This chapter provides a hands-on walkthrough of building a small-scale time series foundation model to illustrate the core ideas behind pretraining, transfer learning, and fine-tuning. Instead of starting with complex Transformers, it adopts the lightweight and generalizable N-BEATS architecture to make the process accessible and fast while still showcasing how foundation models learn broad patterns and adapt to new tasks. Along the way, it highlights practical considerations—like data frequency, forecast horizons, evaluation metrics, and compute/data constraints—that shape how robust foundation models are developed and deployed.
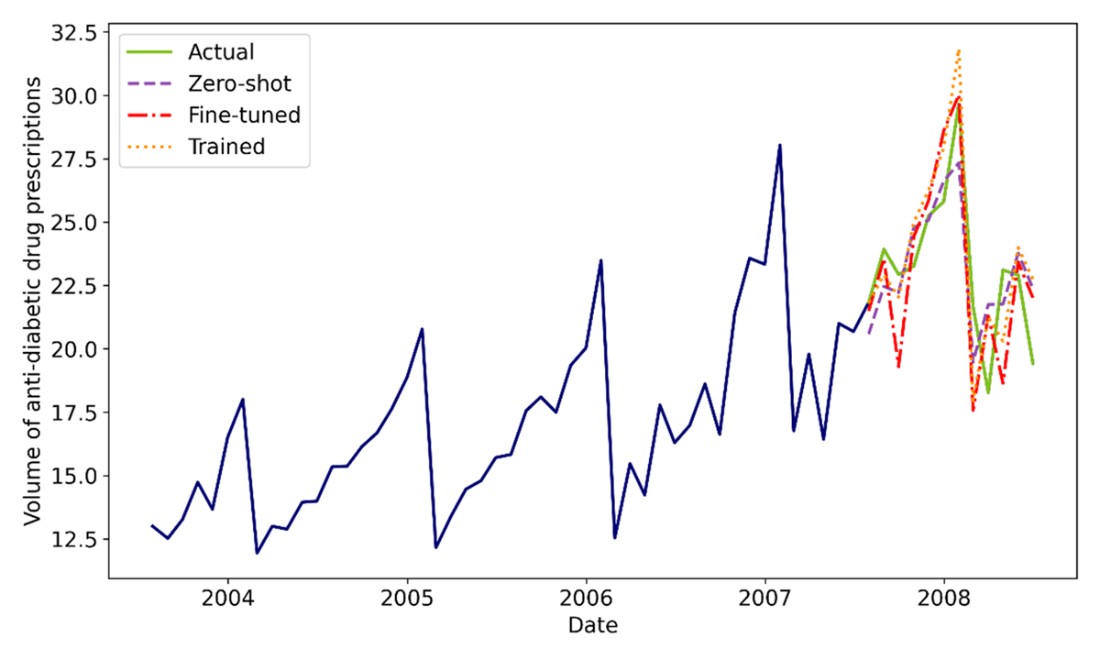
The chapter first demystifies N-BEATS, emphasizing neural basis expansion and a simple, fully connected design organized into blocks and stacks. Each block generates a forecast and a backcast, enabling sequential residual learning across stacks to capture information missed earlier. With this foundation, the model is pretrained on the monthly M3 dataset (learning from diverse series and domains), then saved and reused via transfer learning. Applied to a new monthly series, three approaches are compared—zero-shot forecasting with the pretrained model, fine-tuning that model on the target series, and training a model from scratch. Evaluated with MAE and sMAPE, the zero-shot pretrained model performs best in this monthly setting, underscoring the power of generalization from broad pretraining.
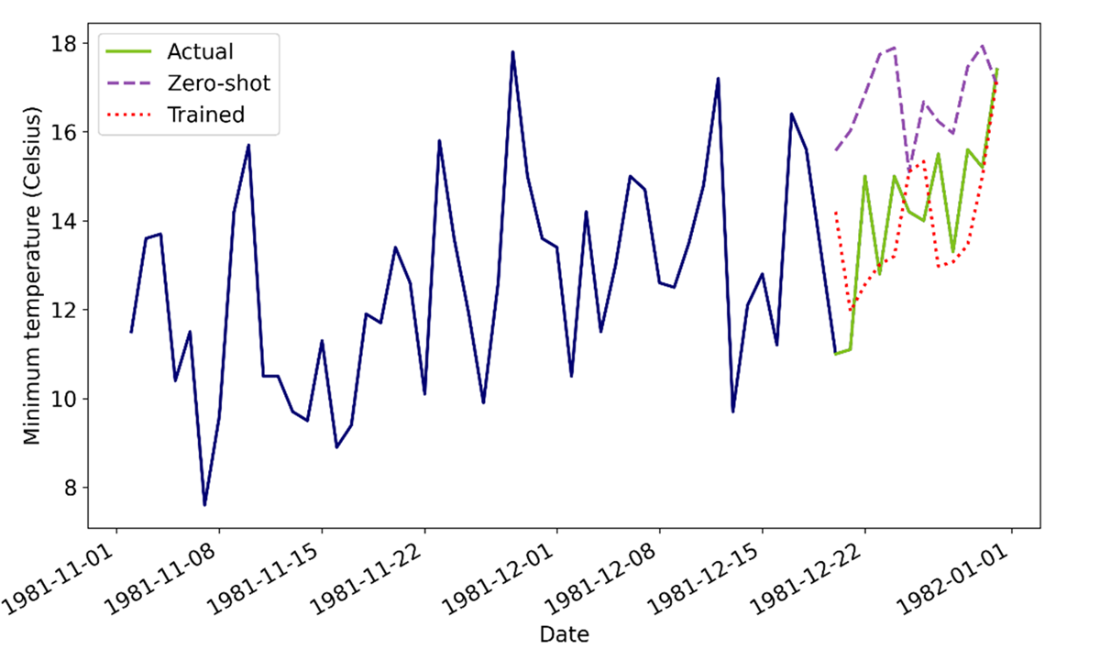
The chapter then tests robustness across frequencies by applying the monthly-pretrained model to a daily temperature series. Here, zero-shot performance degrades relative to a model trained specifically on the daily data, demonstrating that frequency shifts introduce different temporal patterns the pretrained model did not learn. This motivates practical lessons: data frequency matters, horizon limits can be restrictive (suggesting generative approaches for longer forecasts), fine-tuning depth and steps must be chosen carefully, and real foundation models demand substantial, high-variety datasets and significant compute. The chapter closes by reflecting on these challenges and setting up the exploration of larger, purpose-built foundation models in subsequent chapters.
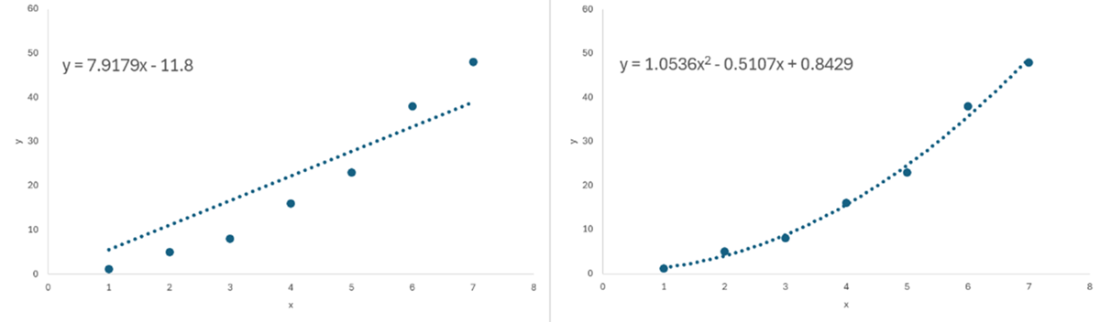
Visualizing the impact of basis expansion. On the left, without basis expansion, we are stuck with using a linear model. On the right, after a second-degree polynomial basis expansion, we can fit a quadratic line and better fit our data.
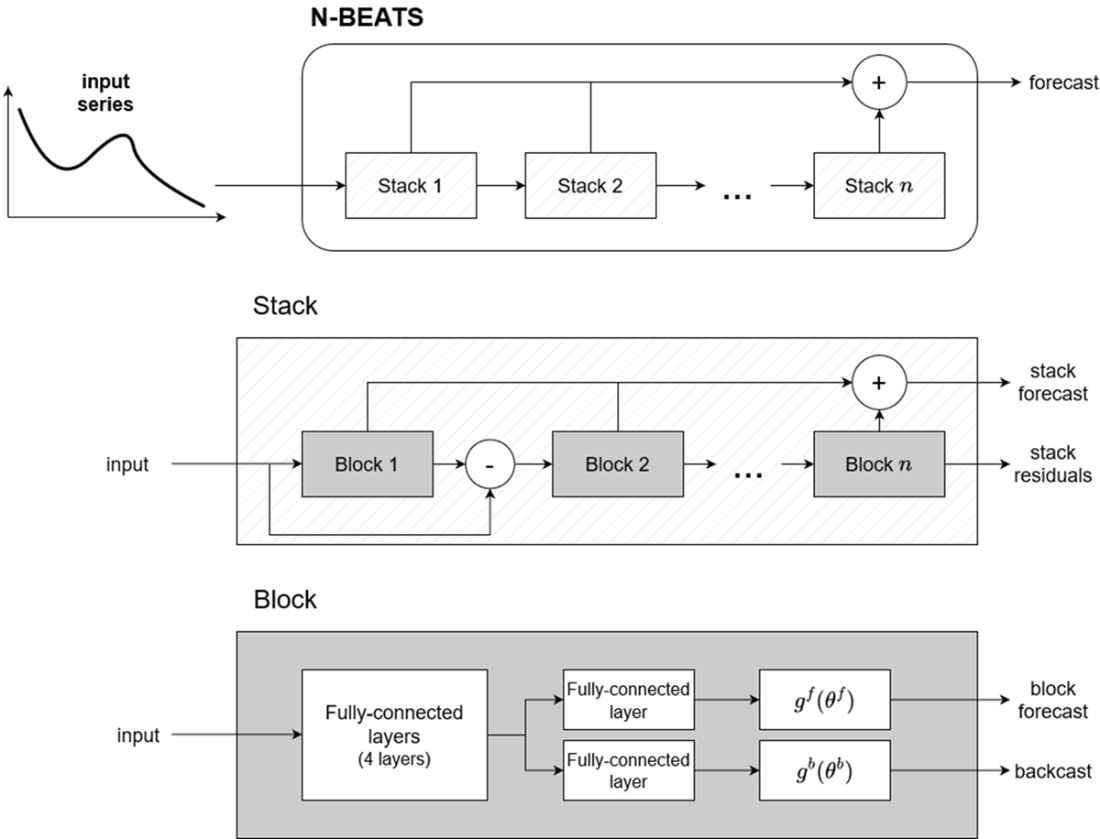
Architecture of N-BEATS. N-BEATS is made of stacks, which are made of blocks, where each block outputs a forecast and a backcast.
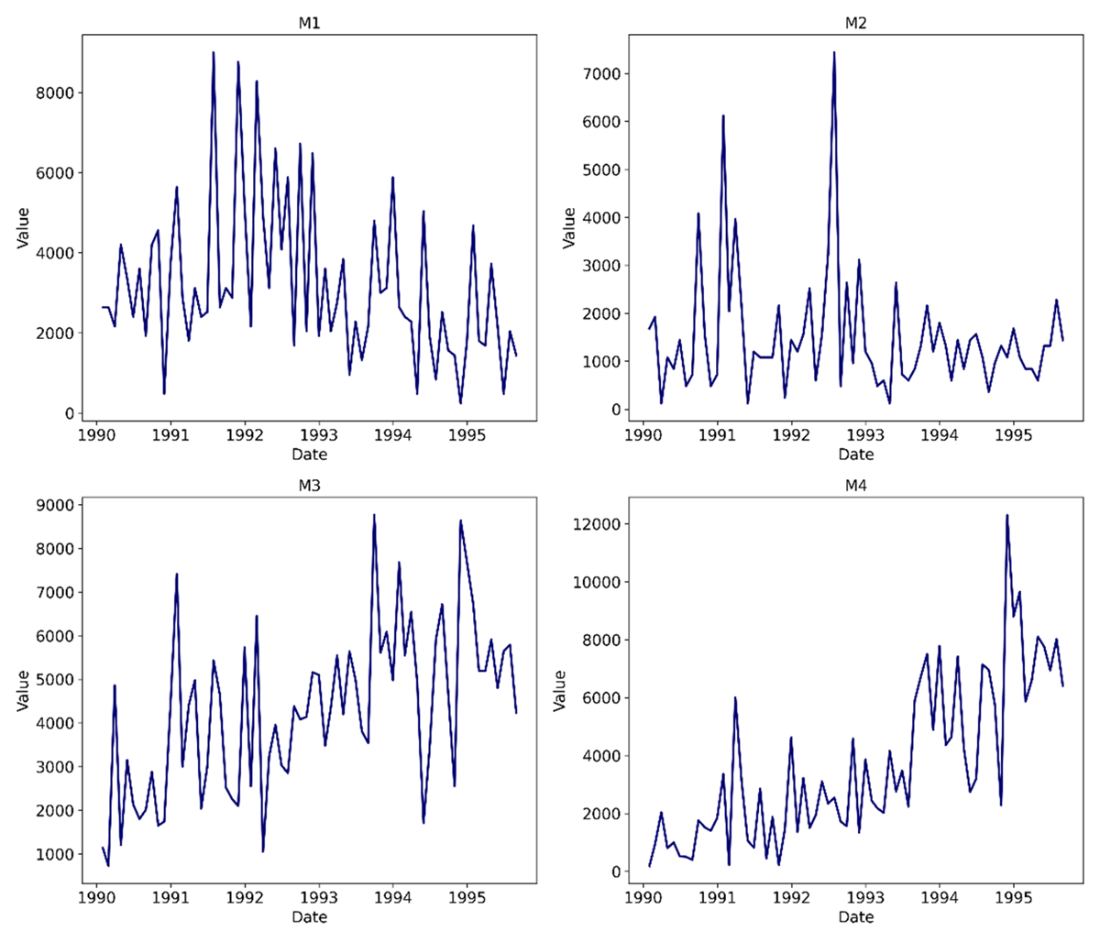
Plotting the first four series of the monthly M3 dataset. The title refers to a label for each series. Note that each series is part of the M3 dataset.
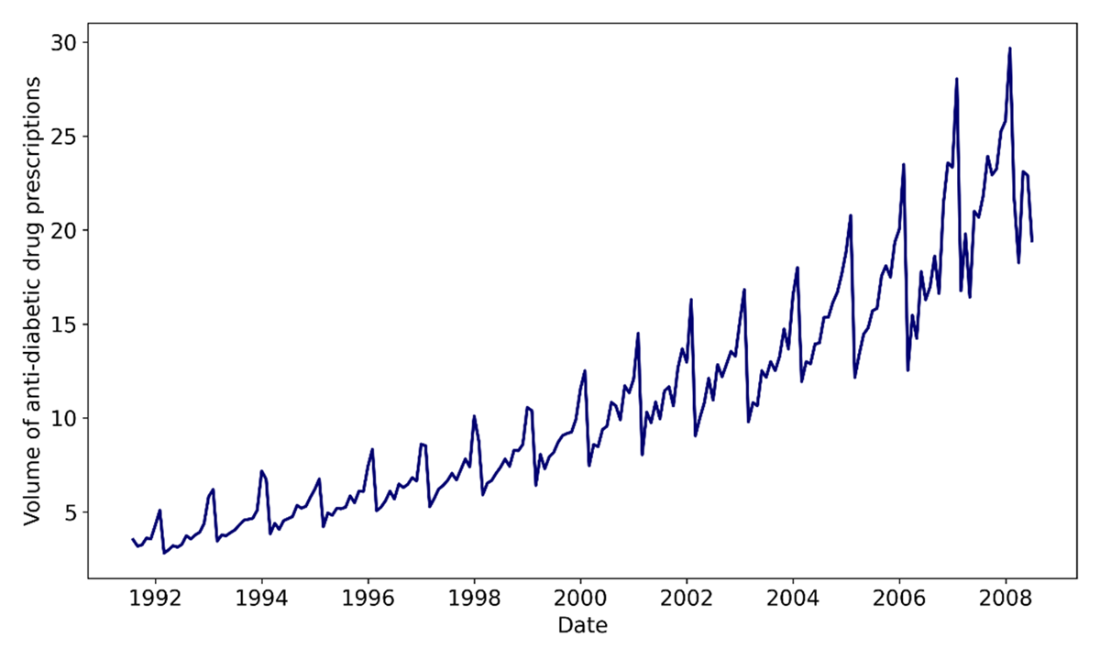
Monthly volume of antidiabetic drug prescription in Australia, from 1991 to 2008.
Plotting the predictions against the actual values. We can see that the predictions mostly overlap with the actual values but coming from the pretrained model with zero-shot forecasting seem to be the closest.
Predictions on daily data using the pretrained model and a data-specific model. Here, we see that the pretrained model fails to make accurate predictions, since the dashed line (zero-shot forecasts) never overlaps the solid line (actual values). However, the forecasts from the trained model (dotted lines) is closer to the actual values.
Summary
A pretrained model is trained on large amounts of data such that it can be used in another scenario.
Transfer learning is when we use a pretrained model on a dataset that was not previously seen by that model.
Pretrained models can generate zero-shot predictions or be fine-tuned. With zero-shot predictions, the model never trains on the new dataset, while fine-tuning allows the model to specialize in the task at hand by training for a few steps.
We can easily build a pretrained model, but it will not perform well on other frequencies, and we are limited in the forecast horizon.
Building foundation models is hard. They require massive amounts of data and expensive resources that are not available to the vast majority of practitioners.
References
FAQ
What is N-BEATS, and why is it a good choice for a tiny foundation model?N-BEATS (Neural Basis Expansion Analysis for Interpretable Time Series forecasting) is a simple, fully connected deep-learning architecture that avoids handcrafted time-series components (like explicit trend/seasonality). It learns complex patterns via neural basis expansion, generalizes well across series, and trains quickly—even on CPU—making it ideal for pretraining and transfer learning at small scale.What is basis expansion, and how does N-BEATS use it?Basis expansion maps inputs into a richer feature space (e.g., polynomial, logarithmic) to capture nonlinear relationships. In N-BEATS, the model learns expansion coefficients (Θ) and basis functions (g) directly (hence “neural basis”). Each block outputs a forecast (future values) and a backcast (reconstruction of the input) using these learned bases.How do blocks, stacks, forecasts, backcasts, and residuals work in N-BEATS?Each block has fully connected layers that produce a forecast and a backcast. The backcast (what the block learned from the input) is subtracted from the input to form residuals, which are passed to the next block so it learns what was missed. A stack sums block forecasts to a partial prediction; the full model sums stack predictions for the final forecast.What does pretraining mean in this context, and how was it done?Pretraining means training on a large, diverse dataset to learn general patterns. Here, N-BEATS was pretrained on the monthly portion of the M3 dataset (1,428 series) with horizon h=12 and input_size=24, for 1,000 training steps. The model was then saved and later loaded for transfer learning. Data for NeuralForecast must include columns: unique_id (series ID), ds (timestamp), y (value).Why train by “steps” instead of “epochs,” and how many steps should I use?A step is a gradient update; an epoch is a full pass over the dataset. Steps are more consistent across datasets of different sizes. Too few steps may undertrain the model. In the chapter’s setup, 1,000 steps was a good default for pretraining; fine-tuning used far fewer (e.g., 10) to avoid overfitting and long runtimes.What is transfer learning and zero-shot forecasting, and when should I use them?Transfer learning applies a pretrained model to new data. Zero-shot forecasting uses the pretrained model directly (no additional training), ideal when you have limited target data and need fast predictions. In the monthly antidiabetic prescription example, zero-shot forecasts from the pretrained model performed best among tested approaches.What is fine-tuning, and how was it applied to N-BEATS here?Fine-tuning trains the pretrained model on the target dataset to specialize it. Typically, you train only the last layers to save time and reduce overfitting, but here the entire small model was fine-tuned briefly (e.g., 10 steps) using NeuralForecast’s fit after reducing max_steps. Fine-tuning may help, but its benefit depends on data and can risk overfitting if overdone.How were approaches evaluated on monthly data, and what were the results?Using MAE and sMAPE on a 12-step test set: the pretrained model in zero-shot mode achieved the best scores (MAE ≈ 1.59, sMAPE ≈ 3.56%), outperforming both the fine-tuned model and a model trained from scratch on the target series.Can a model pretrained on monthly data forecast daily data well?Generally no. Frequency mismatch degrades performance because daily series exhibit different, more granular patterns (e.g., weekly seasonality). In the experiment, the pretrained monthly model performed poorly on daily data (MAE ≈ 2.59, sMAPE ≈ 8.69%), while a daily data–specific N-BEATS trained from scratch performed much better (MAE ≈ 1.34, sMAPE ≈ 4.87%).What are key challenges in building robust foundation forecasting models?- Frequency generalization: models must handle diverse sampling rates (daily, monthly, etc.). - Horizon flexibility: fixed horizons limit use cases; generative approaches can extend horizons. - Compute and scale: large models require substantial GPU time and engineering. - Data scarcity and aggregation: time-series data is less abundant and harder to unify across domains compared to text, making broad, diverse pretraining datasets difficult to assemble.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Time Series Forecasting Using Foundation Models ebook for free
Time Series Forecasting Using Foundation Models ebook for free