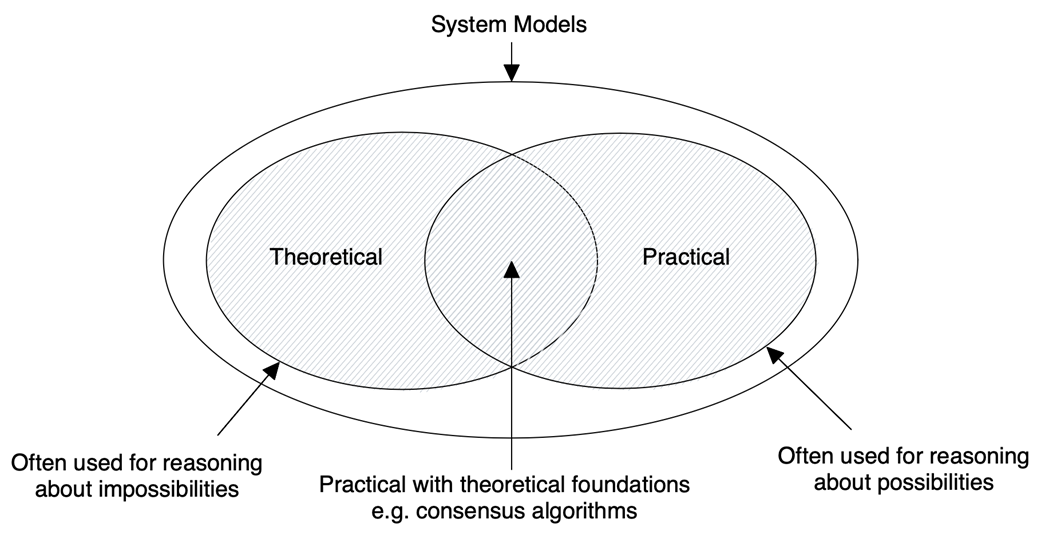
2 System models and order and time
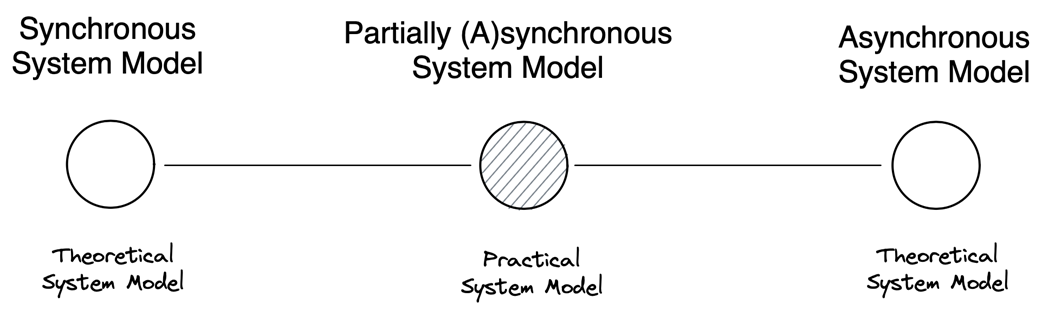
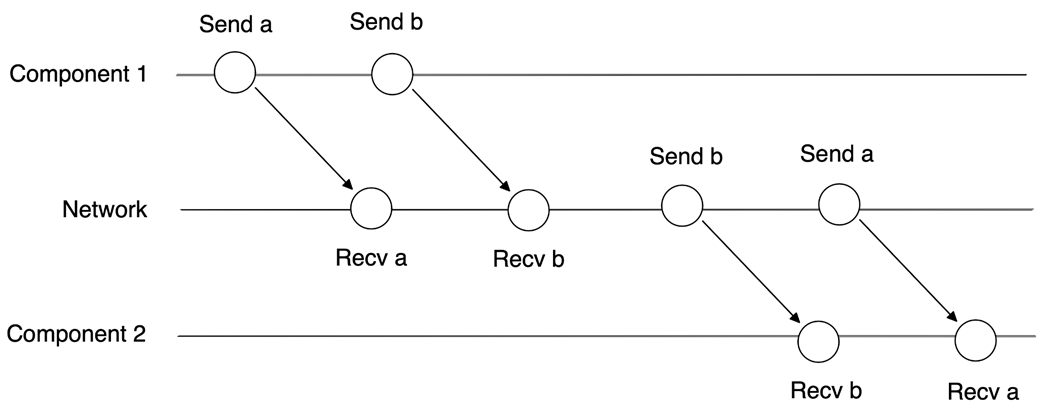
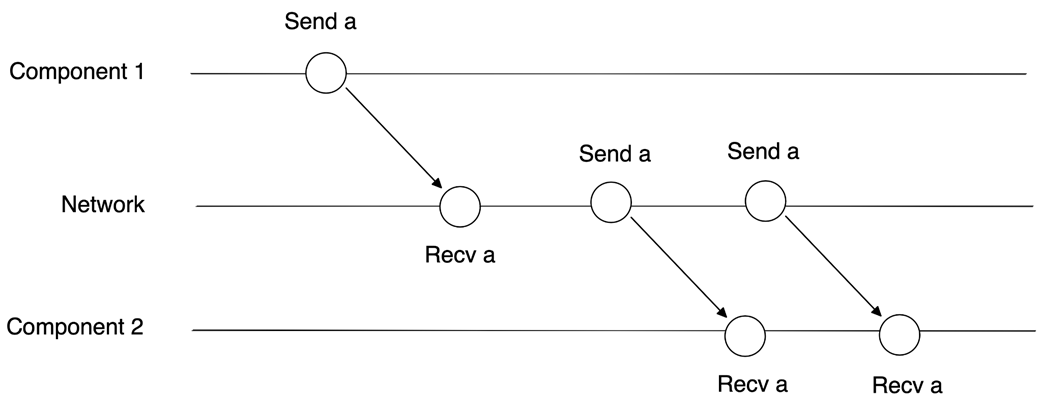
Distributed system design starts with an explicit system model: a set of assumptions about components, the network, and timing. The chapter contrasts theoretical and practical models, then frames synchrony as an assumption about time: synchronous systems have precise or bounded timing guarantees, while asynchronous systems range from having no notion of time (no timeouts) to a weak one (local, unsynchronized clocks that permit timeouts). Reality sits in between as partial synchrony: systems behave synchronously most of the time but occasionally act asynchronously. Within this model, components may crash and stop, pause and resume (omission), or crash and recover with possible state loss; networks may reorder, drop, or duplicate messages. A pragmatic baseline emerges: partially synchronous systems, components subject to crash-stop/omission/crash-recovery, and unreliable networks, with Byzantine behavior typically out of scope.
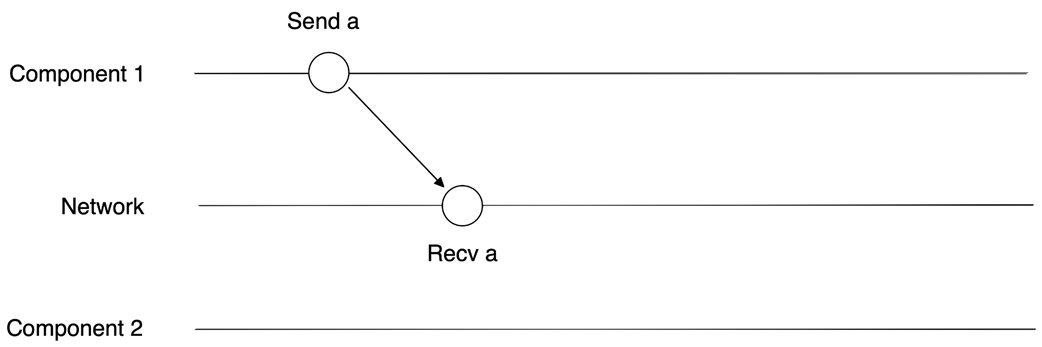
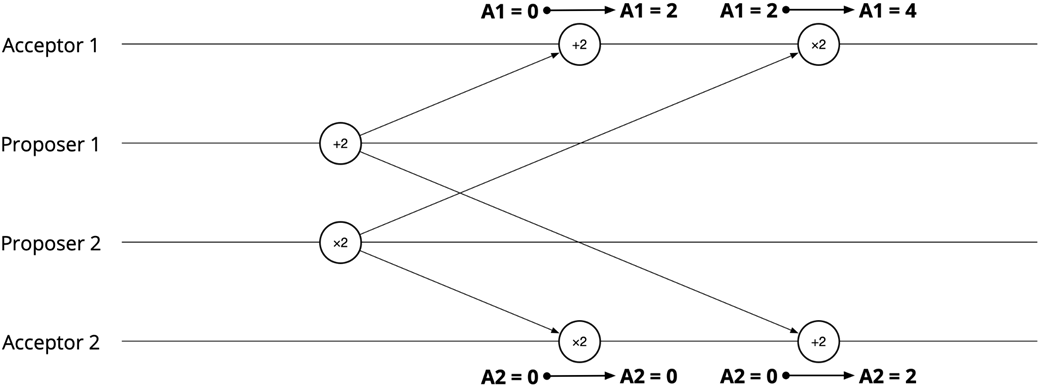
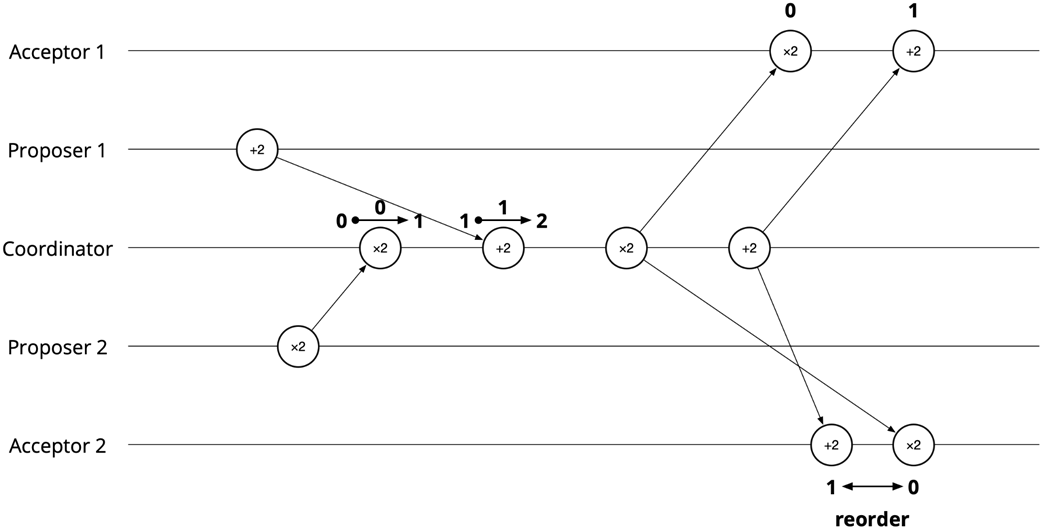
Because collaboration depends on noncommutative actions, correctness hinges on establishing a consistent order of events. The chapter illustrates how differing message arrival orders create race conditions—situations with multiple possible executions, some correct and some not—and shows how introducing a coordinator that assigns progressively increasing tags (sequence numbers) enables receivers to detect gaps and restore a single coherent order. This framing elevates ordering from an implementation detail to a first-class concern that underpins safety and liveness in protocols.
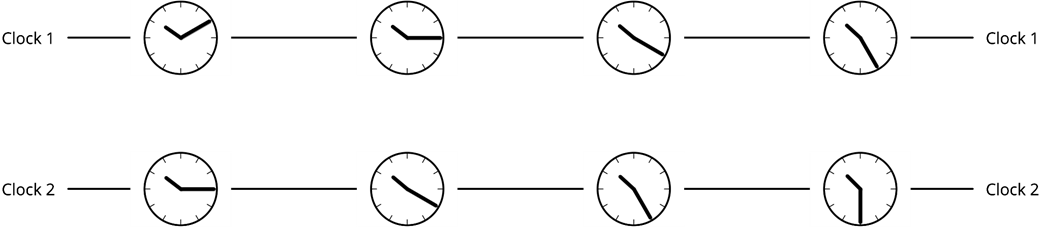
To reason about order, the chapter builds on Lamport’s happened-before relation, a partial order capturing intra-component sequencing, message-send/receive causality, and transitivity. It uses this lens to distinguish concurrency (no causal ordering) from parallelism (temporal overlap) and then ties ordering to clocks through the requirement of clock consistency. Physical clocks timestamp real time but suffer skew and drift, prompting synchronization and the careful use of time-of-day versus monotonic clocks. Logical clocks, such as Lamport and vector clocks, assign timestamps that respect causality across components; even when not used explicitly, many systems embed logical time (for example, per-partition offsets or per-key sequence numbers). In practice, distributed systems combine physical time for measuring durations and triggering timeouts with logical time to enforce consistent cross-component ordering.
System models
From synchronous to asynchronous system models
Component Failures

Crash-Stop failure

Omission failure

Crash recovery failure

Byzantine failure

Message reordering
Message duplication
Message loss
Proposers and acceptors
Proposers, acceptors, and a coordinator
Happened-before, intra component

Happened-before, inter component

Happened-before, transitively

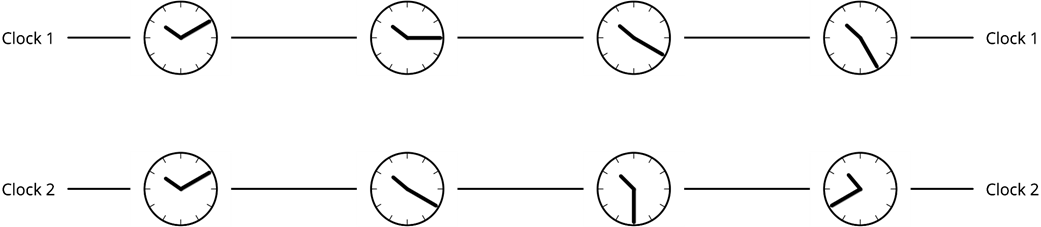
Clock skew
Clock drift
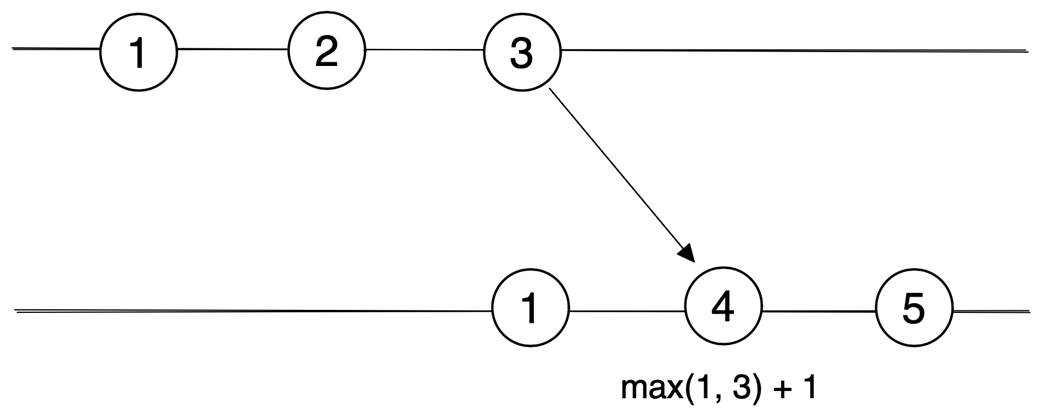
Lamport clocks
Summary
- System models encode assumptions about components, network, and timing behavior; different system models affect algorithm correctness.
- Synchronous systems have strict timing guarantees, while asynchronous systems operate with no timing guarantees. Partially synchronous systems combine the properties of both synchronous and asynchronous systems, operating synchronously most of the time but tolerating asynchronous behavior occasionally.
- Component failures include Crash-Stop, Omission, Crash-Recovery, and Byzantine; network failures include message reordering, duplication, and loss.
- Order of events is crucial for correctness; logical clocks, such as Lamport clocks, are used to establish event order and capture causality.
FAQ
What is a system model, and why is it crucial in distributed systems?
It is the set of assumptions about components, the network, and timing (e.g., failures, message behavior, clock properties). Correctness depends on these assumptions—an algorithm proven correct under one model may be incorrect under another.How do synchronous, asynchronous, and partially synchronous models differ?
- Synchronous: strong notion of physical time; clocks are perfect or have known bounds; processing and communication have bounded delays.- Asynchronous (no notion of time): no clocks; arbitrary delays; timeouts are impossible.
- Asynchronous (weak notion of time): unsynchronized local clocks; arbitrary delays; timeouts are allowed.
- Partially synchronous: systems behave synchronously most of the time and asynchronously sometimes; common in practice.
Do timing assumptions imply anything about failures or message loss?
No. Timing (synchronous/asynchronous) is independent of failure assumptions. Component failures and network faults are separate dimensions of the system model.What component failure models are commonly considered?
- Crash-stop: the component halts forever (ceases to exist).- Omission: the component pauses for an arbitrary time, then resumes with state intact (takes a break).
- Crash-recovery: the component pauses and then resumes but may lose volatile state (memory loss).
- Byzantine: arbitrary/malicious behavior (anything may happen). Many practical systems ignore Byzantine faults.
What network faults should I plan for, and what is an unreliable network?
- Message reordering: delivery order may differ from send order.- Message duplication: receivers may see duplicates.
- Message loss: messages may never arrive.
“Unreliable network” means any of the above can occur. Typically, the network is assumed not to lie: delivered messages were actually sent by some component.
What is the happened-before relationship, and why is it a partial order?
It orders events by causality: (1) within a component, earlier events precede later ones; (2) a send event precedes its corresponding receive event; and (3) it is transitive. Some event pairs are unrelated (concurrent), so the order is partial, not total.How does this chapter define a race condition, and how can coordination resolve it?
- Definition: a system has a race condition if multiple possible executions exist where some are correct and some are incorrect.- Fix: introduce coordination (e.g., a coordinator assigns increasing tags/sequence numbers) so recipients can reorder or delay processing to enforce a consistent global order.
What’s the difference between concurrency and parallelism here?
- Concurrency: neither operation’s end happens before the other’s begin; defined by logical time/causality (happened-before).- Parallelism: operations overlap in real time; determined by physical clocks and physical time.
What is clock consistency, and what challenges do physical clocks pose?
Clock consistency requires: if event A happened before event B, then timestamp(A) < timestamp(B). Physical clocks suffer from skew (offset) and drift (rate differences). Mitigations include clock sync (e.g., NTP). Use time-of-day clocks for wall time (may jump backward) and monotonic clocks for durations (never go backward, but only comparable within one machine).What are logical clocks, and where do we see them in practice?
- Lamport clocks: per-component counters incremented on events; on receive, set to max(local, received)+1 to preserve causality order.- Vector clocks: extend Lamport clocks to detect concurrency.
- Practical analogs: Kafka partition offsets (ordered within a partition) and etcd per-key sequence/revision numbers—both act like logical timestamps that are not comparable across partitions/keys.
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free