11 Durable executions
Durable executions are presented as a systems-level abstraction that, like database transactions, hides the messiness of failures while a process runs. The chapter shows why partial executions are dangerous: even if each step is atomic, their sequential composition is not, so a crash between steps can leave the system in an inconsistent state. It distinguishes process definitions (code) from executions (running code), models processes as sequences of failure-atomic actions, and clarifies that multi-step executions don’t automatically inherit atomicity. It also frames short- versus long-running work in logical time (number of steps), not wall-clock time.
Failure-transparent recovery means a failed-then-recovered execution is observationally equivalent to a failure-free one, judged by an application-defined equivalence function. Exactly-once behavior is the ideal but often unattainable; practical equivalences allow duplicating the last event(s) or even restarting from the beginning. Idempotence is therefore essential. Two recovery strategies are highlighted: restart, which is simple with idempotent steps but can misbehave with delays and nondeterminism; and resume, which continues from a persisted save point between steps.
The chapter contrasts application-level and platform-level implementations. At the application level, Sagas make definitions failure-aware, often via state machines that persist state and drive the next step. At the platform level, Durable Executions keep definitions failure-agnostic while delivering failure-transparent executions. Two platform approaches appear: log-based, which records each step’s output and replays with deduplication (simple, but requires determinism and grows logs), and state-based, which persists the continuation after each step (no replay, tolerates nondeterminism, but needs runtime support for serializable continuations). The net effect is clearer business logic when the platform shoulders failure handling.
The sequential composition of two atomic actions is not itself atomic.

Definition versus execution
A process P consists of one step: a.
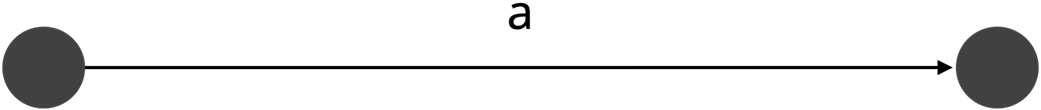
A process P consists of two steps: a and b.

Resume

Failure handling
Summary
- Failure transparency refers to the property of a system where failure-free executions are indistinguishable from failed and subsequently recovered executions.
- Failure transparency can be achieved at two levels: the application level and the platform level.
- At the application level, failure transparency relies on failure-aware process definitions, resulting in failure-transparent process executions.
- At the platform level, failure transparency is achieved through failure-agnostic process definitions, enabling failure-transparent process executions.
- Durable Executions are an emerging approach to implementing failure transparency at the platform level.
- Durable Executions follow two implementation strategies: log-based and state-based.
- In log-based implementations, the system records the output of each step in a durable log and, upon execution failure, replays the process while deduplicating previously executed events.
- In state-based implementations, the system records the state (continuation) after each step and, upon failure, restores the continuation to resume execution without replaying steps.
FAQ
What are durable executions, in a nutshell?
Durable executions are a platform-level abstraction that makes long-running processes in distributed systems behave as if failures did not occur. Much like transactions in databases, they conceal partial failures so that a failure-free run is equivalent to a failed-then-recovered run.Why are partial executions problematic in distributed systems?
Because the sequential composition of atomic steps is not itself atomic. If a process crashes between steps, you can observe a “half-done” outcome (for example, charging a card but failing to create an account), leaving the system in an inconsistent state.What’s the difference between concurrency atomicity and failure atomicity?
- Concurrency atomicity (isolation): intermediate states are not observable by other processes; execution appears uninterrupted with respect to concurrency.- Failure atomicity (all-or-nothing): the overall effect is either fully applied or not applied at all, though intermediate states may be observable during execution. In this chapter, “atomic” refers to failure atomicity.
How do “short-running” and “long-running” executions differ?
They differ by logical, not physical, time. A short-running execution has a single step; a long-running execution has multiple steps. Single-step executions inherit failure atomicity; multi-step executions do not, so they need explicit recovery strategies.What’s the distinction between a process definition and a process execution?
- Process definition: a sequence of failure-atomic steps (P = A • P’ | ε).- Process execution: the observable trace of events (t), which may end in success (✓) or crash-stop (×). The execution can halt at any time, so reasoning must account for partial traces.
What is failure-transparent recovery, and what role do equivalence functions play?
Recovery is failure-transparent if a recovered execution produces a sequence of events equivalent to some failure-free execution. The application defines the equivalence function, e.g., identity (exactly-once), “valid to duplicate last event,” “valid to duplicate last n events,” or “restart from the beginning.” Practical systems often avoid strict identity and rely on idempotent actions to tolerate duplicates.Why is idempotence critical for recovery?
When failures cause retries or replays, steps may execute more than once. If each step is idempotent, repeating it yields the same effect as doing it once, making strategies like restart or resume safe despite potential duplicates.What are the restart and resume strategies, and when does restart fall short?
- Restart: re-execute the process from the beginning; simple but assumes idempotent steps and determinism. It can be problematic with delays/timeouts (they get reset) and with non-deterministic actions (time, randomness).- Resume: continue from the most recent save point by persisting state/continuations between steps; avoids resetting timers and reduces sensitivity to non-determinism.
How do Sagas differ from Durable Executions?
Sagas are application-level (failure-aware) definitions: developers encode state transitions and persistence/compensation to achieve failure transparency. Durable executions are platform-level (failure-agnostic): the runtime captures progress and handles recovery so business logic remains free of failure-handling code.What are log-based and state-based implementations of durable executions?
- Log-based: persist each step’s outputs in a durable log and replay on recovery with deduplication. Pros: simple, minimal runtime support. Cons: requires determinism; log can grow large.- State-based: persist and restore the execution’s continuation (state) to resume exactly where it failed. Pros: no need for determinism or growing logs. Cons: requires serializable continuations, which many runtimes don’t yet support (though some emerging languages do).
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free