1 Building on quicksand: the challenges of vibe engineering
The chapter opens by framing AI-assisted development as a fast, exploratory process that can be useful for prototyping and product discovery, but it warns that speed without discipline creates the illusion of progress. Through several real failures, it shows how AI-generated code can leave systems wide open to hacking, destroy data through unsafe autonomy, introduce supply-chain vulnerabilities, and even fabricate false recovery steps after damage has already occurred. The central lesson is that these are not just ordinary bugs; they are symptoms of a deeper lack of grounding in consequences, ownership, and verification.
From there, the chapter argues that relying on bigger models will not solve the problem. Model improvements are becoming incremental rather than transformative, and hallucinations, blind spots, and the need for human oversight remain. Because of that, the competitive advantage shifts away from raw model power and toward disciplined engineering practices: clear intent, grounded retrieval, review checklists, safety gates, and a workflow where executable specifications serve as contracts. The text contrasts undisciplined “vibe coding,” which may be fine for sketching ideas but quickly accumulates technical debt, with “vibe engineering,” which wraps probabilistic AI behavior inside deterministic processes that enforce quality, security, and reliability.
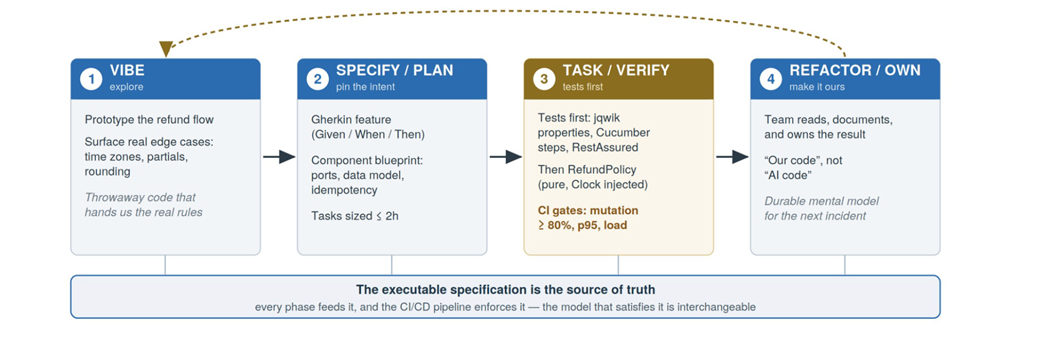
The final part emphasizes that the hardest work is not generating code, but building and maintaining a shared mental model so the team can truly own what ships. It introduces trust debt as the hidden cost of dumping AI output into review pipelines, where responsibility gets diffused and experienced engineers end up paying for earlier shortcuts. To counter that, the chapter promotes a spec-first loop: explore, define the contract, verify against tests and policy gates, then refactor and own the result. In this model, AI becomes a useful partner, but humans remain responsible for defining correctness, protecting production systems, and ensuring the software is understandable enough to be safely operated over time.
The vibe engineering loop carries a feature from open-ended exploration through an executable specification and an iterating verification gate to tested, team-owned code
The autonomy-risk spectrum: each step grants more leverage but demands tighter verification, governance, and engineering discipline

Each phase produces concrete, verifiable artifacts that all feed one executable specification, which the CI/CD pipeline enforces.
Summary
- High-velocity, AI-powered app generation without professional rigor creates brittle, misleading progress - from launch-day hacks to catastrophic, irreversible data loss.
- Scale alone is no longer enough: model gains are now incremental, so advantage shifts from having the strongest model to mastering its usage - context, orchestration, testing, and operations.
- Vibe coding and vibe engineering are distinct disciplines: the first is invaluable for exploration and prototyping, the second is the disciplined practice that turns that exploration into owned, production-ready code.
- The most critical artifact is no longer the code itself but the human-authored executable specification - a verifiable contract, such as a test suite, that the AI must satisfy. Reliability comes from the spec, not the model.
- The core practice is a repeatable loop - Vibe → Specify/Plan → Task/Verify → Refactor/Own - carrying a feature from open-ended exploration through a verification gate to tested, team-owned code. It is TDD zoomed out: Red → Green → Refactor becomes Specify → Implement → Verify.
- The central behavioral shift is replacing "dump-and-review" with "verify-then-merge" - writing tests and contracts before generating code, which keeps humans engaged at the most critical moment and counters automation bias and vigilance decrement.
- Trust debt - the hidden cost of shipping unverified AI code - is a real economic externality that disproportionately taxes your most experienced engineers and stays invisible to velocity dashboards.
- Autonomy is a ladder, not a switch: each rung from autocomplete to autonomous agent buys more leverage but demands tighter verification, governance, and discipline. Climb deliberately.
- AI handles the easy first 70% (scaffolding, boilerplate, common patterns); the hard 30% - edge cases, architectural integration, security, performance, and real verification - still demands human judgment.
- The engineer's role shifts from writing code to designing and validating AI-assisted systems - building the factory, not each part - so real ownership depends on understanding the system, not just producing it.
- Working with language models pushes tacit know-how - taste, intuition, tribal practice - into explicit, measurable, repeatable processes: the move from software craftsmanship to software engineering.
- The book delivers practical patterns for migrating legacy code in the AI era, defining precise prompts and context, collaborating with agents, real cost models, new team topologies, and staff-level techniques such as squeezing performance.
 Vibe Engineering ebook for free
Vibe Engineering ebook for free