6 Reinforcement Learning
This chapter surveys how reinforcement learning is used to align language models with human preferences in RLHF. It starts from the practical training loop: the current policy generates completions, a reward model scores them, and a KL penalty to a frozen reference constrains drift while the optimizer updates the policy. While deep RL spans value-based and policy-gradient families (often combined in actor–critic setups), the algorithms that popularized RLHF are policy-gradient methods run on on-policy data. Despite the mathematical sophistication, the authors stress that outcomes hinge heavily on data quality and reward design.
The chapter builds the policy-gradient objective from first principles (returns, the log-derivative trick, value functions) and shows why baselines and the advantage A(s,a) reduce variance without bias. It then instantiates the theory in widely used algorithms. REINFORCE applies Monte Carlo estimates and simple baselines; RLOO lowers variance by using a leave-one-out per-prompt baseline. PPO adds importance sampling to reuse batches and a clipped surrogate to bound step size, typically with token-level credit assignment and a learned value function trained via targets such as GAE. GRPO removes the value network and computes group-relative sequence-level advantages (with common variants that adjust normalization), while PPO-like clipping is retained and the KL term is often added directly to the loss. For long sequences and large models, the chapter motivates alternatives to token-level importance ratios: GSPO moves ratios to the sequence level (length-normalized geometric mean), and CISPO clips IS weights directly with stop-gradient so every token still gets signal—each choice reflects a bias–variance and stability trade-off when rewards are sequence-level.
Turning to practice, the authors detail choices that strongly affect stability and throughput: whether KL is folded into reward or added to the loss, how to aggregate per-token losses (per-sequence, per-token, or fixed-length normalization), value-network initialization and targets, and reward/advantage normalization or whitening. They contrast bandit-style (sequence-level) and MDP-style (token-level) framings, note how per-token KL can coexist with sequence-level advantages, and discuss asynchronous actor–learner systems that keep GPUs busy while tolerating slight off-policyness (plus techniques like sequence packing). They also explain “double regularization”: in typical LLM setups with one gradient step per batch, PPO clipping often does little and the KL penalty dominates; with one-step updates, PPO/GRPO reduce to near-vanilla policy gradient. Finally, the chapter highlights reasoning-oriented refinements—such as clip-asymmetry, dynamic sampling, and value-aware variants (e.g., DAPO, VAPO)—and emphasizes that most methods share the same backbone; careful choices of advantage estimation, importance-sampling granularity, loss aggregation, and systems design usually determine stability, sample efficiency, and final quality.
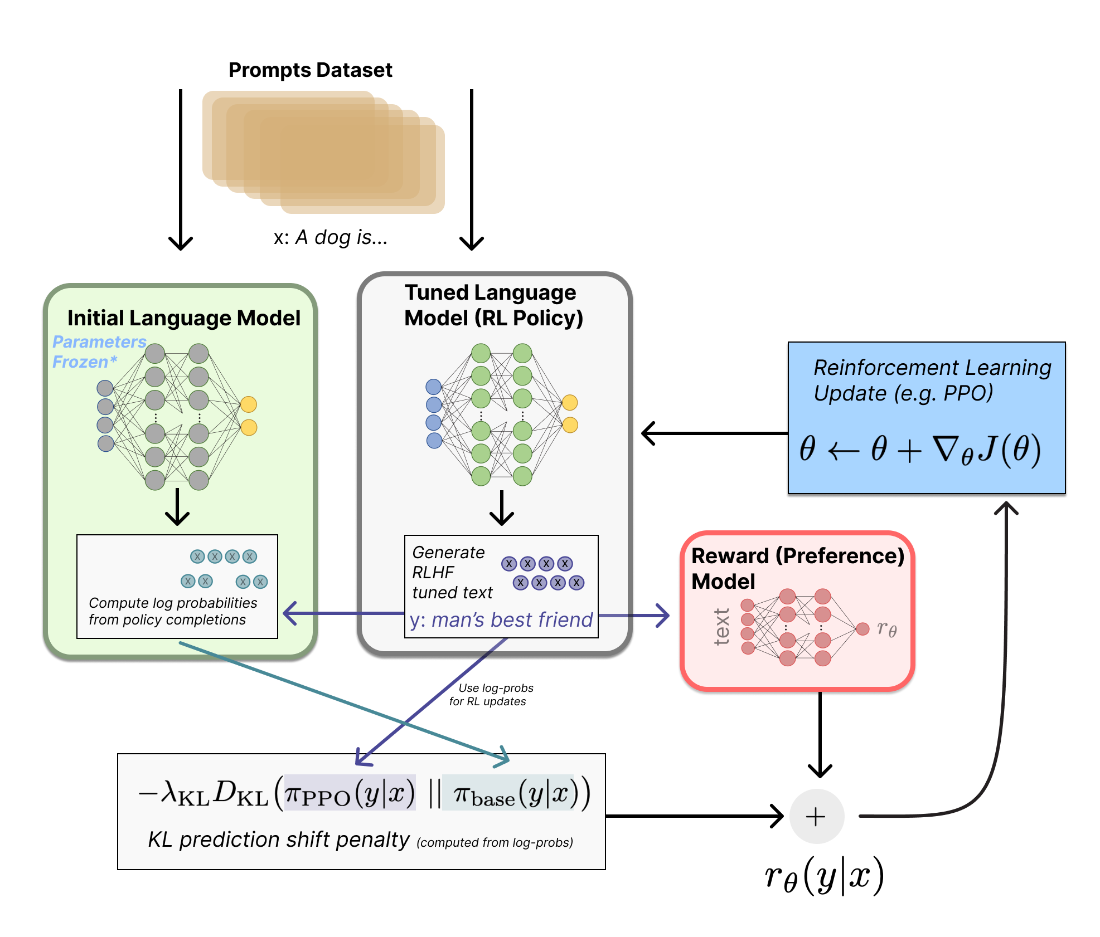
Overview of the RLHF training loop. A prompt from the dataset is passed to the tuned policy, which generates a completion. The reward model scores this completion, while the frozen initial model computes log probabilities on the same text to calculate a KL penalty that prevents excessive drift. The combined reward signal then drives a reinforcement learning update to the policy parameters.
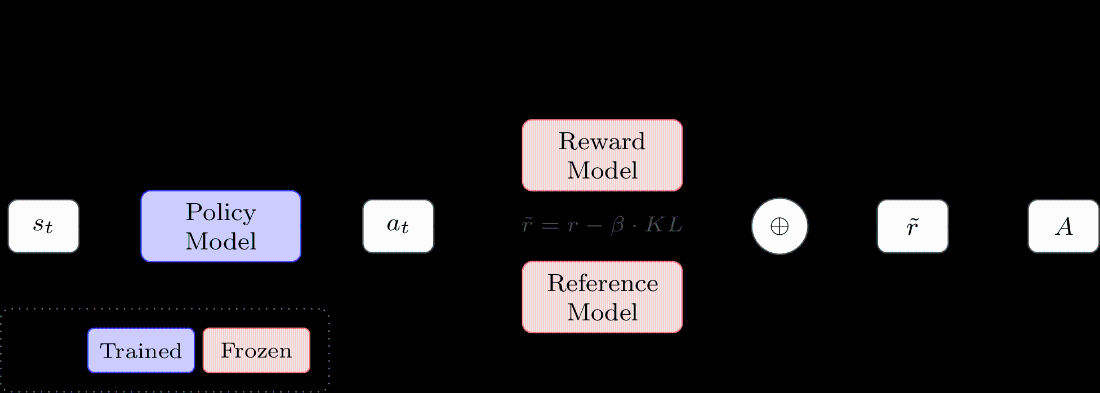
Basic REINFORCE architecture for language models. The shaped reward combines the reward model score with a KL penalty from the reference model. We build on this structure throughout the chapter.
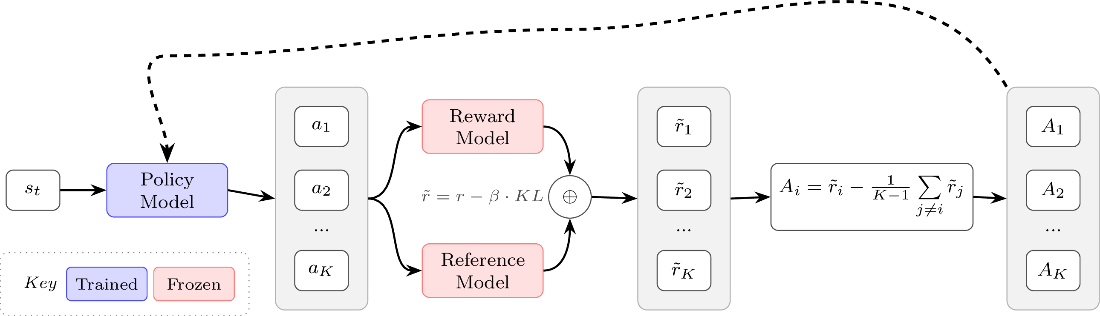
REINFORCE Leave-One-Out (RLOO) architecture. Multiple completions per prompt provide a leave-one-out baseline for advantage estimation without learning a value function.
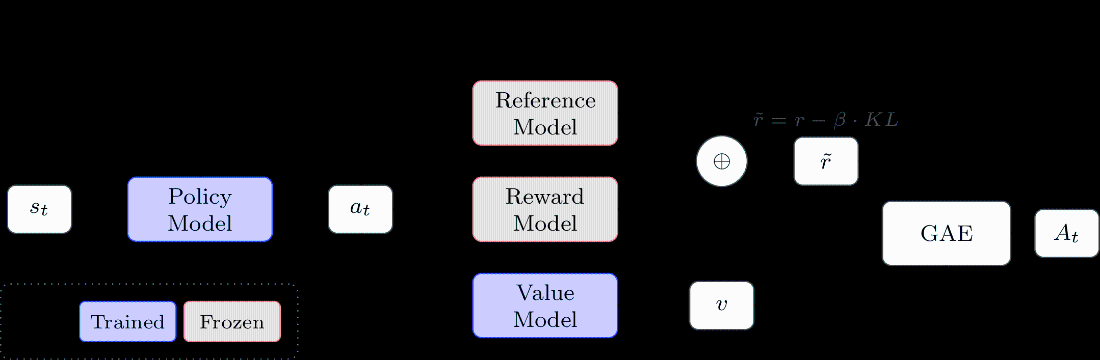
PPO architecture. A learned value function enables Generalized Advantage Estimation (GAE) for per-token advantages, used with a clipped surrogate objective.
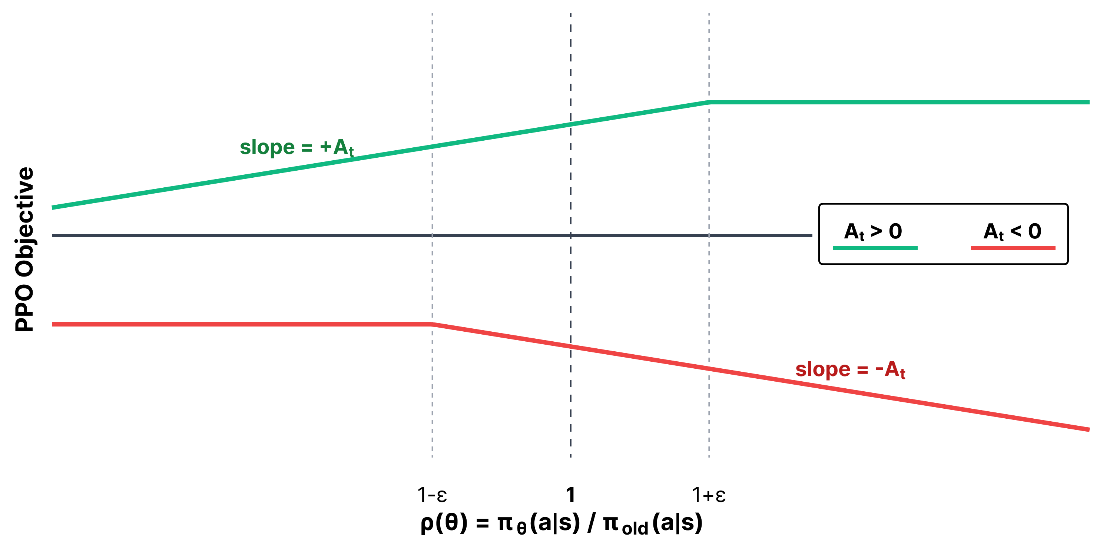
Visualization of the different regions of the PPO objective for a hypothetical advantage. The “trust region” would be described as the region where the probability ratio is within \(1\pm\varepsilon\).
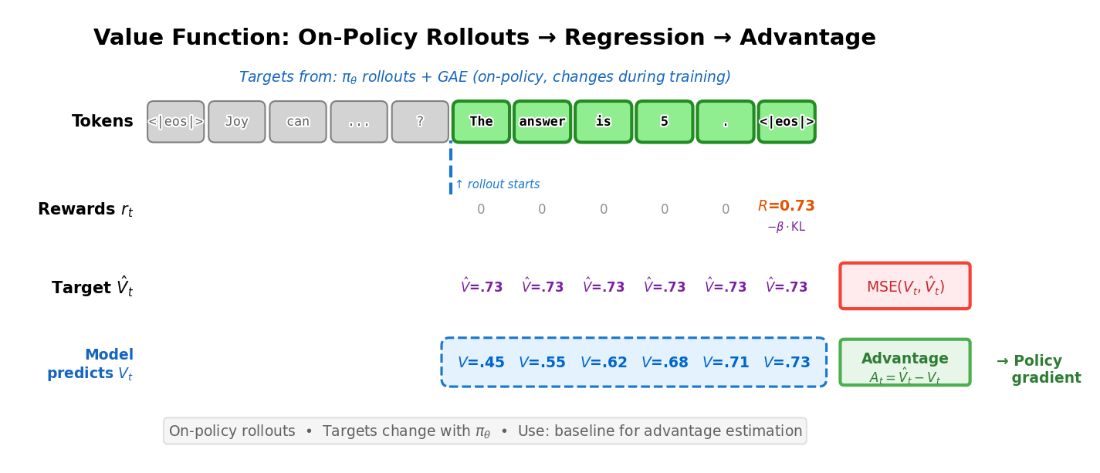
Value function training uses on-policy rollouts to compute targets. The model predicts \(V_t\) at each token, which is trained via MSE against the target return \(\hat{V}_t\). The advantage \(A_t = \hat{V}_t - V_t\) then weights the policy gradient update.
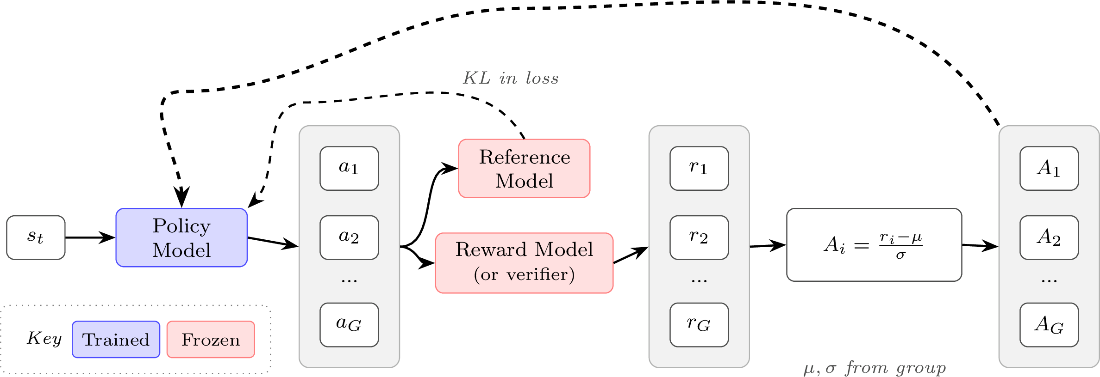
GRPO architecture. Advantages are normalized relative to the group mean and standard deviation. The KL penalty is applied directly in the loss rather than shaping the reward.
A comparison of the generation-update phases for synchronous or asynchronous RL training following Noukhovitch et al. 2024.

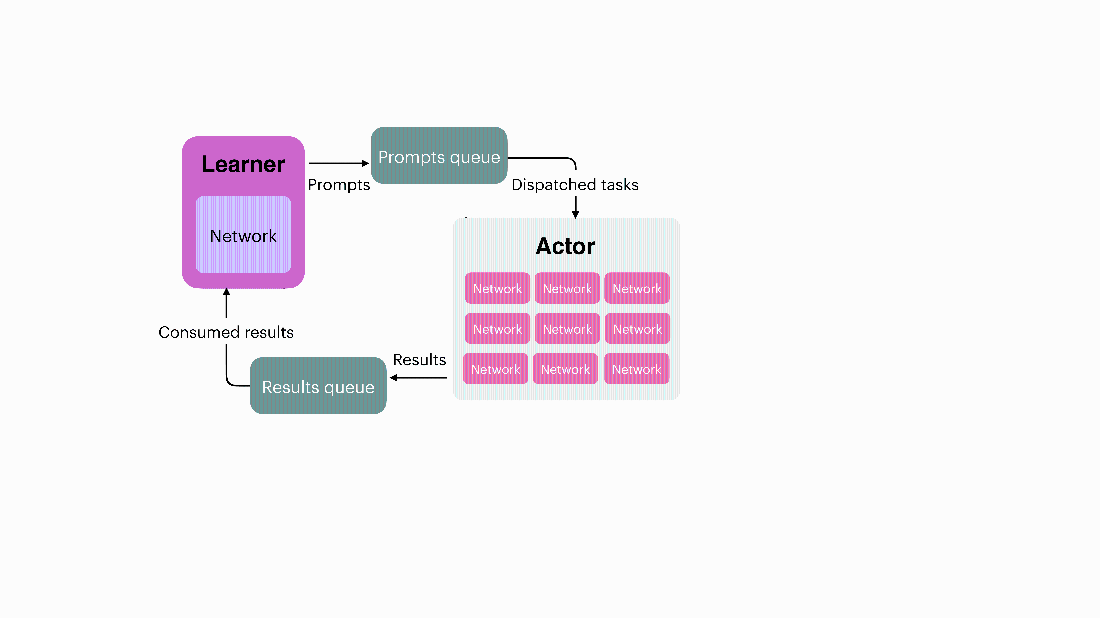
An example distributed RL system, where two queues are managed to pass data to the learner and actor GPUs, which can both be synchronized with a distributed computing library such as Ray. Olmo Team 2025, license CC-BY.
Summary
- The RL stage of RLHF closes the loop: the policy generates completions, the reward model scores them, and policy gradient algorithms update the model to produce higher-reward outputs. This is where the preference signal captured by the reward model is translated into model behavior.
- Policy gradient algorithms derive a gradient of expected reward with respect to model parameters, enabling direct optimization of the policy. Practical algorithms then reduce the variance of this gradient estimate through baselines – reference values that measure how good an action is relative to what’s typical – and advantage functions.
- The chapter covers several algorithms, each with different trade-offs and focuses:
- REINFORCE / RLOO: The simplest approaches – REINFORCE uses Monte Carlo return estimates with a batch-level baseline, while RLOO uses a leave-one-out baseline across multiple completions per prompt. Neither requires a learned value function.
- PPO: Uses importance sampling with clipped surrogate objectives and a learned value function for per-token advantage estimation via GAE. Dominated early RLHF but requires more memory and implementation complexity.
- GRPO: Replaces the learned value function of PPO with group-relative advantage normalization across multiple completions per prompt. Popular for reasoning tasks after DeepSeek R1’s release.
- GSPO / CISPO: Address numerical instability in per-token importance sampling ratios, particularly for large MoE models. GSPO computes a single importance ratio per sequence rather than per token, while CISPO clips the importance weights themselves rather than the objective, ensuring every token still receives a gradient signal.
- Implementation details such as loss aggregation (per-token vs. per-sequence), clipping strategies, value network initialization, and handling truncated generations all affect stability and final model quality.
- Asynchronous training – where generation and gradient updates run on separate systems that may hold different model weights – is crucial to modern RL infrastructure for LLMs and introduces distribution mismatch that importance sampling (and other techniques) must correct for.
- Generalized Advantage Estimation (GAE) reduces variance in PPO’s policy gradient updates by blending multi-step temporal difference (TD) residuals, though newer value-function-free methods like GRPO and RLOO are making it less central to modern LLMs.
- The same policy gradient algorithms covered here form the backbone of reasoning training (chapter 7), where they are applied at larger scale with verifiable rewards rather than learned reward models.
 The RLHF Book ebook for free
The RLHF Book ebook for free