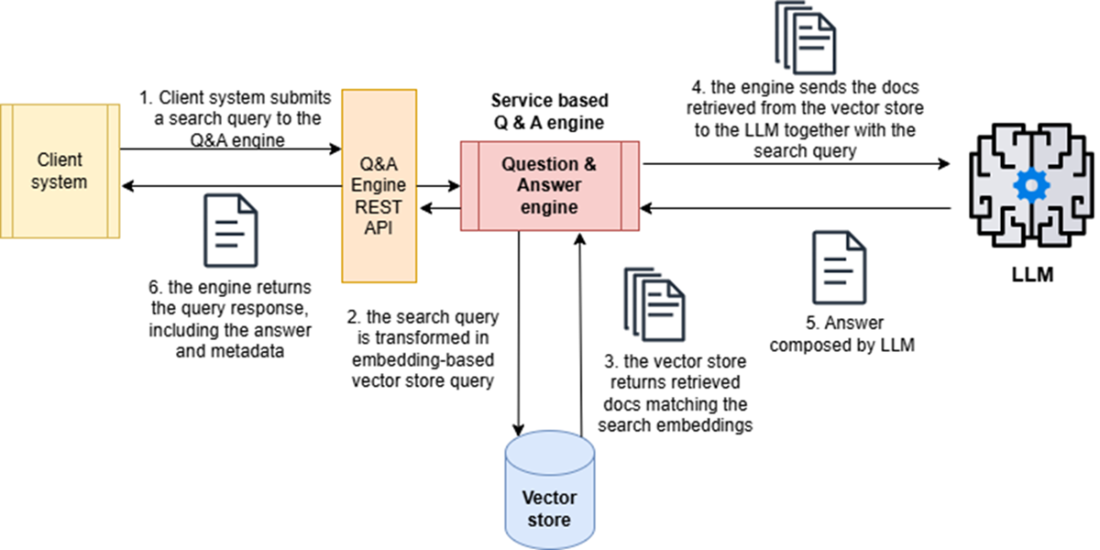
A summarization chatbot has some similarities with a summarization engine, but it offers an interactive experience where the LLM and the user can work together to fine-tune and improve the results.
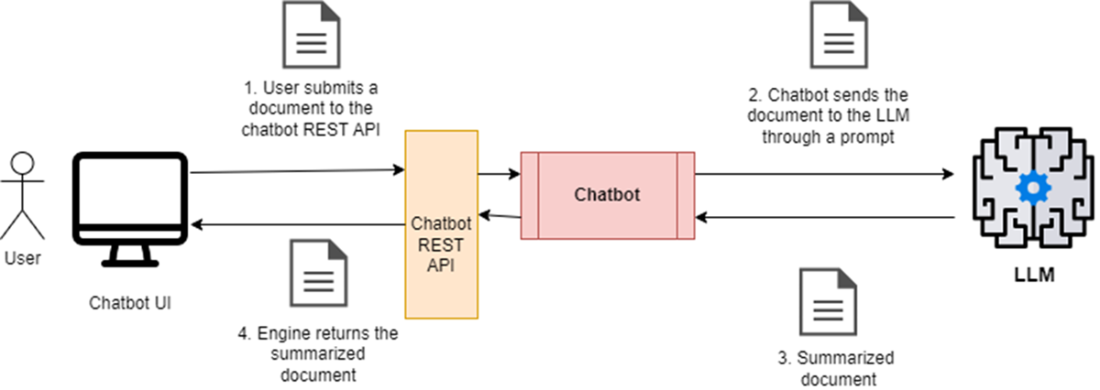
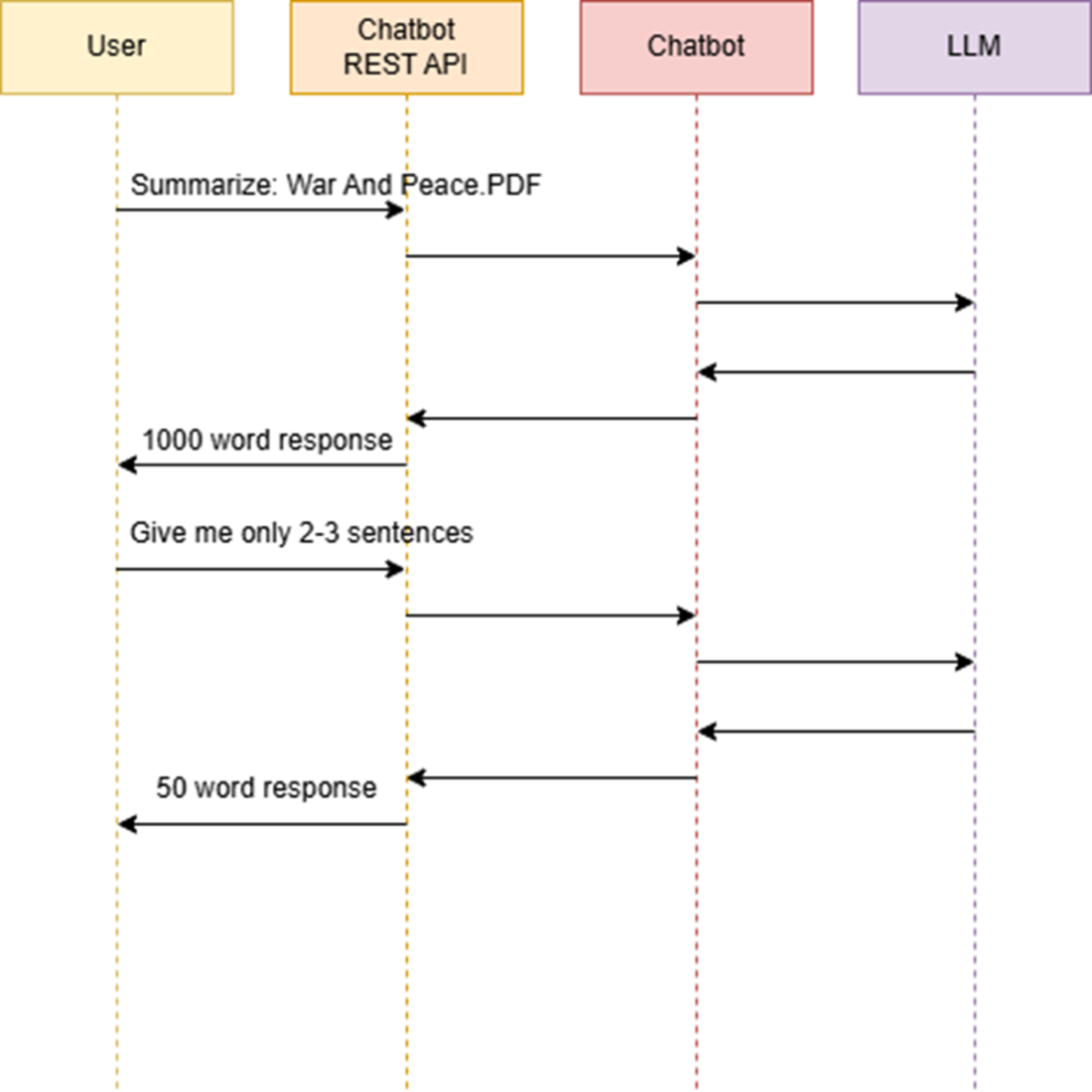
Sequence diagram that outlines how a user interacts with an LLM through a chatbot to create a more concise summary.
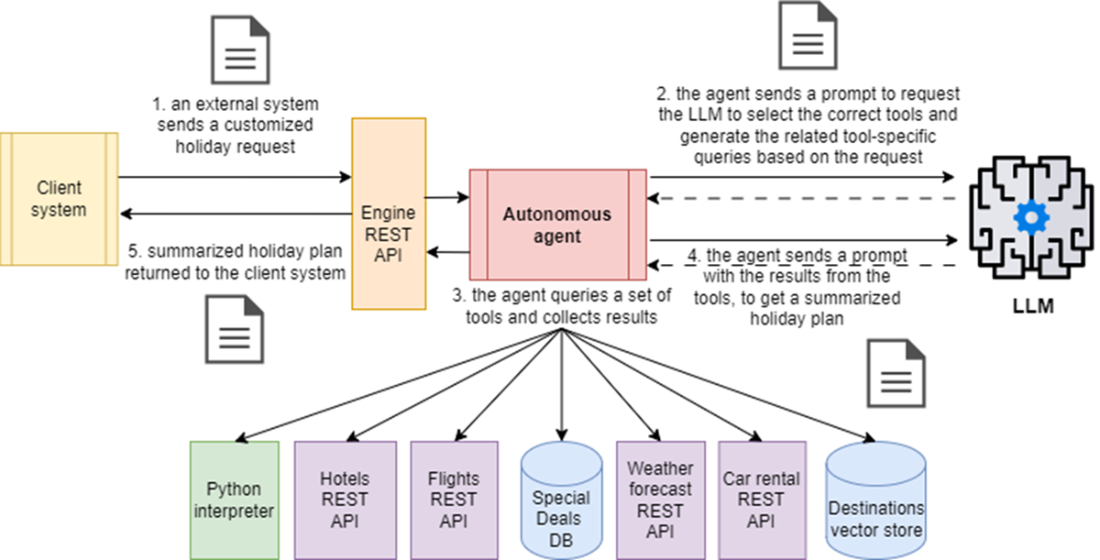
Workflow of an AI agent tasked with assembling holiday packages: An external client system sends a customized holiday request in natural language. The agent prompts the LLM to select tools and formulate queries in technology-specific formats. The agent executes the queries, gathers the results, and sends them back to the LLM, along with the original request, to obtain a comprehensive holiday package summary. Finally, the agent forwards the summarized package to the client system.
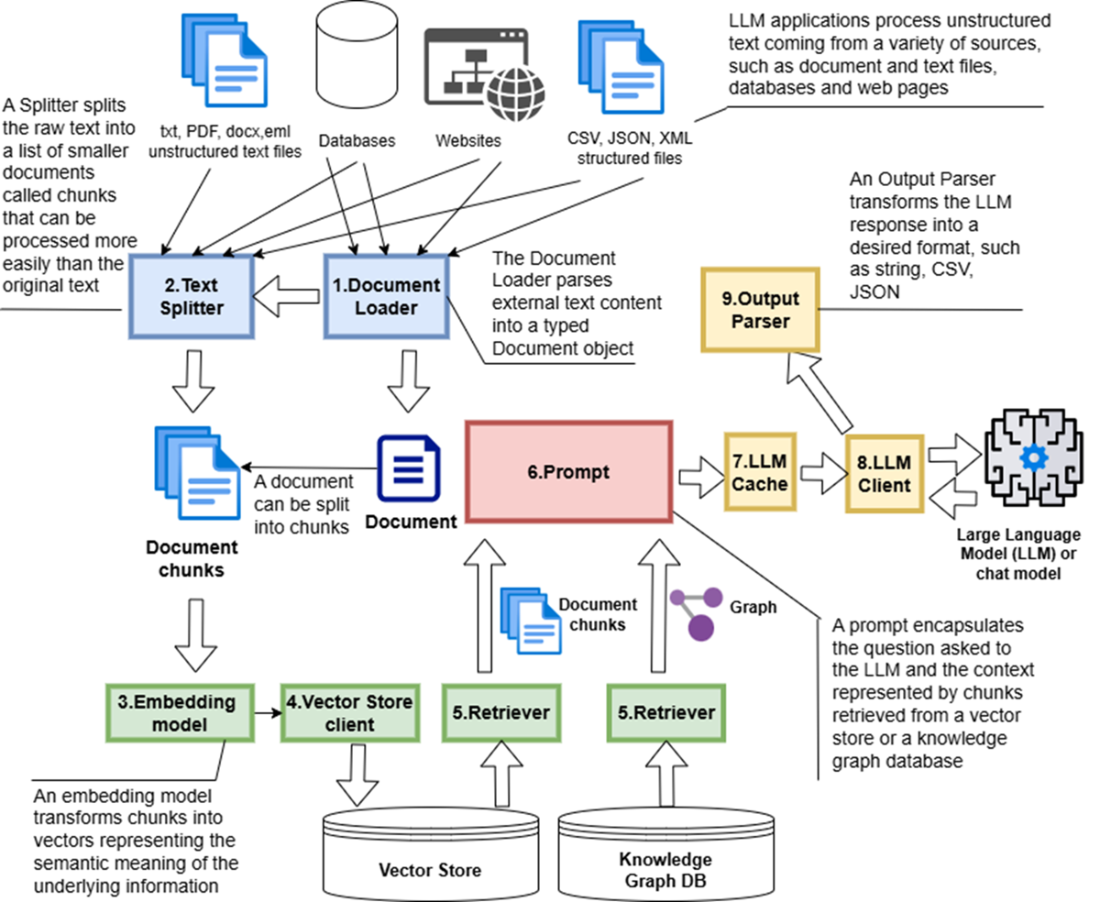
LangChain architecture: The Document Loader imports data, which the Text Splitter divides into chunks. These are vectorized by an Embedding Model, stored in a Vector Store, and retrieved through a Retriever for the LLM. The LLM Cache checks for prior requests to return cached responses, while the Output Parser formats the LLM's final response.
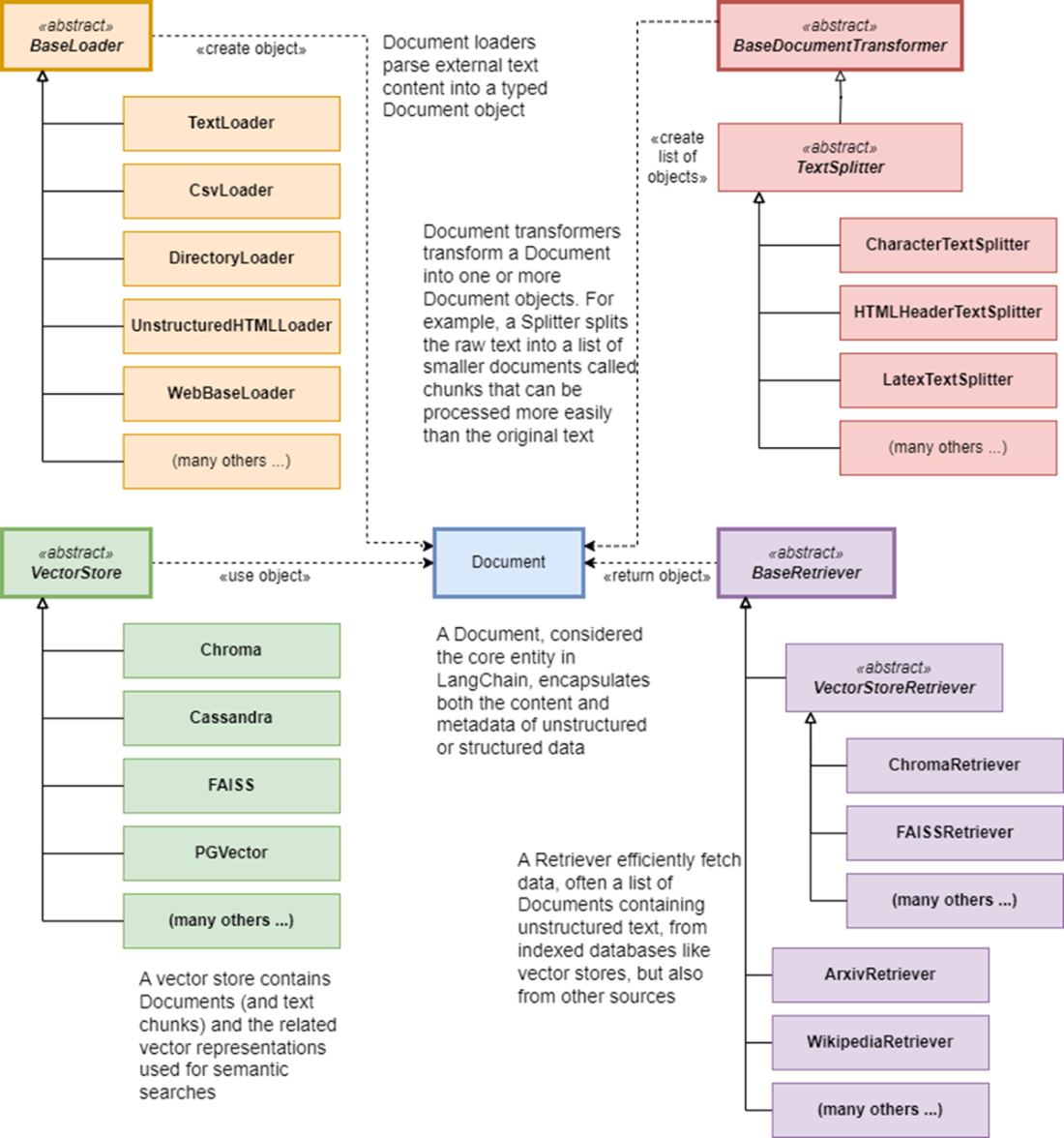
Object model of classes associated with the Document core entity, including Document loaders (which create Document objects), splitters (which create a list of Document objects), vector stores (which store Document objects in vector stores) and retrievers (which retrieve Document objects from vector stores and other sources)
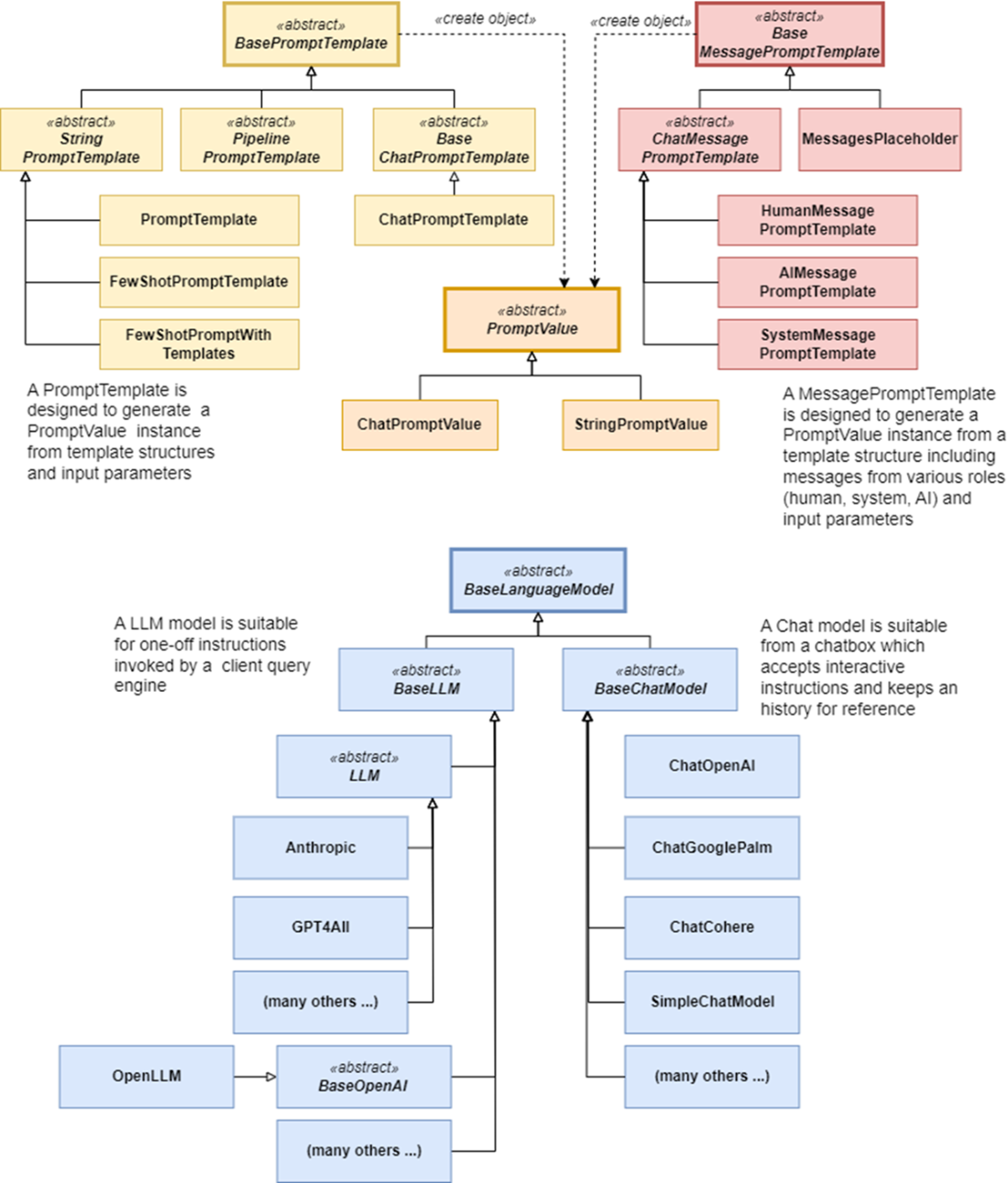
Object model of classes associated with Language Models, including Prompt Templates and Prompt Values
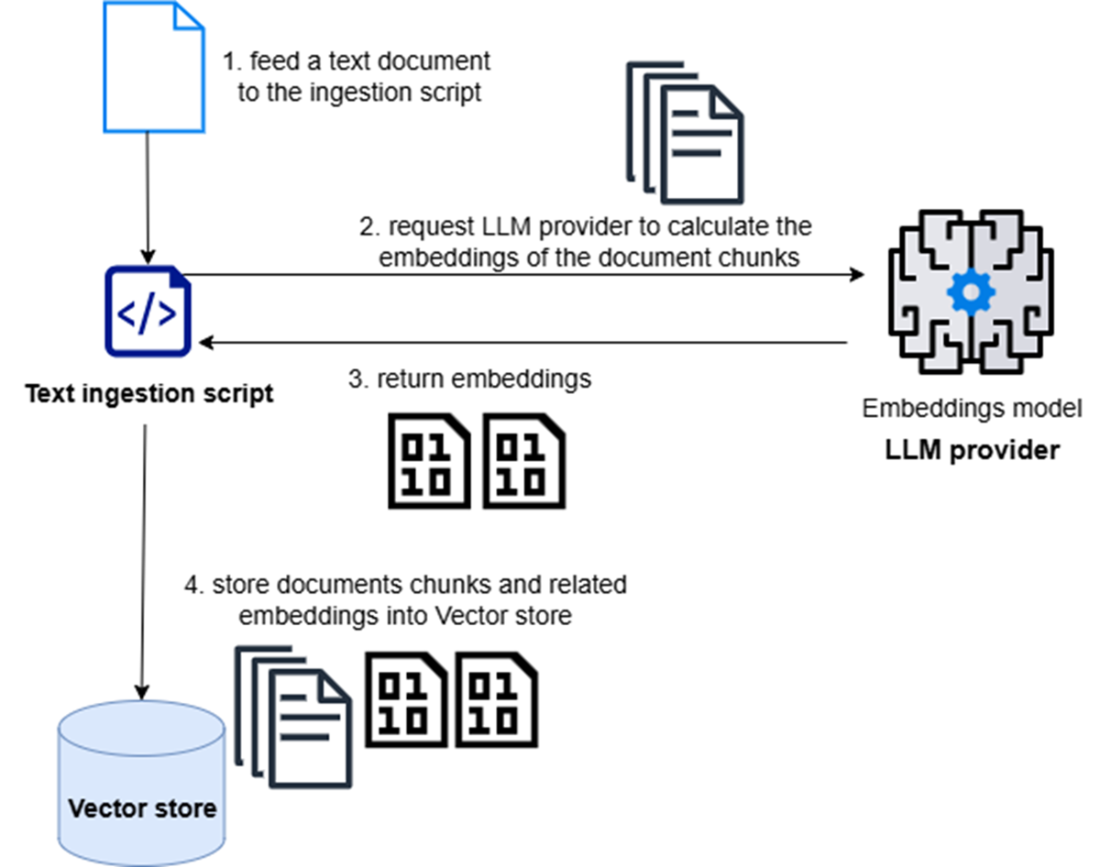
A collection of documents is split into text chunks and transformed into vector-based embeddings. Both text chunks and related embeddings are then stored in a vector store.
Summary
- LLMs have rapidly evolved into core building blocks for modern applications, enabling tasks like summarization, semantic search, and conversational assistants.
- Without frameworks, teams often reinvent the wheel—managing ingestion, embeddings, retrieval, and orchestration with brittle, one-off code. LangChain addresses this by standardizing these patterns into modular, reusable components.
- LangChain’s modular architecture builds on loaders, splitters, embedding models, retrievers, and vector stores, making it straightforward to build engines such as summarization and Q&A systems.
- Conversational use cases demand more than static pipelines. LLM-based chatbots extend engines with dialogue management and memory, allowing adaptive, multi-turn interactions.
- Beyond chatbots, AI agents represent the most advanced type of LLM application.
- Agents orchestrate multi-step workflows and tools under LLM guidance, with frameworks like LangGraph designed to make this practical and maintainable.
- Retrieval-Augmented Generation (RAG) is a foundational pattern that grounds LLM outputs in external knowledge, improving accuracy while reducing hallucinations and token costs.
- Prompt engineering remains a critical skill for shaping LLM behavior, but when prompts alone aren’t enough, RAG or even fine-tuning can extend capabilities further.
 AI Agents and Applications ebook for free
AI Agents and Applications ebook for free