1 Making our First Image: “A damn fine cup of coffee”
This chapter welcomes readers into text-to-image creation with Stable Diffusion by pairing clear prompting with practical tooling. It frames the journey as moving from unpredictable, “wonderful and strange” results toward intentional, repeatable outcomes by learning how to communicate with the model, iterate quickly, and make informed adjustments. The focus is on using the AUTOMATIC1111 WebUI to generate images, while introducing core skills: crafting effective prompts, managing image dimensions and aspect ratios, and controlling randomness for reproducibility.
After a brief orientation to the A1111 interface and the txt2img workflow, the chapter uses a coffee-themed example to demonstrate the mechanics of generation. It shows how to produce many candidates efficiently via batch count (sequential) and batch size (parallel), explains the VRAM trade-offs of larger batch sizes, and emphasizes volume as a simple but powerful tactic for finding strong images. The role of seeds is made explicit: a seed of -1 yields new randomness each run, while fixed seeds enable exact reproduction and fair comparison of setting changes. A short primer on pseudo-random number generators clarifies why seed control is essential for consistent experimentation.
Prompt engineering is presented as an iterative, search-like process where clarity outperforms poetic phrasing. The chapter illustrates how adding concrete details (e.g., scene context) and specifying style descriptors can steer the model away from the uncanny and toward desired aesthetics. It also shows how width and height—constrained to model-friendly multiples—change composition and subject framing, and warns that extreme aspect ratios often degrade results. The overarching workflow is to fix a seed, adjust aspect ratio to suit the subject, generate batches, and refine the prompt with clear, descriptive terms and stylistic guidance—culminating in a satisfying, stylistically coherent image that fits the intended mood.
Stable Diffusion sure can create strange things, let’s try to avoid going too far in that direction.

Image of the upper portion of the A1111 UI.
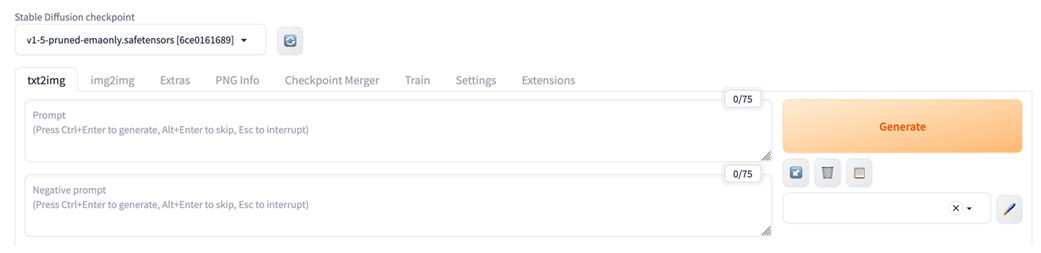
Entering our prompt into A1111
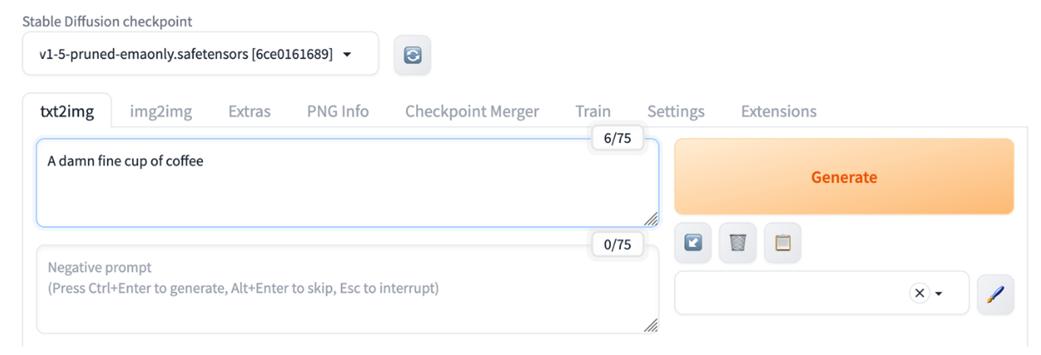
The initial image created by our prompt: “A damn fine cup of coffee.”

Batch count and Batch size theoretically offer different ways to increase images generated

One configuration for generating 30 images at once.

30 different answer to the prompt “A damn fine cup of coffee”

Setting the value to -1 will give us a ‘random’ seed each time we hit ‘Generate’.
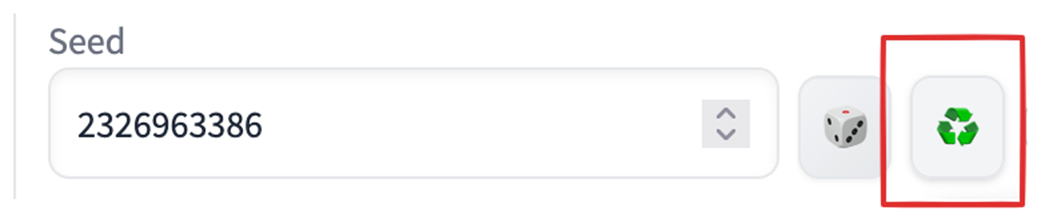
The recycle button will give us the seed we used previously.
The options for setting our Width and Height in the UI.

Images with a 5:3 landscape aspect ratio.

Using the same seed but reverting to 512x512 shows us the impact of aspect ratio and image size.

We can easily swap Width and Height values in A1111.

Images with a 3:5 aspect ratio .

Images with a 3:7 aspect ratio.

Images with a 4:1 aspect ratio.

A poetic prompt does not always yield poetic images.

A straight forward prompt yields more cups of black coffee.

Adding a scene to an image can help provide context.

Choosing a landscape aspect ratio helps display the counter.

Creating surrealistic images.

Images in the style of a wood etching.

I would say that’s a damn fine cup of coffee!

Summary
- Generating with Stable Diffusion is an iterative process, in which we are constantly revising our settings and prompts.
- Despite the many ways to improve images, it’s always a good idea to generate a variety of images to see if we find a particular one that stands out to us as pleasing.
- Our prompts should be clear and descriptive. Giving some context for the object we’re prompting can change the image dramatically. Describing the style of the image can further let us change the feeling of the images we’re generating.
- The aspect ratio that we use to generate an image can have a major impact on the way the image looks. Consider whether the image you want to create would look better as a square, a landscape or portrait.
 A Damn Fine Stable Diffusion Book ebook for free
A Damn Fine Stable Diffusion Book ebook for free