7 Reasoning & Inference-Time Scaling
Reasoning-focused language models and inference-time scaling have driven major performance gains from late 2024 through 2025 by training models to think more before answering and by spending more compute at inference. Building on the classic “cake” view of learning—self-supervision as the cake, instruction tuning as the icing, and reinforcement learning as the cherry—this wave confirmed that scaled reinforcement learning can reliably elicit stronger reasoning, coding, and math abilities. A central development is Reinforcement Learning with Verifiable Rewards (RLVR), which complements RLHF: instead of scoring subjective qualities with a learned reward model, RLVR leans on objective checks (e.g., correctness of a math answer or passing unit tests) to shape behavior. Models like o1 and DeepSeek R1 popularized this approach and demonstrated that allocating more test-time compute—longer chains of thought or multiple sampled solutions—translates into markedly better results.
Operationally, RLVR follows a simple but powerful loop: sample multiple answers, verify them with deterministic checks, reinforce the successful trajectories, and repeat—often revisiting the same problems many times to consolidate rare, latent behaviors into robust skills. Verification functions make reward modeling optional and reduce over-optimization risks in domains with clear signals. This training both encourages and benefits from inference-time scaling: models learn to generate longer reasoning traces when useful and to leverage multiple candidate solutions with answer selection. Improved stability, better tooling, and stronger base models have made large-scale RL runs practical, while distillation and instruction tuning on the outputs of RL-trained models propagate reasoning behaviors to smaller or faster variants without fully reproducing the original RL cost.
Practically, a shared playbook has emerged: filter data by difficulty so the model sees problems it solves inconsistently (to create learning signal), schedule curricula or online filtering during training, remove or relax constraints like KL penalties and clipping to enable exploration, adopt asynchronous or off-policy updates for throughput, add light rewards for formatting and language consistency, manage length with penalties and “thinking budget” curricula, normalize losses to avoid bias, and scale test-time compute with parallel rollouts and answer selection. Empirical lessons include that text-only reasoning phases can improve multimodal performance and that system prompts can toggle reasoning depth. The field is moving rapidly toward open documentation of full training lifecycles and early scaling laws for RL in reasoning. Reinforcement learning has shifted from a decorative “cherry on top” to a load-bearing component of modern post-training, and while today’s RLVR techniques are not final, they form the foundation for the next generation of reasoning-capable models.
RLVR in the form of an RL feedback loop. Instead of a reward model, a verification function is used.
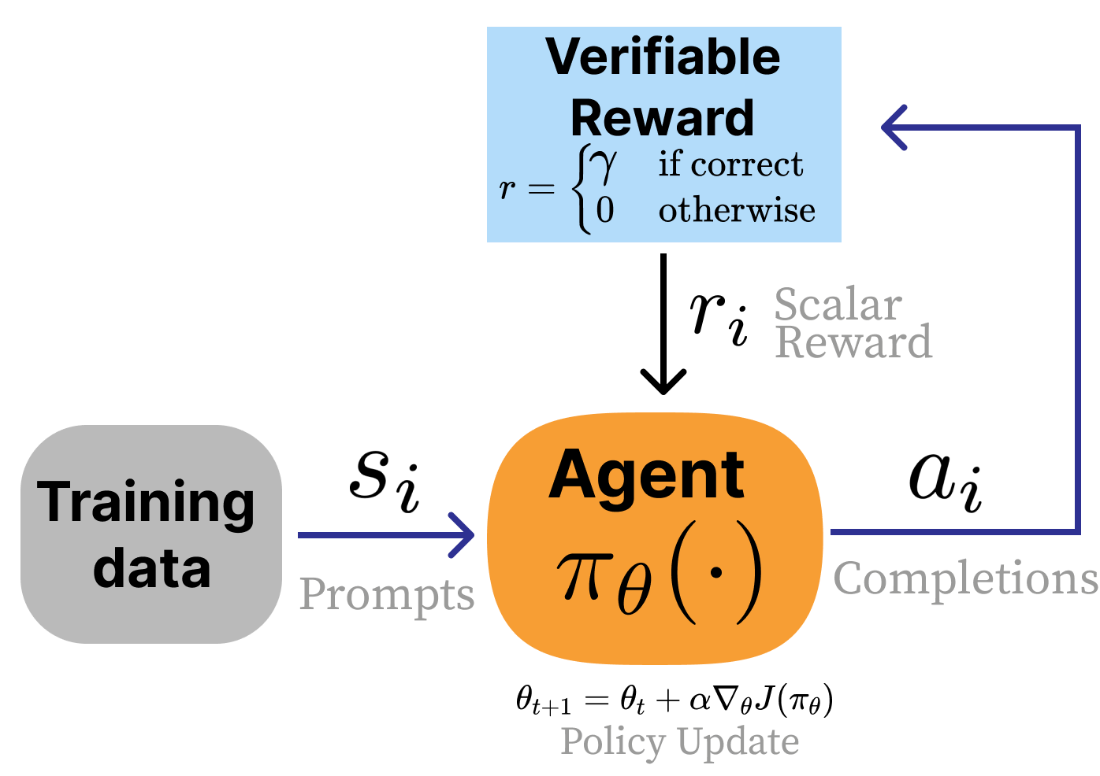
Summary
- Reasoning models use reinforcement learning with verifiable rewards (RLVR) to dramatically improve performance on math, code, science, and other tasks where the correctness of an answer can be assessed. Unlike RLHF, which requires a learned reward model, RLVR uses verification functions – such as answer matching or unit tests – that return definitive correctness signals.
- The core training loop applies the policy gradient algorithms from chapter 6 in a remarkably simple way: sample multiple answers to questions, take gradient steps toward the correct ones, and repeat.
- Inference-time scaling – using more computation during generation to get better responses – is closely linked to reasoning training. RL-trained models learn to produce longer reasoning chains that are strongly correlated with improved performance, a meaningful shift from the superficial length bias seen in early RLHF.
- Common practices for reasoning training include difficulty filtering (training only on problems the model solves 20-80% of the time), removing or relaxing KL penalties to allow greater exploration, format and language consistency rewards, and progressive length scheduling to combat overthinking.
- The reasoning model landscape evolved rapidly from OpenAI’s o1 and DeepSeek R1 through dozens of open-weight models – including Qwen 3, Phi-4 Reasoning, Llama-Nemotron, and OLMo 3 Think – with the field converging on recipes that combine instruction tuning, RLHF, and large-scale RLVR in carefully sequenced stages. Substantial changes to these recipes are expected to continue.
FAQ
What are “reasoning models,” and what changed around 2024–2025?
Reasoning models are language models trained to think extensively before answering (often generating internal reasoning tokens) and to leverage more compute at inference. Around 2024–2025, large-scale reinforcement learning with verifiable rewards (RLVR), together with RLHF and long-context models, enabled a major jump in performance on math, code, and science problems. This shifted post-training priorities industry-wide toward scaling RL and inference-time compute.How does RLVR differ from RLHF?
- RLHF: Uses a learned reward model to score subjective qualities like clarity, helpfulness, and safety; there is no single correct answer.- RLVR: Uses domain verification functions (e.g., exact answer checks or unit tests) that provide definitive rewards (often binary or partial credit). The reward model is optional because correctness can be directly verified.
How are answers “verified” in RLVR for math and code?
- Math: Extract the final answer from the model’s output (e.g., via an answer marker like “The answer is:” or special tokens) and compare to the known correct value to return a 1/0 reward (or partial credit variants).- Code: Run unit tests on the generated code; if all pass, reward = 1; otherwise 0 (with optional partial credit by tests passed). No learned reward model is required.
What does the RLVR training loop look like, and why does it generalize?
1) Sample multiple answers to many questions. 2) Take gradient steps toward the answers that verify as correct. 3) Repeat, revisiting the same data many times. Despite its simplicity, this procedure helps the model discover and reinforce behaviors correlated with correctness, and gains on training tasks often transfer to new questions and related domains.What is inference-time scaling, and how do reasoning models use it?
Inference-time scaling means spending more compute during generation (e.g., longer reasoning chains or multiple sampled rollouts) to improve accuracy. Reasoning models often produce more tokens per response and can aggregate multiple rollouts (e.g., majority vote or learned selector) to boost performance. The key is a strong correlation between extra tokens/compute and downstream gains, not just longer outputs.Why is RL “working now” for language models?
- Improved stability and infrastructure for long RL runs.- Mature, accessible tooling (e.g., TRL, Open Instruct, veRL, OpenRLHF).
- Stronger pretrained bases reached a capability threshold that makes reasoning RL viable (observed circa 2024+).
- Broad practitioner experience reducing brittleness (loss spikes, crashes) and reproducibility issues.
What common practices improve RL training for reasoning?
- Offline difficulty filtering (focus on problems the base solves ~20–80% of the time).- Per-batch online filtering/curriculums to schedule difficulty over training.
- Removing the KL penalty to allow broader exploration when rewards are reliable.
- Relaxed/two-sided clipping variants to encourage exploration and reduce spurious signals.
- Off-policy or asynchronous updates to keep GPUs busy on variable-length traces.
- Small format rewards (e.g., enforce think/answer structure) and language consistency rewards for multilingual stability.
- Length penalties or progressive context extension to curb overthinking and stabilize training.
- Batch-level loss/advantage normalization to avoid group-length biases.
- Parallel test-time compute (majority vote or learned selector over multiple rollouts).
What are “thinking tokens,” and can users control reasoning length?
Thinking tokens are the model’s internal reasoning traces (often bracketed, then followed by a concise answer). For hard tasks, thousands of tokens may be generated. Training often rewards consistent formatting and, in many systems, users can toggle or budget reasoning effort via system prompts or length-controlled training. Some models also distill long-reasoning behavior into smaller models.How does RLVR compare to standard instruction tuning for developers?
- Instruction tuning (often with parameter-efficient methods like LoRA) matches model outputs to provided completions in 1–2 epochs, primarily shaping behavior and style.- RLVR optimizes for correctness using verification signals, running hundreds or thousands of epochs over smaller, curated datasets to turn sparse, fragile skills into robust, repeatable behaviors.
 The RLHF Book ebook for free
The RLHF Book ebook for free