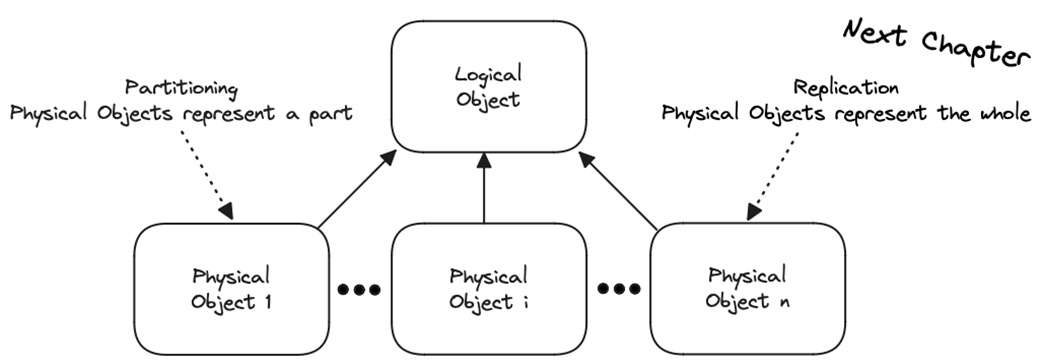
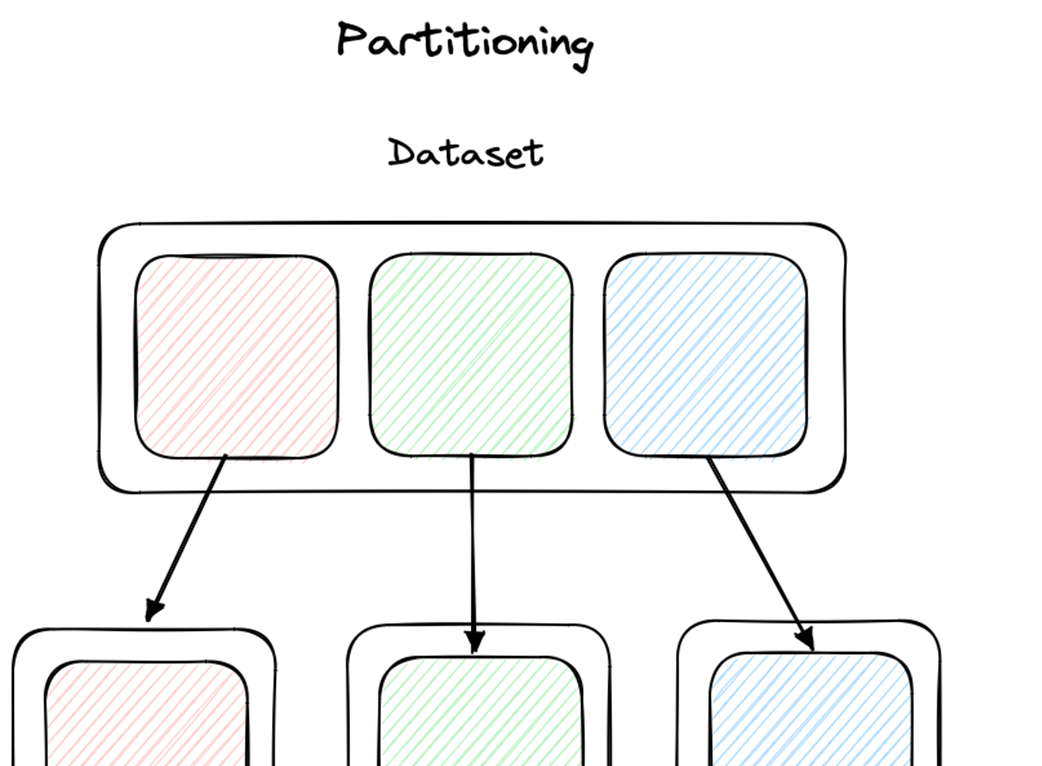
Partitioning is presented as a core technique for scaling distributed systems by breaking a single logical dataset into multiple disjoint physical pieces and spreading them across nodes. Using the encyclopedia–volumes analogy, the text shows how thoughtful placement enables efficient find and fetch operations, while highlighting pitfalls such as uneven distribution, uneven demand, and cross-references that span partitions. Beyond sheer data size, partitioning helps overcome any single-node bottleneck (including request volume), and in a sense every distributed system is intrinsically partitioned because each component owns exclusive local state.
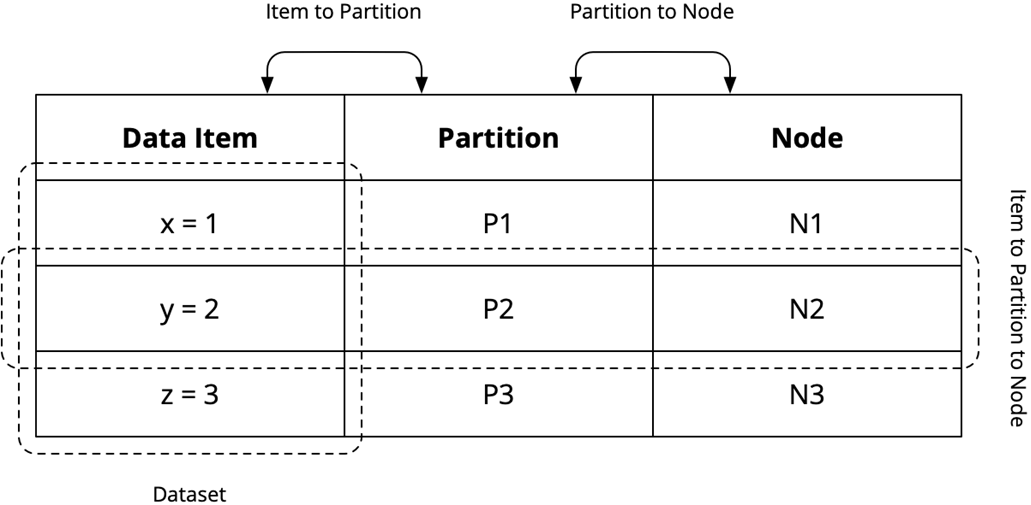
The mechanics center on two mappings: assigning items to partitions and assigning partitions to nodes. Choices like static versus dynamic partitioning influence elasticity and operational complexity, while horizontal (row-wise) and vertical (column/type-wise) partitioning can be combined to scale different concerns independently (for example, splitting user profile text from images, then sharding each). Real workloads (social media hot users, IoT time-based writes) expose skew and evolving requirements, making repartitioning and online migration necessary. Balancing and rebalancing move partitions among nodes to match demand; over-partitioning (more partitions than nodes) increases flexibility to scale in or out by reassigning existing partitions without reshaping the data layout.
Item-to-partition assignment strategies trade simplicity for control. Stateless item-based methods (range or hash) are easy to operate but coarse-grained: range partitioning risks hotspots, while hashing balances variance well yet forces many relocations when the partition count changes. Stateful directory-based methods enable fine-grained placement but introduce a potential bottleneck in the directory itself. The chapter evaluates strategies using variance (uniform spread) and relocation (data moved on resize) and motivates consistent hashing, which preserves good balance while moving only a small, proportional fraction of items when partitions change—supporting elastic growth with fewer disruptions. The overarching message is to pick and evolve partitioning, assignment, and balancing tactics to match a system’s unique access patterns, growth modes, and operational constraints.
Encyclopedias and volumes
Thinking about partitioning (replication is covered in chapter 8).
Partitioning a key-value store
Assignment of data items to partitions and the assignment of partitions to nodes
Partitioning—that is, assignment of data items to partitions
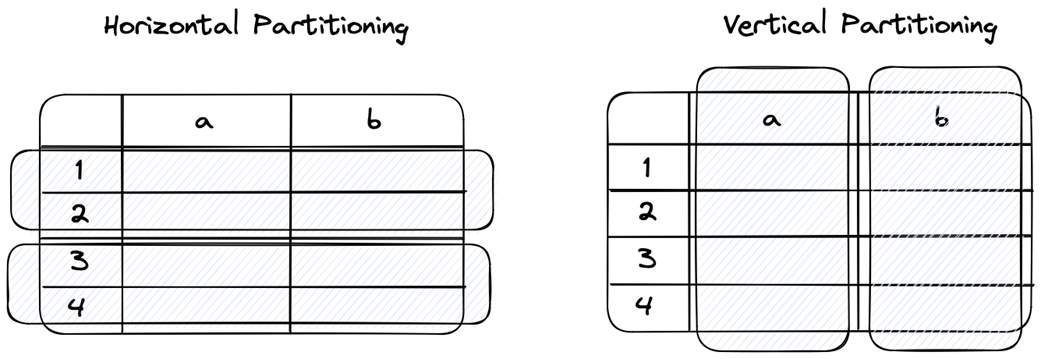
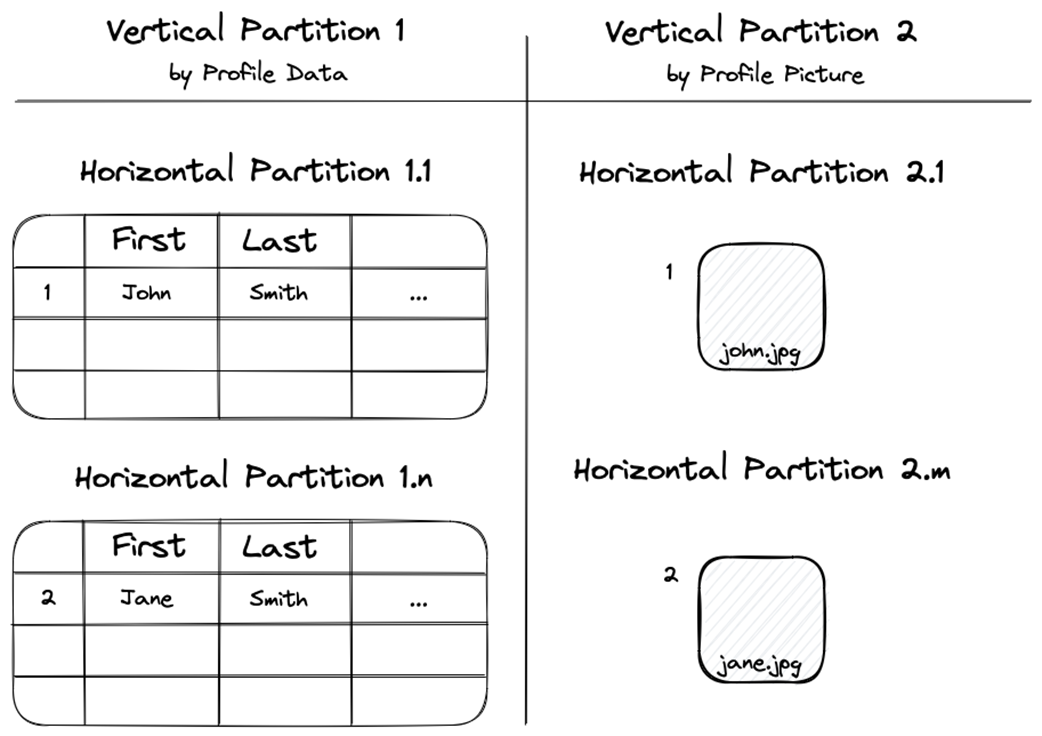
Horizontal and vertical partitioning
Partitioning user information
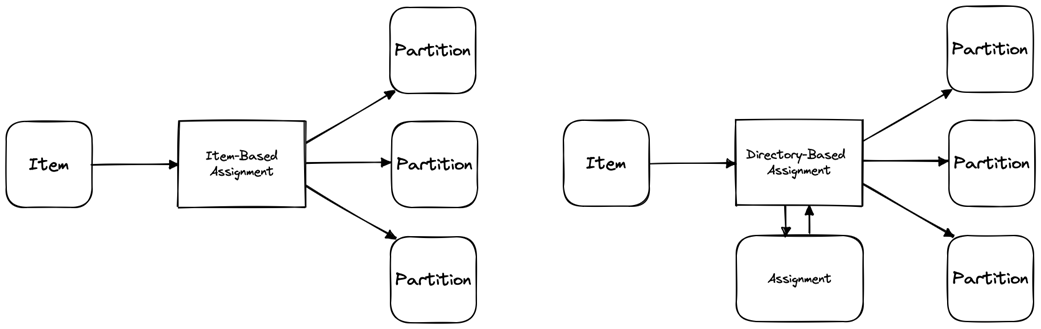
Item-based and directory-based assignment
Balancing—that is, assignment of partitions to nodes
Partitioning (left) and Over Partitioning (right)
Summary
Partitioning improves the scalability of distributed systems by distributing data across multiple resources, overcoming the limitations of a single resource.
Partitioning assigns items to partitions while balancing assigns partitions to nodes.
Static partitioning uses a fixed number of partitions, offering simplicity but lacking elasticity, while dynamic partitioning adapts to changing demands with a variable number of partitions, adding complexity.
Horizontal partitioning (or sharding) divides data by rows, and vertical partitioning divides data by columns; both can be combined to manage different data types and scale aspects of the application independently.
Item-based assignment is a partitioning strategy that assigns each data item to a partition based solely on its own characteristics. Directory-based assignment is a partitioning strategy using a separate component called a directory or lookup table.
Consistent hashing minimizes uneven distribution and data relocation during partition changes.
Designing an adequate partitioning strategy requires consideration of the system's unique characteristics and unique requirements and may change as the system evolves.
FAQ
What is partitioning in a distributed system, and how does it differ from replication?Partitioning represents a single logical object as multiple, disjoint physical objects (partitions) spread across nodes to distribute load and improve scalability. Replication, by contrast, creates redundant copies to improve reliability. Partitioning tackles scalability limits; replication tackles reliability limits.What challenges commonly arise when partitioning data?Typical challenges include uneven distribution (some partitions hold far more data than others), uneven demand (some partitions receive disproportionately more traffic), and cross-references (operations need data from multiple partitions). The “right” strategy depends on your system’s requirements and access patterns.What is the difference between partitioning, repartitioning, balancing, and rebalancing?Partitioning assigns items to partitions. Repartitioning reassigns previously placed items to different partitions (e.g., when the number of partitions changes). Balancing assigns partitions to nodes. Rebalancing reassigns partitions to different nodes (e.g., in response to demand or cluster size changes).What are static and dynamic partitioning, and what are their trade-offs?Static partitioning uses a fixed number of partitions that changes only via administrative, typically offline, operations—low complexity but not elastic. Dynamic partitioning allows the number of partitions to change online as a normal operation—elastic but adds significant complexity (especially around safe repartitioning).What is the difference between horizontal and vertical partitioning, and can they be combined?Horizontal partitioning (sharding) splits data by rows (items). Vertical partitioning splits by columns (fields/attributes). They can be combined—for example, store text profile data and images in separate systems (vertical), and then shard each of those across multiple partitions (horizontal) to scale independently.How do item-based and directory-based assignment strategies compare?Item-based assignment computes a partition from the item itself (e.g., key or key hash). It is stateless, simple, and good for coarse-grained balancing, but cannot steer specific items to specific partitions (risking hot-spot collisions). Directory-based assignment uses a stateful lookup table to map items to partitions, enabling fine-grained placement but adding operational complexity and a potential scalability/reliability bottleneck in the directory.What do “variance” and “relocation” mean when evaluating partitioning strategies?Variance measures how evenly items are distributed across partitions (lower variance is better). Relocation measures how many items must move when the number of partitions changes (less relocation is better). Good strategies aim to minimize both.How do range partitioning and hash partitioning compare?Range partitioning assigns items based on key ranges; it’s simple but often yields uneven distribution (high variance) if keys are skewed. Hash partitioning applies a hash of the key to select a partition; it typically balances load well (low variance) but can cause many items to move when the partition count changes (high relocation).What is consistent hashing and why is it useful?Consistent hashing assigns items to partitions so that when the number of partitions changes, only about n/m items (on average) need to move (n items, m partitions). It reduces both variance and relocation, making scaling up or down far less disruptive than naive hashing or range schemes.What is over-partitioning, and when should I use it?Over-partitioning creates more partitions than nodes so each node hosts multiple partitions. This gives the system flexibility to rebalance: add nodes and spread partitions out as demand grows, or remove nodes and reassign partitions as demand shrinks. The trade-off is that the number of partitions still caps the maximum usable nodes.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!



 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free