5 The birth of information theory: Shannon and the mathematics of uncertainty
The chapter recounts how Claude Shannon reframed uncertainty into a measurable resource and, in doing so, founded information theory. Building on earlier statistical ideas yet striking in a new direction, Shannon treated a message as a probabilistic sequence of symbols and defined information as the reduction of uncertainty. By introducing entropy—quantified in bits—and insisting that communication engineering concerns transmission rather than meaning, he supplied a universal yardstick that made “information” concrete, comparable, and optimizable across any channel.
Armed with this definition, Shannon articulated a complete end‑to‑end model—source, encoder, channel with noise, decoder, receiver—and turned the central trade‑offs of communication into mathematics. Source coding tied the limits of lossless compression to a source’s entropy; noisy‑channel coding showed that carefully added redundancy can make errors arbitrarily rare below a channel’s capacity; and capacity itself set the ceiling for reliable information rate. These results, extended through practical signaling and modulation schemes, solved urgent mid‑century engineering problems and still underwrite today’s digital infrastructure—from telephony and storage to satellite links, Wi‑Fi, and streaming.
The chapter also traces Shannon’s unintended legacy far beyond wires and radio. Entropy and mutual information became core tools in statistics, data science, and AI: decision trees and random forests split on information gain; feature selection ranks predictors by mutual information; clustering is assessed with entropy‑based measures such as purity and normalized mutual information; and neural networks learn by minimizing cross‑entropy, while representation learning compresses inputs to preserve high‑entropy structure and discard redundancy. In all these settings, the bit remains the unit and entropy the common currency for quantifying, managing, and ultimately learning from uncertainty.
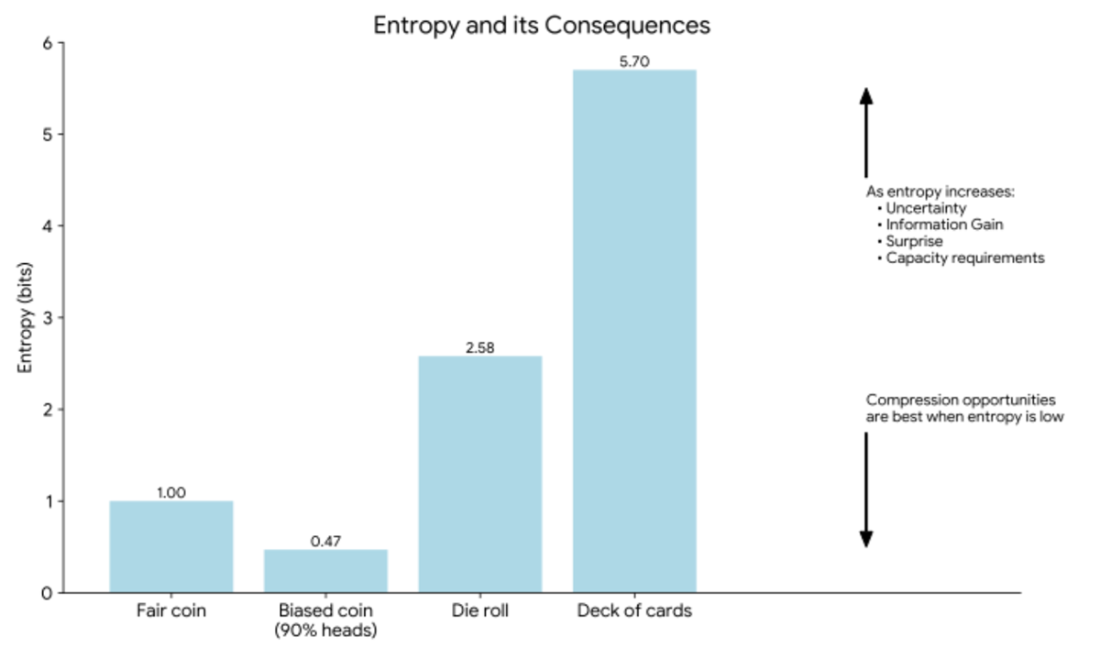
Entropy quantifies the uncertainty of a message in bits. A fair coin resolves 1 bit of uncertainty, while a biased coin conveys less (0.47 bits) because the outcome is more predictable. A die roll (2.58 bits) and a card draw (5.7 bits) carry progressively higher entropy as the number of equally likely outcomes increases. As entropy rises, so do uncertainty, surprise, information gain, and channel capacity requirements. When entropy is low, redundancy allows greater opportunities for compression.
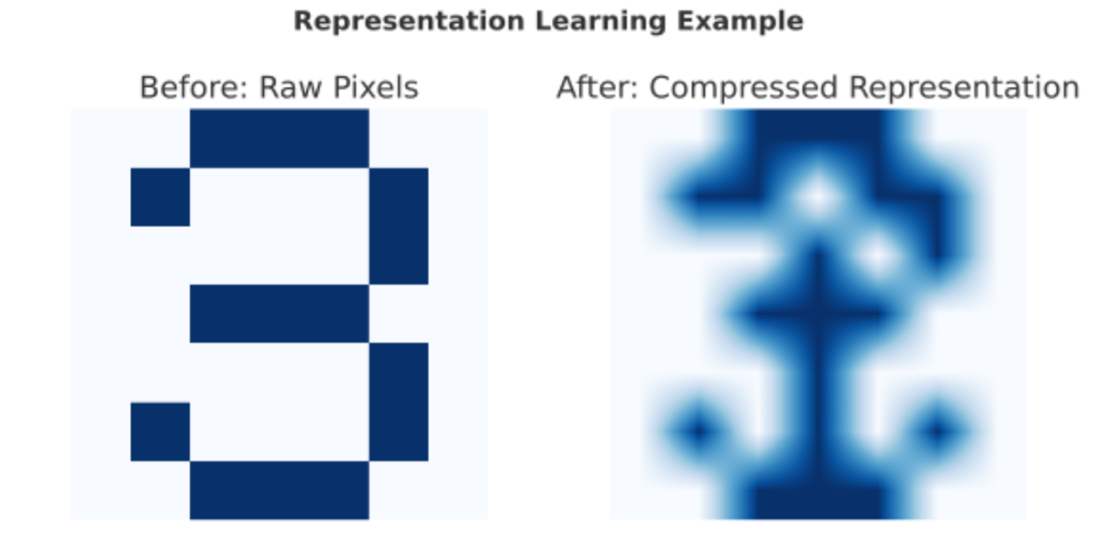
An illustration of representation learning as compression. On the left is the original raw object, containing many pixels and redundancies. In representation learning, an encoder compresses this object into a compact form, shown here on the right. The compressed version looks blurrier, but it preserves the high-entropy elements—the unpredictable parts that carry real information—while discarding low-entropy redundancies. This compressed representation is the “message” that can be transmitted or stored efficiently. Although not depicted here, a decoder can reconstruct an image that closely resembles the original, demonstrating how uncertainty can be reduced without losing essential content.
Summary
- Claude Shannon redefined information not as meaning but as the resolution of uncertainty. A predictable message like “the sun will rise tomorrow” carries almost no information, while an unpredictable one like a coin flip resolves genuine doubt. This shift allowed information to be quantified in probabilistic terms rather than treated as a vague concept.
- Borrowing from physics, Shannon formalized entropy as the average uncertainty in a source of messages. Measured in bits, entropy provides a precise yardstick: one bit for a fair coin flip, more for larger sets of equally likely outcomes. With entropy, engineers could assign numbers to unpredictability and compare the information content of different sources.
- Low-entropy sequences, such as repeated letters, are highly redundant and can be compressed without loss. High-entropy sequences, by contrast, resist compression because every symbol is unpredictable. Shannon also showed that redundancy, when deliberately added through coding, enables error correction—balancing efficiency with reliability in noisy channels.
- Shannon demonstrated that every channel has a maximum capacity, defined by its bandwidth and noise level, beyond which reliable transmission is impossible. By comparing entropy against channel capacity, engineers could design systems that transmit as much information as possible with minimal error. This principle still governs today’s telephony, Wi-Fi, satellite links, and digital media.
- In the 1940s, telegraphy, telephony, and radio faced urgent problems of efficiency and reliability. By making uncertainty measurable and showing how entropy governs redundancy, coding, and channel limits, Shannon gave engineers the tools to tame noise, compress signals, and design communication systems that approach theoretical limits of performance.
- Entropy quickly escaped engineering. In data science, it became the foundation of decision trees and random forests, where splits are chosen to maximize information gain. Mutual information extended this idea, guiding feature selection and quantifying relationships between variables. Entropy also became central to clustering, neural networks, and representation learning.
- By treating information as measurable uncertainty and entropy as its unit, Shannon gave science and engineering a new common currency. His work solved practical problems of mid-20th-century communication while also laying the groundwork for the information age. Today, bits and entropy remain the backbone of both digital technology and modern artificial intelligence.
 Timeless Algorithms: The Seminal Papers ebook for free
Timeless Algorithms: The Seminal Papers ebook for free