Distributed consensus is presented as a foundational building block for reliable, scalable systems: it lets multiple processes advance in lockstep and act as a single fault-tolerant unit. The chapter explains why agreement on a single value (or a sequence of values) is both essential and hard in realistic settings with crashes and unreliable networks. It clarifies the safety (Validity, Integrity, Agreement) and liveness (Termination) goals, relates consensus to earlier atomic commitment work, and situates the problem amid the FLP impossibility result, which limits guaranteed liveness in fully asynchronous systems. The payoff is state machine replication: if identical deterministic replicas process the same ordered log of commands, they remain consistent and can mask failures, making consensus the mechanism that orders those commands.
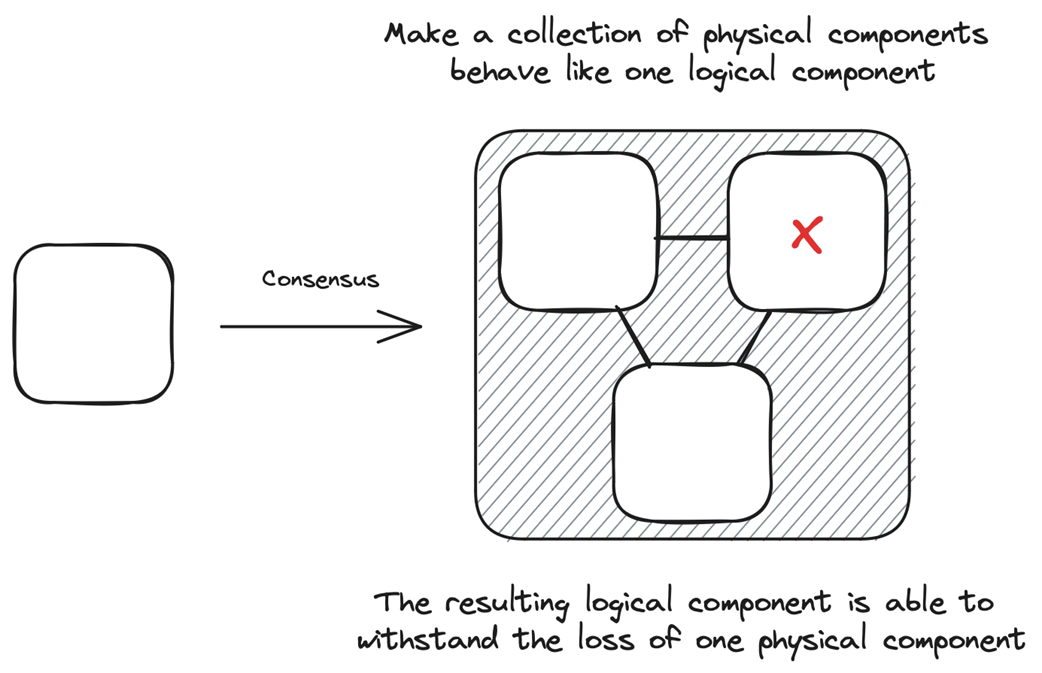
To implement consensus in practice, the text contrasts an idealized single decision-maker with robust, failure-tolerant designs built from leaders and quorums. Majority quorums (> N/2) ensure overlapping knowledge, prevent split-brain, and yield the familiar N = 2f + 1 rule to tolerate f failures. Historically, Paxos introduced fault-tolerant consensus for a single decision and inspired Multi-Paxos for sequences; Viewstamped Replication independently addressed the same problem earlier; and modern systems commonly combine a leader that proposes values with quorum acknowledgments for commitment. This pairing preserves progress and consistency despite message loss, duplication, reordering, and crashes.
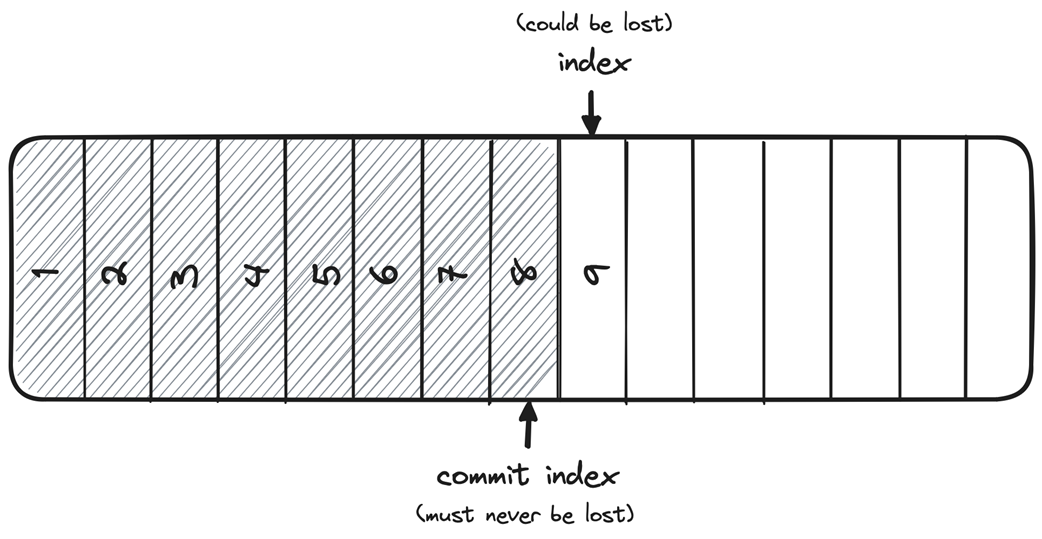
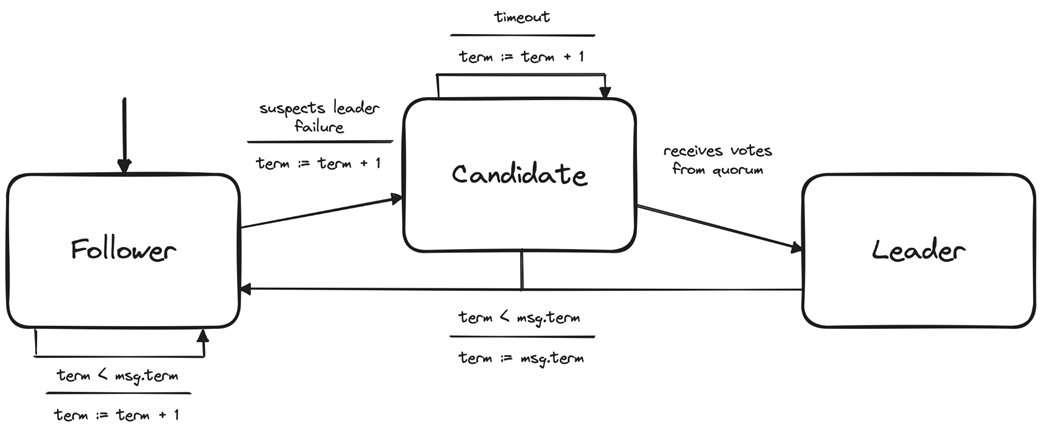
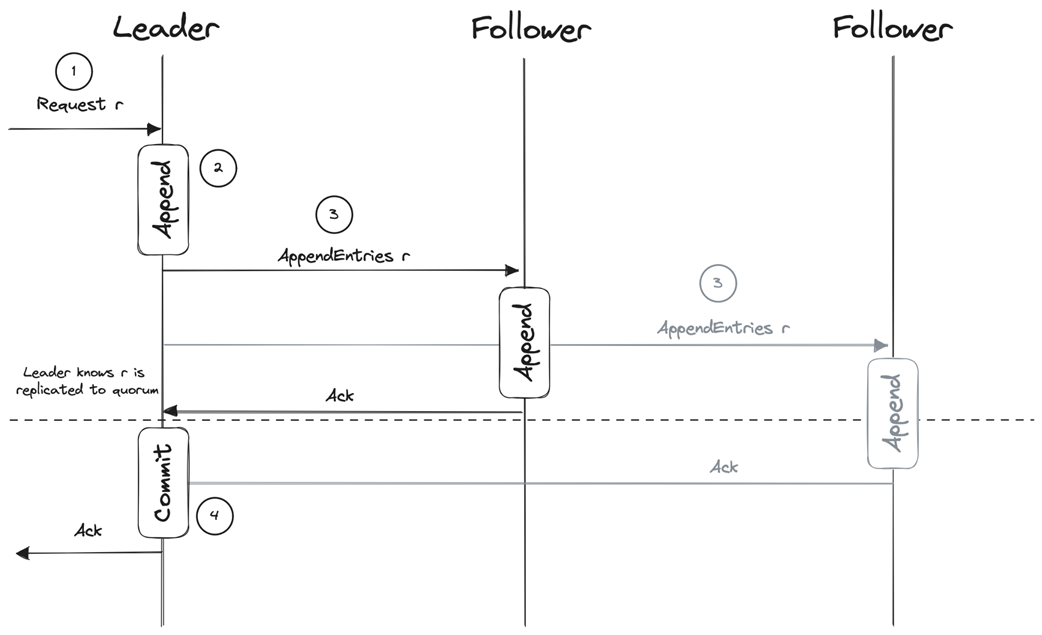
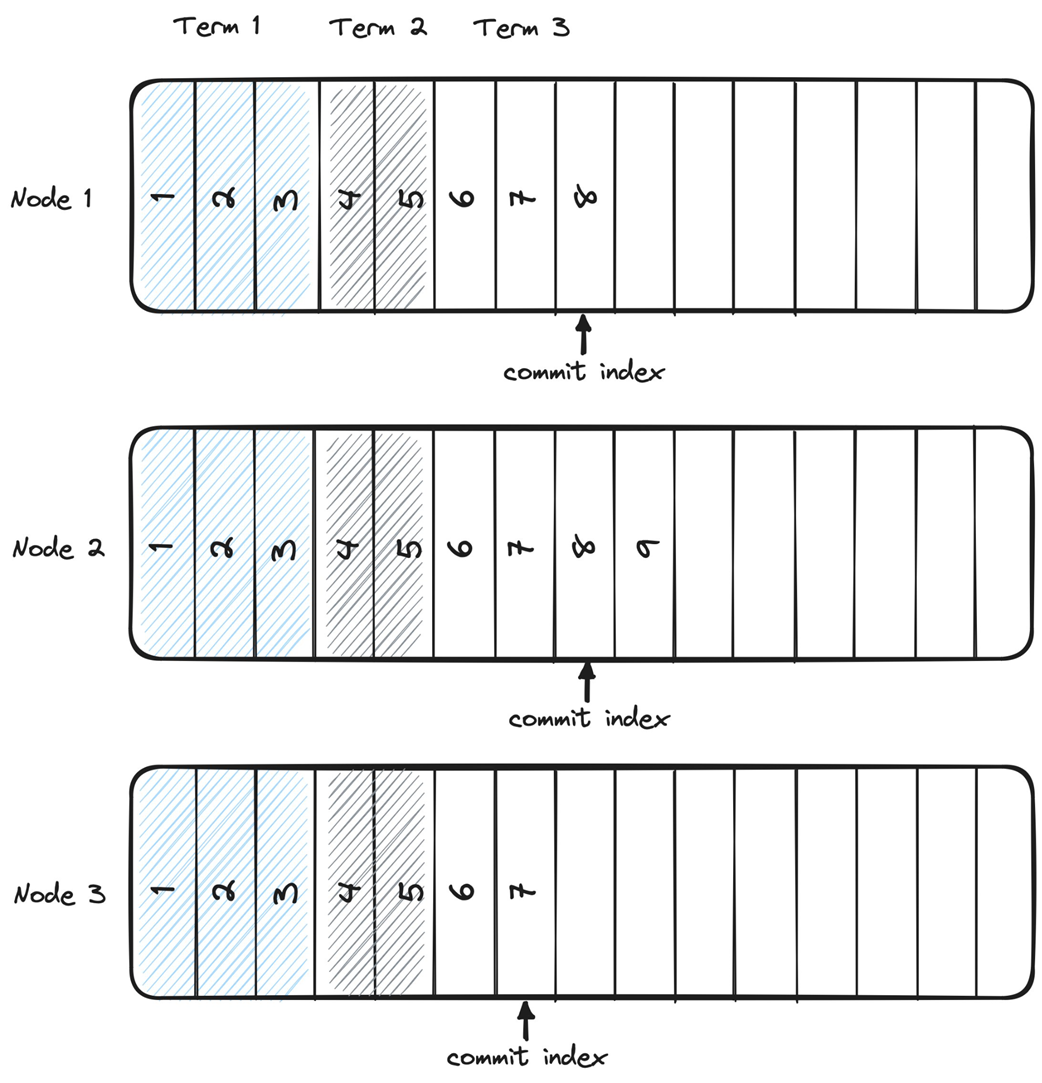
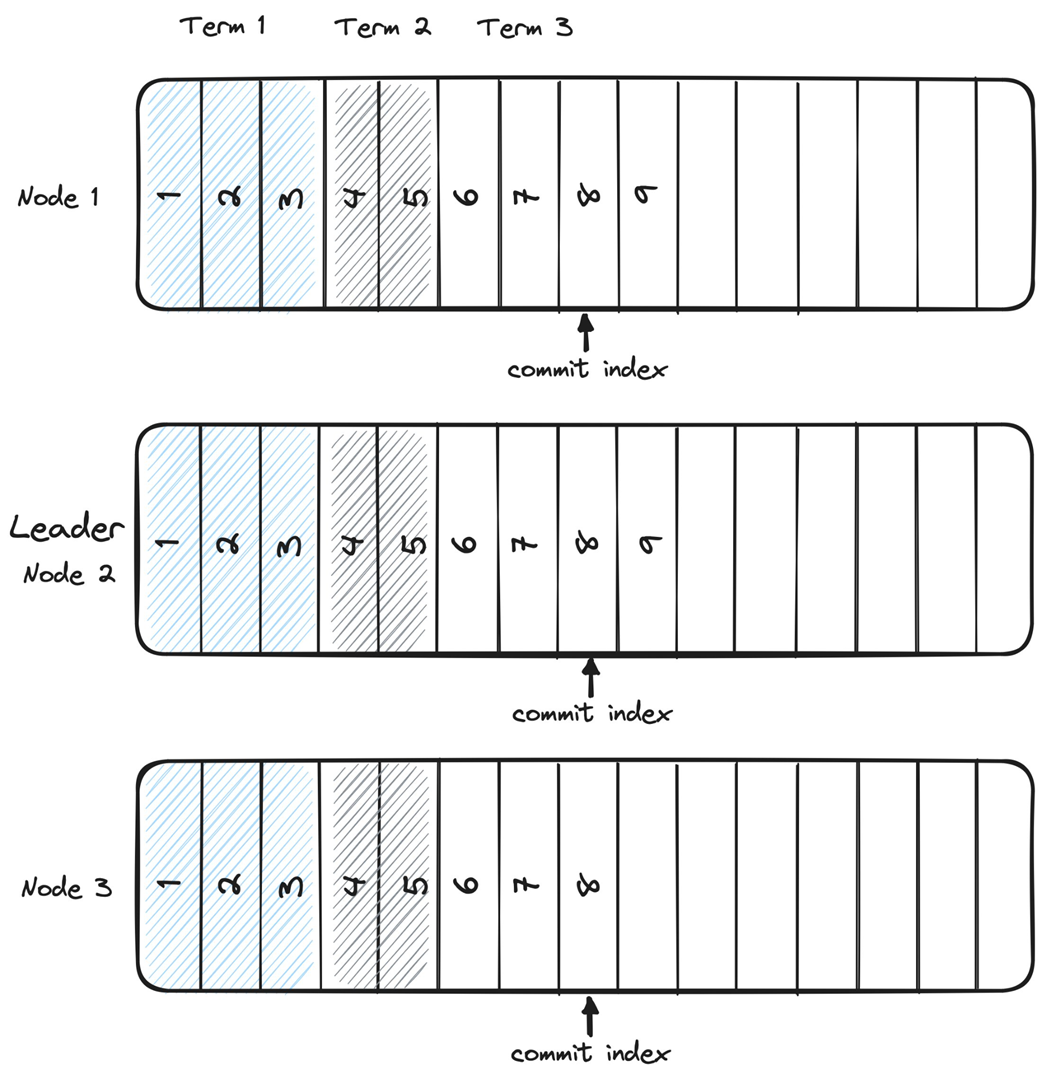
The chapter then focuses on Raft, a consensus protocol designed for understandability while managing a replicated log. Raft structures time into terms with leader election and log replication phases, uses a logical clock and term numbers as fencing tokens, and maintains log consistency and a commit index to protect state machine safety. Leaders accept, append, propagate, and commit entries after quorum acknowledgments; only candidates with the most up-to-date logs (by last term and index) can win elections, ensuring that committed entries are never lost. Through puzzles, the text highlights subtle implications: entries that exist only on a leader can be lost if the leader fails before replication, but once an entry reaches a quorum—even if the leader crashes before advancing its commit index—election rules ensure the next leader preserves and completes the commitment, maintaining safety and eventual consistency.
Transforming a process into a fault-tolerant process
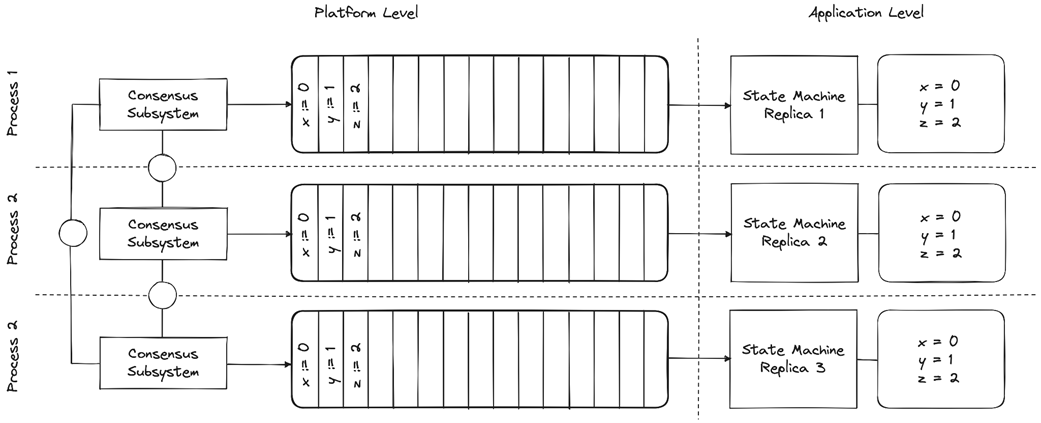
State machine replication in action
Raft’s log abstraction
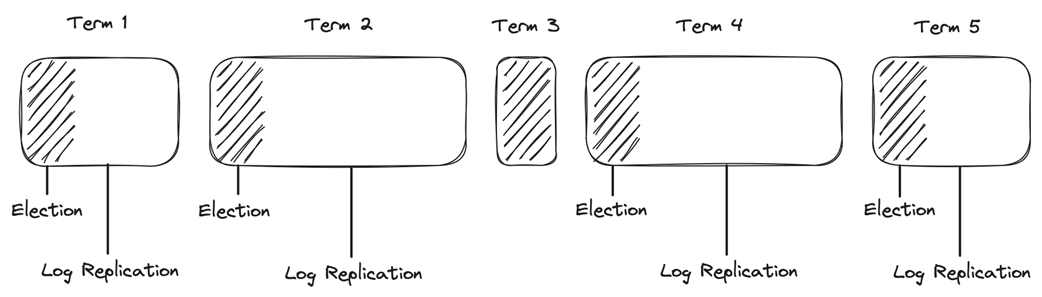
The Raft consensus protocol advances in terms, where each term consists of a leader election phase and a log replication phase.
Node states and state transition of the Leader Election Protocol
Message flow of the Log Replication Protocol
Puzzle 1
Puzzle 2
Puzzle 3
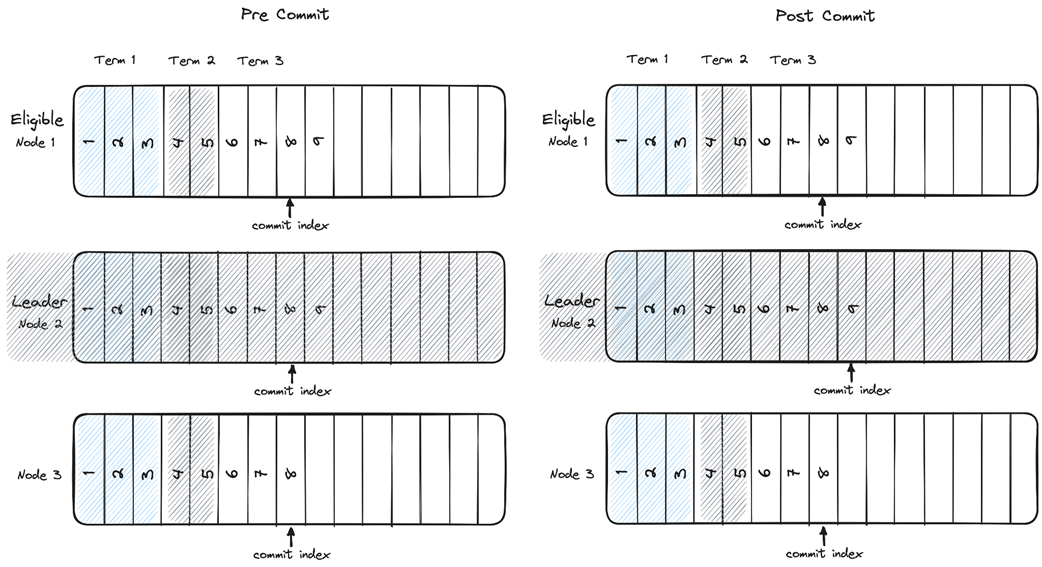
Left: Leader crashes before commit; right: Leader crashes after commit.
Summary
Distributed Consensus allows a group of redundant processes to advance in lockstep via State Machine Replication.
State Machine Replication achieves identical outputs by applying identical inputs in identical order to a group of identical processes.
Achieving consensus in realistic systems with process and network failures is notoriously challenging. Consensus algorithms like Viewstamped Replication, Paxos, and Raft address these challenges.
The Raft protocol is a popular consensus protocol, often praised for its emphasis on understandability. Yet Raft remains a complex protocol.
Raft divides finding consensus into leader election and log replication.
FAQ
What is distributed consensus and why is it difficult to achieve in real systems?Distributed consensus is the process by which multiple processes agree on a single value so they can advance in lockstep and act as one. It is easy in an idealized model with no failures and perfectly reliable, ordered messaging, but difficult in realistic environments where nodes can crash and networks can delay, drop, duplicate, or reorder messages.What safety and liveness properties define a consensus algorithm?Safety: Validity (only proposed values can be decided), Integrity (a process decides at most once), and Agreement (no two correct processes decide different values). Liveness: Termination (every non-failed process eventually decides).What does the FLP impossibility theorem imply for consensus?FLP shows that in a fully asynchronous system without clocks, no algorithm can guarantee consensus termination under all conditions if even one node may fail. Practically, systems assume additional timing constraints (e.g., clocks, partial synchrony, or failure detectors) to achieve consensus with high probability and preserve safety.How does state machine replication use consensus to provide fault tolerance?State machine replication runs identical deterministic processes that start from the same state and apply the same inputs in the same order. A consensus protocol agrees on a single, ordered log of commands for all replicas, ensuring identical outputs and enabling the group to mask individual node crashes.What is a quorum and why is N = 2f + 1 needed to tolerate f failures?A quorum is a strict majority of nodes (size greater than N/2) whose acknowledgments are required to make a decision. Any two quorums intersect, preventing split-brain and preserving consistency; to tolerate f failures you need at least f + 1 live nodes to form a majority, hence N = 2f + 1.Why combine a leader with quorums in protocols like Raft, Multi-Paxos, and Viewstamped Replication?A leader orders proposals (simplifying sequencing), while quorum acknowledgments ensure durability and agreement despite failures. This pairing avoids single points of failure inherent in a naive “benevolent dictator” approach and copes with unreliable networks by requiring majority confirmation to commit.In Raft, what are terms and how do they ensure only one node can act as leader?Time is divided into monotonically increasing terms, each with a leader election phase followed by log replication. Term numbers act like fencing tokens: nodes reject messages from lower terms, so even if multiple nodes momentarily believe they’re leaders, only the node in the highest term can make progress.How does Raft ensure log consistency and its State Machine Safety property?Raft elects only candidates with the most up-to-date logs, comparing last-entry term first and then log length. Once an entry is stored on a quorum, any future leader must contain that entry, ensuring committed entries are never lost or overwritten and that no two processes apply different entries at the same index.What are the steps of Raft’s log replication from client request to commit?1) Leader accepts a client request and appends it locally. 2) Leader sends AppendEntries RPCs to followers. 3) Followers append and acknowledge. 4) When the leader receives acknowledgments from a quorum (including itself), it advances the commit index and replicas can apply the entry to their state machines.Can an uncommitted log entry be lost in Raft, and when must it be preserved?An entry that exists only on the leader can be lost if the leader fails before replication. However, if the entry has been replicated to a quorum (e.g., leader and one follower in a three-node cluster), it must not be lost even if the leader crashes before marking it committed; the follower with the most up-to-date log will win leadership and finish committing it.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Think Distributed Systems ebook for free
Think Distributed Systems ebook for free